






【引用格式】:Sun J, Shen Z, Wang Y, et al. LoFTR: Detector-free local feature matching with transformers[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 8922-8931.
【开源代码】:https://github.com/zju3dv/LoFTR
目录
1.1 Local Feature Extraction(局部特征提取)
1.2 Local Feature Transformer (LoFTR) Module
1.3 Establishing Coarse-level Matches(建立粗级匹配)
1.4 Coarse-to-Fine Module(微调模块)
一、瓶颈问题
大多数现有的匹配放大都是有三个阶段工作:特征点检测、特征点描述和特征点匹配。然而,当在低纹理区域、重复模式、视角变化、光照变化和运动模糊等情况下难以提取可重复兴趣点,进而会导致特征点匹配失败。
二、本文贡献
- 提出了一种名为LoFTER的新型无检测器的局部图像特征匹配方法,使用了Transformer框架来处理图像特征,更好的获得全局上下文信息。
- LoFTER首先在粗略级别建立像素级的密集匹配,然后在此基础上细化出高质量的匹配,避免了传统方法中依赖于特征检测器的局限性。
- 分别在室内和室外数据集上进行实验,证明了其在多个图像匹配和相机姿态估计任务重优于现有的基于检测器和无检测器的特征匹配基线方法。
三、解决方案
1 LoFTER网络框架
LoFTER首先通过对图像进行卷积下采样以及上采样等操作,获得在原始图像1/8维度处的粗粒度特征表示和1/2维度处的细粒度特征表示;然后,将粗粒度特征表示进行Transformer特征提取;将得到的特征表示图进行特征匹配,获得粗匹配;然后将细粒度特征表示重新进行Transformer操作,对粗匹配进行微调,以获得像素级别匹配。
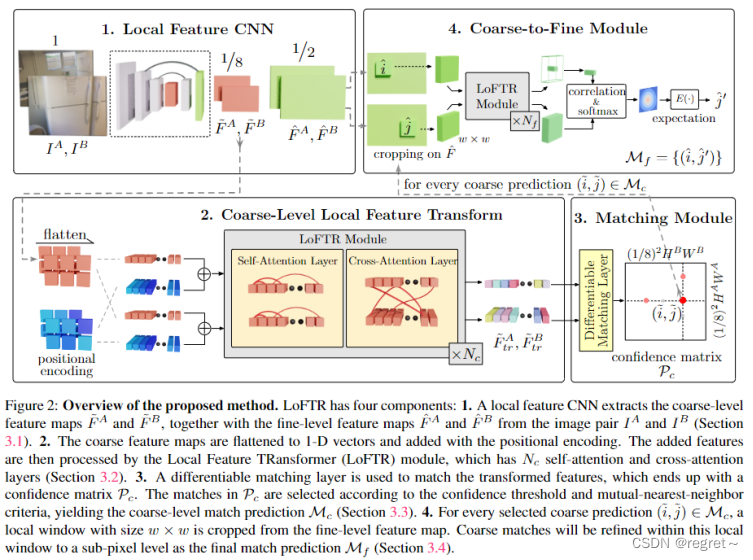
1.1 Local Feature Extraction(局部特征提取)
局部特征提取使用了带有特征金字塔(FPN)的标准卷积框架从两个图片中提取多层级的特征。文章使用和
表示粗略级别的特征图,大小是原始图像维度的1/8;使用
和
表示细级别特征图,大小是原始图像维度的1/2。
import torch.nn as nn
import torch.nn.functional as F
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution without padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, padding=0, bias=False)
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False)
class BasicBlock(nn.Module):
def __init__(self, in_planes, planes, stride=1):
super().__init__()
self.conv1 = conv3x3(in_planes, planes, stride)
self.conv2 = conv3x3(planes, planes)
self.bn1 = nn.BatchNorm2d(planes)
self.bn2 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
if stride == 1:
self.downsample = None
else:
self.downsample = nn.Sequential(
conv1x1(in_planes, planes, stride=stride),
nn.BatchNorm2d(planes)
)
def forward(self, x):
y = x
y = self.relu(self.bn1(self.conv1(y)))
y = self.bn2(self.conv2(y))
if self.downsample is not None:
x = self.downsample(x)
return self.relu(x+y)
class ResNetFPN_8_2(nn.Module):
"""
ResNet+FPN, output resolution are 1/8 and 1/2.
