







 本文深入解析了2018年CVPR发表的级联金字塔网络(CPN)在多人姿态估计中的应用。CPN由GlobalNet和RefineNet两部分组成,解决了遮挡和复杂背景中的关键点检测难题。GlobalNet初步定位简单关键点,RefineNet则通过多层级特征融合精细化修正。文章还介绍了FPN和Mask R-CNN在人体检测中的作用,以及CPN在网络设计和训练策略上的创新,如在线困难关键点挖掘(OHKM)。在COCO数据集上,CPN取得了优异的性能表现。
本文深入解析了2018年CVPR发表的级联金字塔网络(CPN)在多人姿态估计中的应用。CPN由GlobalNet和RefineNet两部分组成,解决了遮挡和复杂背景中的关键点检测难题。GlobalNet初步定位简单关键点,RefineNet则通过多层级特征融合精细化修正。文章还介绍了FPN和Mask R-CNN在人体检测中的作用,以及CPN在网络设计和训练策略上的创新,如在线困难关键点挖掘(OHKM)。在COCO数据集上,CPN取得了优异的性能表现。
该论文发表在2018年CVPR上,用于多人姿态估计的级联金字塔网络
arxiv论文地址:https://arxiv.org/abs/1711.07319
github代码:https://github.com/GengDavid/pytorch-cpn,https://github.com/chenyilun95/tf-cpn
文档编辑参考:
1、论文笔记(CPN):Cascaded Pyramid Network for Multi-Person Pose Estimation
2、2018-CPN:Cascaded Pyramid Network for Multi-Person Pose Estimation - 知乎
一、背景
目前多人姿态估计中仍然存在的问题(hard” keypoints)(遮挡点,不可见点和拥挤的背景,是的人体关键点检测存在的问题),其原因归纳为两点:
1)只通过表层特征不能识别这些“难点”,例如:躯干点;
