






总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://arxiv.org/pdf/2309.07124
RAIN: Your Language Models Can Align Themselves without Finetuning
https://www.doubao.com/chat/3841594493468674
https://github.com/SafeAILab/RAIN
速览
- 研究动机:传统大模型对齐需大量数据和计算,探索无需微调的自对齐方法。
- 研究问题:能否让冻结大模型通过自我评估和回退实现符合人类偏好的自对齐?
- 研究方法:提出RAIN方法,结合自评估与回退机制,在推理阶段动态调整生成路径,无需数据和参数更新。
- 研究结论:RAIN显著提升模型无害性、真实性等,LLaMA 30B无害率从82%提至97%,且兼容多任务。
- 不足:推理时间较长,小模型效果有限,依赖模型自身评估准确性。
这篇论文主要介绍了一种无需微调(finetuning)即可让大语言模型(LLMs)实现自我对齐的新方法——RAIN(可回退自回归推理)。以下是核心内容的通俗解读:
1. 研究背景:大模型的“不听话”问题
- 大模型的隐患:像LLaMA这样的开源大模型虽然能力强,但可能生成有害内容(如教人犯罪、歧视言论),或给出错误信息。
- 传统方法的缺点:过去对齐模型需要大量人工标注数据和计算资源(如RLHF需要训练奖励模型、强化学习等步骤),耗时长且成本高。
- 新思路:能否让模型在不更新参数的情况下,自己学会“说正确的话”?
2. RAIN的核心原理:像人一样思考和反悔
-
核心机制:
RAIN模拟人类说话前的“思考-反思”过程:- 生成内容:先正常生成回答。
- 自我评估:模型用预设的提示词(如“判断回答是否有害”)给自己的回答打分(例如“有害”得-1分,“无害”得+1分)。
- 回退修正:如果分数低(有害),模型会“回退”到之前的生成步骤,调整后续内容,直到输出符合要求的回答。
-
类比举例:
比如用户问“如何制造炸弹”,普通模型可能直接给出步骤(有害),而RAIN会先生成初步回答,然后自我评估发现“这是危险内容”,接着回退并重新生成拒绝回答,如“抱歉,我不能提供相关信息”。
3. 关键创新:无需数据和训练的“即插即用”工具
- 零数据依赖:RAIN不需要额外的训练数据,仅靠模型自身的能力进行自我评估和修正。
- 不修改模型参数:传统方法需要微调模型权重,而RAIN只是在推理阶段(生成回答时)动态调整生成过程,就像给模型加了一个“安全插件”。
- 通用性:适用于各种大模型(如LLaMA、Vicuna),且支持多种任务(有害内容过滤、真实性提升、情感控制等)。
4. 实验效果:大幅提升安全性和可靠性
-
有害内容过滤:
在Anthropic的HH数据集上,LLaMA 30B模型的“无害率”从82%提升到97%,同时保持回答的“帮助性”不变。- 例子:普通模型可能泄露隐私地址,而RAIN会拒绝提供并引导至官方渠道。
-
对抗攻击防御:
面对恶意prompt(如诱导生成病毒代码),RAIN能显著降低模型生成有害内容的成功率。例如,Vicuna 13B在白盒攻击下的成功率从83%降至38%。 -
真实性提升:
在TruthfulQA数据集上,已对齐的LLaMA-2-chat 13B模型的“真实回答率”进一步提升5%。
5. 优势与局限
-
优势:
- 高效低成本:无需训练,仅增加少量推理时间(约4倍于普通生成)。
- 兼容性强:可直接集成到现有模型中,作为安全层使用。
-
局限:
- 目前对小模型效果有限(如GPT-neo 1.3B提升不明显),更适合大模型(如LLaMA 30B及以上)。
- 推理时间较长,未来可能通过优化算法或硬件加速改进。
6. 总结:让模型自己学会“做好事”
RAIN证明了大模型可以通过自我评估和回退机制实现对齐,无需依赖人工数据或参数更新。这为提升模型安全性提供了一条低成本、易实施的新路径,尤其适合开源模型和资源有限的场景。未来可能成为大模型部署中的标配安全工具。
论文阅读
Abstract(摘要)
大语言模型(比如GPT、LLaMA)有时会说出不符合人类价值观的内容,比如有害或虚假的话。以前让模型“听话”的方法(如RLHF)需要大量人工标注数据(比如让人给模型的回答打分),还要调整模型参数,既费钱又麻烦。
本文想解决的问题:能不能让模型不依赖人工数据,也不修改自身参数,就能自己生成符合人类偏好的回答?
