






目录
本文记录弱监督语义分割领域论文笔记 《Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation》
文章发布于 CVPR2022
官方pytorch代码 https://github.com/zhaozhengChen/ReCAM
文章概述
本文研究领域为弱监督语义分割,遵从目前主流的研究思路:
- 使用图片级多分类标注文件,训练多分类模型
- 获取CAM激活图作为种子区域——Seed Generation,然后据此生成伪标签——Mask Generation
- 把伪标签当作ground-truth直接训练分割网络
本文重点在于Seed Generation以及Loss函数的调整,其余技术均借鉴其他研究成果。下图为第二个步骤,Seed Generation采用本文独创的ReCAM,图中Mask Generation展示了多种可选方法。第一、三步骤直接引用常规模型。
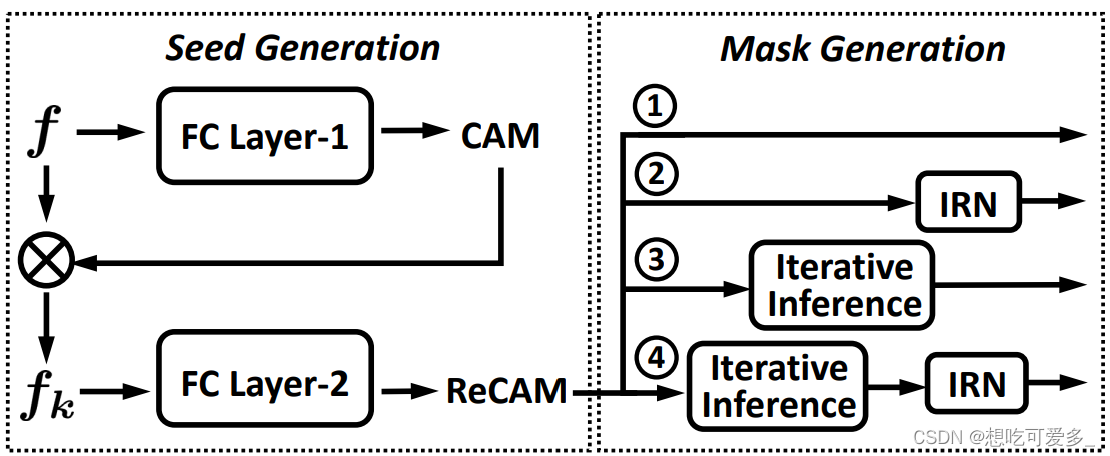
提出了传统CAM的两大缺点,并以此为基础展开研究:
- 被标注类之间的误分类(针对标注类之间)。
- 目标区域被误当作背景(针对标注类和未标注类之间)。
网络架构
CAM(类激活映射)
参考链接《如何利用CAM(类激活图)动态可视化模型的学习过程》
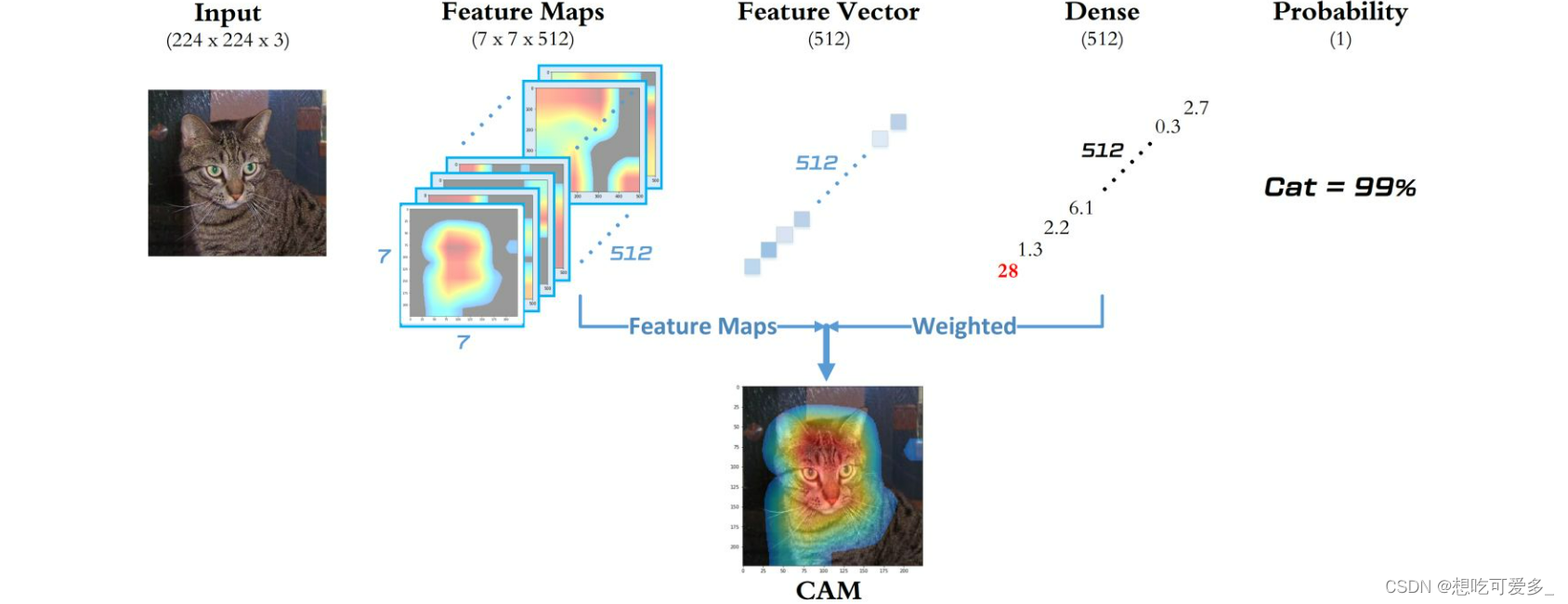
我们先来重新了解一下这里的分类网络。
- 我们的输入首先会经过经过特征提取主干网络(e.g.VGG,本文使用了ResNet-50),这时会得到 Feature Maps,假定有C个通道,就代表我们得到了 C 层特征图。
- 之后把每个通道的之 H x W 个特征做全局平均池化池化 GAP ,得到 1 x 1 x C 的 Feature Vectors,相当于把每个特征曾浓缩。
- 最后会加入一个全连接层 FC,如果说我们训练集包含20个类别(上图中是单分类任务,只包含一个类别),就把这个特征向量和一个权重矩阵 W 做矩阵乘法,得到一个20维的向量,对这个向量进行softmax回归使每个元素呈现为概率的形式(元素和为1),概率就是最后对图片进行分类的依据。
这里的全连接层权重W代表什么含义呢?从特征向量到最后的概率向量,可见W是为对特征向量进行加权得到各个类的概率,而特征向量从特征图而来,也就说明了W是为各个类选择合适的特征层并加权,通过训练W,对特征层的选择会越来越准确。
引用一下参考链接的例子:“假设对于一张猫咪的图片,刚开始训练时,由于 W 的值刚刚初始化,此时模型听信 W 矩阵,选择了第10/20/30号特征图作为判断依据,判断图像 84% 是狗。由于这么预测的Loss很大,因此在后续反向传播的时候不断更新 W 矩阵,开始逐渐以第99/100/101号等特征图作为判断依据,直到能够判断图像 100% 是猫的时候,模型基本上就学会了如何判断猫狗”。
