






回归树在认知诊断模型中的应用是一种基于数据驱动的方法,用于分析学生的认知状态(如知识掌握情况)并预测其表现(如考试成绩)。以下是回归树在认知诊断模型中的详细应用说明,包括其原理、优势、实现步骤以及实际应用场景。
1. 回归树的基本原理
回归树(Regression Tree)是一种决策树算法,用于解决回归问题(预测连续值)。其核心思想是通过递归地将数据集划分为更小的子集,使得每个子集内的目标变量(如学生成绩)尽可能同质。划分的依据是特征(如认知属性)的值。
回归树的关键步骤:
-
选择划分特征:根据某个特征的值将数据集划分为两个子集,使得划分后的子集的均方误差(MSE)最小。
-
递归划分:对每个子集重复上述过程,直到满足停止条件(如树的深度、节点样本数等)。
-
生成叶节点:每个叶节点代表一个预测值,通常是该节点内样本目标变量的均值。
2. 回归树在认知诊断模型中的应用
在认知诊断模型中,回归树可以用于:
-
预测学生表现:根据学生的认知属性(如是否掌握某个知识点)预测其考试成绩。
-
分析认知属性的重要性:通过特征重要性评分,了解哪些认知属性对学生的表现影响最大。
-
个性化诊断:通过回归树的结构,识别学生的认知弱点,并提供个性化的学习建议。
3. 回归树的优势
-
可解释性强:
-
回归树的结构清晰,可以直观地展示认知属性如何影响学生表现。
-
通过可视化回归树,教师可以快速理解学生的认知状态。
-
-
处理非线性关系:
-
回归树能够捕捉认知属性与学生表现之间的复杂非线性关系。
-
-
自动特征选择:
-
回归树在训练过程中会自动选择重要的认知属性,减少冗余特征的影响。
-
-
适用于小样本数据:
-
回归树在小样本数据上表现良好,适合教育领域中的小规模数据集。
-
4. 实现步骤
以下是回归树在认知诊断模型中的具体实现步骤:
(1)数据准备
-
数据收集:收集学生的答题记录和认知属性数据。
-
特征工程:将认知属性转化为模型可用的特征(如二进制编码)。
-
目标变量:确定目标变量(如学生成绩)。
(2)划分训练集和测试集
-
将数据集划分为训练集(用于模型训练)和测试集(用于模型评估)。
(3)训练回归树模型
-
使用训练集训练回归树模型,目标变量为学生的表现,特征为认知属性。
(4)模型评估
-
使用测试集评估模型性能,常用的评估指标包括均方误差(MSE)和均方根误差(RMSE)。
(5)特征重要性分析
-
提取回归树模型中各认知属性的重要性评分,了解哪些属性对学生的表现影响最大。
(6)结果解释与应用
-
通过回归树的结构和特征重要性,分析学生的认知状态,并提供个性化的学习建议。
5. 示例代码
以下是使用R语言实现回归树在认知诊断模型中的应用的完整代码:
(本代码有点点问题,交叉验证部分会有警告信息,博主调整失败,请大神指教)
# 安装和加载必要的包
install.packages("rpart") # 用于构建回归树
install.packages("rpart.plot") # 用于可视化回归树
install.packages("caret") # 用于数据划分和模型评估
install.packages("dplyr") # 用于数据操作
library(rpart) # 加载回归树包
library(rpart.plot) # 加载回归树可视化包