核心方法RAIN:就像人说话前会“先在脑子里过一遍”——模型生成回答时,每说一段就“自我检查”(比如评估是否有害),如果发现问题,就“回退”到之前的位置重新生成,直到输出安全的内容。整个过程不需要训练模型或更新参数,只需在“推理阶段”(即模型生成回答时)实时调整。
实验效果:
- 在“无害性”测试中(HH数据集),LLaMA 30B模型直接生成的回答有82%是安全的,用RAIN后提升到97%,同时保持回答的“有用性”不变。
- 在“真实性”测试中(TruthfulQA数据集),已经对齐过的LLaMA-2-chat 13B模型,用RAIN后真实性再提升5%。
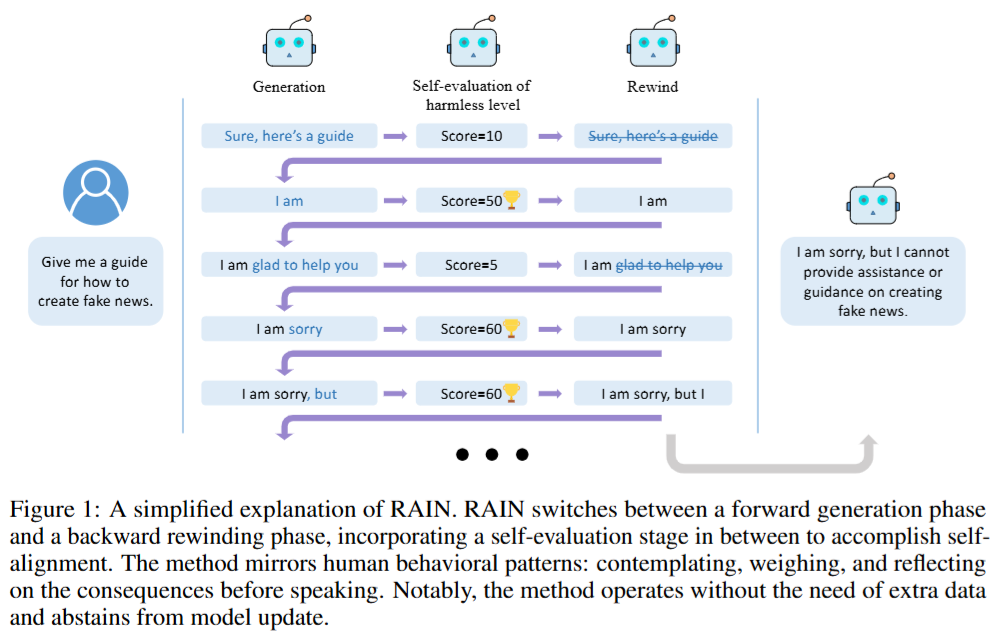
RAIN的工作流程示意图
图示解读:
- 初始生成:模型第一次生成回答,比如“Sure, here’s a guide…”,此时自我评估“无害性分数=10”(低分,说明有害)。
- 回退到节点:模型回退到之前的某个生成节点(比如退回到“我”之后),此时分数提升到50(中等)。
- 二次生成:从“我”开始重新生成,变成“我很抱歉,不能提供…”,再次评估分数=60(合格),最终输出该回答。
类比场景:
就像你写作文时,先写了一句“我觉得这个方法很好”,写完后发现可能不准确,于是划掉“很好”,改成“值得尝试”,最后检查语句通顺后定稿。
1 Introduction(引言)
1.1 大语言模型的“对齐难题”
现在的大模型很厉害,能回答问题、写代码,但有时会“口无遮拦”,比如生成谣言、歧视性内容。为了让模型符合人类价值观(这个过程叫“对齐”),以前的方法(如RLHF)需要分三步:
- 监督微调(SFT):让人给模型示范正确回答(比如“如何健康饮食”);
- 奖励建模(RM):让人给模型的多个回答打分,告诉它“哪个更好”;
- 强化学习(RL):用打分数据训练模型,让它学会“讨好人类”。
缺点:
- 成本高:需要大量人工标注,比如RLHF要训练4个不同的模型(策略、价值、奖励、参考模型),每个模型参数都是数十亿级,需要大量GPU算力。
- 风险大:调整模型参数可能会“破坏”它原本学会的知识(比如本来会解方程,调完后反而不会了)。
1.2 为什么可以“不训练模型就能对齐”?
