






融合模型在认知诊断评估(CDA)中的应用
融合模型(Fusion Model)是一种通过整合多个模型或数据源的信息来提高预测性能的方法。在认知诊断评估(Cognitive Diagnostic Assessment, CDA)中,融合模型被广泛应用于结合不同认知诊断模型(如DINA、DINO、GDINA、RUM、LCDM等)的结果,从而更准确地诊断学生的知识状态。以下是融合模型在CDA中的详细解析:
1. 融合模型的核心思想
融合模型的核心思想是通过整合多个模型的优势,弥补单一模型的不足,从而提高诊断的准确性和可靠性。在CDA中,融合模型的主要目标是:
-
结合不同认知诊断模型的输出:例如,将DINA模型的严格性和GDINA模型的灵活性结合起来。
-
提高诊断结果的稳定性:通过减少单一模型的偏差和方差,增强诊断结果的鲁棒性。
-
适应复杂评估需求:通过灵活融合多种模型,满足不同测试场景的需求。
2. 常见认知诊断模型简介
在CDA中,有多种认知诊断模型可用于分析学生的知识状态。以下是几种常见模型的简介:
(1)DINA模型(Deterministic Input, Noisy “And” Gate Model)
-
核心思想:假设学生在掌握所有相关属性的情况下才能正确回答题目,但存在一定的猜测和失误概率。
-
参数:
-
猜测参数(guessing parameter):学生未掌握相关属性但仍答对题目的概率。
-
失误参数(slipping parameter):学生掌握了相关属性但仍答错题目的概率。
-
-
优点:模型简单,易于解释。
-
缺点:假设较强,可能不适合复杂题目。
(2)DINO模型(Deterministic Input, Noisy “Or” Gate Model)
-
核心思想:假设学生只要掌握任意一个相关属性即可正确回答题目,但存在一定的猜测和失误概率。
-
参数:与DINA模型类似,包括猜测参数和失误参数。
-
优点:适合考察多个替代性知识属性的题目。
-
缺点:假设较强,可能不适合复杂题目。
(3)GDINA模型(Generalized DINA Model)
-
核心思想:DINA模型的广义版本,允许题目与知识属性之间的关系更加灵活。
-
参数:包括主效应和交互效应,能够捕捉更复杂的题目-属性关系。
-
优点:灵活性高,适合复杂题目。
-
缺点:模型复杂度高,计算成本较大。
(4)RUM模型(Rule-Based Mixture Model)
-
核心思想:基于规则的混合模型,假设学生在不同知识状态下的答题概率不同。
-
参数:包括规则参数和混合比例参数。
-
优点:能够捕捉学生知识状态的异质性。
-
缺点:模型复杂度高,参数估计难度较大。
(5)LCDM模型(Logistic Cognitive Diagnosis Model)
-
核心思想:基于逻辑回归的认知诊断模型,允许题目与知识属性之间的关系更加灵活。
-
参数:包括主效应和交互效应,能够捕捉复杂的题目-属性关系。
-
优点:灵活性高,适合多种测试场景。
-
缺点:模型复杂度高,计算成本较大。
(6)RRUM模型(Reduced Reparameterized Unified Model)
-
核心思想:RUM模型的简化版本,通过重新参数化减少模型复杂度。
-
参数:包括主效应和简化后的交互效应。
-
优点:计算效率高,适合大规模数据分析。
-
缺点:灵活性略低于RUM模型。
3. 融合模型在CDA中的实现方法
在CDA中,融合模型通常通过以下方式实现:
(1)模型平均(Model Averaging)
-
方法:将多个认知诊断模型(如DINA、DINO、GDINA、RUM等)的预测结果进行加权平均,生成最终的诊断结果。
-
