






二、蒙特卡洛采样
假设我们能从一个目标概率分布p(x)中采样到一系列的样本(粒子),(至于怎么生成服从p(x)分布的样本,这个问题先放一放),那么就能利用这些样本去估计这个分布的某些函数的期望值。譬如:
上面的式子其实都是计算期望的问题,只是被积分的函数不同。
蒙特卡洛采样的思想就是用平均值来代替积分,求期望:
这可以从大数定理的角度去理解它。我们用这种思想去指定不同的f(x)以便达到估计不同东西的目的。比如:要估计一批同龄人的体重,不分男女,在大样本中男的有100个,女的有20个,为了少做事,我们按比例抽取10个男的,2个女的,测算这12个人的体重求平均就完事了。注意这里的按比例抽取,就可以看成从概率分布p(x)中进行抽样。
下面再看一个稍微学术一点的例子:
假设有一粒质地均匀的骰子。规定在一次游戏中,连续四次抛掷骰子,至少出现一次6个点朝上就算赢。现在来估计赢的概率。我们用来表示在第n次游戏中,第k次投掷的结果,k=1...4。对于分布均匀的骰子,每次投掷服从均匀分布,即:
这里的区间是取整数,1,2,3,4,5,6,代表6个面。由于每次投掷都是独立同分布的,所以这里的目标分布p(x)也是一个均匀分布。一次游戏就是
空间中的一个随机点。
为了估计取胜的概率,在第n次游戏中定义一个指示函数:
其中,指示函数I{x }是指,若x的条件满足,则结果为1,不满足结果为0。回到这个问题,这里函数 f()的意义就是单次游戏中,若四次投掷中只要有一个6朝上,f()的结果就会是1。由此,就可以估计在这样的游戏中取胜的期望,也就是取胜的概率:
当抽样次数N足够大的时候,上式就逼近真实取胜概率了,看上面这种估计概率的方法,是通过蒙特卡洛方法的角度去求期望达到估计概率的目的。是不是就跟我们抛硬币的例子一样,抛的次数足够多就可以用来估计正面朝上或反面朝上的概率了。
当然可能有人会问,这样估计的误差有多大,对于这个问题,有兴趣的请去查看我最下面列出的参考文献2。(啰嗦一句:管的太多太宽,很容易让我们忽略主要问题。博主就是在看文献过程中,这个是啥那个是啥,都去查资料,到头来粒子滤波是干嘛完全不知道了,又重新看资料。个人感觉有问题还是先放一放,主要思路理顺了再关注细节。)
接下来,回到我们的主线上,在滤波中蒙特卡洛又是怎么用的呢?
由上面我们知道,它可以用来估计概率,而在上一节中,贝叶斯后验概率的计算里要用到积分,为了解决这个积分难的问题,可以用蒙特卡洛采样来代替计算后验概率。
假设可以从后验概率中采样到N个样本,那么后验概率的计算可表示为:
其中,在这个蒙特卡洛方法中,我们定义,是狄拉克函数(dirac delta function),跟上面的指示函数意思差不多。
看到这里,既然用蒙特卡洛方法能够用来直接估计后验概率,现在估计出了后验概率,那到底怎么用来做图像跟踪或者滤波呢?要做图像跟踪或者滤波,其实就是想知道当前状态的期望值:
(1)
也就是用这些采样的粒子的状态值直接平均就得到了期望值,也就是滤波后的值,这里的 f(x) 就是每个粒子的状态函数。这就是粒子滤波了,只要从后验概率中采样很多粒子,用它们的状态求平均就得到了滤波结果。
思路看似简单,但是要命的是,后验概率不知道啊,怎么从后验概率分布中采样!所以这样直接去应用是行不通的,这时候得引入重要性采样这个方法来解决这个问题。
三、重要性采样
无法从目标分布中采样,就从一个已知的可以采样的分布里去采样如 q(x|y),这样上面的求期望问题就变成了:
(2)式
其中
由于:
所以(2)式可以进一步写成:
(3)式