2)在训练过程中没有明确解决这些“难点”的检测问题;
因此,作者提出了一种新的网络结构,称为Cascaded Pyramid Network(CPN)级联金字塔网络,该网络可以有效缓解“hard” keypoints的检测问题,CPN网络分为两个阶段:GlobalNet和RefineNet。GlobalNet网络是一个特征金字塔网络,该网络用于定位简单的关键点,如眼睛和手等,但是对于遮挡点和不可见的点可能缺乏精确的定位;RefinNet网络该网络通过集合来自GolbalNet网络的多级别特征来明确解决“难点”的检测问题。
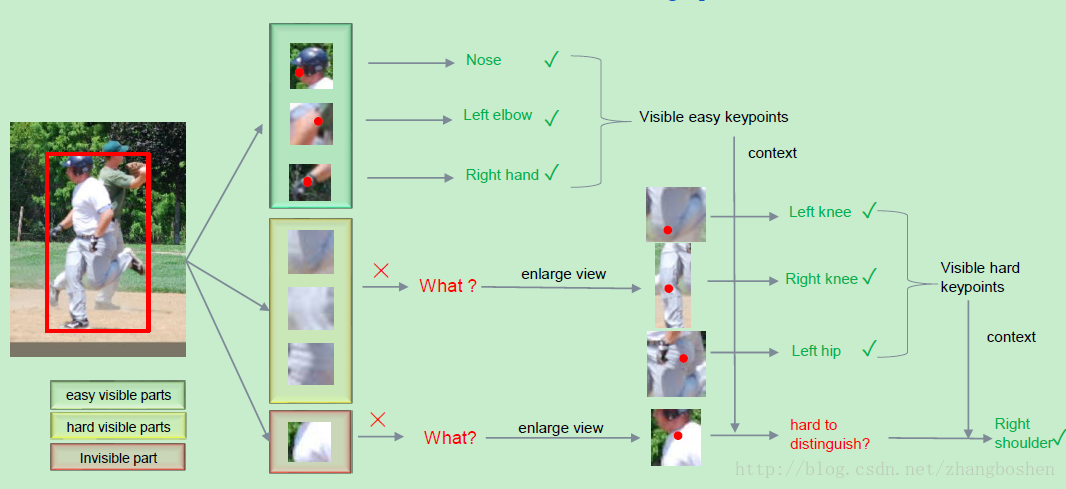
三大创新点:
- 提出了一个新的有效的网络:CPN,该网络由GlobalNet和RefineNet网络构成;
- 分析了在top-down结构中问题对于多人姿态估计产生影响的不同因素;
- 算法实现了在challenging COCO multi-persion keypoint benchmark数据集上的最好的结果,在test-dev dataset上达到73.0AP,在test challenge dataset 上达到72.1AP。
采用了top-down的路线:先在image上使用一个human detector得到人的bounding-boxes,然后再使用cpn网络进行关键点的检测;重点在cpn网络实现的关键点检测。
二、 Human Detector
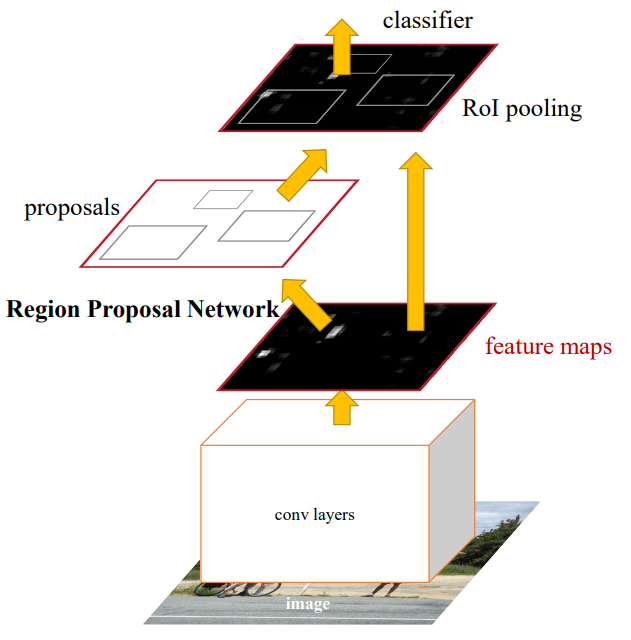
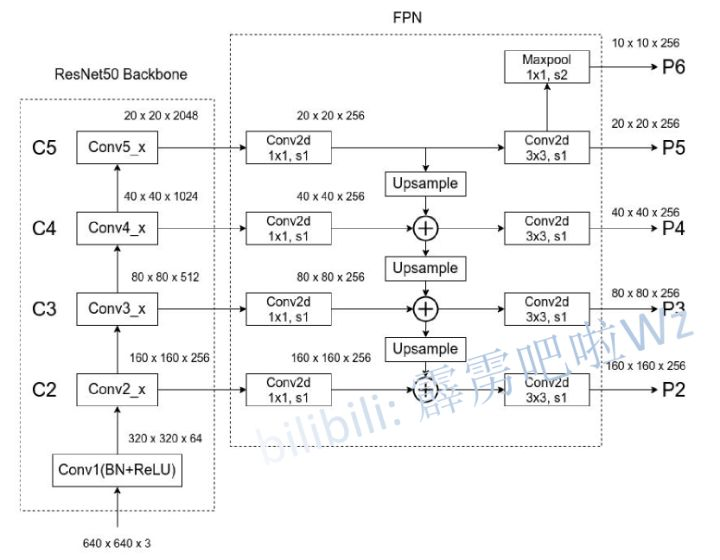
类似于 Mask R-CNN,CPN pipeline 也是自顶而下的:首先通过人体检测器根据图像生成一个边界框集合bounding-boxes;然后使用bounding-boxes对原图进行裁剪,并将裁剪后的结果用于CPN网络,接着通过单人关键点估计器预测每个人关键点的详细定位。采用基于 FPN 的当前最优物体检测器作为人体检测器,并用 Mask R-CNN ROIAlign 替代 FPN ROIPooling。
