






目录
本文记录弱监督语义分割领域论文笔记《L2G: A Simple Local-to-Global Knowledge Transfer Framework for Weakly Supervised Semantic Segmenta》
文章发布于 2022/04/07 CVPR2022
官方pytorch代码 https://github.com/PengtaoJiang/L2G
文章概述
本文的研究领域为弱监督语义分割,这个方面的相关基础知识可以看我之前的博客,重点是CAM的理解和弱监督的含义,就不再赘述了。
作者的baseline仍然是使用分类网络进行类激活映射,来利用image-level的标注信息,生成伪标签然后去直接训练分割网络。但是他指出,传统的CAM生成的伪标签会丢失很多细节信息,所以训练时把原图进行裁剪生成若干个patches(文中提供了随机裁剪和均匀裁剪两种方式),把这些局部视野像全局视野那样去训练,因为局部视野激活后往往含有更加细节的信息,全局和局部融合之后可以得到更加细节的伪标签。可以看出,本文的目标是训练主干分类网络,使其能生成更好的CAM图,他们提出了两种Loss来实现这个架构。
其实还可以看出,这个实验的基础是已经有一个已经很好的分类模型,所以ImageNet的预训练模型是一定要有的,因为这样才能使训练专注于对CAM的效果优化。文中也提到,这个过程只需要十几个epoch即可。
很多的弱监督语义分割的思路是分成Seed、Expand和Constrain,这个可以参考文章:《Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation》
其实这也是本文的思路,只是文中没有明确的提出,剖析来看:
- 使用传统的CAM,这是就是产生种子Seed的过程。
- 通过多个局部视野的激活去丰富全局视野激活后的细节,这不正是Expand的过程吗。
- 文中为了结果中让目标的轮廓更清晰,增加了显著性检测模块,这就是Constrain。
需要注意的是作者在文中描述的分类网络最后没有全连接层(我之前看的文章都是有的),主干网络最后仅是feature maps全局池化后输出一个feature vector,也是最后的概率向量,代表当前输入输入每个类的概率值。如果是n个目标的分类,那么最后的feature maps的通道数也应该是n(这里忽略说背景是否属于一类),feature maps的第c个通道直接就是独属于第c类的特征图,然后CAM的公式如下:

