






1 淡水质量预测相关描述和方案
1.1 问题描述
与淡水质量相关的问题日益凸显,全球范围内淡水资源的质量受到威胁。水质问题包括污染、生态系统破坏和供水不足,对环境和人类健康造成严重影响。据统计,全球每年因淡水质量问题导致的损失已超过数十亿美元。
特别是随着城市化和工业化的加速发展,淡水质量问题愈发凸显。根据复合年增长率 (CAGR) 的统计,淡水质量问题以约 15% 的速度逐年增长。为了解决这一问题,机器学习技术可以通过训练淡水质量预测模型,更迅速、更准确地监测水体质量,发挥至关重要的作用。这对于预测水质变化、及时采取措施以保护淡水资源对环境和社会具有重要意义。
1.2 预期解决方案
通过训练一个机器学习模型,使其在给定一组样品数据时能够准确地判断其是否为淡水。该模型应该能够推广到从未见过的样品数据,并在测试数据上表现良好。这里将推理时间和二分类准确度(F1分数)作为评分的主要依据。
1.3 数据集
https://filerepo.idzcn.com/hack2023/datasetab75fb3.zip
2 解决流程
为解决淡水质量预测问题,我们可以采用机器学习技术,利用XGBClassifier算法对已有的淡水质量数据进行训练,以构建预测模型。XGBClassifier是一种高效的梯度提升决策树算法,能够处理大规模数据集,并在预测准确性上表现优异。同时,利用Intel的OneAPI工具包,我们可以充分利用硬件资源,如Intel的多核处理器和加速器,提高淡水质量预测模型的训练和推理速度。
2.1 使用intel加速组件
import daal4py as d4p
from sklearnex import patch_sklearn
import modin.pandas as pd
from modin.config import Engine
Engine.put("dask")
patch_sklearn()(1)daal4py库: 可将训练好的xgboost转换为 daal4py 模型,以便进一步改进预测时间性能,它提供了一系列用于高性能数据分析和机器学习的算法,其中一些支持流式输入数据并且可以轻松有效地扩展到工作站集群。
(2)sklearnex库 :是一个Intel DAAL 提供的扩展,用于提高 scikit-learn 在特定硬件上的性能,将 scikit-learn 中的一些函数替换为 DAAL 的加速版本的工具,并且仍然完全符合所有 Scikit-Learn API 和算法。
(3)Modin库:Modin是一个Python第三方库,可以通过并行来处理大数据集。它的语法和pandas非常相似,因其出色的性能,能弥补Pandas在处理大数据上的缺陷。Intel® Distribution of Modin添加了优化,进一步加速了在Intel硬件上的处理。