优点:简单直接,能够有效减少单一模型的偏差。
-
示例:
-
使用DINA模型和GDINA模型分别诊断学生的知识状态。
-
对两个模型的诊断结果进行加权平均,得到更稳定的结果。
-
(2)模型堆叠(Model Stacking)
-
方法:使用一个元模型(Meta-Model)来整合多个基模型(Base Models)的预测结果。
-
步骤:
-
使用多个基模型(如DINA、DINO、GDINA、RUM等)对学生的知识状态进行初步诊断。
-
将基模型的诊断结果作为输入,训练一个元模型(如逻辑回归、随机森林等)。
-
使用元模型生成最终的诊断结果。
-
-
优点:能够捕捉基模型之间的复杂关系,显著提高诊断准确性。
-
示例:
-
使用DINA模型和RUM模型作为基模型,生成初步诊断结果。
-
使用逻辑回归作为元模型,结合两个基模型的结果,生成最终诊断。
-
(3)层次融合(Hierarchical Fusion)
-
方法:在不同层次上结合多个模型的结果。例如,先使用DINA模型和GDINA模型分别进行诊断,然后在更高层次上结合两者的结果。
-
优点:灵活性高,能够充分利用不同模型的优势。
-
示例:
-
在第一层次,使用DINA模型和GDINA模型分别诊断学生的知识状态。
-
在第二层次,使用一个融合算法(如加权平均或投票法)结合两个模型的诊断结果。
-
4. 融合模型的优势
在CDA中,融合模型具有以下显著优势:
-
提高诊断准确性:通过结合多个模型的优势,能够更准确地反映学生的知识状态。
-
增强鲁棒性:减少单一模型的偏差和方差,提高诊断结果的稳定性。
-
灵活性高:可以结合不同类型的认知诊断模型,适应多种评估需求。
-
适应复杂场景:能够处理复杂的题目-属性关系,适合多样化的测试场景。
5. 融合模型的挑战
尽管融合模型在CDA中具有显著优势,但其应用也面临一些挑战:
-
模型选择:需要选择合适的基模型和融合方法,以达到最佳效果。
-
计算成本:融合模型通常需要更多的计算资源和时间。
-
解释性:融合模型的结果可能较难解释,特别是在使用复杂元模型时。
-
数据质量:融合模型的性能高度依赖于输入数据的质量,噪声或缺失值可能影响诊断结果。
6. 实际应用中的注意事项
在实际应用中,使用融合模型进行认知诊断评估时需要注意以下几点:
-
数据预处理:确保测试数据的高质量,避免噪声和缺失值对诊断结果的影响。
-
模型验证:使用交叉验证等方法评估融合模型的性能,确保其泛化能力。
-
专家评审:结合领域专家的意见,对融合模型的结果进行评审和调整。
-
参数调优:对融合模型中的参数(如权重、元模型类型等)进行调优,以提高诊断性能。
7. 融合模型的典型应用场景
融合模型在CDA中的典型应用场景包括:
-
大规模教育评估:如国家或地区层面的学业水平测试,通过融合模型提高诊断的准确性和可靠性。
-
个性化学习:通过融合模型精准诊断学生的知识状态,为个性化学习路径提供依据。
-
教学改进:通过融合模型分析学生的知识掌握情况,帮助教师改进教学策略。
8.总结
融合模型在认知诊断评估(CDA)中扮演着重要角色,通过整合多个认知诊断模型(如DINA、DINO、GDINA、RUM、LCDM等)的结果,能够显著提高对学生知识状态的诊断准确性和可靠性。尽管融合模型的设计和实现面临一定的挑战,但其在提高诊断性能方面的潜力使其成为CDA中的重要工具。未来,随着数据质量的提升和融合算法的改进,融合模型在教育和心理学领域的应用将更加广泛和深入。
下面写一段代码进行简单的数据模拟:
问题:
在教育和心理学中,认知诊断评估(CDA)旨在通过学生的答题数据,推断他们在多个知识属性(或技能)上的掌握情况。例如:
-
学生是否掌握了“加法”和“乘法”?
-
学生在“几何”和“代数”上的表现如何?