每一张特征层包含了相应特征的位置等信息,当我们得到一个良好的分类模型时,通过 Feature Maps 以及全连接层权重 W 就能够知道模型在分类时的依据是什么,我们对这种“依据”进行量化,生成热力图可视化出来(e.g.对于猫的图片,热力图中猫耳朵等重要标志位置颜色会很深),这就是我们说的CAM。而热力图的深色区域不正好和语义分割的标注文件具有同样的效果吗,因此CAM就被广泛应用于伪标签的生成,当然这种标签是极度粗糙的。
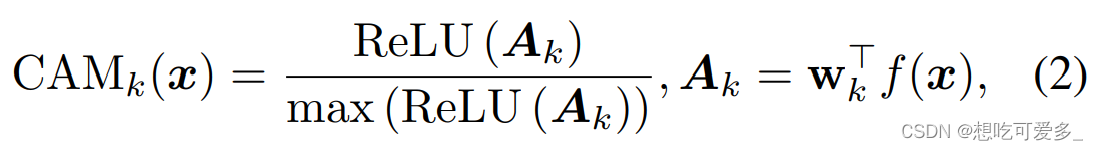
上图公式中的 f(x) 是特征图,对于第 k 类(通过矩阵的运算规则,我们是可以逐类的生成CAM热力图),把特征图直接和全连接层权重相乘,得到第 k 类初步的激活图 Ak,ReLu(Ak) 可以摒弃掉负值(负值代表了相应位置与第 k 类基本无关,因此直接归零,因为生成热力图的话不能有负值),除以 max(ReLu(Ak)) 归一化使激活图取值于 [0, 1] ,生成一个 0-1 mask,这是为了生成热力图处理的,值越大,颜色越深,相应位置越重要。
CAMk是第 k 类的激活图,同一张图片对标注中有的每一类都会有生成一张激活图(本文构思的关键:class-exclusive)。
至此,“种子”部分就生成了。
ReCAM(第二次激活)
上面讲解了最原始的CAM是如何操作的,本文核心是连续使用两次CAM进行再激活,下面我们来看是怎么做到的。

直接看示意图,在我们做第一次CAM时使用了主干网络生成的 Feature Maps 记作 f(W x H x C),假定标注中该输入有 j 类,然后生成了 j 张激活图 CAMk 记作 Mk(k<=j<=n)。
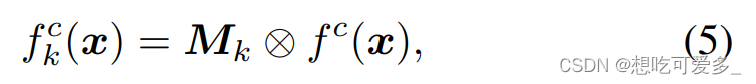
现在根据公式(5),我们把第 k 类的激活图 Mk 和 f 的 C 个通道逐个做对应像素相乘(⊗ 代表pixel-wise的乘法),然后生成 fk。标注中有的每类都要做一次,这样会得到 j 个 fk(f1, f2, f3, ...)。
如果说之前的特征图 f,是为多分类任务服务的。那么经过上面的操作,每一张 fk 就只重点负责对第 k 类分类,这时多分类任务就变成了若干个个单分类任务。
这么做有什么道理呢?前面说特征图包含了每个特征的位置等信息,CAM激活图 Mk 通过某些位置更深的像素值,来表明相应位置具有当前类的重要特征。当两者进行元素间的相乘后,相当于在特征图中把具有第 k 类特征的部分赋予更高的注意力,对 f 做了一个关于第 k 类的“激活”,得到 fk。
