






 本文介绍了C++17中并行算法标准库的std::execution::par和std::execution::par_unseq执行策略,分别阐述了它们的并行与向量化特性,以及在编程中如何确保线程安全和避免数据竞争。
本文介绍了C++17中并行算法标准库的std::execution::par和std::execution::par_unseq执行策略,分别阐述了它们的并行与向量化特性,以及在编程中如何确保线程安全和避免数据竞争。
前言
在 C++17 中,引入了并行算法标准库,这包括了两种主要的执行策略:std::execution::par 和 std::execution::par_unseq。这些执行策略用于控制算法的并行执行方式。这两个都是用于程序并行,但存在一些区别,其中,后者多了unseq这个后缀(unsequenced的简写,意为“不顺序”,记住这个方便后续理解)下面通过示例代码来说明一下。
说明
-
std::execution::par:
- 这是并行执行策略。
- 它指示算法应该并行执行,允许同时处理不同的数据元素。
- 使用这种策略时,算法会在多个线程之间分配工作,但它不会执行向量化操作。
- 这种策略适用于可以安全地在多个线程上并行执行而不引发数据竞争的情况。
-
std::execution::par_unseq:
- 这是并行和向量化的执行策略。
- 它不仅允许并行执行,而且还允许不顺序和向量化的执行。
- 这意味着算法可以同时在单个线程的多个数据元素上执行操作(例如,通过使用 SIMD 指令集)。
- 这种策略是最不限制的,允许最大程度的并行性,但它也要求操作之间没有任何顺序依赖关系,因为它们可能会同时或在不确定的顺序中执行。
在使用这些执行策略时,重要的是要确保操作是线程安全的,并且在 std::execution::par_unseq的情况下,操作之间没有顺序依赖。这是因为并行和向量化执行可能会导致不可预测的执行顺序,从而在没有适当同步的情况下可能引发数据竞争和其他并发问题。
这里看不太明白也没关系,可以直接看代码示例和后续总结。
示例一
https://en.cppreference.com/w/cpp/algorithm/execution_policy_tag
上面链接是cppreference上的代码示例,除了有std::execution::par 和 std::execution::par_unseq的示例外,也包括了std::execution::seq,和std::execution::par(这两个是串行的选项)的一并举例,直接看该链接的代码示例也能一定程度上理解。
示例二
#include <iostream>
#include <vector>