2.2 数据探索
(1)查看数据集
使用modin库来读取数据,同时将 Modin 的计算引擎配置为使用 Dask。Dask 是一个用于并行计算的灵活库,允许在分布式环境中进行大规模数据处理。
import modin.pandas as pd
import os
os.environ["MODIN_ENGINE"] = "dask"
from modin.config import Engine
Engine.put("dask")
data = pd.read_csv('./dataset.csv')
print('数据规模:{}\n'.format(data.shape))
display(data.head())
data.info() 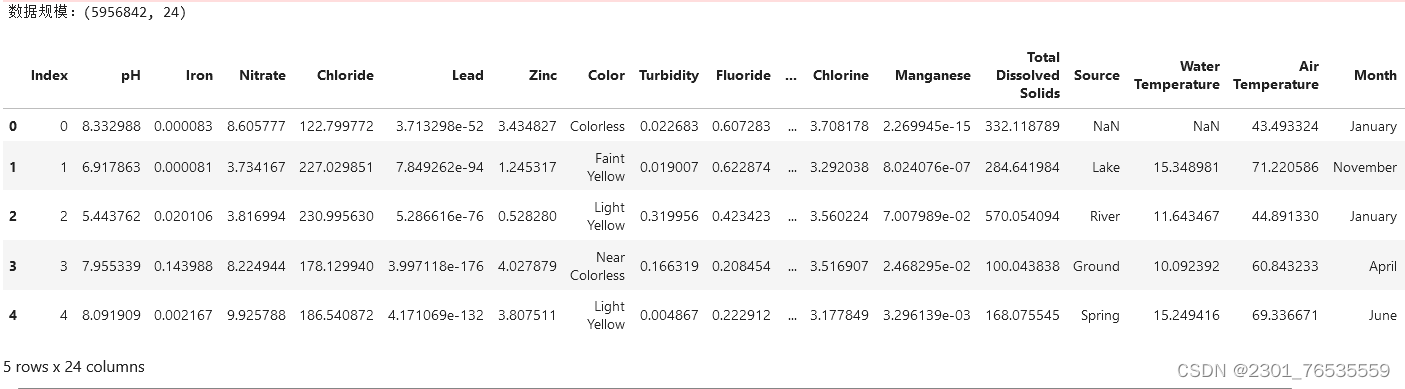

由图可知文件中含有 5956842 条数据,有24 列,包含23个特征和Target标签。浮点型(float64)占 19 列,整型(int64)字段占 2 列,对象型(object)占 3 列,总共占用内存空间大约 1.1GB。
(2)饼状图查看Target标签分布
import matplotlib.pyplot as plt
def plot_target(target_col):
tmp=data[target_col].value_counts(normalize=True)
target = tmp.rename(index={1:'Target 1',0:'Target 0'})
wedgeprops = {'width':0.5, 'linewidth':10}
plt.figure(figsize=(6,6))
plt.pie(list(tmp), labels=target.index,
startangle=90, autopct='%1.1f%%',wedgeprops=wedgeprops)
plt.title('Label Distribution', fontsize=16)
plt.show()
plot_target(target_col='Target')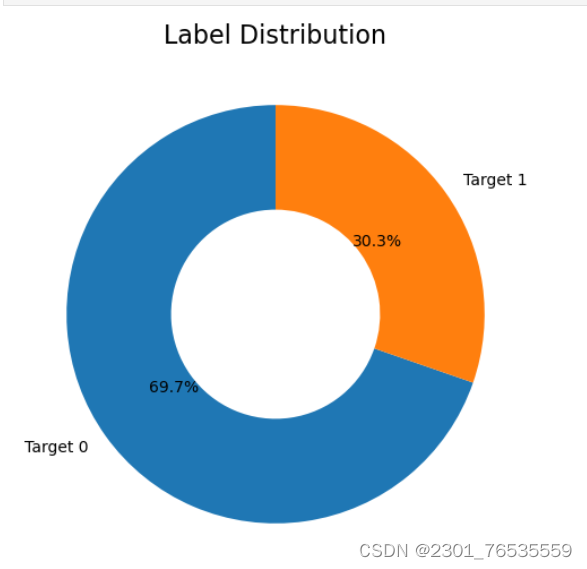
上图为标签分布图,由图可知数据中淡水占30.3%,非淡水占69.7%。比例大约为7:3。
(3)查看热力图
import plotly.io as pio
import matplotlib
import plotly.graph_objects as go
import pandas as pds