Each block has 2 layers.
"""
def __init__(self, config):
super().__init__()
# Config
block = BasicBlock
initial_dim = config['initial_dim']
block_dims = config['block_dims']
# Class Variable
self.in_planes = initial_dim
# Networks
self.conv1 = nn.Conv2d(1, initial_dim, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(initial_dim)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(block, block_dims[0], stride=1) # 1/2
self.layer2 = self._make_layer(block, block_dims[1], stride=2) # 1/4
self.layer3 = self._make_layer(block, block_dims[2], stride=2) # 1/8
# 3. FPN upsample
self.layer3_outconv = conv1x1(block_dims[2], block_dims[2])
self.layer2_outconv = conv1x1(block_dims[1], block_dims[2])
self.layer2_outconv2 = nn.Sequential(
conv3x3(block_dims[2], block_dims[2]),
nn.BatchNorm2d(block_dims[2]),
nn.LeakyReLU(),
conv3x3(block_dims[2], block_dims[1]),
)
self.layer1_outconv = conv1x1(block_dims[0], block_dims[1])
self.layer1_outconv2 = nn.Sequential(
conv3x3(block_dims[1], block_dims[1]),
nn.BatchNorm2d(block_dims[1]),
nn.LeakyReLU(),
conv3x3(block_dims[1], block_dims[0]),
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, dim, stride=1):
layer1 = block(self.in_planes, dim, stride=stride)
layer2 = block(dim, dim, stride=1)
layers = (layer1, layer2)
self.in_planes = dim
return nn.Sequential(*layers)
def forward(self, x):
# ResNet Backbone
x0 = self.relu(self.bn1(self.conv1(x)))
x1 = self.layer1(x0) # 1/2
x2 = self.layer2(x1) # 1/4
x3 = self.layer3(x2) # 1/8
# FPN
x3_out = self.layer3_outconv(x3)
x3_out_2x = F.interpolate(x3_out, scale_factor=2., mode='bilinear', align_corners=True)
x2_out = self.layer2_outconv(x2)
x2_out = self.layer2_outconv2(x2_out+x3_out_2x)
x2_out_2x = F.interpolate(x2_out, scale_factor=2., mode='bilinear', align_corners=True)
x1_out = self.layer1_outconv(x1)
x1_out = self.layer1_outconv2(x1_out+x2_out_2x)
return [x3_out, x1_out]
class ResNetFPN_16_4(nn.Module):
"""
ResNet+FPN, output resolution are 1/16 and 1/4.
Each block has 2 layers.
