






kmeans聚类,肘部法确定聚类个数
代码对数据先进行归一化然后聚类
可设定聚类个数范围,根据肘部法选择合适的聚类个数
可求得每类的具体数据
matlab代码,备注清楚,更改为自己的数据和要求即可
ID:8750705318262195
Matlab编程
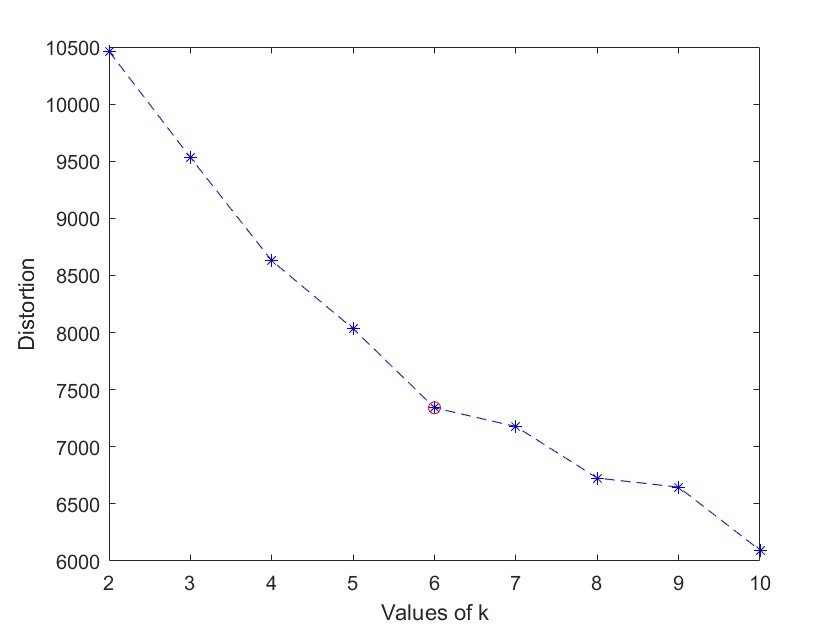
k-means聚类是一种经典的无监督学习算法,可以对数据进行聚类分析,将相似的样本归为一类。在实际应用中,确定聚类个数是一个重要的问题,而肘部法(elbow method)是一种常用的确定聚类个数的方法。
首先,我们需要对数据进行归一化处理,以保证不同特征的数值范围一致。这样可以避免由于数值差异过大而导致的聚类结果失真。归一化后的数据可以提高聚类算法的准确度。
在进行聚类分析前,我们可以设定一个聚类个数的范围,例如从2到10。然后,对每个聚类个数进行聚类分析,并计算相应的聚类性能指标。其中,肘部法是一种常用的指标,可以帮助我们确定最佳的聚类个数。
肘部法的基本思想是,随着聚类个数的增加,聚类性能指标会逐渐降低。但是,当聚类个数达到一定程度后,性能指标的下降速度会明显减缓。这个拐点就是我们所说的“肘部”,也是最佳聚类个数的选择。
具体来说,我们可以通过计算聚类误差来衡量聚类性能。聚类误差是每个样本与其所在聚类中心的距离的平方和。肘部法就是通过观察聚类误差与聚类个数的关系来确定最佳的聚类个数。
在使用k-means进行聚类分析时,我们可以借助MATLAB提供的相关函数来实现。首先,我们需要将代码中的数据和要求进行更改,以适应自己的数据集。然后,运行代码,即可得到每个类别的具体数据。
为了更好地理解代码,我们需要在代码中添加清晰的备注。这样可以帮助他人更快地理解代码的功能和逻辑,并进行相应的修改。
总结起来,k-means聚类算法是一种强大的工具,可以对数据进行有效的聚类分析。通过肘部法确定最佳的聚类个数,我们可以得到每个类别的具体数据。在使用MATLAB进行代码实现时,我们需要对数据进行归一化处理,然后根据肘部法选择合适的聚类个数。在代码中添加清晰的备注,并根据自己的数据和要求进行相应的更改,即可得到准确且具有实际意义的聚类结果。
【相关代码,程序地址】:http://fansik.cn/705318262195.html
















 4103
4103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









