







1. 传统的CNN网络
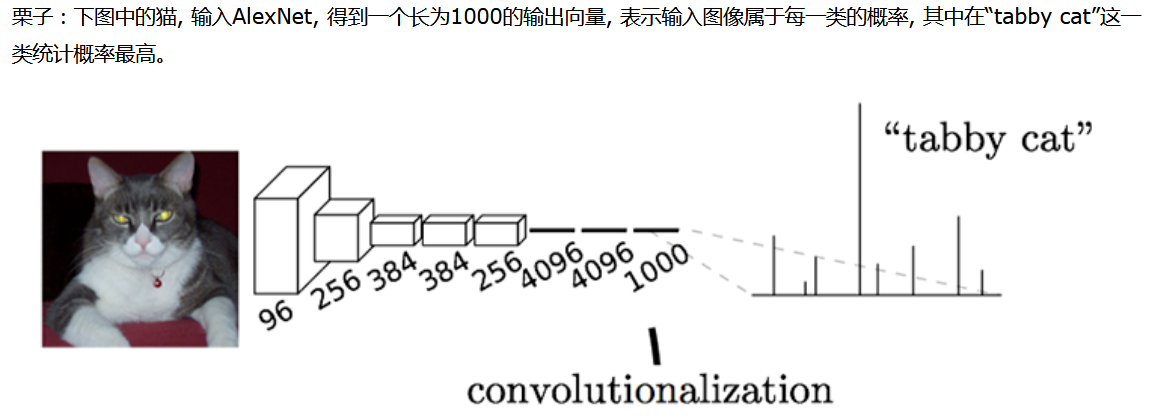
传统的CNN在卷积层之后会连接若干个全连接层,将卷积层产生的feature map映射成一个具有固定长度的特征向量。以AlexNet为例,卷基层后的全连接层有三层,第一层为4096*1,第二层为4096*1,第三层为输出层,大小为1000*1. 该结构适合于图像级别的分类和回归任务,因为最后希望得到整个输入图像的一个数值描述(分类概率),最后一层尺寸为1000*1,表示输入图像属于每一类的概率(softmax归一化)。
2. CNN的优势与劣势
CNN的多层结构能自动学习特征,并且可以学习到多个层次的特征:(1) 较浅的卷积层感知域较小,可以学习到一些局部区域的特征;(2)较深层的卷积具有较大的感知域,能够学习到一些更加抽象的特征,这些特征对物体的大小、位置、方向等敏感性更低,有助于识别分类,可以很好的判断出一副图像中包含什么物体,但是因为丢失了一些物体的细节,不能很好的给出物体的具体轮廓、指出每个像素具体属于哪个物体,因此做到精确分割是很难的。
3. 基于传统CNN的分割方法
为了对一个像素进行分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。这种方法的几个缺点:
(1)存储开销大:假设对每个像素使用的图像块大小为15*15,那么做图像块的滑动,会产生大量的滑动窗口,然后再对每个滑动窗口进行识别判断,因此所需的存储空间会因为滑动窗口的次数和大小不同而急剧上升。
(2) 计算效率低下:相邻的图像块有很多的重叠区域,因此针对每个滑动图像块都做卷积运算,是存在大量重复运算的。
(3) 像素块的大小限制了感知区域的大小:通常图像块的大小远小于整副图像的大小,只能提取一些局部特征,从而导致分类的性能受到限制。
FCN从抽象的特征中恢复出每个像素所属的类别,即从图像块级别的分类进一步细致到像素级别的分类。
3. 本篇主角FCN
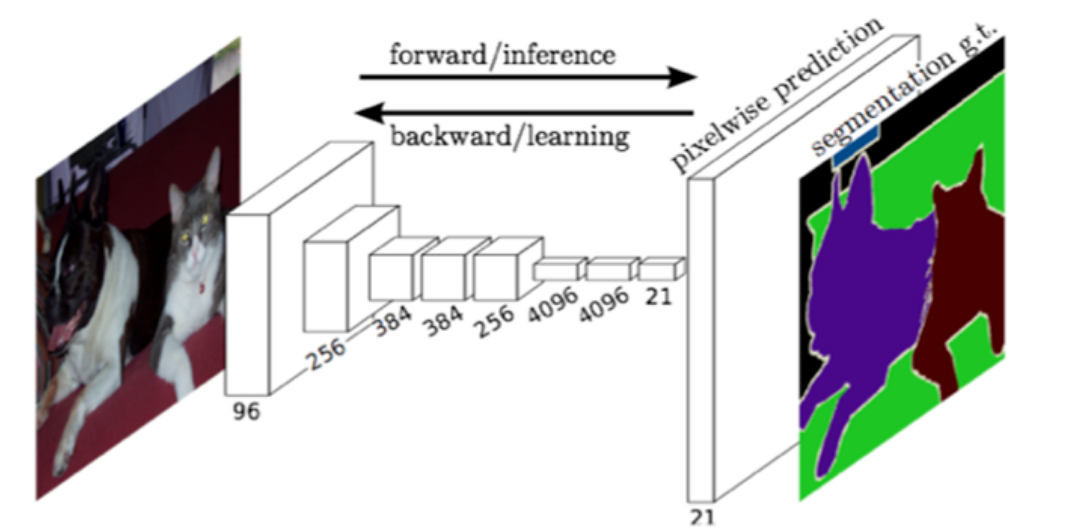
FCN与CNN的最大区别就是:FCN将CNN最后的全连接层换成全卷基层,输出得到一张已经label好的图片。