import seaborn as sns
data1 = pds.read_csv('./dataset.csv')
factor = pds.factorize(data1['Color'])
print(factor)
data1.Color = factor[0]
factor = pds.factorize(data1['Source'])
print(factor)
data1.Source = factor[0]
factor = pds.factorize(data1['Month'])
print(factor)
data1.Month = factor[0]
corr = plt.subplots(figsize = (30,20),dpi=128)
corr= sns.heatmap(data1.corr(method='spearman'),annot=True,square=True)
(4)查看各属性与类别相关性
pio.renderers.default = "iframe"
def plot_target_corr(corr, target_col):
corr=corr[target_col].sort_values(ascending=False)[1:]
pal=sns.color_palette("RdYlBu",37).as_hex()
pal=[j for i,j in enumerate(pal) if i not in (17,18)]
rgb=['rgba'+str(matplotlib.colors.to_rgba(i,0.8)) for i in pal]
fig=go.Figure()
fig.add_trace(go.Bar(x=corr.index, y=corr, marker_color=rgb,
marker_line=dict(color=pal,width=2),
hovertemplate='%{x} correlation with Target = %{y}',
showlegend=False, name=''))
fig.update_layout(title='Feature Correlations with Target',
yaxis_title='Correlation', margin=dict(b=160), xaxis_tickangle=45)
fig.show()
corr=data1.corr()
plot_target_corr(corr=corr, target_col='Target') 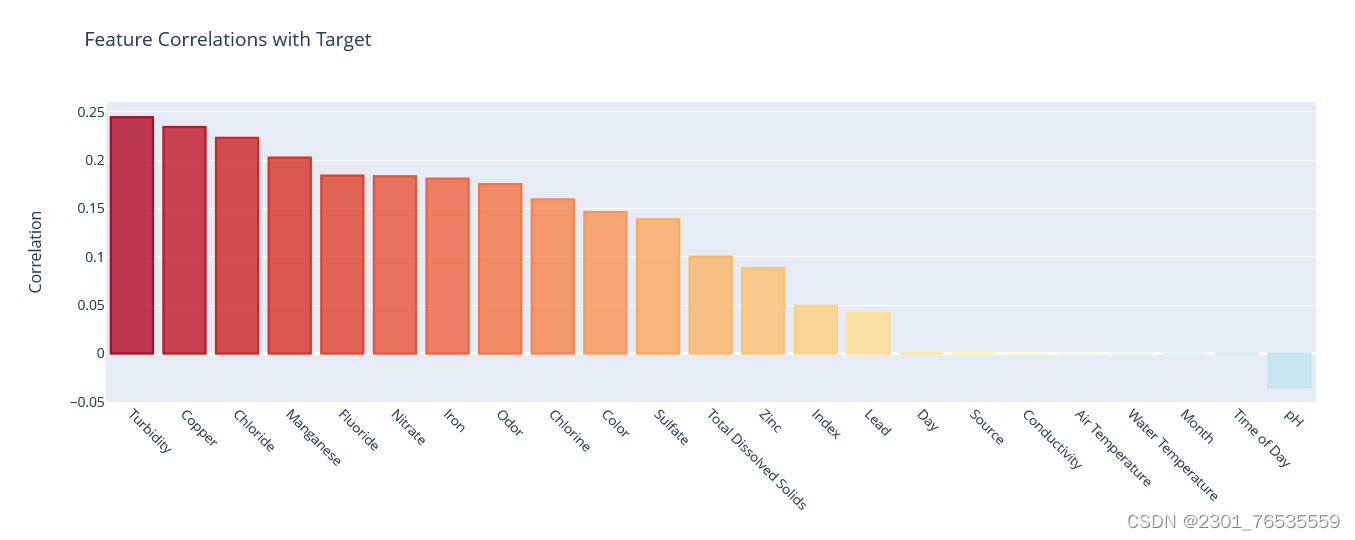