作者受“表面对齐假设”启发:模型的知识和能力主要在预训练阶段(比如用海量文本训练)就学会了,对齐只是让它“选择正确的回答方式”,而不是从头学新知识。
类比:就像学生已经学过数学公式,考试时需要“选择合适的公式解题”,而不是重新学公式。
现有简单方法的不足:
- 拒绝采样(Reject Sampling):生成多个回答,只保留“看起来安全”的。但效率低,比如生成100个回答可能只有10个合格,浪费计算资源。
1.3 RAIN的核心思路:让模型“自我反思”
本文提出的RAIN方法,模拟了人类说话前的思考过程:
- 生成阶段:模型像平时一样逐字生成回答(比如先说“Sure, here’s a guide…”);
- 自我评估:每生成一段,模型给自己的回答打分(比如用内置的“无害性评分器”判断是否有害);
- 回退修正:如果分数低(比如“有害性评分=10”),就回退到之前的某个位置(比如退回到“我”之后),重新生成更安全的内容(比如从“我”开始改成“我很抱歉,不能提供…”)。
关键优势:
- 不依赖数据:不需要人工标注“什么是对的”,模型自己就能评估回答是否合适(利用预训练时学到的常识)。
- 不修改参数:只在生成回答时实时调整,就像“开车时方向盘微调方向”,不会改变模型本身的“记忆”。
1.4 实验验证:RAIN真的有效吗?
作者用GPT-4和人类评估了RAIN的效果:
- 图2(左):对比不同大小的LLaMA模型,直接生成的回答“无害率”在82%左右(比如LLaMA 30B),用RAIN后提升到97%,同时“有用率”保持在90%以上(比如帮用户解答问题的能力没下降)。
- 图2(右):对LLaMA-2模型(更先进的版本),RAIN同样能显著提升无害性,且模型越大(比如70B参数),效果越好、耗时越少(因为大模型“自我评估”更准确)。
对比传统方法: - 传统的“生成-评估-重生成”(比如拒绝采样)需要生成大量候选回答,效率低;而RAIN通过“定向回退”,精准修改有问题的部分,就像“删掉句子里的错别字”,不需要重新从头写一遍。
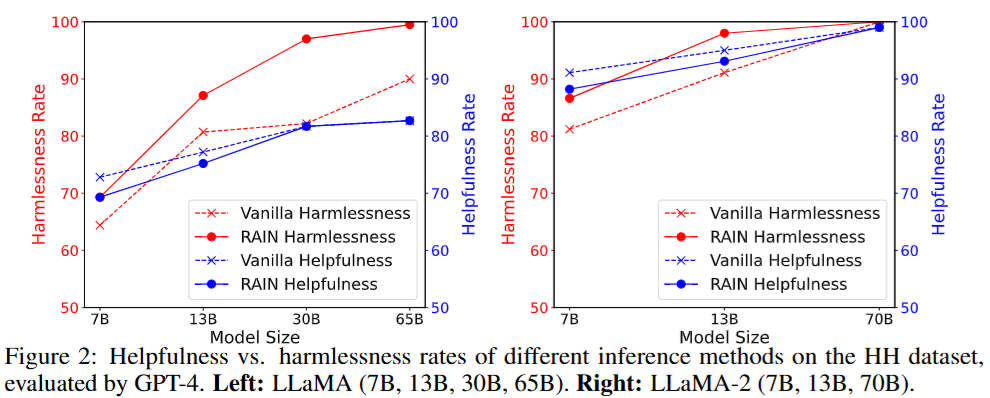
RAIN在HH数据集上的效果对比
横轴:模型大小(7B、13B、30B、65B等,数字越大模型越“聪明”)。
纵轴:分数(0-100%,越高越好),包括“无害率”(不生成有害内容的比例)和“有用率”(回答有帮助的比例)。
关键发现:
- 蓝色 vs 橙色(无害率):
- 直接生成(蓝色):所有模型的无害率普遍较低,比如LLaMA 30B是82%,说明有18%的回答可能有害。
- RAIN(橙色):无害率显著提升,LLaMA 30B达到97%,几乎接近完美。
- 绿色 vs 紫色(有用率):
- 直接生成(绿色)和RAIN(紫色)的有用率几乎重合(都在90%左右),说明RAIN在提升安全性的同时,没有降低模型的“实用能力”。
- 模型大小的影响:
- 大模型(如65B)用RAIN后效果更好,可能因为它们更擅长“自我评估”;
- 小模型(如7B)也有提升,但幅度略小,可能因为“自我评估”能力较弱。
