






代码网址:https://github.com/marvis/pytorch-yolo3
参考的博客:https://blog.csdn.net/leviopku/article/details/82660381
1.backbone
使用Darknet-53,这种网络使用了残差结构,feature map的改变通过步长的改变,一共缩小到1/32。
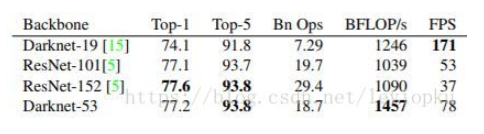
darknet_53有着相当大的优势,速度更快准确率也差不多,在论文中,作者认为RES101缺点在于层数太多,效率低。如果追求速度,可以使用 tiny-darknet, tiny-yolo有轻量和高速两个特点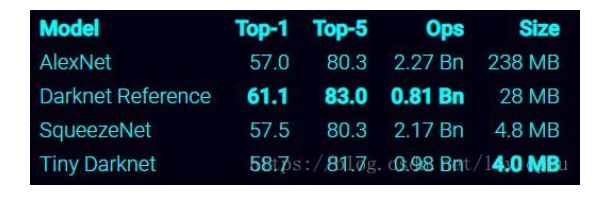
darknet结构2
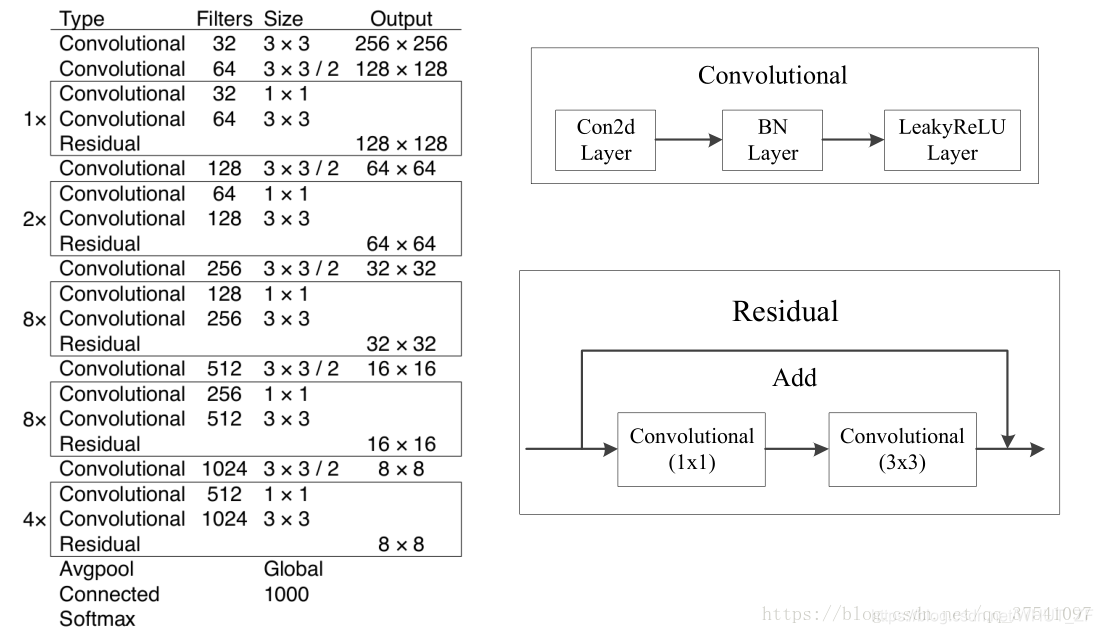
2.网络结构
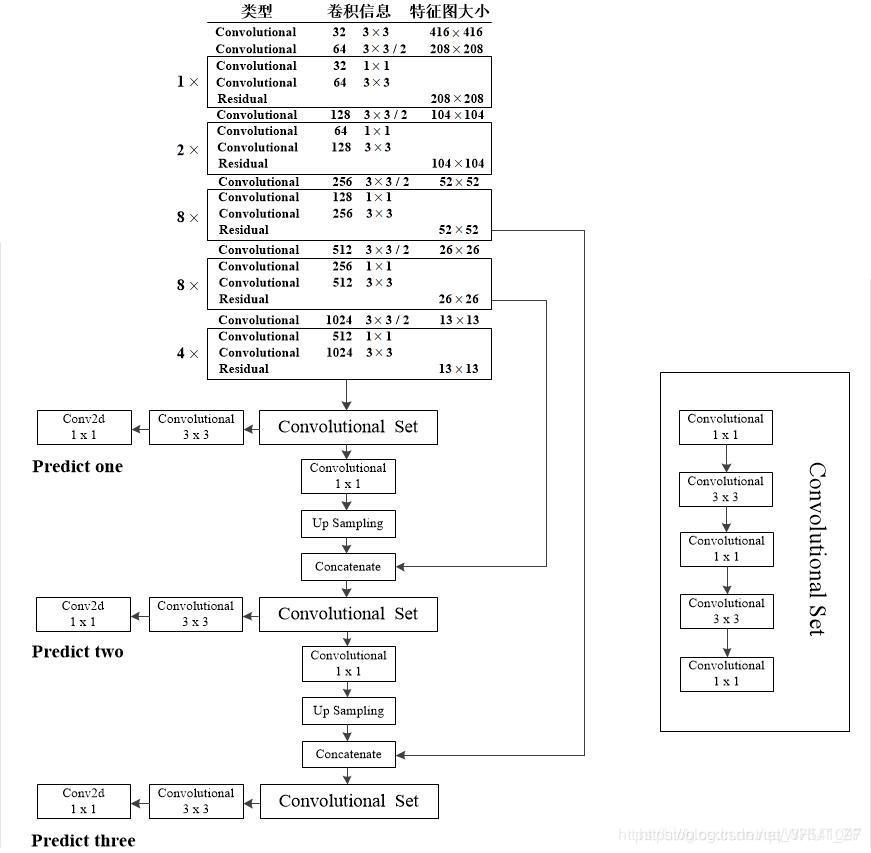
3.检测方法
使用了3种不同的尺寸,当然也可以自己调整
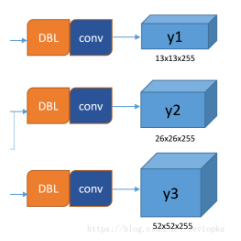
yolo v3输出了3个不同尺度的feature map, 这个借鉴了FPN, 用多尺度来对不同size的目标进行检测,越精细的grid cell就可以检测出越精细的物体,可以增强对小目标的结果。