由图可知,正相关性最高的是Tutbidity,负相关性最高的是pH。相关性较低的是Time of Day, Month, Water Temperature, Source, Conductivity, Air Temperature。后续将删除这些特征。
(3)查看箱型图
figData=data1.drop(columns=['Index','Target'])
sns.set_style('ticks')
sns.set_context('notebook', font_scale=1.1)
plt.figure(figsize=(30, 15))
for i,column in enumerate(figData.columns,start=1):
plt.subplot(6,4,i)
sns.boxplot(y=column, data=figData, width=0.6)
plt.ylabel(column, fontsize=12)
plt.tight_layout() 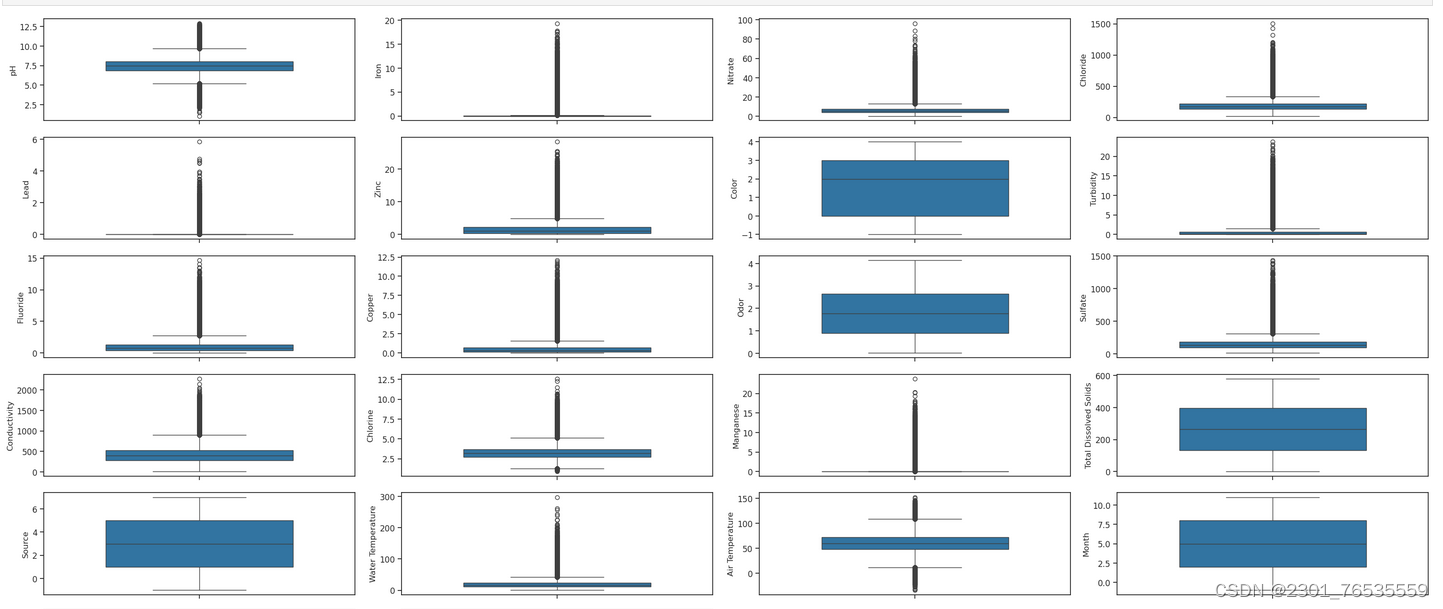
(5)查看直方图和QQ图
from scipy import stats
data1=data1.drop(columns=['Index','Time of Day', 'Month', 'Water Temperature', 'Source', 'Conductivity', 'Air Temperature'])
train_cols = 4
train_rows = len(data1.columns)
plt.figure(figsize=(4*train_cols,4*train_rows))
i=0
for col in data1.columns:
i+=1
ax=plt.subplot(train_rows,train_cols,i)
sns.distplot(data1[col],fit=stats.norm)
i+=1
ax=plt.subplot(train_rows,train_cols,i)
res = stats.probplot(data1[col], plot=plt)
plt.tight_layout()
plt.show() 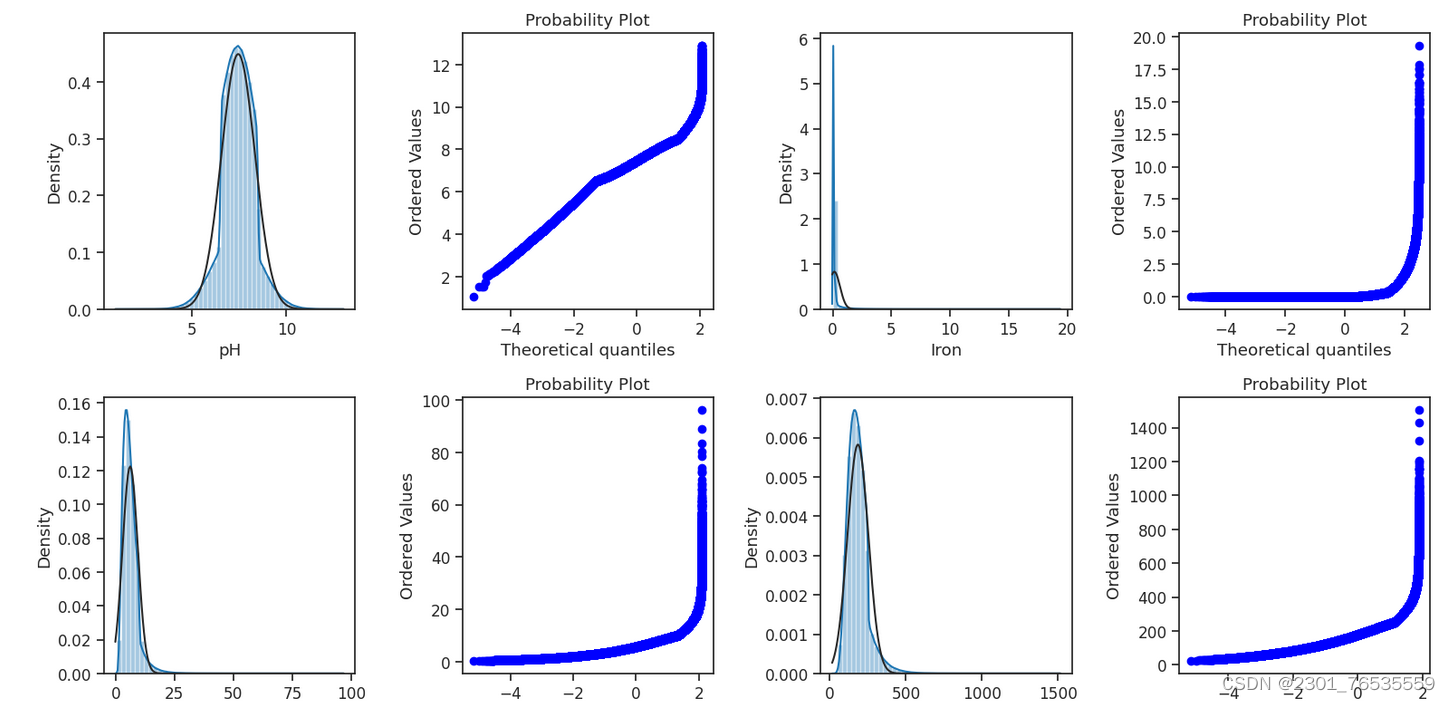
2.3 数据处理
(1)转换字符型数据
将Color、Source以及Month这三个标签进行因子化转换为数字型变量,有利于后续进行模型学习和预测。
factor = pd.factorize(data['Color'])
print(factor)
data.Color = factor[0]