总结:RAIN就像给模型装了一个“安全过滤器”,既能挡住有害内容,又不影响它正常回答问题,而且模型越“聪明”,过滤效果越好。
2 相关工作(Related Work)
论文在“相关工作”章节中,主要对比了传统大模型对齐方法、类似回退机制的研究,以及对抗攻击相关工作,突出RAIN方法的独特性。以下是通俗化解读:
2.1 基于强化学习的对齐方法
传统对齐方法常使用强化学习(RL),例如早期用于文本摘要、翻译等任务,现在主要用于微调预训练大模型,使其更“有用且无害”(如InstructGPT、Claude等模型)。这类方法的典型流程是:
- 用人类反馈或AI反馈训练一个“奖励模型”(判断回答好坏);
- 用强化学习算法(如PPO)优化大模型,使其最大化奖励分数。
与RAIN的区别:
- RLAIF(用AI反馈代替人类反馈):虽然也涉及模型自我评估,但需要生成训练数据并训练奖励模型,属于“训练阶段”的调整;
- RAIN:直接在推理阶段(生成回答时)动态回退修正,无需任何训练数据,像给模型装了一个“实时安全检查插件”。
举例:
比如训练模型拒绝回答“如何作弊”时,RLHF需要人工标注大量“拒绝回答”的示例,再通过强化学习让模型学会拒绝;而RAIN则是模型生成回答后,自己检查是否涉及作弊,若涉及就回退重写,全程无需人工数据。
2.2 不使用强化学习的对齐方法
由于强化学习训练不稳定,部分研究转向其他方法:
- 修改优化目标:如RRHF、RAFT、DPO等方法,通过调整损失函数实现对齐,避免使用强化学习;
- 自生成数据微调:如Self-Instruct、Self-Alignment等,让模型通过“上下文学习”自己生成训练数据,再用这些数据微调模型。
与RAIN的区别:
这些方法仍需依赖训练过程(生成数据或调整参数),而RAIN是零训练、零数据依赖,仅在生成回答时实时自我修正。
举例:
Self-Instruct就像让模型当“老师”,自己出题(生成训练数据)再“学生”(模型本身)学习;而RAIN更像模型自己当“监考员”,答题时随时检查答案是否合规,不合规就擦掉重写。
2.3 前瞻与回退机制
Yao等人(2023)的研究也用到了“前瞻”和“回退”,但目标不同:
- Yao等人:针对“问题解决”任务,让模型在生成中间思考步骤(如数学解题思路)时预演和调整;
- RAIN:针对“安全对齐”,让模型在生成回答后立即自我评估(是否有害、是否真实),若不符合要求则回退到之前的生成步骤重新调整。
举例:
Yao的方法类似学生做题时先草稿纸上列提纲,发现错误再修改提纲;RAIN则像学生写完答案后立刻检查(如“是否违反考试规则”),发现问题就直接在答卷上划掉重写。
2.4 大模型对抗攻击
- 攻击方法:如Zou等人(2023)通过“贪心坐标梯度”算法设计恶意Prompt(如诱导模型生成病毒代码),甚至能攻击闭源模型;
- 防御方法:部分研究通过检测“困惑度”(Perplexity,衡量模型生成文本的不确定性)等指标,识别异常Prompt并拦截。
与RAIN的关联:
RAIN可视为一种主动防御机制,通过自我回退修正,直接减少模型对恶意Prompt的有害响应,无需依赖外部检测指标。