为了实现这一目标,我们需要:
-
生成模拟数据:模拟学生的知识状态和答题数据。
-
拟合认知诊断模型(融合模型):使用DINA和GDINA模型预测学生的知识状态。
-
融合多个模型的预测结果:通过随机森林模型结合DINA和GDINA的预测结果,提高诊断的准确性。
注:
-
DINA模型:假设学生必须掌握所有相关属性才能答对题目。
-
GDINA模型:允许更灵活的题目与知识属性之间的关系。
# 安装必要的包(如果尚未安装)
install.packages("CDM") # 用于认知诊断模型(如DINA、GDINA)
install.packages("caret") # 用于机器学习模型训练和评估
install.packages("dplyr") # 用于数据操作
install.packages("randomForest") # 用于随机森林模型
# 加载包
library(CDM) # 加载CDM包
library(caret) # 加载caret包
library(dplyr) # 加载dplyr包
library(randomForest) # 加载randomForest包
# 设置随机种子以确保结果可重复
set.seed(123) # 设置随机种子为123,确保每次运行结果一致
# 生成模拟数据
n_students <- 100 # 学生数量
n_items <- 20 # 题目数量
n_attrs <- 3 # 知识属性数量
# 生成Q矩阵(题目与知识属性的关系矩阵)
Q_matrix <- matrix(c(
1, 0, 0,
1, 1, 0,
0, 1, 0,
0, 1, 1,
1, 0, 1,
1, 1, 1,
0, 0, 1,
1, 0, 0,
0, 1, 0,
0, 0, 1,
1, 1, 0,
0, 1, 1,
1, 0, 1,
1, 1, 1,
0, 0, 1,
1, 0, 0,
0, 1, 0,
0, 0, 1,
1, 1, 0,
0, 1, 1
), nrow = n_items, ncol = n_attrs, byrow = TRUE) # 生成一个20x3的Q矩阵,表示题目与知识属性的关系
# 生成学生的知识状态(真实值)
true_alpha <- matrix(sample(0:1, n_students * n_attrs, replace = TRUE), nrow = n_students, ncol = n_attrs) # 生成一个100x3的矩阵,表示每个学生的知识状态(0或1)
# 手动生成学生的答题数据
response_data <- matrix(0, nrow = n_students, ncol = n_items) # 初始化一个100x20的答题数据矩阵,初始值为0
guess <- 0.2 # 猜测概率(学生未掌握知识属性但仍答对题目的概率)
slip <- 0.2 # 失误概率(学生掌握了知识属性但仍答错题目的概率)
for (i in 1:n_students) {
for (j in 1:n_items) {
# 判断学生是否掌握了所有需要的属性
required_attrs <- Q_matrix[j, ] # 获取第j题所需的知识属性
mastered_attrs <- true_alpha[i, ] # 获取第i个学生的知识状态
if (all(mastered_attrs >= required_attrs)) {
# 学生掌握了所有属性,正确回答的概率是 1 - slip
response_data[i, j] <- rbinom(1, 1, 1 - slip) # 生成一个二项分布随机数(0或1),概率为1 - slip
} else {
# 学生未掌握所有属性,正确回答的概率是 guess
response_data[i, j] <- rbinom(1, 1, guess) # 生成一个二项分布随机数(0或1),概率为guess
}
}
}
# 拟合DINA模型
dina_model <- CDM::din(response_data, Q_matrix, rule = "DINA") # 使用DINA模型拟合答题数据,rule = "DINA"表示使用DINA规则