FCN可以对图像进行像素级别的分类,从而可以解决语义级别的图像分割问题。与CNN不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层(对应CNN中的FC8)的feature map进行上采样,使它恢复到与输入图像相同的尺寸,从而可以对每个像素都产生一个预测,同时保留了原始输入图像中的空间信息,最后在上采样的特征图上进行逐个像素的分类,对每个像素都计算一个softmax分类损失,相当于每一个像素对应一个训练样本。
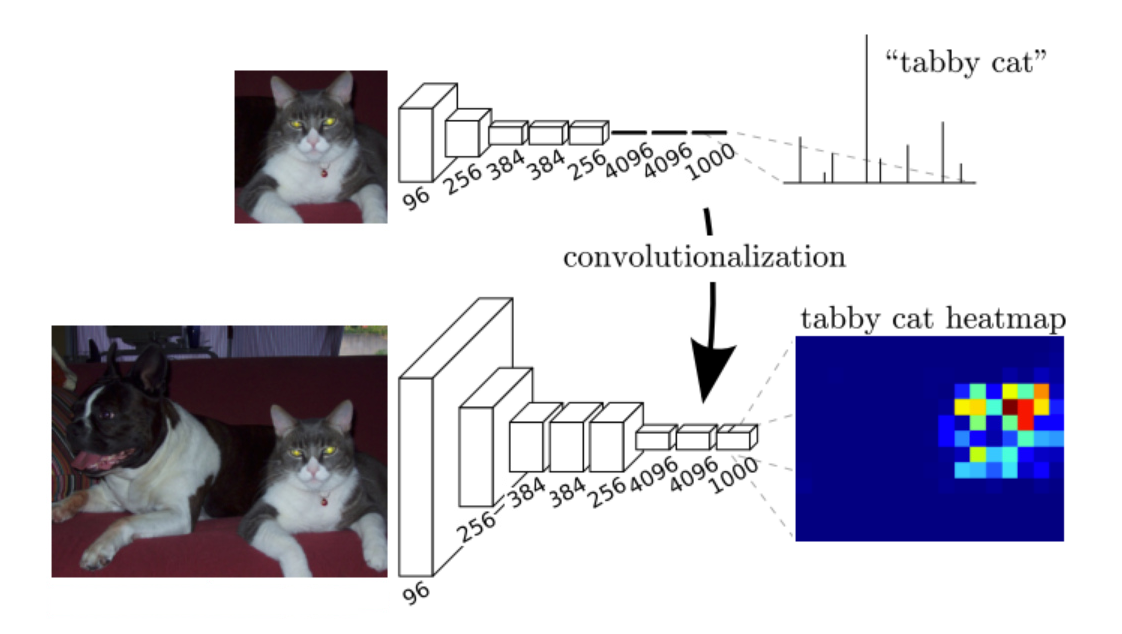
6. 全连接到全卷积的转换:
全连接与全卷积的不同是卷积层中的神经元只与输入数据中的一个局部区域连接,并且在卷积列中的神经元共享参数,相同点是神经元都是计算点积,所以全连接和全卷积在函数形式上是一致的,因此两者之间的转化是可以的。
比如K=4096的全连接第一层,尺寸为4096*1,而卷积层的feature map的尺寸为7*7*256,如果将卷积核的尺寸设置为和输入数据的尺寸一致,即卷积核的尺寸为7×7×4096,那么输出将变成1*1*4096,和全连接是一致的。
具体到实例:假设一个神经网络的输入图像为224*224*3,经过一系列的卷积层和下采样层之后将图像的尺寸转化为7*7*256,的激活体,AlexNet使用了两个尺寸为4096的全连接层,最后一层的输出层大小为1000个神经元的全链接用于计算分类score。
>> 针对第一个全连接层,输入数据为7*7*256,令滤波器的尺寸为7×7,滤波器的个数为4096,经过卷积后输出数据体的尺寸为1×1*4096
>> 针对第二个全连接层,输入数据为1*1*4096,令滤波器的尺寸为1×1,滤波器的个数为4096,经过卷积后的输出数据体的尺寸为1*1*4096
>> 针对第三个全连接层,为输出层,输入数据为1*1*4096,令滤波器的尺寸为1*1,滤波器的个数为1000,经过卷积后的输出数据体的尺寸为1*1*1000
在每次这样的变换中,都要将全连接层中的权重W重塑成卷积层的滤波器,这样的转化可以让卷及网络在一张很大的图像上滑动得到多个滑动输出在一次前向传播过程中得到实现。