2.1 FPN
目标检测算法FPN(Feature Pyramid Networks)简介
FPN使用不同分辨率的特征图感知不同大小的物体,并通过连续上采样和跨层融合机制使输出特征兼具底层视觉信息和高层语义信息。低层次的特征图语义不够丰富,不能直接用于分类,而深层的特征更值得信赖。将侧向连接与自上而下的连接组合起来,就可以得到不同分辨率的特征图,而它们都包含了原来最深层特征图的语义信息。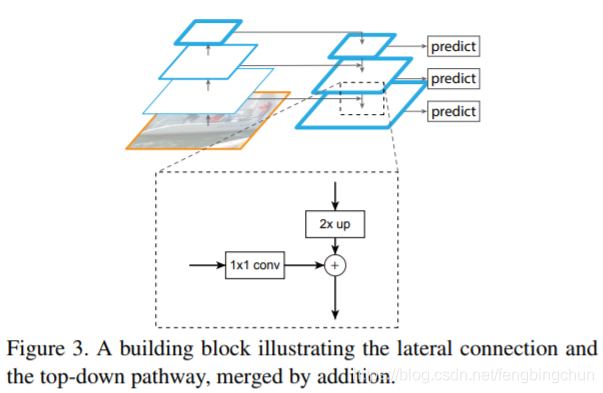
2.2 Mask R-CNN 回顾
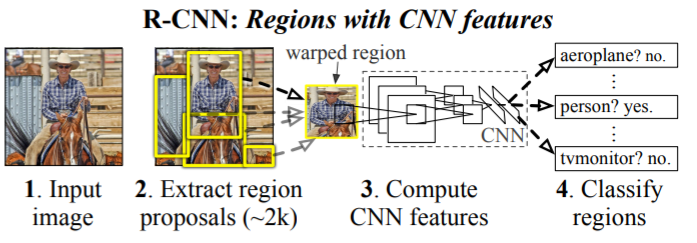
R-CNN
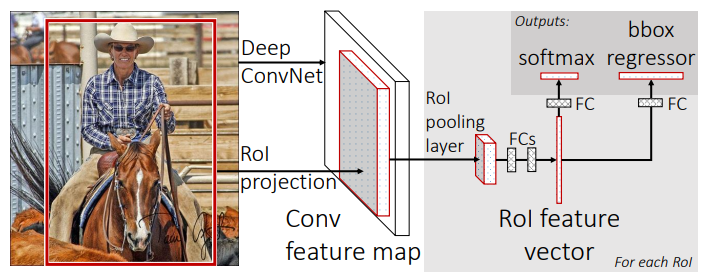
Fast R-CNN
Faster R-CNN
实现了与特征提取器网络共享卷积层的区域提案网络(RPN)
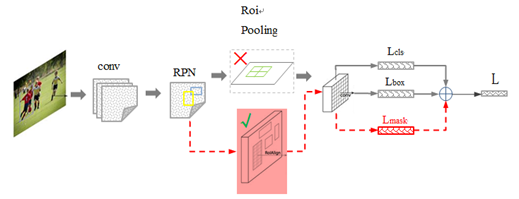
Mask R-CNN = Backbone+RPN+RoIAlign+(分类+回归+mask)
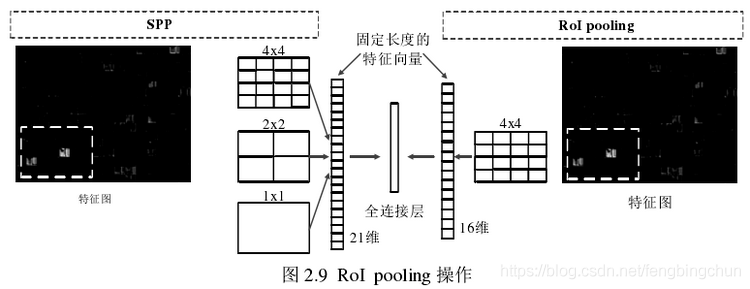
RoIAlign与RoIPooling参见 RoIPooling、RoIAlign笔记
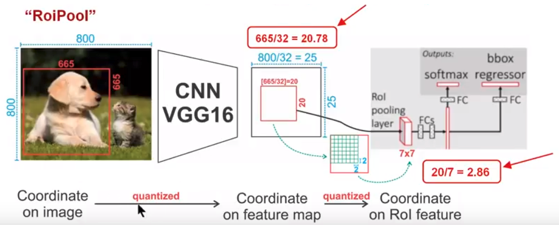
RoIPooling量化取整为最大值。
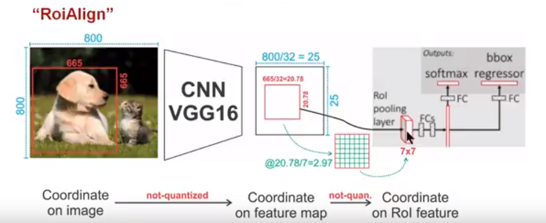
RoiAlign量化不取整,保持浮点数。
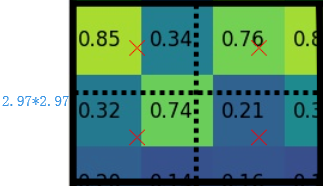
上图中,四个红色叉叉‘×’的像素值是通过双线性插值算法计算得到的
三、 cascaded Pyramid Network(CPN)
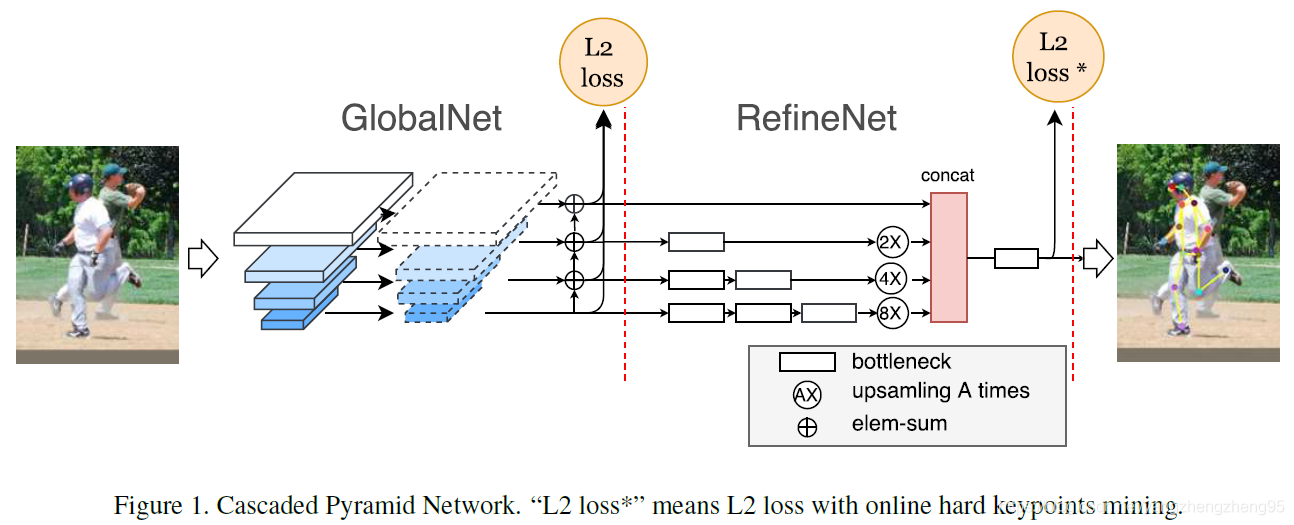
