






一、决策树
1、什么是决策树?如何进行高效的决策?
最早的决策树就是利用程序设计中的if-else结构分割数据的一种分类学习法。决策树的思想就是:如何高效的进行决策。而我们决策是有顺序的,即:我们在看不同的特征的时候,先看哪一个,后看哪一个是有讲究的。因为正确的特征先后顺序有利于我们进行高效的决策。比如:
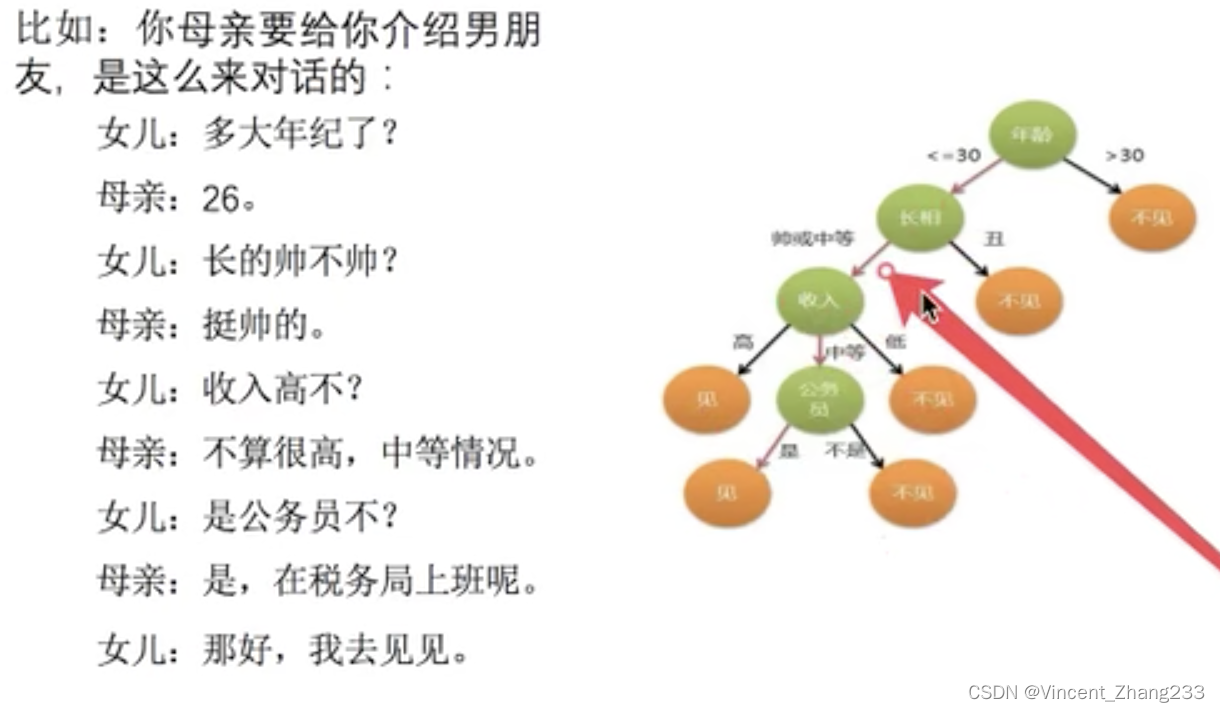
从上图可以看出,该女生最在意的是男方的年龄,其次是长相,收入,职业。如果男方年龄不合适,则直接就不见了,就省去了后面的问题。所以正确的特征的先后顺序有利于我们进行高效决策。
2、特征的先后顺序
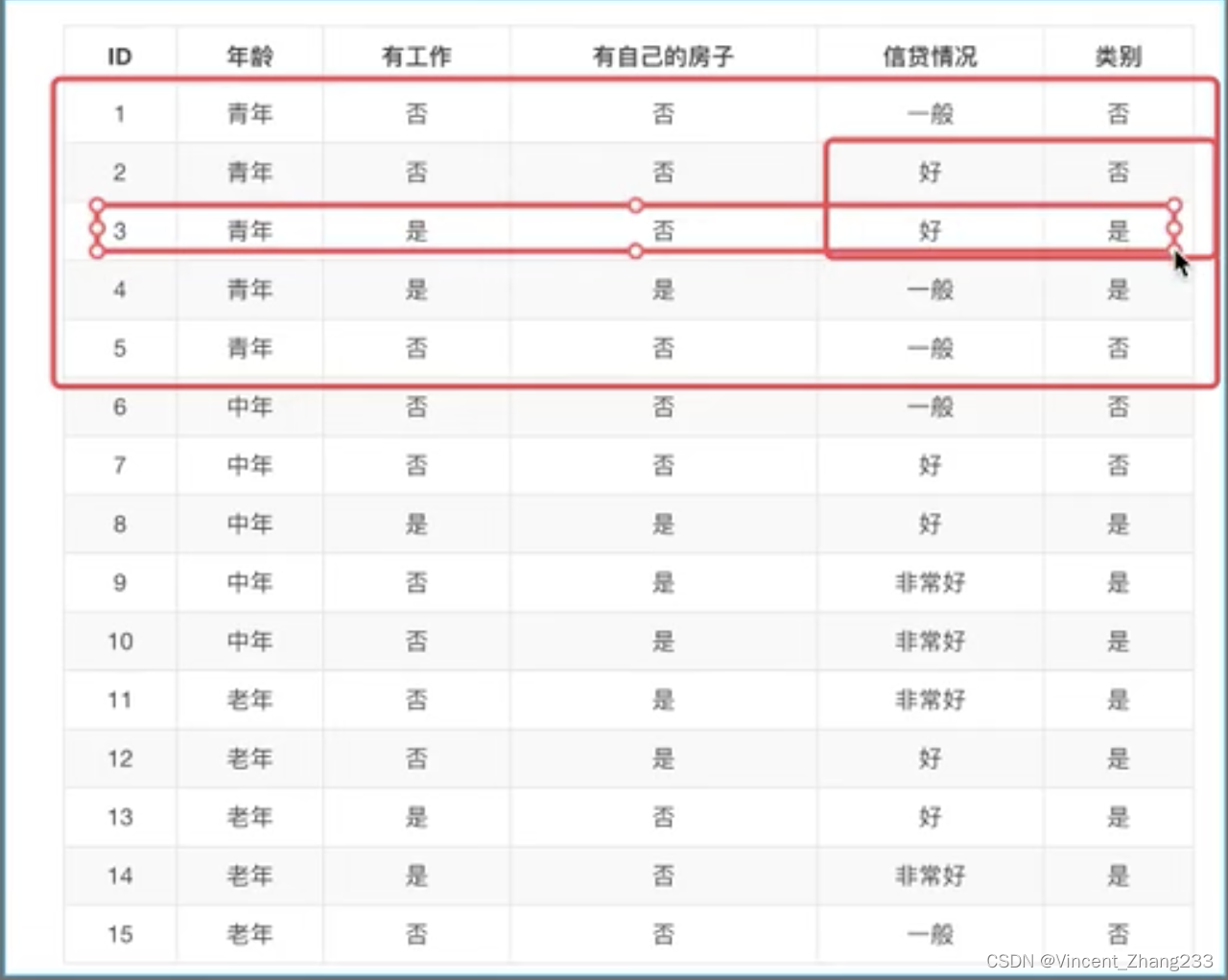