网络架构
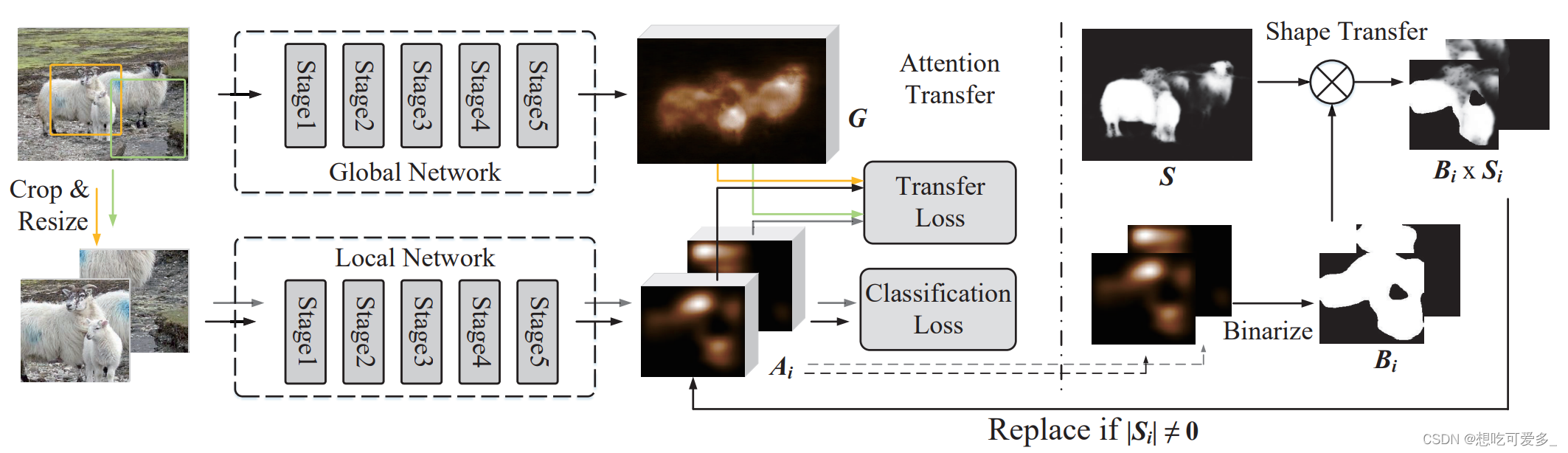
从左往右看,上面是用于全局视野的分类网络,下面是局部视野的分类网络(作者采用了ResNet,并且指出两个分类网络可不同,且使用不同的分类网络时结果有提升)。上下两个分类网络最后都使用CAM进行激活,然后将局部和全局融合后会产生损失,对损失优化后梯度会传播回两个分类主干网络,这会使分类网络最后经过CAM激活后的结果有更多的细节。下面对图中的三种损失逐个介绍。
Classification Loss
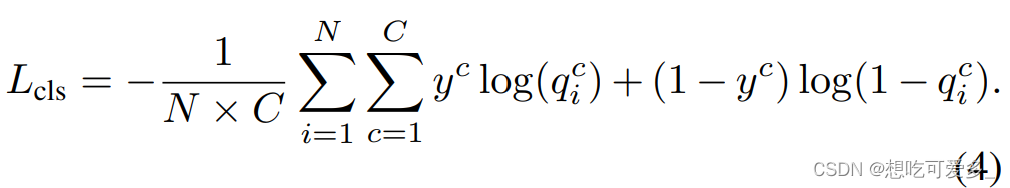
输入图片为 ,定义全局视野为
,N个局部视野为
。由全局视野得到的feature maps为
,局部视野得到的feature maps为
,经过全局池化后生成的feature vector用
表示,最后经过sigmoid函数变成最后输出的概率向量
。
然后看这个损失,他是对每个局部视野输出的概率向量和标注文件的multi-hot向量求交叉熵,随着损失优化,每个局部视野对于被标注类的概率输出会增大。
比如说一张图片里是一头牛,然后我把图片裁剪成若干个patches,使用这个损失,在把patches输入到分类网络时,也能够分辨出有一头牛。
很明显这里有一个问题,patches和整张图片的多分类结果是一样的吗,不一定,说不定有的类别被裁处去了呢,分类这个领域我懂得不是很多,大家可以一起讨论一下。不过根据实验数据,输入尺寸是448 x 448,patch的尺寸是320 x 320,这个patch还是挺大的,被裁掉的概率比较小?
Attention Transfer Loss
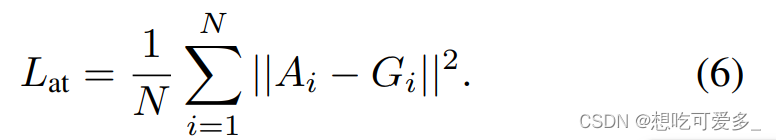

N个局部视野的feature maps经过CAM激活之后生成c个
,上标c代表对第c类的激活,注意没有被标注的类激活后是全0。
看公式6,对全局视野的特征图激活后会在通道方向做softmax回归,使特征图的所有的值呈现概率样式,C+1类是考虑了背景。
为什么这里使用softmax而前面却使用sigmoid? 结论是sigmoid的不考虑概率和为1,每个位置输出的概率范围是0到1即可,类与类之间没有抑制关系,用于多标签分类任务。 而softmax输出的向量中概率和为1,类与类之间有抑制关系,用于单标签分类任务。
在通道方向做softmax,即每一组softmax输入是各特征图同一位置的不同通道,显然同一位置的像素只能属于一个类别,所以用softmax。 而之前局部视野的概率输出向量中,因为局部视野可能有多个类,所以用sigmoid。
对于图片中的某个区域,采用局部视野相比于采用全局视野信息更加丰富,所以在某区域我们希望把局部视野的信息传递给全局视野
。所以看损失公式6,让两个分布的距离减小,就是让全局视野学习局部视野的信息。
这里运用了Online Learning的思想,局部信息传递给全局这个过程是随着训练同步地源源不断地。
Shape Tansfer Loss