- 网络整体结构采用CPN(Cascaded Pyramid Network)结构,Cascaded指的是级联的意思,代表了网络级联了2个类似的模块(GolbalNet和RefineNet),Pyramid指的是类似于FPN的金字塔网络结构。
- 其中,GolbalNet负责网络所有关键点的检测,重点是对比较容易检测的眼睛,胳膊等部位的关键点预测效果较好,采用的损失函数为L2 loss。其中在每一个elem-sum操作之前,都对feature map使用了1*1的卷积操作。
- RefineNet指的是对GolbalNet预测的结果进行修正的网络。GolbalNet对身体部位的那些遮挡,看不见,或者有复杂背景的关键点预测误差较大,RefineNet则专门修正这些点。主要还是基于shortcut的思想。在该阶段的训练中,还使用了类似OHEM的online hard keypoints mining难例挖掘策略。
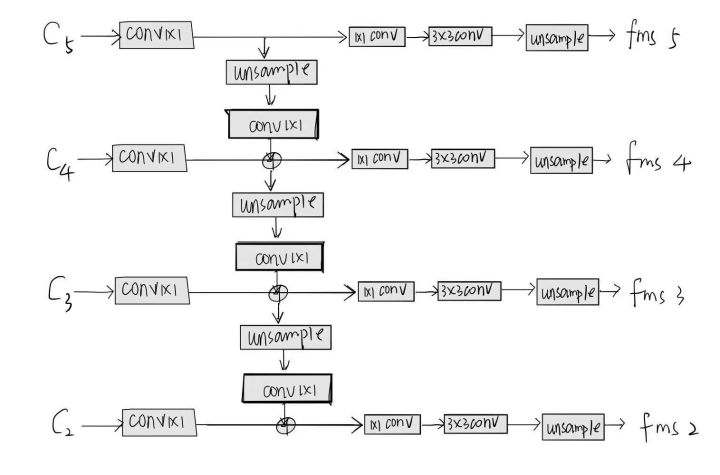
3.1 GolbalNet
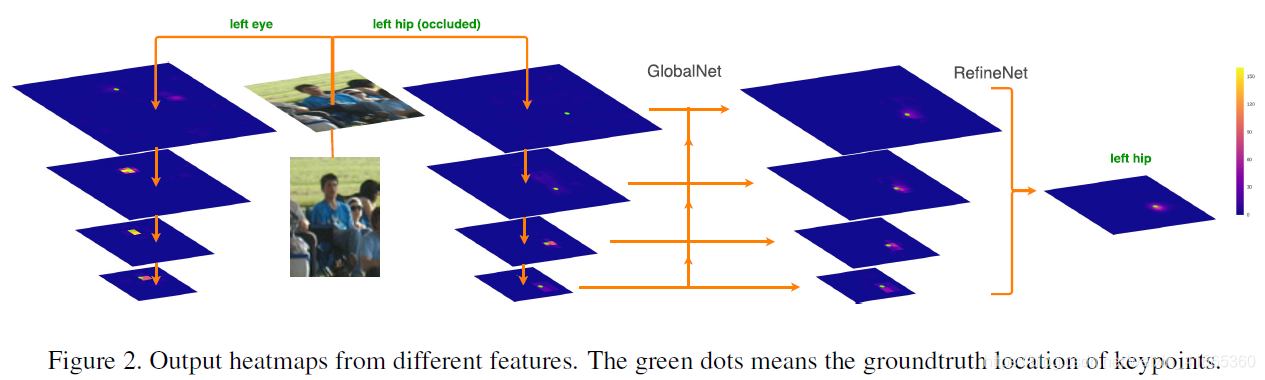
- CPN 的网络架构基于 ResNet。把不同卷积特征 conv2∼5 的最后残差块分别表示为 C_2 , C_3 , ..., C_5,并在其上应用 3 × 3 卷积滤波器生成关键点的热力图。如图所示,浅层特征比如C_2 , C_3 在定位上有着较高的空间分辨率,但是在识别上语义信息较少。另一方面,由于卷积(和池化),深度特征层比如 C_4,C_5 语义信息较多,但空间分辨率较低。因此经常引入 U 型结构同时保留特征层的空间分辨率和语义信息。
- 本文的关键点估计应用了特征金字塔结构。稍微不同于 FPN,在上采样的过程中,在逐像素加和之前使用 1 × 1 卷积核,而这一结构正是 GlobalNet。
- 如图所示,基于 ResNet backbone,GlobalNet 可有效定位简单的可见关键点(比如眼睛),却无法精确定位困难的隐藏关键点(臀部)。对臀部这类关键点的定位通常需要更多的语境信息和处理,而不是相邻的外观特征。很多情况下,单一 GlobalNet 无法直接识别这些“困难”点。