之后的步骤大致和CAM相同,但是这时候因为有 j 张特征图,因此需要做 j 次ReCAM。
损失函数
BCE(binary cross entropy)
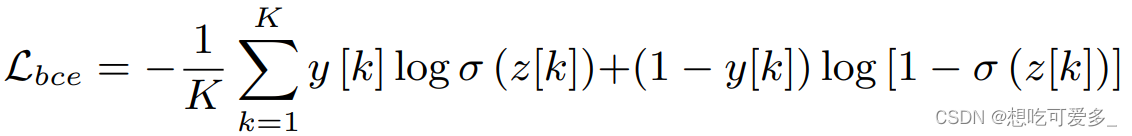
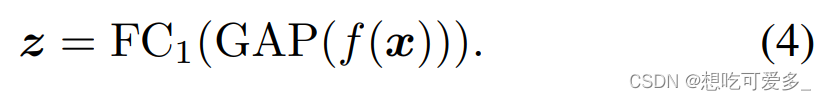
BCE-Loss被用于第一次CAM,训练全连接层 FC1 的权重 W1,主干网络冻结不参与训练。
BCE原本是用于二分类,本文用于了多分类任务。z = FC1( GAP( f( x ) ) ) 是我们最后输出的预测向量,会通过一个sigmoid函数,假设有 n 个类别,那么 z 的长度为 n ;y就是 multi-hot 标注向量,是一个由0和1组成的 n 维向量,1代表相应类别存在图片中,0代表没有。
使用BCE损失,既能相互独立地促进被标注的类别,也能相互独立地抑制没有被标注的类别,文中将这种特性描述为non-exclusive,是一种在多分类中会出现的现象,并指出了他的优缺点:
- 因为一个类个激活并不影响另一类的激活,这可能会导致错误的分类(比如某区域属于A,且A、B都有标注,因为A的激活不会抑制B的激活,这时有可能A被错误当作B)
- 因为所有被标注的类被平等的激活,导致激活能力被分散,使部分区域应被激活但未被激活
SCE(softmax cross entropy)
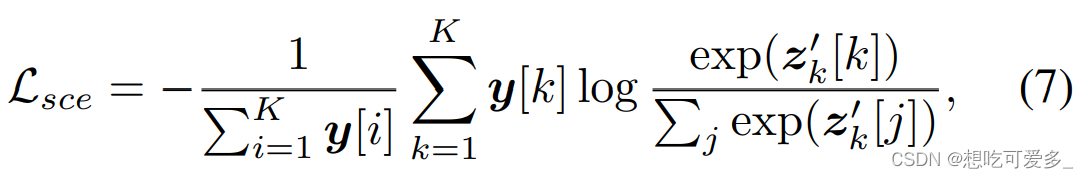
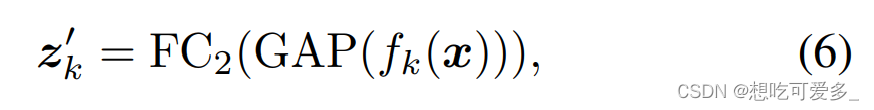
SCE-Loss被用于ReCAM阶段,但是它的梯度会传到整个网络进行训练:FC1 的 W1、FC2 的 W2、主干网络。之所以不仅仅训练 FC2,是因为有可能主干网络的特征图和第一次CAM生成的mask并不理想。同时也可以看出整个网络都是反向传播的,所有处理都是soft,没有任何阈值。
式子预测向量进行softmax操作(SCE = softmax + CE,softmax可以理解为是网络的一部分,也可以当作损失的一部分)。这里使用的标注文件是 one-hot,也就是标注向量中只有一个1,其余全是0,因为在ReCAM阶段我们把多分类任务转换成了多个单分类任务。所以SCE训练时具有 class-exclusive 的特性。
这种损失带来的性质有:
- 每个类之间独立激活,对于被标注的类激活能力更强,模型收敛能力比BCE更强
- 因为使用了softmax,所以计算梯度时没有被标注的类的预测值也参与了计算,所以仍然具有抑制未被标注类的能力
文章动机(重点)
