







CUDA编程线程模型
CUDA(Compute Unified Device Architecture)是NVIDIA推出的并行计算平台和编程模型,它允许开发者利用GPU的强大计算能力进行通用计算(GPGPU)。理解CUDA的线程模型是高效使用GPU并行计算的关键。
CUDA线程层次结构
CUDA的线程模型采用分层结构,从高到低依次为:
-
网格(Grid):最高层次的线程组织
-
线程块(Block):中间层次的线程组织
-
线程(Thread):最基本的执行单元
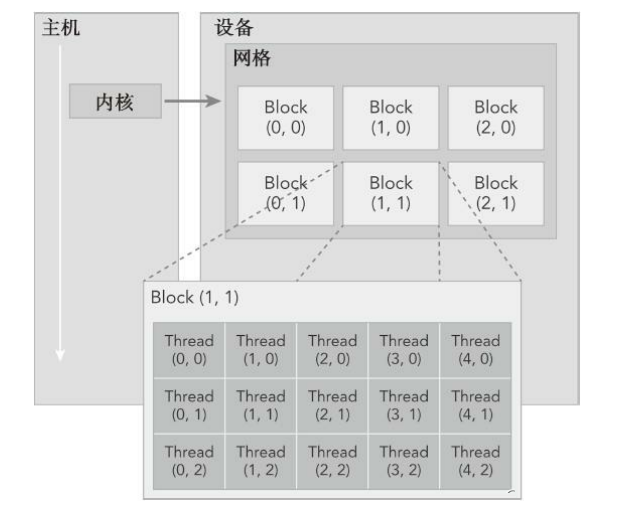
线程(Thread)
-
最基本的执行单元
-
每个线程有唯一的ID(threadIdx)
-
执行相同的代码(SIMT模型 - 单指令多线程)
线程块(Block)
-
由多个线程组成(最多1024个线程)
-
块内的线程可以:
-
通过共享内存(Shared Memory)通信
-
通过同步点(__syncthreads())同步
-
-
每个块有唯一的ID(blockIdx)
网格(Grid)
-
由多个线程块组成
-
网格中的所有线程执行相同的核函数(Kernel)
-
网格中的块可以按一维、二维或三维组织
线程全局索引计算
在CUDA编程中,正确计算线程的全局索引是高效利用GPU并行计算能力的关键。全局索引决定了每个线程处理的数据位置,下面详细介绍不同维度的线程全局索引计算方法。
一维网格与一维线程块
这是最简单的组织形式,常用于处理线性数组:
__global__ void kernel(float* data) {
// 计算全局索引
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// 使用全局索引访问数据
data[tid] = ...;
}
// 调用示例
int numBlocks = (arraySize + threadsPerBlock - 1) / threadsPerBlock;
kernel<<<numBlocks, threadsPerBlock>>>(deviceData);计算方式:
-
blockIdx.x: 当前线程块在网格中的索引 -
blockDim.x: 每个线程块中的线程数 -
threadIdx.x: 当前线程在线程块中的索引
二维网格与二维线程块
常用于处理图像或矩阵:
__global__ void kernel(float* data, int width) {
// 计算全局行列索引
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
// 计算线性内存索引
int tid = row * width + col;
data[tid] = ...;
}
// 调用示例
dim3 blocks(ceil(width/16.0), ceil(height/16.0));
dim3 threads(16, 16); // 16x16=256 threads per block
kernel<<<blocks, threads>>>(deviceData, width);计算方式:
-
行索引:
blockIdx.y * blockDim.y + threadIdx.y -
列索引:
blockIdx.x * blockDim.x + threadIdx.x -
线性内存索引:
行索引 * 矩阵宽度 + 列索引
三维网格与三维线程块
用于处理体积数据或更高维度的数据:
__global__ void kernel(float* data, int width, int height) {
// 计算全局索引
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int z = blockIdx.z * blockDim.z + threadIdx.z;
// 计算线性内存索引
int tid = z * width * height + y * width + x;
data[tid] = ...;
}
// 调用示例
dim3 blocks(ceil(dimX/8.0), ceil(dimY/8.0), ceil(dimZ/8.0));
dim3 threads(8, 8, 8); // 8x8x8=512 threads per block
kernel<<<blocks, threads>>>(deviceData, width, height);通用计算公式
对于N维网格和线程块,全局索引可以表示为:
// 对于第i维
globalIdx_i = blockIdx.i * blockDim.i + threadIdx.i;线性内存索引的计算取决于数据的存储方式(行优先或列优先)。
边界检查
在实际应用中,必须添加边界检查以防止越界访问:
__global__ void kernel(float* data, int N) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// 边界检查
if (tid < N) {
data[tid] = ...;
}
}网格跨度(Grid Stride)模式
对于数据量大于线程总数的情况,可以使用网格跨度模式:
__global__ void kernel(float* data, int N) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int stride = gridDim.x * blockDim.x; // 总线程数
for (int i = tid; i < N; i += stride) {
data[i] = ...;
}
}这种方法可以处理任意大小的数据,同时保持较高的GPU利用率。

















 5652
5652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









