






【引用格式】:Li Z, Snavely N. Megadepth: Learning single-view depth prediction from internet photos[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 2041-2050.
【网址】:论文地址https://openaccess.thecvf.com/content_cvpr_2018/papers/Li_MegaDepth_Learning_Single-View_CVPR_2018_paper.pdf
目录
一、瓶颈问题
- 现有的基于3D传感器的数据集存在一些限制,如仅适用于室内场景(NYU)、训练样本数量有限(Make3D)、深度采样稀疏(LITTI)等。
- 从MVS方法得到的深度数据通常包含噪声和不准确的深度估计,特别是对于动态物体(如人、车辆)和某些难以重建的物体(如细长的物体、透明物体等)。
二、本文贡献
- 文章利用互联网上大量存在的多视角照片集合作为训练数据的来源,通过structure-from-motion(SfM)和多视图立体(MVS)技术生成密集的深度图,即Megadepth数据集。
- 文章提出了新的数据清洗方法和增强技术,包括改进的MVS算法、语义分割辅助的深度图过滤,以及利用语义信息自动生成的序数深度关系,从而提高了训练数据的质量。
- 文章提出了一个端到端的深度学习算法,用于从单张照片预测深度,评估不同的网络架构(如VGG、ResNet和“hourglass”网络),并设计了一个包含尺度不变数据项、多尺度梯度匹配项和序数深度损失项的复合损失函数。
- 做了一系列实验验证了在MegaDepth数据集上训练的模型具有强大的泛化能力。
三、解决方案
1、Megadepth数据集
1.1 照片收集
文章从Flickr下载了一组著名地标图片(Landmarks 10K数据集),这些照片覆盖了全球各地的地标建筑。
1.2 3D模型重建
文章使用COLMAP软件(最先进的SfM系统【Structure-from-Motion Revisited】(用于重建相机姿势和稀疏点云)和MVS系统【Pixelwise View Selection for Unstructured Multi-View Stereo】)从每张照片集合中构建一个3D模型。首先通过SfM技术恢复相机的姿态和稀疏点云,然后使用MVS技术生成每个重建图像的密集深度图。