举例:已知有四个特征:“年龄”,“是否有工作”,“是否有自己的房子”,“信贷情况”这四个特征,请你预测是否要贷款给某个人。
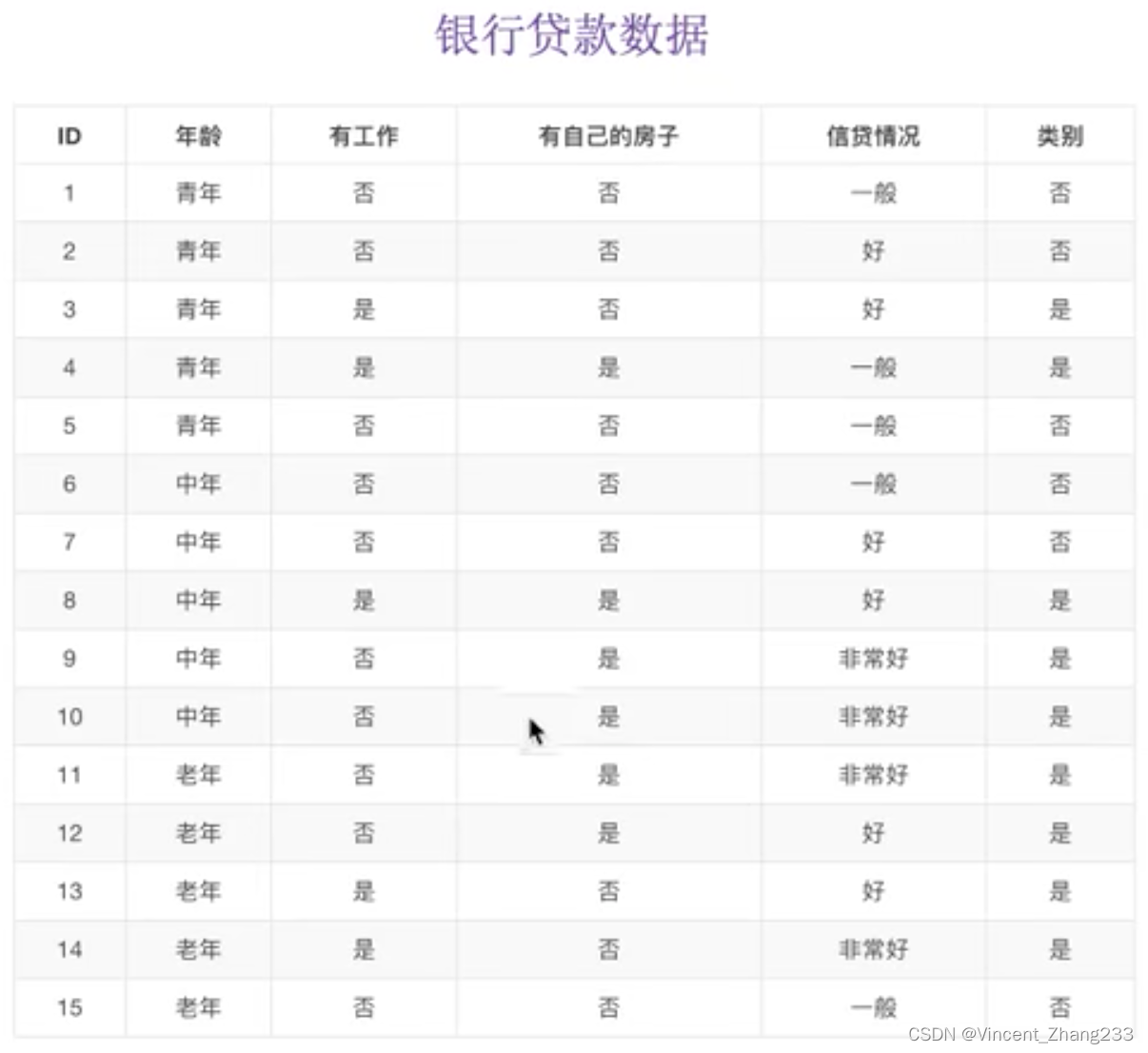
参考上图(以往的样本),如果我们先看是否有房子,再看是否有工作:
以往的样本中,有房子的都拿到了贷款:
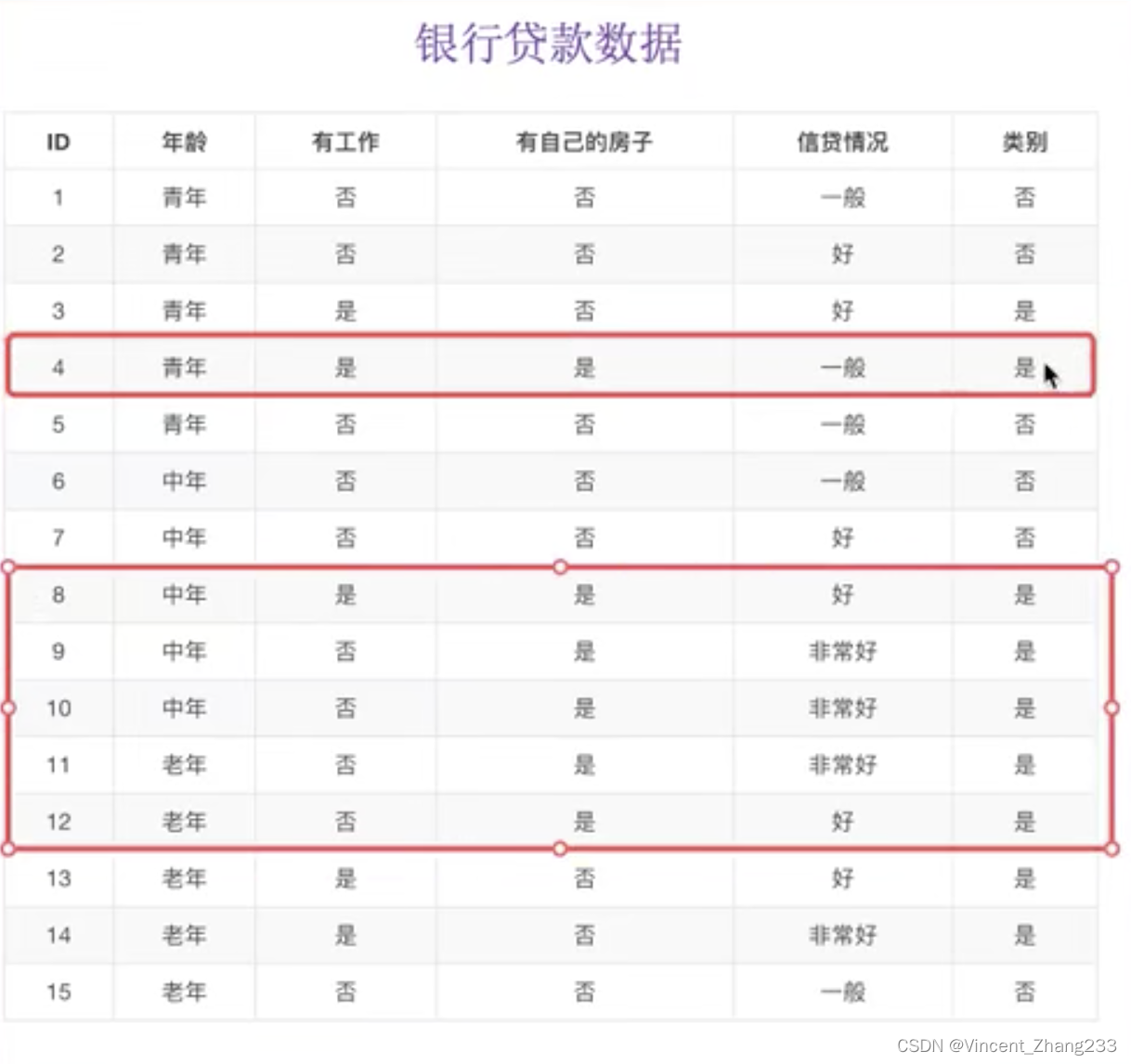
但是,有一些人没有房子也拿到了贷款,所以我们光看房子还不够,所以继续看是否有工作。
剩下的没放没工作的人,不论信用如何,都没有拿到贷款。所以如果我们先看房子,再看工作,就不用再看其他特征,就可以决定是否贷款了。
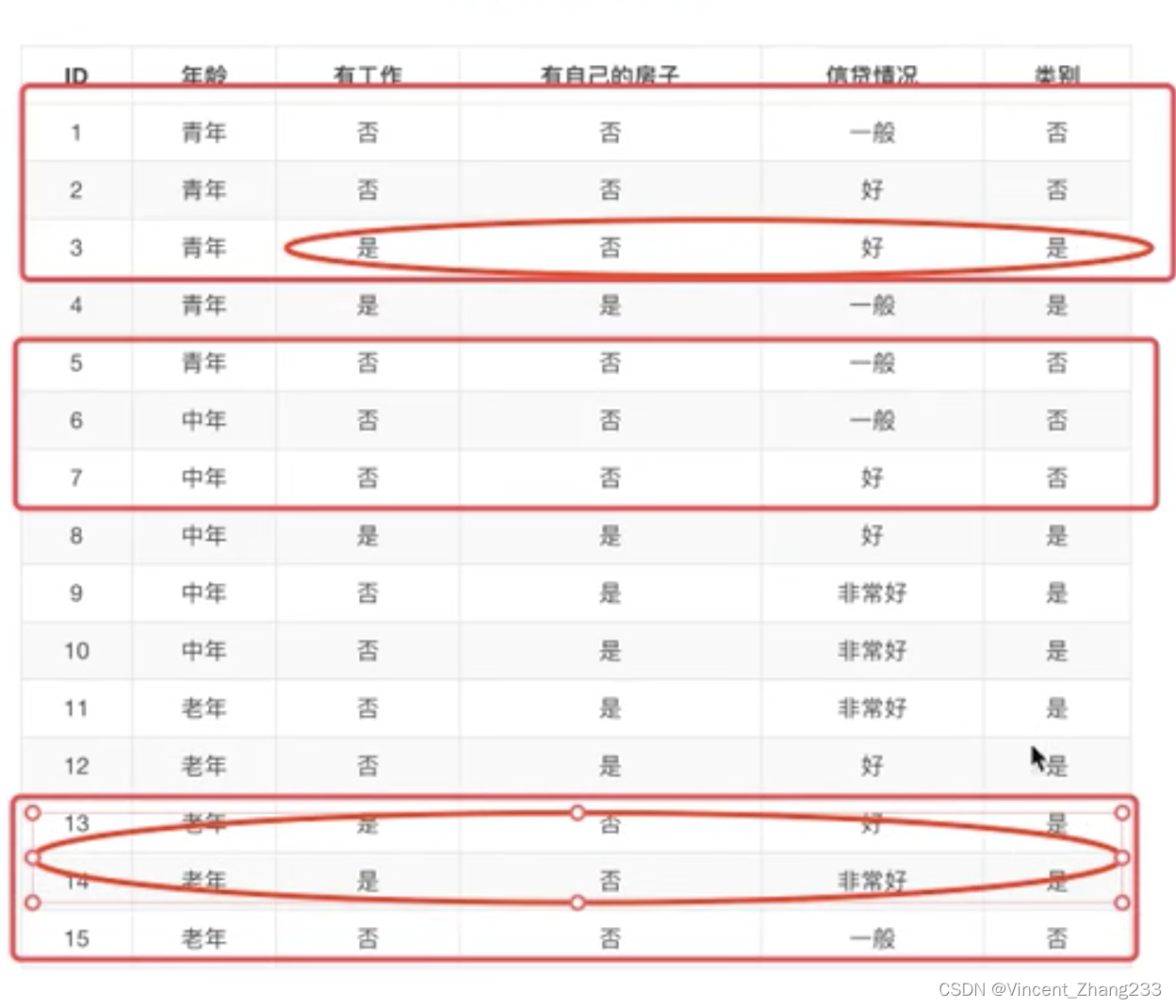
如果我们不按照这个顺序,比如我们先看年龄,再看信贷情况,再看工作,才能确定是否贷款。如下图:
我们需要看3个特征才能确定是否贷款,这个效率显然就比前面看2个特征的效率要低了。所以,特征的先后顺序会影响到我们决策的效率。
那么问题来了,我们如何找到高效的决策顺序呢?这里就要引入信息熵、信息增益的知识。
3、信息论基础——信息熵
1)什么是信息?
信息是消除随机不定性的东西是信息(香农定义的)。比如:我不确定小明的年龄。而小明说:“我今年18岁。”那么“我今年18岁。”就是一个信息。
为了进一步取理解什么是信息,我们再举一个例子:现在我已经知道小明18岁了,而小华说:“小明明年19岁。”那么“小明明年19岁。”这句话就不算信息了,因为小明之前已经告诉了我他的年龄,我对于小明年龄的不确定性已经被消除,所以小华这句话并没有消除我任何不确定性,所以不能算是信息。
2)信息的衡量——信息量和信息熵
信息量度量的是一个具体事件发生所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。
信息量的表示:

信息量的大小和事件发生的概率成反比
信息熵的表示:

发生概率越高的事件,其所携带的信息熵越低。极端案例就是“太阳从东方升起”,因为为确定事件,所以不携带任何信息量。
信息熵是用来衡量事物不确定性的。信息熵越大,事物越具不确定性,事物越复杂。
那么对于上面的贷款问题,可以计算出,信息熵为:
H(X) = -(6/15 * log6/15 + 9/15 * log9/15) = 0.971
这个0.971表示的就是申请贷款者的总的不确定性
3)决策树划分的依据之一——信息增益
当我们知道贷款人的某个特征之后,其不确定性就会减少,如果我们能够计算出知道某个特征之后,其不确定性减少的程度,再比较出哪个特征减少的不确定性的程度是最大的,那么我们以后放贷款时就可以先看这个特征了。这就是决策树解决问题的思路。同时,我们还要引入信息论中的一个新的概念——信息增益。
信息增益衡量的是知道某个特征之后,不确定性的减少程度。
公式:特征A对训练集X的信息增益g(X, A),定义为集合X的信息熵H(X)与特征A给定条件下X的信息条件熵H(X|A)之差,即:
g(X, A) = H(X) - H(X|A)
举例:计算知道年龄之后的信息增益?
g(X|年龄) = H(X) - H(X|年龄)


4、在sklearn中使用决策树

实操:鸢尾花分类















 1556
1556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