library(caret) # 加载模型评估包
library(dplyr) # 加载数据操作包
# 1. 数据准备
# 生成示例数据
set.seed(123) # 设置随机种子,确保结果可重复
n <- 100 # 样本数量
# 创建一个数据框,包含学生的认知属性和成绩
df <- data.frame(
attribute1 = rbinom(n, 1, 0.6), # 认知属性1(0或1),生成二项分布随机数
# 参数:
# - n: 生成的随机数数量
# - 1: 每次试验的次数(二分类数据)
# - 0.6: 每次试验成功的概率(60%的概率为1)
attribute2 = rbinom(n, 1, 0.5), # 认知属性2(0或1),生成二项分布随机数
# 参数:
# - n: 生成的随机数数量
# - 1: 每次试验的次数(二分类数据)
# - 0.5: 每次试验成功的概率(50%的概率为1)
attribute3 = rbinom(n, 1, 0.4), # 认知属性3(0或1),生成二项分布随机数
# 参数:
# - n: 生成的随机数数量
# - 1: 每次试验的次数(二分类数据)
# - 0.4: 每次试验成功的概率(40%的概率为1)
score = rnorm(n, mean = 70, sd = 10) # 学生成绩(目标变量),生成正态分布随机数
# 参数:
# - n: 生成的随机数数量
# - mean: 正态分布的均值(70分)
# - sd: 正态分布的标准差(10分)
)
# 检查数据
summary(df) # 查看数据摘要,包括每个变量的最小值、最大值、均值等
str(df) # 查看数据结构,包括变量类型和数据框的维度
# 2. 划分训练集和测试集
set.seed(42) # 设置随机种子,确保划分结果可重复
train_index <- createDataPartition(df$score, p = 0.8, list = FALSE)
# createDataPartition:用于创建数据划分索引
# 参数:
# - df$score: 目标变量(学生成绩)
# - p: 训练集的比例(这里是80%)
# - list: 是否返回列表形式(FALSE表示返回向量)
train_data <- df[train_index, ] # 训练集
test_data <- df[-train_index, ] # 测试集
# 3. 训练回归树模型
# 调整复杂度参数 cp,避免过拟合
model <- rpart(score ~ ., data = train_data, method = "anova", cp = 0.02)
# rpart:用于构建回归树
# 参数:
# - score ~ .: 公式,表示目标变量为score,特征为所有其他变量
# - data: 训练数据集
# - method: 方法类型,"anova"表示回归树(用于连续目标变量)
# - cp: 复杂度参数,控制树的复杂度,值越小树越复杂
# 查看模型
print(model) # 打印模型的基本信息
summary(model) # 显示模型的详细摘要
# 4. 可视化回归树
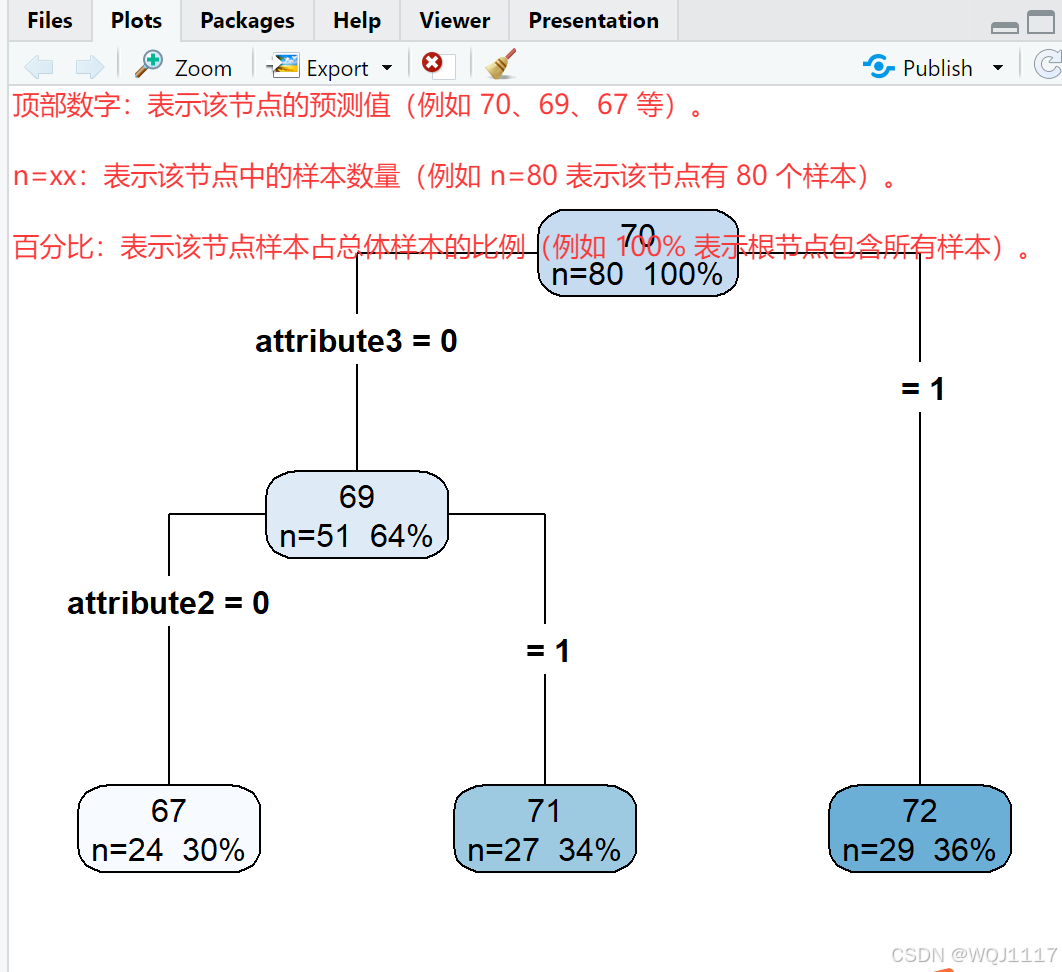