# 拟合GDINA模型
gdina_model <- CDM::gdina(response_data, Q_matrix, rule = "GDINA") # 使用GDINA模型拟合答题数据,rule = "GDINA"表示使用GDINA规则
# 提取DINA模型的预测结果(知识状态)
dina_predictions <- dina_model$pattern[, 1:n_attrs] # 提取DINA模型预测的知识状态(100x3矩阵)
# 提取GDINA模型的预测结果(知识状态)
gdina_predictions <- gdina_model$pattern[, 1:n_attrs] # 提取GDINA模型预测的知识状态(100x3矩阵)
# 将预测结果和真实值合并为数据框
fusion_data <- data.frame(
dina_attr1 = dina_predictions[, 1], # DINA模型预测的第一个知识属性
dina_attr2 = dina_predictions[, 2], # DINA模型预测的第二个知识属性
dina_attr3 = dina_predictions[, 3], # DINA模型预测的第三个知识属性
gdina_attr1 = gdina_predictions[, 1], # GDINA模型预测的第一个知识属性
gdina_attr2 = gdina_predictions[, 2], # GDINA模型预测的第二个知识属性
gdina_attr3 = gdina_predictions[, 3], # GDINA模型预测的第三个知识属性
true_attr1 = true_alpha[, 1] # 真实的第一个知识属性
)
# 将目标变量转换为因子
fusion_data$true_attr1 <- as.factor(fusion_data$true_attr1) # 将目标变量true_attr1转换为因子类型,用于分类问题
# 将数据分为训练集和测试集
train_index <- createDataPartition(1:n_students, p = 0.8, list = FALSE) # 将数据分为训练集和测试集,80%为训练集
train_data <- fusion_data[train_index, ] # 提取训练集
test_data <- fusion_data[-train_index, ] # 提取测试集
# 训练随机森林模型
rf_model <- randomForest(
true_attr1 ~ ., # 公式:true_attr1为目标变量,其他变量为特征
data = train_data, # 训练数据集
ntree = 100, # 树的数量(默认500,这里设置为100以加快运行速度)
mtry = sqrt(ncol(train_data) - 1), # 每棵树使用的特征数量(默认为特征总数的平方根)
importance = TRUE # 计算特征重要性
)
# 查看模型性能
print(rf_model) # 打印随机森林模型的性能摘要
# 在测试集上进行预测
test_predictions <- predict(rf_model, newdata = test_data, type = "class") # 使用随机森林模型对测试集进行预测
# 计算准确率
accuracy <- mean(test_predictions == test_data$true_attr1) # 计算预测结果与真实值的准确率
print(paste("随机森林融合模型的准确率:", round(accuracy, 3))) # 打印准确率,保留3位小数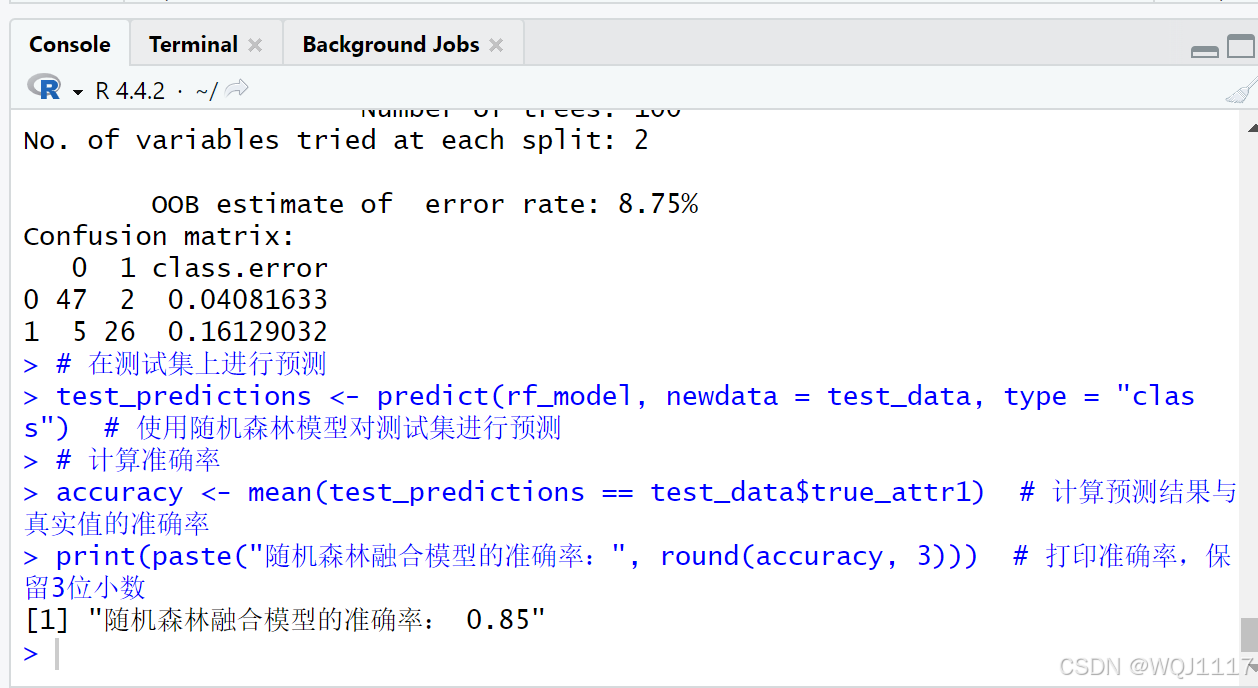

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