factor = pd.factorize(data['Source'])
print(factor)
data.Source = factor[0]
factor = pd.factorize(data['Month'])
print(factor)
data.Month = factor[0]
data.head()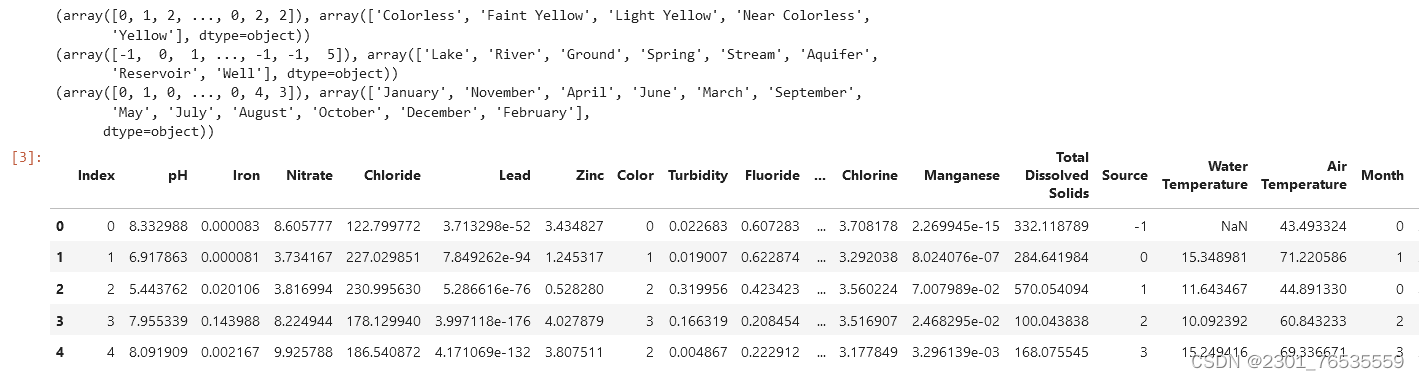
(2)缺失值和重复值处理
data=data.drop(columns=['Index','Time of Day', 'Month', 'Water Temperature', 'Source', 'Conductivity', 'Air Temperature'])
display(data.isna().sum())
missing = data.isna().sum().sum()
duplicates = data.duplicated().sum()
print("\n数据集中共有{:,.0f}缺失值.".format(missing))
print("数据集中共有{:,.0f}重复值.".format(duplicates))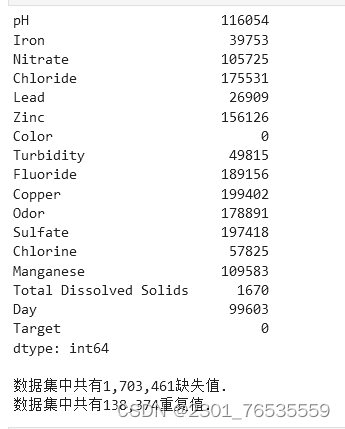
data = data.fillna(data.interpolate())
data.drop_duplicates(keep='first', inplace=True, ignore_index=True)
missing = data.isna().sum().sum()
duplicates = data.duplicated().sum()
print("\n数据集中有{:,.0f} 缺失值.".format(missing))
print("数据集中有 {:,.0f} 重复值.".format(duplicates)) 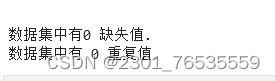
(3)最大最小值归一化
cols_numeric=list(data.columns)
def scale_minmax(col):
return (col-col.min())/(col.max()-col.min())
scale_cols = [col for col in cols_numeric]
data[scale_cols] = data[scale_cols].apply(scale_minmax,axis=0)
data.describe() 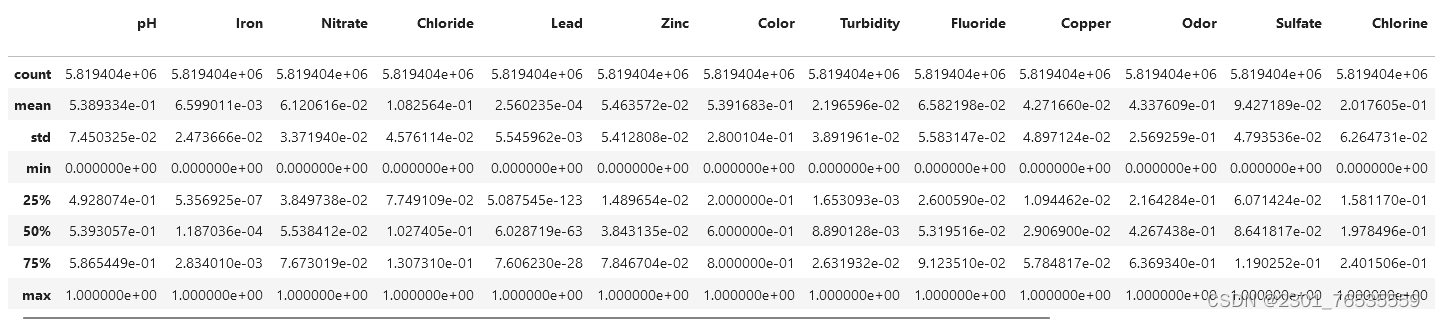
2.4 模型拟合