对于COLMAP软件构建的原始深度图像存在以下问题:
- MVS算法在处理图像中可能会遇到匹配错误或深度估计不准确的情况,导致深度图中出现噪声和异常值。
- MVS算法趋向于不重建或错误重建在多个图像中出现动态变化的物体,例如人、车辆等。
- 在深度图中,尤其是在前景和背景物体的交界处,可能会出现深度不连续的现象。
- 可能会出现深度渗透的情况,即背景深度可能会错误地分配给前景物体。
- 对于细长的物体、复杂形状的物体或具有特殊材质的物体,难以准确的恢复它们的深度信息。
1.3 深度图的清洗和增强
- 设计了一种基于COLMAP的修改MVS算法,在深度估计中更保守。COLMAP迭代计算深度图中,在每个阶段试图确保附近深度图之间的几何一致性(问题:由于增加深度图一致性的一种方法是一致的预测背景深度,故导致背景深度倾向于吃掉前景图像)。因此文中提出在COLMAP的每个深度推断迭代中,比较像素在更新前后的深度值,并保留较小(更接近)的值。然后,使用中值滤波器来去除不稳定的深度值。
- 文中提出了三种语义分割用途。首先,使用这样的分割来去除前景区域中的虚假MVS深度;其次,使用分割作为标准,将每个照片分类为提供欧几里得深度或序数深度数据;最后,结合语义信息和MVS深度自动注释序数深度关系,用于帮助训练MVS无法重构的区域。
- 首先使用PSPNet运行语义分割,将像素分给三个子集:前景对象F(静态前景图像【雕像、喷泉】和动态对象【人、汽车】)、背景对象B(建筑物、塔、山脉)和SKy。然后,为了删除动态对象导致的虚假深度,文中设计:当发现前景掩膜中的像素有少于50%的像素具有重建的深度时,选择移除这些前景区域中的所有深度值,从而减少噪声和不准确的深度估计。
- 文中通过对重构像素的比例进行阈值处理来计算高质量深度图子集。如果大于30%的图像由有效的深度值组成,那么就保留该图像作为学习欧氏深度的训练集。否则,则用于自动生成训练数据来学习序数深度关系。
- 对于上述2中不满足学习欧氏深度的子集,文中设计了一种基于估计的3D几何和语义分割方法,来自动提取序数深度标签的新方法。对于图像中每个像素对(i,j),如果像素i属于前景区域F,而像素j属于背景区域B,则使像素i比像素j更接近相机,从而生成一个序数深度关系。
