







(
CVPR 2020|中科院VIPL实验室
)
1.要解决的问题:
基于类别标签的弱监督语义分割是一个具有挑战性的问题,类别响应图(class activation map,简称CAM)始终是这一领域的基础方法。但是由于强监督与弱监督信号之间存在差异,由类别标签生成的CAM无法很好地贴合物体边界。因为在强监督语义分割的数据增广阶段,像素层级标注和输入图像需经过相同的仿射变换,自此这种同变性约束被隐式地包含,而这种约束在只有类别标签的CAM的训练过程中是缺失的,类别标签没有变化,原数据data做了scale处理,因而会影响CAM的训练过程。
(CAM: 类别响应图,根据图像中的不同类别,来为图像中的不同物体打分,一般是前景图高分,后景图低分,以此来生成的热力图)
2.贡献:
1
.提出self-supervised equivariant attention mechanism (SEAM)模型,结合pixel correlation module(PCM) ,减少了全监督与弱监督的gap.
2.利用(ECR)loss 优化了孪生网络(两个相同网络共享权重)
3.在主流数据集PASCAL VOC 2012刷到了 state-of-the-art performance
3.解决方法:
PCM结构:
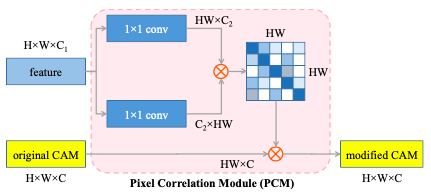
CAM 模块是kaiming 的Non-local 变体,这里的PCM是CAM的一个变体,去掉了残差连接,也去掉了g,ϕ,这里只使用了2个conv, 可以降低参数,意在防止过拟合。但仍保持和原始CAM相同的激活强度,使用ReLU和L1正则化去标记不相关的像素值,并且产生一个包含像素相关性的特征图。
PCM意在使得那些rescale后的图像,在弱监督训练时,仍能保证与原始图像拥有同样的信息(不会造成个别信息的丢失)。
SEAM结构:

孪生网络共享权重,对输入数据做不同的rescale,得到不同图像,再输入到网络中。
对于不同 transform 的数据,同时输入到孪生网络中,得到 y0(original), yt(transformed),再做后续的Loss计算。
网络的loss如下:
分类损失 Lcls, 使用了multi-label soft margin loss,Lcls是通过监督学习的方式来确定目标的位置。
通过一个全局平均池化层,生成向量Z0, Zt. l 是图像的类别标签,这个分类的loss计算在这两个分支上:
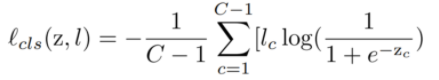
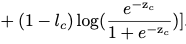
C类别数目, C-1是减去背景, lc 是第C个类别的label, z 是要预测的vector
The equivariant regularization (ER) loss:
A(.)任何特殊的变换 scale,
对网络处理后的数据y0在做transformed操作,与yt做L1正则化,目的是为了进一步缩小transformed后的数据与原始数据间的差异。
孪生网络是一个 shared-weight siamese structure,输出的两个分支的特征图共同保证CAM的一致性
equivariant cross regularization (ECR) loss:
一开始输入 y0, yt, 但训练很快陷入到局部最优,容易导致多数的像素点都只变为一类,所以最后设置成四个都输入,达到相互制约的目的。
4.实验:
在 PASCAL VOC 2012 dataset with 21 class annotations,20 foreground ob- jects and the background
1464 training
1449 validation
1456 testing
使用SBG(Semantic contours from inverse detectors)的annotations 增强数据到10582
实验结果:


















 4519
4519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