from sklearnex import patch_sklearn
import daal4py as d4p
patch_sklearn()
from sklearn.model_selection import train_test_split, StratifiedKFold, GridSearchCV, RandomizedSearchCV
from sklearn.preprocessing import RobustScaler
from sklearn.metrics import roc_auc_score, roc_curve, auc, accuracy_score, f1_score
from sklearn.metrics import precision_recall_curve, average_precision_score
from xgboost.sklearn import XGBClassifier
import warnings
import numpy as np
import plotly.graph_objects as go
from plotly.subplots import make_subplots
warnings.filterwarnings("ignore")
import time
import warnings
## Prepare Train and Test datasets ##
print("Preparing Train and Test datasets")
X_train, X_test, y_train, y_test = prepare_train_test_data(data=data,
target_col='Target',
test_size=.25)
## 初始化 XGBoost 模型 ##
# 设置正负样本比例,改进模型在不平衡数据集上的表现
ratio = float(np.sum(y_train == 0)) / np.sum(y_train == 1)
parameters = {'scale_pos_weight': ratio.round(2),
'tree_method': 'hist',
'random_state': 1}
xgb_model = XGBClassifier(**parameters)
## 超参数调优 ##
# 使用更多的折数和随机搜索来优化超参数
strat_kfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=1)
print("\nTuning hyperparameters...")