以上文中均未具体介绍,详细信息见论文的补充材料。

(自动生成的序数标记)
1.4 创建数据集
文中使用上述的方法从世界各地的地标密集重建200个3D模型,代表大约150K重建图像。在进行以上方法对图像过滤之后,剩下130K有效图像。其中大约100K图像用于欧几里得深度数据,其余30K图像用于推导序数深度数据。最后构建数据集出Megadepth,可通过网址:https://www.cs.cornell.edu/projects/megadepth/来获得。
2、深度估计网络
文中评估了几种在先前工作中用于单视图深度预测的网络框架,包括VGG、‘hourglass’网络和ResNet架构;通过对比这些网络在Megadepth数据集上的性能,‘hourglass’网络在深度预测任务上表现最佳。
2.1 损失函数
由于从SfM+MVS产生的3D数据只有相对尺度,而非绝对尺度,故不能直接比较预测深度和真实深度。这里,文中采用了尺度不变损失函数,包括数据项、梯度匹配项和序数深度损失项。
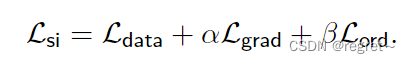
2.1.1 尺度不变数据项
采用Eigen和Fergus提出的损失函数【Depth Map Prediction from a Single Image using a Multi-Scale Deep Network】,计算预测的对数深度图和实际对数深度图之间差异的均方误差(MSE)。【可免受深度值尺度的影响】
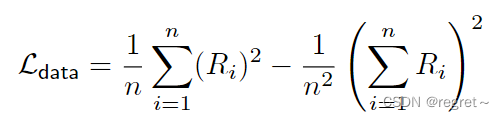
假设有一个预测的深度图L和真实深度图L*;
和
表示由像素位置i索引的相应单个对数深度值。对于上式中的Ri表示为:
.
n表示真实深度图中,有效深度值的数量。
2.1.2 多尺度尺度不变梯度匹配项
为了鼓励预测深度图具有平滑的梯度变化和清晰的深度不连续性,文中引入了一个多尺度尺度不变梯度匹配项。该项通过比较预测深度图和真实深度图在不同尺度上的梯度差异来定义。
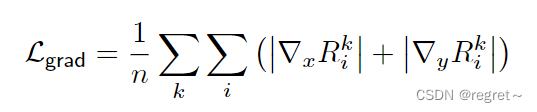
:位置i和尺度k处的对数深度差异图的值。
和
:分別表示沿水平方向和垂直方向的梯度。
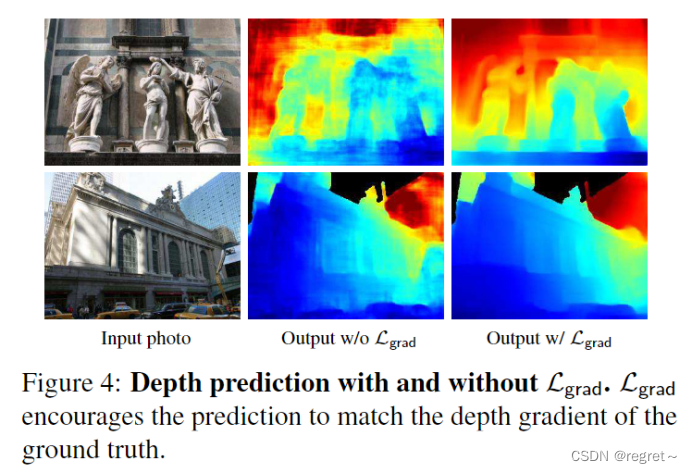
使用多尺度尺度不变梯度匹配项和不使用的对比。
2.1.3 序数深度损失项