上面的期望计算都可以通过蒙特卡洛方法来解决它,也就是说,通过采样N个样本,用样本的平均来求它们的期望,所以上面的(3)式可以近似为:
其中:
这就是归一化以后的权重,而之前在(2)式中的那个权重是没有归一化的。
注意上面的(4)式,它不再是(1)式中所有的粒子状态直接相加求平均了,而是一种加权和的形式。不同的粒子都有它们相应的权重,如果粒子权重大,说明信任该粒子比较多。
到这里已经解决了不能从后验概率直接采样的问题,但是上面这种每个粒子的权重都直接计算的方法,效率低,因为每增加一个采样,p( x(k) |y(1:k))都得重新计算,并且还不好计算这个式子。所以求权重时能否避开计算p(x(k)|y(1:k))?而最佳的形式是能够以递推的方式去计算权重,这就是所谓的序贯重要性采样(SIS),粒子滤波的原型。
下面开始权重w递推形式的推导:
假设重要性概率密度函数
后验概率密度函数的递归形式可以表示为:
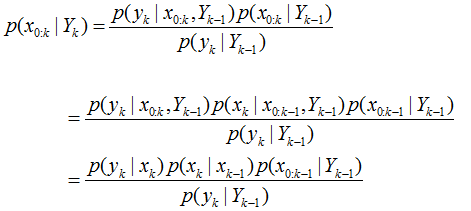
其中,为了表示方便,将 y(1:k) 用 Y(k) 来表示,注意 Y 与 y 的区别。同时,上面这个式子和上一节贝叶斯滤波中后验概率的推导是一样的,只是之前的x(k)变成了这里的x(0:k),就是这个不同,导致贝叶斯估计里需要积分,而这里后验概率的分解形式却不用积分。
粒子权值的递归形式可以表示为:
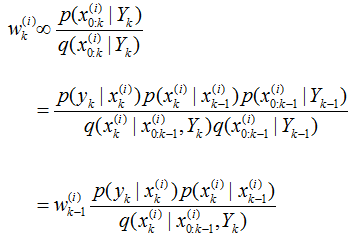 ( 5)式
( 5)式
注意,这种权重递推形式的推导是在前面(2)式的形式下进行推导的,也就是没有归一化。而在进行状态估计的公式为
四、Sequential Importance Sampling (SIS) Filter
在实际应用中我们可以假设重要性分布q()满足:
这个假设说明重要性分布只和前一时刻的状态x(k-1)以及测量y(k)有关了,那么(5)式就可以转化为:
在做了这么多假设和为了解决一个个问题以后,终于有了一个像样的粒子滤波算法了,他就是序贯重要性采样滤波。
下面用伪代码的形式给出这个算法:
----------------------pseudo code-----------------------------------
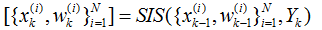
For i=1:N
(1)采样:;
(2)根据递推计算各个粒子的权重;
End For
粒子权值归一化。粒子有了,粒子的权重有了,就可以由(4)式,对每个粒子的状态进行加权去估计目标的状态了。
-----------------------end -----------------------------------------------
这个算法就是粒子滤波的前身了。只是在实际应用中,又发现了很多问题,如粒子权重退化的问题,因此就有了重采样( resample ),就有了基本的粒子滤波算法。还有就是重要性概率密度q()的选择问题,等等。都留到下一章 去解决。
在这一章中,我们是用的重要性采样这种方法去解决的后验概率无法采样的问题。实际上,关于如何从后验概率采样,也就是如何生成特定概率密度的样本,有很多经典的方法(如拒绝采样,Markov Chain Monte Carlo,Metropolis-Hastings 算法,Gibbs采样),这里面可以单独作为一个课题去学习了,有兴趣的可以去看看《统计之都 的一篇博文》,强烈推荐,参考文献里的前几个也都不错。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









