







一、TRPO
TRPO算法是Shulman博士为了解决普通的策略梯度算法无法保证性能单调非递减而提出来的方法。也就是说,普通的策略梯度算法无法解决更新步长的问题,对于普通的策略梯度方法,如果更新步长太大,则容易发散;如果更新步长太小,即使收敛,收敛速度也很慢。
Shulman并不从策略梯度的更新步长下手,而是换了一个思路:更换优化函数。通过理论推导和分析,Shulman找到一个替代损失函数(Surrogate loss),最终将强化学习策略更新步转化为如下优化问题:
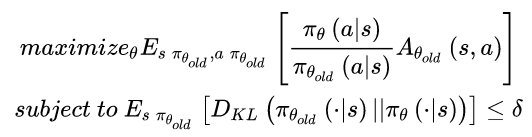
TRPO的标准解法是将目标函数进行一阶近似,约束条件利用泰勒进行二阶展开,然后利用共轭梯度的方法求解最优的更新参数。
然而当策略选用深层神经网络表示时,TRPO的标准解法计算量会非常大。因为共轭梯度法需要将约束条件进行二阶展开,二阶矩阵的计算量非常大。
二、PPO1
PPO在原目标函数的基础上添加了KL divergence 部分,用来表示两个分布之前的差别,差别越大则该值越大。那么施加在目标函数上的惩罚也就越大,因此要尽量使得两个分布之间的差距小,才能保证较大的目标函数。
TRPO 与 PPO 之间的差别在于它使用了 KL divergence 作为约束。但是这使得TRPO相对而言更难计算,因此较少使用。
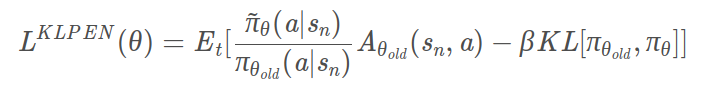
图1 Loss(KLPEN)
PPO是TRPO的一阶近似,可以应用到大规模的策略更新中。
图2 PPO1算法
从伪代码我们很清楚地看到,PPO利用了TRPO推导出来的损失函数,并用随机梯度下降的方法更新参数,其中正则项是为了控制更新的策略参数离当前的策略参数不要太远。
三、PPO2
OpenAI将它们的最新的PPO算法也公开了。新的PPO算法对替代目标函数进行了进一步的改进,让优化过程变得更加简洁。
PPO2引入了Clip函数, 新的替代损失函数为:
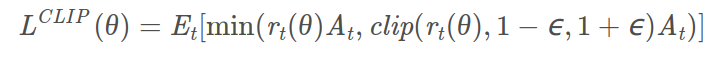
图3 Loss(CLIP)
其中: 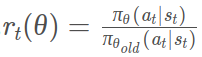
PPO2算法:

图4 PPO2算法















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