"""
def __init__(self, config):
super().__init__()
# Config
block = BasicBlock
initial_dim = config['initial_dim']
block_dims = config['block_dims']
# Class Variable
self.in_planes = initial_dim
# Networks
self.conv1 = nn.Conv2d(1, initial_dim, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(initial_dim)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(block, block_dims[0], stride=1) # 1/2
self.layer2 = self._make_layer(block, block_dims[1], stride=2) # 1/4
self.layer3 = self._make_layer(block, block_dims[2], stride=2) # 1/8
self.layer4 = self._make_layer(block, block_dims[3], stride=2) # 1/16
# 3. FPN upsample
self.layer4_outconv = conv1x1(block_dims[3], block_dims[3])
self.layer3_outconv = conv1x1(block_dims[2], block_dims[3])
self.layer3_outconv2 = nn.Sequential(
conv3x3(block_dims[3], block_dims[3]),
nn.BatchNorm2d(block_dims[3]),
nn.LeakyReLU(),
conv3x3(block_dims[3], block_dims[2]),
)
self.layer2_outconv = conv1x1(block_dims[1], block_dims[2])
self.layer2_outconv2 = nn.Sequential(
conv3x3(block_dims[2], block_dims[2]),
nn.BatchNorm2d(block_dims[2]),
nn.LeakyReLU(),
conv3x3(block_dims[2], block_dims[1]),
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, dim, stride=1):
layer1 = block(self.in_planes, dim, stride=stride)
layer2 = block(dim, dim, stride=1)
layers = (layer1, layer2)
self.in_planes = dim
return nn.Sequential(*layers)
def forward(self, x):
# ResNet Backbone
x0 = self.relu(self.bn1(self.conv1(x)))
x1 = self.layer1(x0) # 1/2
x2 = self.layer2(x1) # 1/4
x3 = self.layer3(x2) # 1/8
x4 = self.layer4(x3) # 1/16
# FPN
x4_out = self.layer4_outconv(x4)
x4_out_2x = F.interpolate(x4_out, scale_factor=2., mode='bilinear', align_corners=True)
x3_out = self.layer3_outconv(x3)
x3_out = self.layer3_outconv2(x3_out+x4_out_2x)
x3_out_2x = F.interpolate(x3_out, scale_factor=2., mode='bilinear', align_corners=True)
x2_out = self.layer2_outconv(x2)
x2_out = self.layer2_outconv2(x2_out+x3_out_2x)
return [x4_out, x2_out]
1.2 Local Feature Transformer (LoFTR) Module
输入特征:LoFTER模块接收来自局部特征提取阶段的粗略级别特征图和
。
变换过程:首先将特征图展平为一维向量,并添加位置编码,然后,将这些添加了位置编码的特征通过LoFTER模块进行处理。
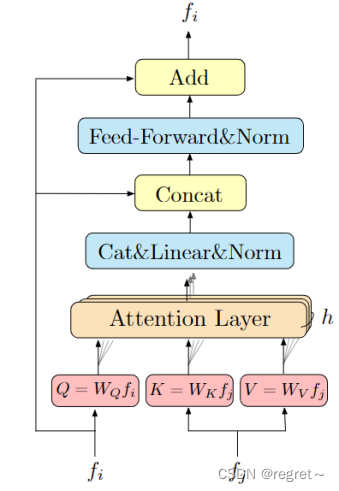
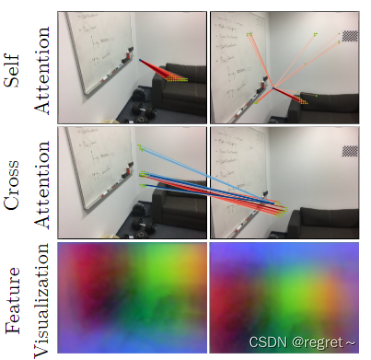
LoFTER模块:LoFTER模块包含了多个自注意力和交叉注意力层,通过查询(query)、键(key)和值(value)之间的交互来选择相关信息。
import copy
import torch
import torch.nn as nn
from .linear_attention import LinearAttention, FullAttention
class LoFTREncoderLayer(nn.Module):
def __init__(self,
d_model,
nhead,
attention='linear'):
super(LoFTREncoderLayer, self).__init__()
self.dim = d_model // nhead
self.nhead = nhead
# multi-head attention
self.q_proj = nn.Linear(d_model, d_model, bias=False)
self.k_proj = nn.Linear(d_model, d_model, bias=False)
self.v_proj = nn.Linear(d_model, d_model, bias=False)
self.attention = LinearAttention() if attention == 'linear' else FullAttention()
self.merge = nn.Linear(d_model, d_model, bias=False)
# feed-forward network
self.mlp = nn.Sequential(
nn.Linear(d_model*2, d_model*2, bias=False),
nn.ReLU(True),
nn.Linear(d_model*2, d_model, bias=False),
)
# norm and dropout
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x, source, x_mask=None, source_mask=None):
"""
Args:
x (torch.Tensor): [N, L, C]
source (torch.Tensor): [N, S, C]
x_mask (torch.Tensor): [N, L] (optional)
source_mask (torch.Tensor): [N, S] (optional)
"""
bs = x.size(0)
query, key, value = x, source, source
# multi-head attention
query = self.q_proj(query).view(bs, -1, self.nhead, self.dim) # [N, L, (H, D)]
key = self.k_proj(key).view(bs, -1, self.nhead, self.dim) # [N, S, (H, D)]
value = self.v_proj(value).view(bs, -1, self.nhead, self.dim)
message = self.attention(query, key, value, q_mask=x_mask, kv_mask=source_mask) # [N, L, (H, D)]
message = self.merge(message.view(bs, -1, self.nhead*self.dim)) # [N, L, C]
message = self.norm1(message)
# feed-forward network
message = self.mlp(torch.cat([x, message], dim=2))
message = self.norm2(message)
return x + message
class LocalFeatureTransformer(nn.Module):
"""A Local Feature Transformer (LoFTR) module."""