受Chen等人的启发【Single-Image Depth Perception in the Wild】,文中设计了一个鲁邦的序数深度损失项,该项利用自动生成的序数深度关系来训练网络,用于鼓励网络学习正确的深度顺序。
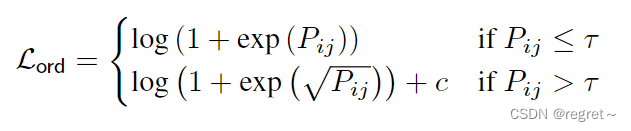
: 表示像素i和j之间的序数深度关系。
:表示自动标注的序数深度关系(如果像素i比j更远,则 = 1,否则为-1)。

2.2 训练设置
在 Megadepth 数据集中的 200 个重建模型中,随机选择 46 个来形成测试集(训练期间从未见过的位置)。对于剩下的 154 个模型,将每个单独模型的图像随机分成训练集和验证集,比率分别为 96% 和 4%。使用交叉验证设置 α = 0.5 和 β = 0.1。在 PyTorch 中实现我们的网络,并使用 Adam 训练 30 个 epoch,批量大小为 32。
2.3 评估指标
2.3.1 尺度不变均方根误差(si-RMSE)
si-RMSE是一种衡量预测深度图与真实深度图之间差异的度量,它考虑了深度值的尺度不变性。由于从SfM+MVS产生的深度数据只有相对尺度,而不包含绝对尺度信息,因此需要使用尺度不变的误差度量。
计算方式就是2.1.1中尺度不变数据项的计算。
2.3.2 SfM分歧率(SDR)
SDR是一种衡量预测深度图与基于SfM点云的序数深度关系一致性的度量。它专注于评估深度顺序的准确性,而不是绝对深度值的精确度。
对于预测深度图 D 和真实深度图 D*,对于每一对像素 i 和 j,计算它们的深度关系ord(Di, Dj) 和 ord(Di*, Dj*)。然后,计算预测深度关系和真实深度关系不一致的比例,即SDR。计算公式如下:
![]()
- P:具有有效深度值的像素对的集合
- 空心1():是指示函数,当预测的深度顺序与真实的深度顺序不一致时取值为1
ord( . )的计算如下:
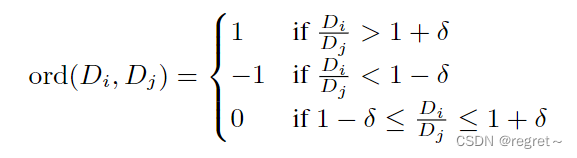
- 如果像素 i 的深度大于像素 j 的深则 ord(Di, Dj) = 1。
- 如果像素 i 的深度小于像素 j 的深度,则 ord(Di, Dj) = −1。
- 如果像素 i 和 j 的深度相等,则ord(Di, Dj) = 0。
- 为了容忍一定程度的深度值不确定性,设置了一个阈值δ。如果预测深度比真实深度大或者小不超过δ,则认为这两个深度值是相同的。