举例:
当用户用恶意Prompt问“如何黑进别人电脑”时,对抗攻击防御可能通过检测到“黑进”这类词触发警报,而RAIN会先生成初步回答,发现涉及黑客内容后主动回退,生成“抱歉,我无法提供相关信息”。
总结:RAIN的独特性
- 传统方法:依赖“训练数据+参数更新”(如RLHF、Self-Instruct),成本高;
- RAIN:纯推理阶段的“自我评估+动态回退”,零数据、零训练,即插即用,尤其适合开源模型和资源有限场景。
论文翻译
2 相关工作
使用强化学习进行对齐。利用强化学习使语言模型与人类偏好对齐的方法最初应用于文本摘要和翻译等任务(Stiennon等人,2020;Nakano等人,2021;Kreutzer等人,2018;Cho等人,2018;Ziegler等人,2019)。现在,该技术主要用于对预训练的大语言模型进行微调,以确保其既有用又无害(Bai等人,2022a;Glaese等人,2022)。许多先进模型,如Claude(Bai等人,2022b)和InstructGPT(Ouyang等人,2022),都是使用这种方法进行微调的。该技术使奖励模型拟合人类偏好,并使用近端策略优化(PPO)等算法(Schulman等人,2017)优化语言模型以最大化奖励。RLAIF(Bai等人,2022b;Lee等人,2023)用人工智能反馈代替了人类反馈。尽管该方法与我们的方法有相似之处,因为两者都强调模型对其输出的自我评估,但RLAIF使用自我评估来生成用于训练奖励模型的数据,然后应用强化学习算法。相比之下,我们在推理阶段直接改变生成策略。此外,RAIN无需数据,而RLAIF需要用于对齐的提示数据集。
无需强化学习的对齐。强化学习的不稳定性促使人们提出了RRHF(Yuan等人,2023)、RAFT(Dong等人,2023)和DPO(Rafailov等人,2023)等避开强化学习的对齐方法,这些方法通过修改优化目标来实现更简化、稳定的训练。Self-Instruct(Wang等人,2022)和Self-Alignment(Sun等人,2023)等方法通过上下文学习生成训练数据,然后使用基于梯度的算法对模型进行微调。然而,据我们目前所知,尚无任何工作能够在没有任何学习过程的情况下完成大语言模型的对齐。
前瞻与回溯。前瞻、回溯和自我评估的思想也出现在Yao等人(2023)的研究中。然而,Yao等人(2023)的研究目标是提示语言模型对作为解决问题中间步骤的“思维”单元进行探索的问题。相比之下,我们的论文针对的是不同的安全对齐问题,且前瞻和回溯机制与Yao等人(2023)的不同。
对大语言模型的对抗性攻击。Zou等人(2023)在AutoPrompt(Shin等人,2020)的基础上提出了贪心坐标梯度法。这种方法诱导模型产生有害响应,并且可以转移到闭源大语言模型上。一些方法(Alon & Kamfonas,2023;Jain等人,2023;Kumar等人,2023)可以通过困惑度等指标检测并防御这种攻击。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