We proposed a simple yet effective method named ReCAM by plugging SCE into the BCE-based model to reactivate the model.
这是文章的总结语:使用SCE损失函数来构建ReCAM网络架构。
其中的核心是对损失函数从BCE->SCE的思考。
文中首先指出了CAM因为使用BCE损失函数的两个缺陷:1、被标注类之间的误分类(针对标注类之间)。 2、目标区域被误当作背景(针对标注类和未标注类之间)。
- 第一个问题,归结为 non-exclusive。也就是说在我们传播梯度想要对某一类激活时(也就是提升相应的预测值),如果使用BCE,会忽视对其他被标注类的抑制效果。而我们想要做到 class-exclusive,让我们“集中火力”对相应类激活,防止“火力分散”。 这时就需要使用 CE(不使用softmax的SCE)损失函数,但是 CE 损失函数相应的标注文件 y 必须 one-hot(对应单标签多分类任务) 格式,因为如果使用 multi-hot(对于多标签多分类任务) 标注的话,通过公式的观察 ,CE 函数就失去了“独立激活“的能力——所以 CE 损失必须配合one-hot编码。 这不就对应上了我们为什么要进行ReCAM然后把Feature Maps 逐类激活生成 f1, f2, f3, ....。所以说 ReCAM除了本身具有相较于CAM的优势,它的核心是为了服务于 CE/SCE 损失函数。
- 上一点我们一直说的是 CE 损失,现在来看为什么要加上softmax变成SCE。因为从BCE到CE无法解决第二个缺陷,我们需要抑制未被标注类的激活。 通过式子观察 BCE 对预测向量使用的是sigmoid函数,把每个预测值映射到 [0, 1] 之间,但这种处理没有对预测值之间建立联系,更谈不上抑制效果了。 但是当我们使用sofmax回归时,每个预测量会除以总体的和,此时所有需要被抑制的类的预测值会出现在分母上,刚好可以满足这个目的。
- 实验中作者采用了综合SCE和BCE的办法:Loss-ReCAM = Loss-bce + λ Loss-sce,λ是平衡系数。
以上只是经验论断,文中给出了从数学公式上的理解。
这个基于SCE-ReCAM的模块支持plug-and-play热插拔,可以直接植入很多基于CAM的模型。
因此作者从:BCE对比CE、ReCAM+优化(e.g.ReCAM+AdvCAM)、CAM-based+ReCAM、后续的Mask Generation网络、后续的Semantic Segmentation等角度做了大量的实验,大家可以浏览原文。














 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