param_dist = {'min_child_weight': [1, 5, 7, 10],
'gamma': [0.5, 1, 2],
'max_depth': [5, 7, 10, 15],
'subsample': [0.6, 0.8, 1.0],
'colsample_bytree': [0.6, 0.8, 1.0]}
random_search = RandomizedSearchCV(xgb_model, param_distributions=param_dist,
n_iter=50, scoring='roc_auc',
cv=strat_kfold, verbose=1, n_jobs=-1,
random_state=1)
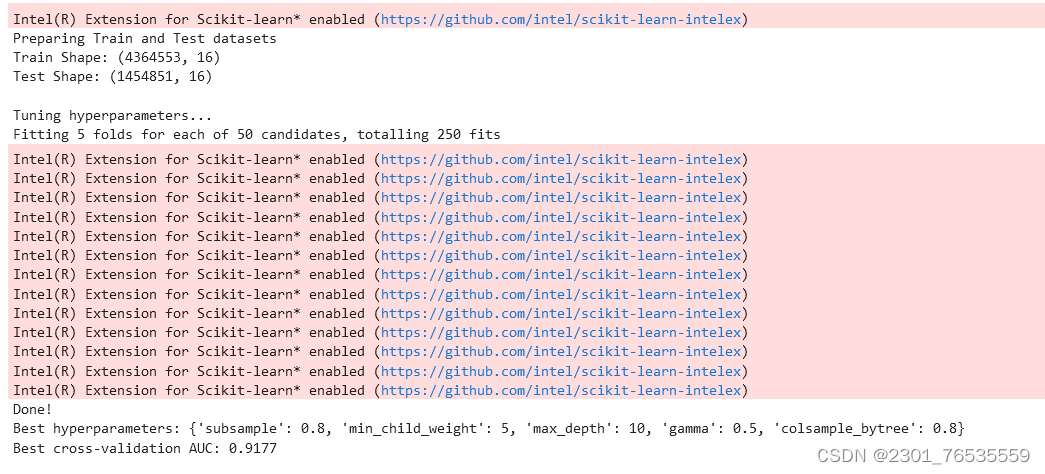
start = time.time()
random_search.fit(X_train, y_train)
end = time.time()
print("Done!\nBest hyperparameters:", random_search.best_params_)
print("Best cross-validation AUC: {:.4f}".format(random_search.best_score_))
## Convert XGB model to daal4py ##
# 转换 XGBoost 模型以使用 Intel DAAL 加速预测
xgb = random_search.best_estimator_
daal_model = d4p.get_gbt_model_from_xgboost(xgb.get_booster())
# 使用 daal4py 计算预测概率
daal_prob = d4p.gbt_classification_prediction(nClasses=2,
resultsToEvaluate="computeClassLabels|computeClassProbabilities",
fptype='float').compute(X_test, daal_model).probabilities
# 生成预测标签,计算评估指标
xgb_pred = pd.Series(np.where(daal_prob[:,1] > 0.5, 1, 0), name='Target')
xgb_auc = roc_auc_score(y_test, daal_prob[:,1])
xgb_f1 = f1_score(y_test, xgb_pred)
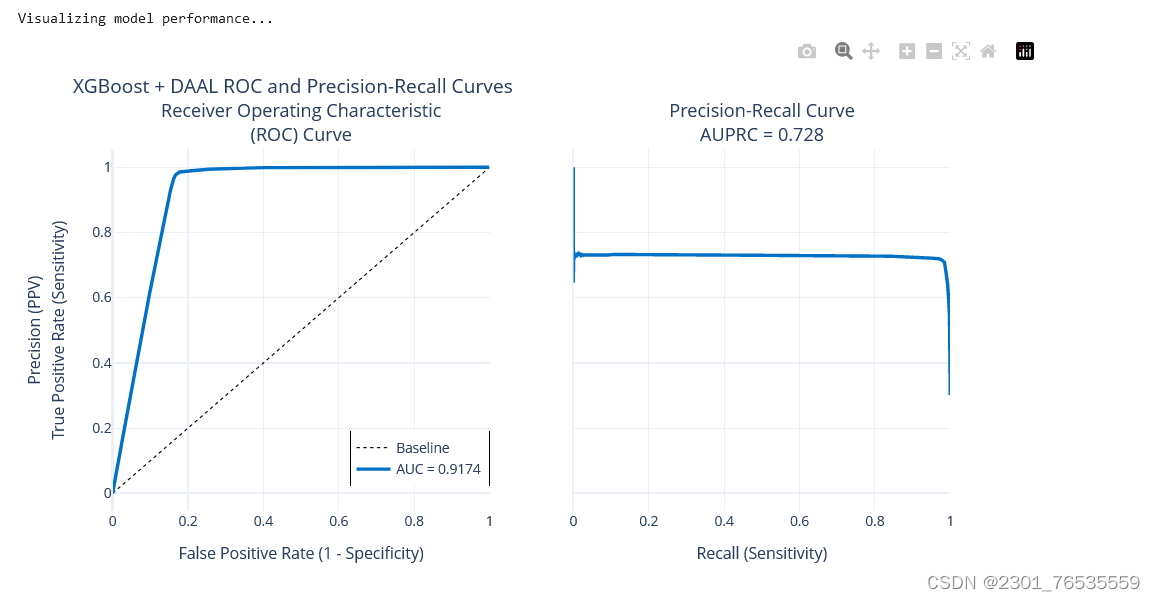

2.5 模型预测
from sklearn.metrics import f1_score, accuracy_score, roc_auc_score
scaler = RobustScaler()