另外,下面实验中,提到了SDR=和SDR≠,分別表示了ord(Di, Dj)=0和ord(Di, Dj)≠0时的分歧率(不一致率)。
四、实验结果
1、在不同框架上进行的测试
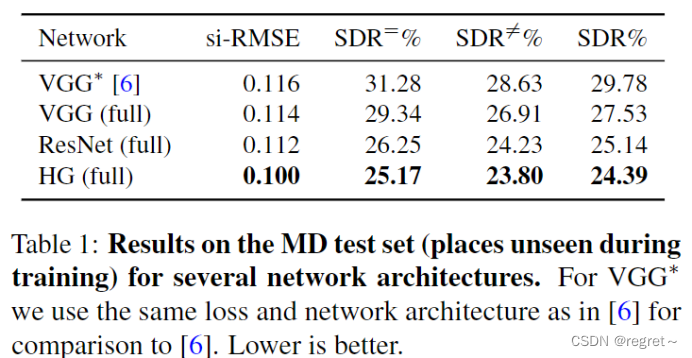
- VGG *: 使用VGG网络和Eigen等人 【Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture】 提出的损失函数和网络架构。
- VGG (full): 使用VGG网络和论文中提出的完整损失函数。
- ResNet (full): 使用ResNet网络和论文中提出的完整损失函数。
- HG (full): 使用"hourglass"网络和论文中提出的完整损失函数。
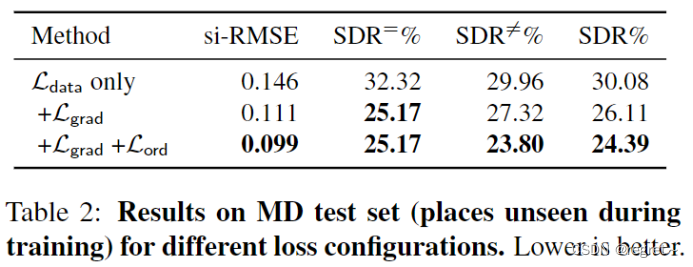
2、损失函数的消融实验
3、在三个数据集上的测试
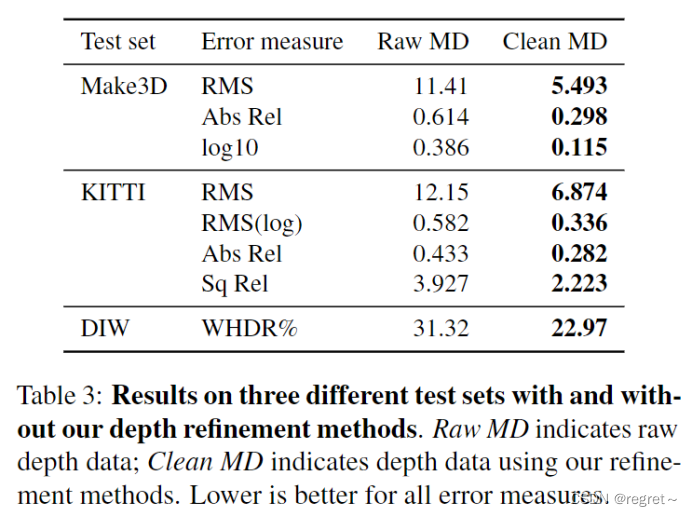
- Raw MD:原始MVS深度数据。
- Clean MD:经过清洗的深度数据。
- RMS:均方根误差,衡量预测深度图与真实深度图之间的差异。
- RMS(log): 对数尺度下的均方根误差,这是一个尺度不变的误差度量。
- Abs Rel: 绝对相对误差,考虑了深度值的比例差异。
- WHDR%: 加权人类不一致率,衡量预测深度图与人类标注的深度顺序之间的不一致程度。
- Sq Rel:平方相对误差。
- log10:对数误差,是一种尺度不变的误差度量。
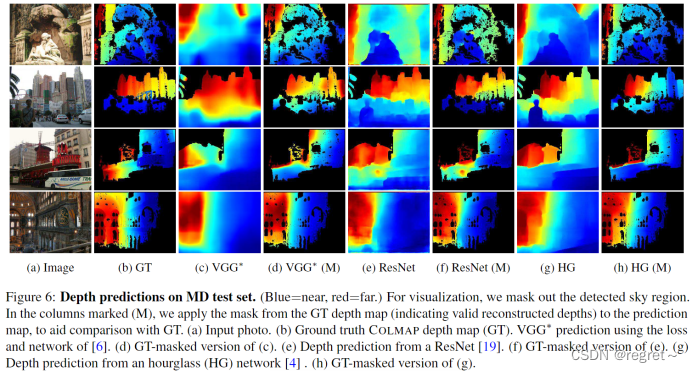
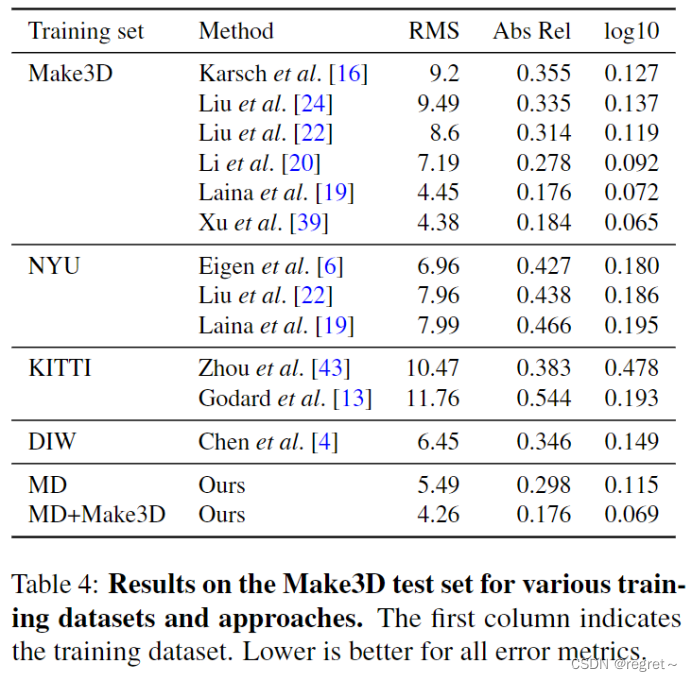
4、使用不同训练集训练在Make3D上进行测试

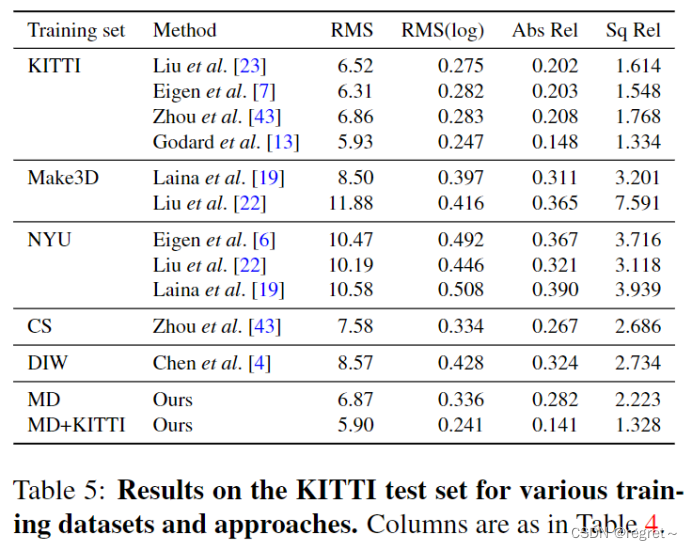
5、使用不同的训练集训练在KITTI上进行测试

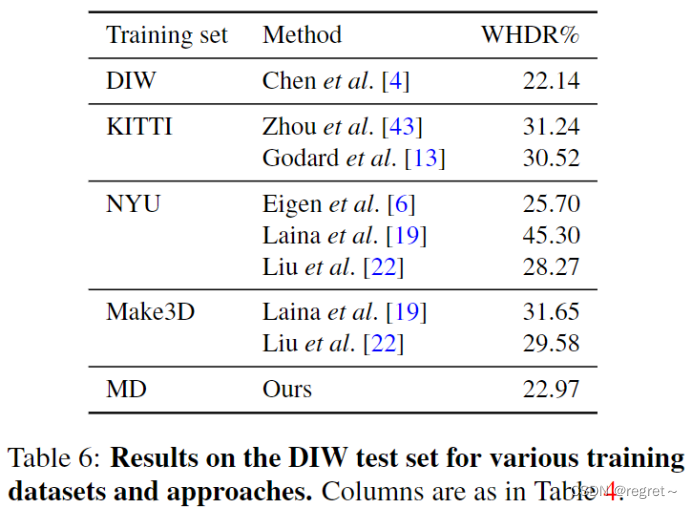
6、使用不同的训练集训练在DIW上进行测试


















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