#include <execution>
#include <chrono>
#include <thread>
void doubleValue(int &n)
{
auto thread_id = std::this_thread::get_id();
std::cout<<"thread_id: "<<thread_id<<std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
n *= 2;
std::cout << n << " "<<std::endl;
}
int main()
{
std::vector<int> v = {1, 2, 3, 4, 5};
// 使用 std::execution::par并行
std::for_each(std::execution::par, v.begin(), v.end(), doubleValue);
// 使用 std::execution::par_unseq并行且向量化执行
std::for_each(std::execution::par_unseq, v.begin(), v.end(), doubleValue);
return 0;
}
创建为一个test.cpp文件且用g++编译:
g++ -std=c++17 test.cpp -o test.out -ltbb
运行后打印结果如下:
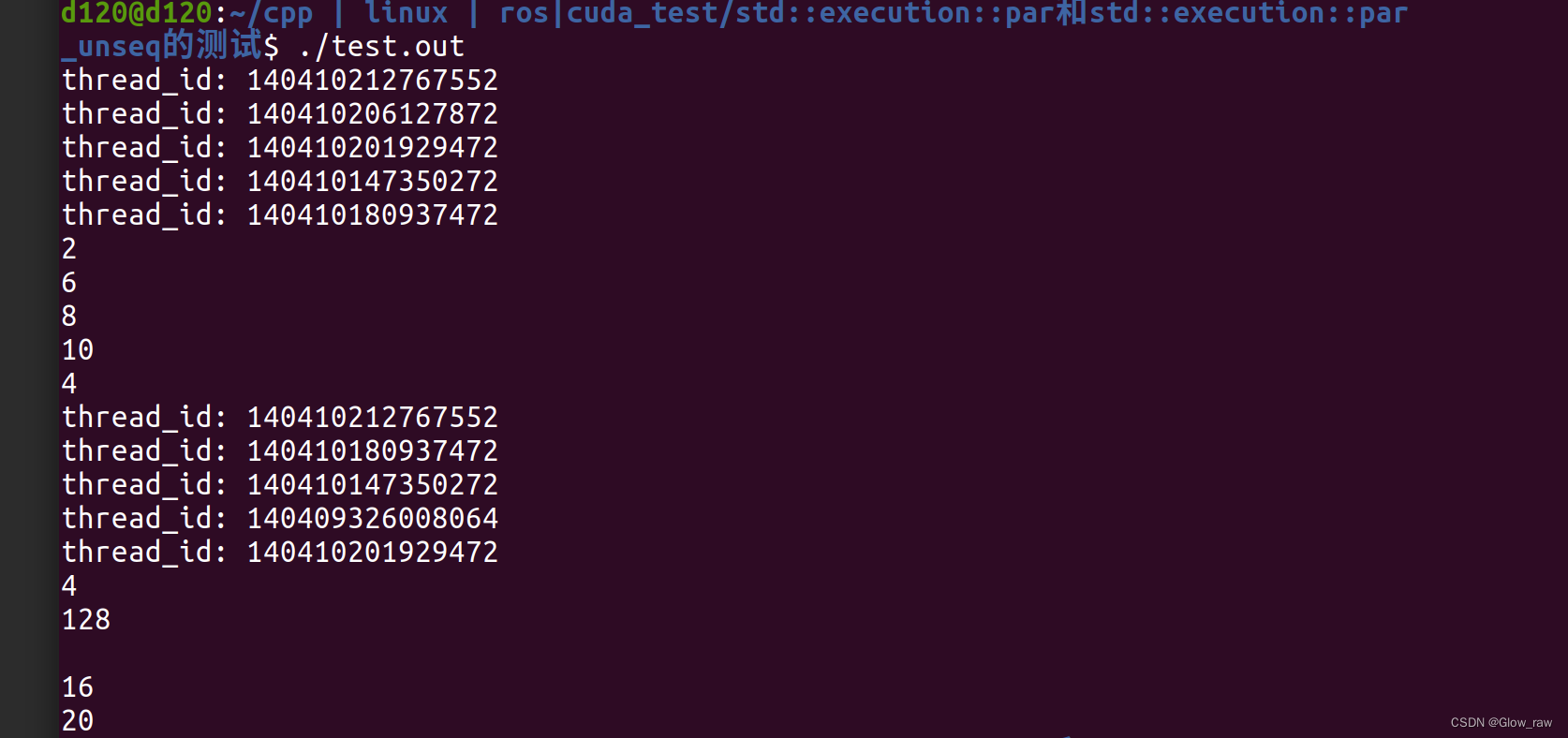
根据线程id,可以观察到std::for_each都是并行的(不加std::execution::par 或execution::par_unseq参数的std::for_each是串行的),但下面部分的打印,即std::execution::par_unseq的部分可能会出现换行符打印出错,读者们可以试一下,上面的换行是不会出错的,但下面的部分运行有概率会换行出错。
这就是因为:std::execution::par_unseq这种执行策略既允许并行也允许“不顺序”执行。在这里,“不顺序”(unsequenced)指的是在单个线程内,操作可以以不顺序的方式执行,这通常涉及向量化(如 SIMD 指令)。
总结
std::execution::par使算法在多个线程中执行,并且线程各自具有自己的顺序任务。即并行但不并发。
std::execution::par_unseq使算法在多个线程中执行,并且线程可以具有并发的多个任务。即并行和并发。(当然,这是一种通俗的近似理解,不能说完全准确)

















 2008
2008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