yolo3把图像分成N*N,这里的N对应feature map,每个网格预测3个框,所以有3*(80+4+1),其中80为类,4为对框的调整参数,1为置信度。
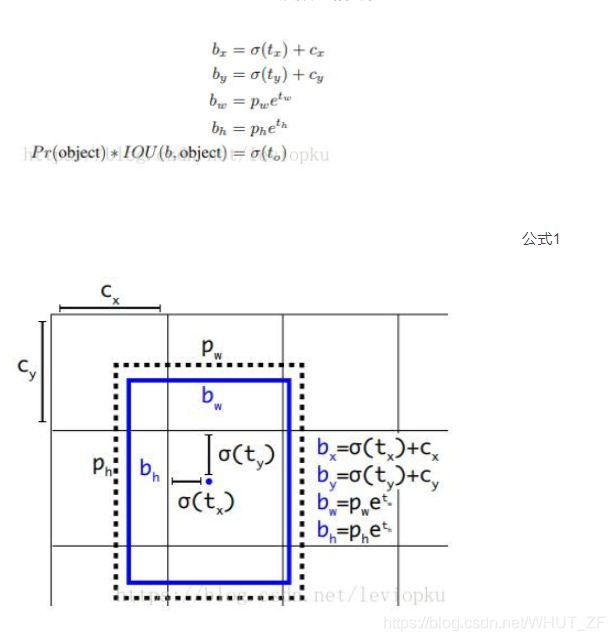
根据这个公式来求得框的center coordinate和长宽,其中CX,CY为网格的左上角坐标,作者对x,y的预测想直接线性回归代替逻辑回归,但是结果变差,可能是因为线性回归的不稳定行引起(可以偏移到任何位置).
yolo3在计算LOSS的时候,用的是对应网格(包含目标中心)的最适合的框来计算坐标,长宽和分类的损失,对于置信度的损失也计算了其他的值,并且给了1和100的权值,
loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobj
self.obj_scale=1
self.noobj_scale=100
4.NMS算法,结合了confidence
按照置信度对框进行排序
1.从第一个框开始,寻找和他的NMS大于nms_thres的框
2.找出和第一个框同一类的框
3.对上面两个结果求交集得到指向同一个的所有框
4.对这些框加权求平均,得到一个结果,去除这些结果,在返回步骤一















 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