假设原始图像的带下为384*384*3,采用224*224的图像块进行滑窗,滑动步长为32,得到6*6=36个滑动图(bbox),将每个滑动图输入到传统的CNN中,经过全连接网络,输出为1*1000的向量(已经过softmax计算),从而对该bbox的类别进行判定,这样的过程要经过36次;而FCN将384*384的原始图直接输入到FCN中,经过一次全程的卷积得到6*6*4096的输出,然后再对这个6*6的输出进行上采样,得到384*384的全局feature map,这样的全局feature map有1000个,对1000个全局feature map的每个像素计算一个softmax输出,通过统计该位置像素(假设为(0,0)位置的像素)在1000个图中的最大值,作为全局feature map的在(0,0)位置的softmax输出值,这样的到一张每个像素(384*384个像素)具有label(1000个分类属于哪类)的全局feature map,从而根据每个像素的类别对像素进行聚类,得到最后的像素级别的分割图。


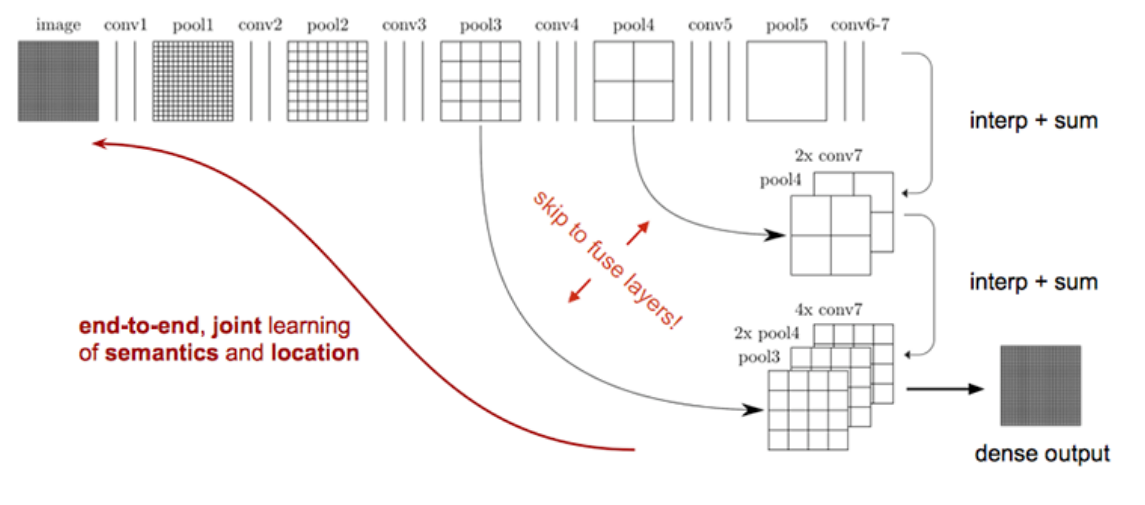
7. 上采样 upsampling
主要目的是补充最后的heatMap的特征细节,采用的方法是skip layer,将第三卷积层的feature map(原图的1/8尺寸)和第四卷积层的feature map(原图的1/16尺寸)经过上采样恢复到原图的尺寸(384*384),然后将feature map3 + feature map4 + heatMap进行融合,这样的feature map具有更多的图像细节。

8. 缺点
(1) 得到的结果不够精细,进行8倍上采样虽然比32倍好很多,但是上采样的结果比较模糊和平滑,对图像的细节描述不够清晰。
(2) 对各个像素进行分类,没有充分靠虑像素与像素之间的关系,忽略了在通常的基于像素分类的分割方法中使用的空间规整步骤,缺乏空间一致性。
9. 优点
(1) 采用全卷积结构,计算更快,占用内存更小。
(2) 实现了像素级别的分类,分割相对更精细。
(3) 可以接受任意尺寸的输入图片。















 161
161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