new_test_scaled = scaler.fit_transform(new_test)
model_file = './xgb_model.model'
start = time.time()
xgb_model = xgb.Booster()
xgb_model.load_model(model_file)
daal_model = d4p.get_gbt_model_from_xgboost(xgb_model)
## Calculate predictions ##
daal_prob = d4p.gbt_classification_prediction(nClasses=2,
resultsToEvaluate="computeClassLabels|computeClassProbabilities",
fptype='float').compute(new_test_scaled, daal_model).probabilities # or .predictions
end = time.time()
# 生成预测标签,基于概率阈值
xgb_pred = pds.Series(np.where(daal_prob[:,1] > .5, 1, 0), name='Target')
# 打印推理时间
print('推理时间:{:.2f}s'.format(end - start))
# 计算 F1 分数
f1 = f1_score(y_true, xgb_pred)
# 计算准确率
accuracy = accuracy_score(y_true, xgb_pred)
# 计算 AUC 值
auc1 = roc_auc_score(y_true, daal_prob[:, 1])
# 打印性能指标
print(f'F1 Score: {f1}')
print(f'Accuracy: {accuracy}')
print(f'AUC Score: {auc1}')
plot_model_res("XGBoost + DAAL", y_true, daal_prob[:,1])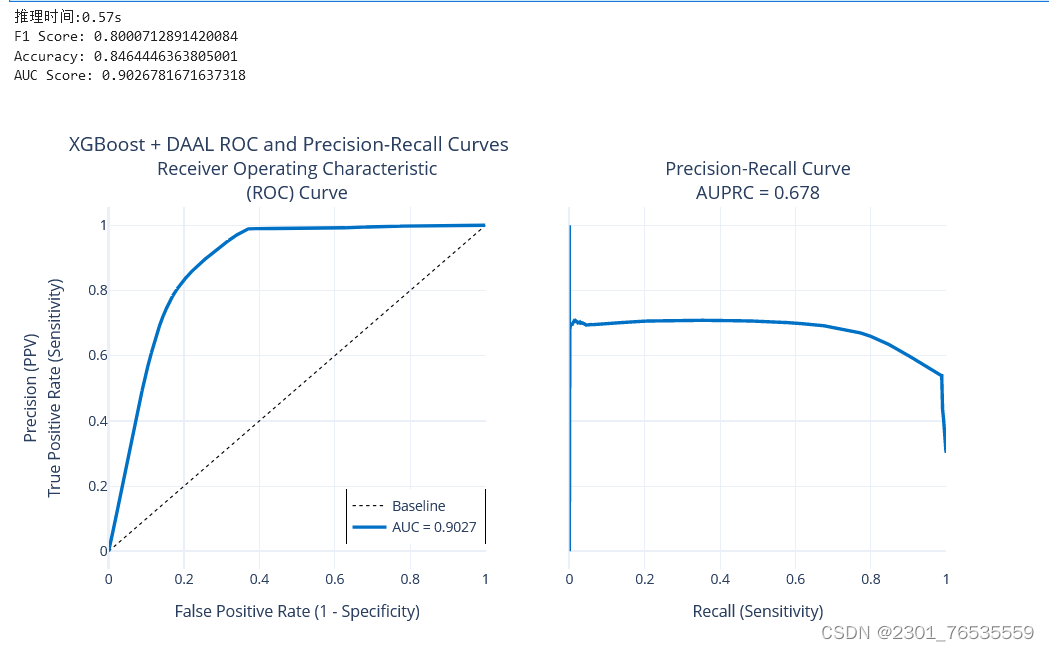
3 总结
基于机器学习的淡水质量预测为解决当今水质问题提供了重要的解决途径。通过采用先进的算法和工具,如XGBClassifier算法和Intel的OneAPI工具包,我们能够构建高效、准确的预测模型。推理时间可缩短至0.56s,F1指标可达到0.9。
这些模型不仅能够及时监测水质变化,还能够预测未来的水质情况,为环境保护和水资源管理提供有力支持。随着城市化和工业化的不断发展,淡水质量问题日益突显,因此,机器学习技术的应用对于保障环境和人类健康具有重要意义。综上所述,基于机器学习的淡水质量预测是解决当今水质问题的有效手段,也是推动可持续发展的重要举措。

















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