def __init__(self, config):
super(LocalFeatureTransformer, self).__init__()
self.config = config
self.d_model = config['d_model']
self.nhead = config['nhead']
self.layer_names = config['layer_names']
encoder_layer = LoFTREncoderLayer(config['d_model'], config['nhead'], config['attention'])
self.layers = nn.ModuleList([copy.deepcopy(encoder_layer) for _ in range(len(self.layer_names))])
self._reset_parameters()
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, feat0, feat1, mask0=None, mask1=None):
"""
Args:
feat0 (torch.Tensor): [N, L, C]
feat1 (torch.Tensor): [N, S, C]
mask0 (torch.Tensor): [N, L] (optional)
mask1 (torch.Tensor): [N, S] (optional)
"""
assert self.d_model == feat0.size(2), "the feature number of src and transformer must be equal"
for layer, name in zip(self.layers, self.layer_names):
if name == 'self':
feat0 = layer(feat0, feat0, mask0, mask0)
feat1 = layer(feat1, feat1, mask1, mask1)
elif name == 'cross':
feat0 = layer(feat0, feat1, mask0, mask1)
feat1 = layer(feat1, feat0, mask1, mask0)
else:
raise KeyError
return feat0, feat1
输出特征:经过LoFTER模块处理后,得到特征和
用于后续的匹配层以建立粗略级别的匹配。
线性变换器:为了降低计算复杂度,LoFTER模块采用了线性变换器,通过替换原始注意力层中的指数核,将计算复杂度从二次方(O(N^2))降低到线性(O(N))。
 | 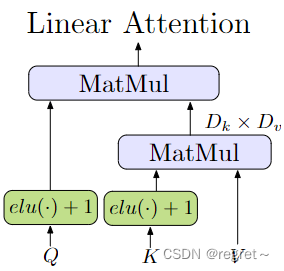 |
位置编码:位置编码为每个元素提供了独特的位置信息,这对于LoFTR在不具区分性区域生成匹配至关重要。位置编码以正弦波的形式添加到特征中,使得变换后的特征成为位置依赖的。
import math
import torch
from torch import nn
class PositionEncodingSine(nn.Module):
"""
This is a sinusoidal position encoding that generalized to 2-dimensional images
"""
def __init__(self, d_model, max_shape=(256, 256), temp_bug_fix=True):
"""
Args:
max_shape (tuple): for 1/8 featmap, the max length of 256 corresponds to 2048 pixels
temp_bug_fix (bool): As noted in this [issue](https://github.com/zju3dv/LoFTR/issues/41),
the original implementation of LoFTR includes a bug in the pos-enc impl, which has little impact
on the final performance. For now, we keep both impls for backward compatability.
We will remove the buggy impl after re-training all variants of our released models.