rpart.plot(model, type = 4, extra = 101, fallen.leaves = TRUE)
# rpart.plot:用于可视化回归树
# 参数:
# - model: 回归树模型
# - type: 绘图类型,4表示绘制带有节点编号的树
# - extra: 显示额外信息,101表示显示节点样本数和均值
# - fallen.leaves: 是否将所有叶节点对齐
# 5. 模型预测
predictions <- predict(model, test_data) # 使用测试集进行预测
# predict:用于生成预测值
# 参数:
# - model: 回归树模型
# - test_data: 测试集数据
# 计算均方误差(MSE)
mse <- mean((test_data$score - predictions)^2) # 计算均方误差
cat("Mean Squared Error (MSE):", mse, "\n")
# 计算均方根误差(RMSE)
rmse <- sqrt(mse) # 计算均方根误差
cat("Root Mean Squared Error (RMSE):", rmse, "\n")
# 6. 特征重要性分析
importance <- model$variable.importance # 提取特征重要性评分
importance_df <- data.frame(
Feature = names(importance), # 特征名称
Importance = importance # 特征重要性评分
)
# 按重要性排序
importance_df <- importance_df %>% arrange(desc(Importance)) # 按重要性降序排列
print(importance_df) # 打印特征重要性表格
# 7. 交叉验证(可选)
# 设置交叉验证,增加折数以避免警告
ctrl <- trainControl(method = "cv", number =10) # 设置10折交叉验证
# trainControl:用于定义交叉验证的参数
# 参数:
# - method: 交叉验证方法,"cv"表示K折交叉验证
# - number: 折数(这里是10折)
# 训练模型
cv_model <- train(score ~ ., data = train_data, method = "rpart", trControl = ctrl, tuneLength = 5)
# train:用于训练模型并进行交叉验证
# 参数:
# - score ~ .: 公式,表示目标变量为score,特征为所有其他变量
# - data: 训练数据集
# - method: 模型类型,"rpart"表示回归树
# - trControl: 交叉验证参数
# - tuneLength: 调参的长度,表示尝试的复杂度参数的数量
# 查看交叉验证结果
print(cv_model) # 打印交叉验证结果

















 1608
1608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