 在GlobalNet中,得到了四层特征图,作者通过给每一层特征图设计了不同的数量的botleneck块,再分别经过不同倍率的上采样,然后经过concat操作后,达到了对不同尺度特征的结合,最后经过一个bottlenet块,再经过简单的变换,得到网络的最终的输出。
在GlobalNet中,得到了四层特征图,作者通过给每一层特征图设计了不同的数量的botleneck块,再分别经过不同倍率的上采样,然后经过concat操作后,达到了对不同尺度特征的结合,最后经过一个bottlenet块,再经过简单的变换,得到网络的最终的输出。
3.2 RefineNet
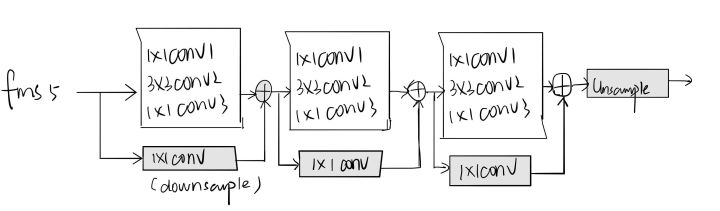
- GlobalNet 生成特征金字塔表征来识别“容易”点,RefineNet 则显式处理“困难”关键点。为提升信息传输的效率,保证信息完整性,RefineNet 在不同层之间传输信息,并通过像 HyperNet 一样的上采样和连接把这些信息整合起来。不同于 Stacked hourglass 的优化策略,RefineNet 接收了来自所有金字塔层的特征信息,而不是类似 hourglass 模块之间仅通过最后一个上采样特征进行信息传递。此外还把更多的 bottleneck 模块来处理更深的特征,其较小的空间尺度可实现效率和性能的良好权衡。
- 随着训练的进行,网络会倾向于关注占比较多的“简单”点,其重要性不及“困难”点,比如遮挡等情况,因此网络对两者的关注应该取得一个平衡。为此,RefineNet 根据训练损失在线地显式选择困难关键点(称之为在线困难关键点挖掘/ OHKM),并只从已选择的关键点反向传播梯度。

















 4049
4049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









