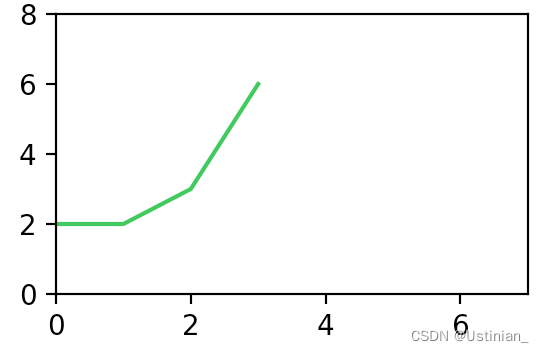
选中的序列
需要做匹配的所有序列

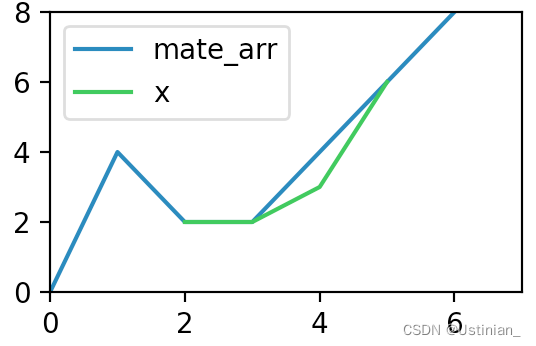
匹配结果
输入
def mate(cls,x:list,a_list:list,n=1,accurate_matching=True,normalization=False)
- x: 选择的序列
- a_list: 需要进行匹配的所有序列(二维列表)
- n: 返回匹配度最高的n个
- accurate_matching: 是否精确匹配(选择的序列点个数和匹配到的点个数相等)
- normalization: 是否做归一化处理(True将只考虑序列形状)
输出
[{'mate_arr': [2, 2, 4, 6], 'index': 2, 'mate_range': (2, 6), 'd': 1.0}]
- mate_arr : 命中的序列值
- index :命中的第几条序列
- mate_range:命中的序列的范围
- d:距离,值越小,匹配度越高
源码
import numpy as np
from dtw import dtw
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['STSong']
plt.rcParams['axes.unicode_minus'] = False
class MateCurve:
@classmethod
def mate(cls,x:list,a_list:list,n=1,accurate_matching=True,normalization=False):
"""
序列匹配
:param x: 选择的序列
:param a_list: 需要进行匹配的所有序列(二维列表)
:param n: 返回匹配度最高的n个
:param accurate_matching: 是否精确匹配(选择的序列点个数和匹配到的点个数相等)
:param normalization: 是否做归一化处理(True将只考虑序列形状)
:return mate_list: 匹配到的序列
"""
#曼哈顿距离定义,各点相减的绝对值
manhattan_distance = lambda x, y: np.abs(x - y)
# 转ndarray提升速度
x = np.array(x)
a_list = np.array(a_list,dtype=object)
len_x = len(x)
mate_list = []
for index,a in enumerate(a_list):
len_a = len(a)
if len_a>len_x and accurate_matching:
# 精确匹配,循环切片获得与选择序列点数相等的长度
for i in range(1,len_a-len_x+1):
a_split = a[len_a-len_x-i:len_a-i]
mate_range = (len_a-len_x-i,len_a-i)
mate_dic = {"mate_arr":a_split}
# 归一化处理
a_split = cls.maxminnorm(a_split) if normalization else a_split
# 计算出总距离,耗费矩阵,累计耗费矩阵,在矩阵上的路径
d, cost_matrix, acc_cost_matrix, path = dtw(a_split, x, dist=manhattan_distance)
mate_dic["index"] = index
mate_dic["d"] = d
mate_dic["mate_range"] = mate_range
mate_list.append(mate_dic)
else:
mate_dic = {"mate_arr":a}
# 归一化处理
a = cls.maxminnorm(a) if normalization else a
#计算出总距离,耗费矩阵,累计耗费矩阵,在矩阵上的路径
d, cost_matrix, acc_cost_matrix, path = dtw(a, x, dist=manhattan_distance)
mate_dic["index"] = index
mate_dic["d"] = d
mate_dic["mate_range"] = [0,len_a]
mate_list.append(mate_dic)
# 按照总距离排序,距离越小,匹配度越高
mate_list.sort(key=lambda s: s["d"])
return mate_list[:n]
@classmethod
def maxminnorm(cls,array):
"""
一维数组归一化(最小值为0,最大值为1)
:param array: 需要归一化的一维数组
:return t: 归一化后的一维数组
"""
array = np.array(array)
max = array.max()
min = array.min()
if min<0:
array = array-min
data_shape = array.shape
data_rows = data_shape[0]
t=np.empty((data_rows))
for i in range(data_rows):
t[i]=array[i]/(max)
return t
@classmethod
def biult_test_data(cls):
"""
构造测试数据
:return x: 选择的序列
:return a_list: 需要进行匹配的所有序列(二维列表)
"""
a1 = [0,5,2,2,4,5,2,7]
a2 = [0,1,4,3,3,8]
a3 = [0,4,2,2,4,6,8]
a4 = [1,2,4,5]
a_list = [a1,a2,a3,a4]
x = [2,2,3,6]
return x,a_list
if __name__=="__main__":
x,a_list = MateCurve.biult_test_data()
mate_list = MateCurve.mate(x,a_list)
print(mate_list)
fig,axs = plt.subplots(2,4,figsize=(14,4))
for i in range(2):
for j in range(4):
axs[i,j].set_xlim([0,7])
axs[i,j].set_ylim([0,8])
for i in range(4):
axs[0,i].plot(a_list[i])
axs[1,0].plot(x,color="#33c648")
axs[1,1].plot(a_list[mate_list[0]["index"]],label="mate_arr")
axs[1,1].plot(range(mate_list[0]["mate_range"][0],mate_list[0]["mate_range"][1]),x,label="x",color="#33c648")
axs[1,1].legend()
plt.show()






















 6875
6875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