这个公式其实是对Attention Transfer Loss的扩充,当等于零的话还和之前一样,但若不等于零就要采用另一种损失,来看看
是什么。
开头提到主流的弱监督语义分割最后会加入Constrain这个步骤,更好的塑造边界,这里也不例外。作者借用的显著图saliency map来完成,的样子可以看下面的图,他提供了很好的边界信息。具体的显著模型可以参考论文的引用《Railroad is not a train: Saliency as pseudo-pixel supervision for weakly supervised semantic segmentatio》《A simple pooling-based design for realtime salient object detection》
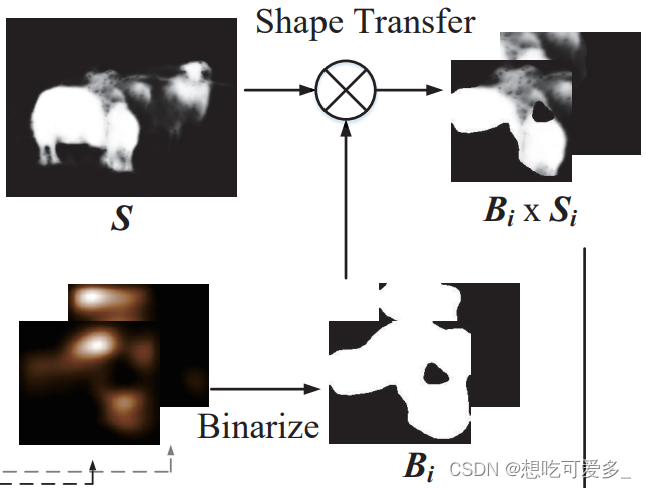
首先对之前的局部激活图Ai选定阈值二值化(0-1)处理成Bi,把Bi和Si做一个element-wise的乘积,因为显著图S目标边界之外都是0,这样就把Bi中目标的边界之外给“抹平”了。图中可以看出这么处理后边界明显平滑了。
之后把Bi x Si直接替换到Attention Transfer Loss的Ai即可,直接植入边界信息。因为显著图不是每张图片都会有的,所以只对有显著图的图片(即Si不等于0)做处理。
相关讨论
1、对原图进行裁剪这个思路看上去有点像分类中的滑动窗口。不过作者指出,裁剪的目的是挖掘那些原本不太被关注但是属于目标的区域(称为non-discriminative);而分类网络的滑动窗口仍然是以全局视野的网络为基础,关注的仍是最关键的区域(称为discriminative),无法实现我们的目的。
2、为什么不在全局视野的分类网络上产生classification loss?类似上一个问题,因为本文的目的是挖掘non-discriminative区域,这么做的话会促进全局视野分类网络更加关注重点的区域,与其目的背道而驰,我们要的是他把一部分注意力分散到周边那些不太被关注但是属于目标的区域。
3、本文进对分类网络训练,所以整个架构是可以被轻松移植的修改的,作者指出,分类主干网络如果换成更先进的架构比如ViT话可能有更进一步的提升。
看过代码后补充几个点:
1、如何把局部网络的信息传递给全局网络。代码中把局部网络输出的CAM做成了分割标签,然后使用MaskRCNN中RoiAlign的思路去把patch对齐,以补丁的方式训练全局网络。对局部网络的输出调用了clone().detach(),所以这个操作不涉及局部网络的参数更新,仅会训练到全局网络。
2、其实也可以认为,全局网络如果忽略最后的概率向量层,他就是一个用局部伪分割标签训练的分割网络,这个局部伪分割标签随着局部分类网络的收敛会越来越好。而局部网络就是只用image-level标签训练的分类网络。从梯度传播的角度来看,两个网络上是独立训练的,他们的联系只是说全局网络的标注是来自于局部网络输出。
3、文中交代它的模型使用了《Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation》中的PCM块,他是怎么做的呢:主干用的残差网络是一系列的卷积层,作者用 倒数第二层+倒数第三层+网络输入(下采样保证一样大),在通道数拼接,求得自注意力(QK),把这个注意力在和残差网络的最后一层相乘(QKV),得到最后得输出,代码中会阻止QK的参数更新。PCM块可以让网络能学习到形状上的不变性。















 1743
1743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