"""
super().__init__()
pe = torch.zeros((d_model, *max_shape))
y_position = torch.ones(max_shape).cumsum(0).float().unsqueeze(0)
x_position = torch.ones(max_shape).cumsum(1).float().unsqueeze(0)
if temp_bug_fix:
div_term = torch.exp(torch.arange(0, d_model//2, 2).float() * (-math.log(10000.0) / (d_model//2)))
else: # a buggy implementation (for backward compatability only)
div_term = torch.exp(torch.arange(0, d_model//2, 2).float() * (-math.log(10000.0) / d_model//2))
div_term = div_term[:, None, None] # [C//4, 1, 1]
pe[0::4, :, :] = torch.sin(x_position * div_term)
pe[1::4, :, :] = torch.cos(x_position * div_term)
pe[2::4, :, :] = torch.sin(y_position * div_term)
pe[3::4, :, :] = torch.cos(y_position * div_term)
self.register_buffer('pe', pe.unsqueeze(0), persistent=False) # [1, C, H, W]
def forward(self, x):
"""
Args:
x: [N, C, H, W]
"""
return x + self.pe[:, :, :x.size(2), :x.size(3)]
1.3 Establishing Coarse-level Matches(建立粗级匹配)
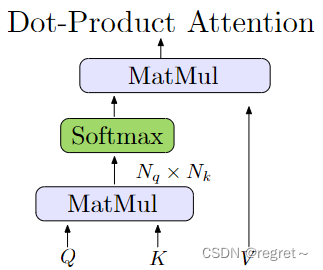
LoFTER使用两种类型的可微分配层来计算变换后特征之间的匹配分数。一种是使用最优传输(Optimal Transport, OT)层,另一种是使用双softmax算子(dual-softmax operator)。
分数矩阵计算:根据以下公式计算分数矩阵S:
- τ:超参数
- < . >:表示点积
最优传输匹配:当使用最优传输层时,可以将-S用作部分分配问题的代价矩阵,从而找到最优的匹配【见SuperGlue: Learning Feature Matching with Graph Neural Networks】。
双softmax匹配:当使用双softmax算子时,通过在S矩阵的两个维度上应用softmax函数获得软最近邻匹配的概率矩阵。
匹配选择:基于置信度矩阵,选择置信度高于阈值
的匹配,并进一步强制相互最近邻(MNN)准则进一步筛选可能的异常粗略匹配。粗略级别的匹配预测
表示为:
这一步得到的粗略匹配为后续的细化阶段提供了基础,通过选择高置信度的匹配对,可以提高最终匹配的准确性和鲁棒性。
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops.einops import rearrange
INF = 1e9
def mask_border(m, b: int, v):
""" Mask borders with value
Args:
m (torch.Tensor): [N, H0, W0, H1, W1]
b (int)
v (m.dtype)
"""
if b <= 0:
return
m[:, :b] = v
m[:, :, :b] = v
m[:, :, :, :b] = v
m[:, :, :, :, :b] = v
m[:, -b:] = v
m[:, :, -b:] = v
m[:, :, :, -b:] = v
m[:, :, :, :, -b:] = v
def mask_border_with_padding(m, bd, v, p_m0, p_m1):
if bd <= 0:
return
m[:, :bd] = v
m[:, :, :bd] = v
m[:, :, :, :bd] = v
m[:, :, :, :, :bd] = v
h0s, w0s = p_m0.sum(1).max(-1)[0].int(), p_m0.sum(-1).max(-1)[0].int()
h1s, w1s = p_m1.sum(1).max(-1)[0].int(), p_m1.sum(-1).max(-1)[0].int()
for b_idx, (h0, w0, h1, w1) in enumerate(zip(h0s, w0s, h1s, w1s)):
m[b_idx, h0 - bd:] = v
m[b_idx, :, w0 - bd:] = v
m[b_idx, :, :, h1 - bd:] = v
m[b_idx, :, :, :, w1 - bd:] = v
def compute_max_candidates(p_m0, p_m1):
"""Compute the max candidates of all pairs within a batch
Args:
p_m0, p_m1 (torch.Tensor): padded masks
"""
h0s, w0s = p_m0.sum(1).max(-1)[0], p_m0.sum(-1).max(-1)[0]
h1s, w1s = p_m1.sum(1).max(-1)[0], p_m1.sum(-1).max(-1)[0]
max_cand = torch.sum(
torch.min(torch.stack([h0s * w0s, h1s * w1s], -1), -1)[0])
return max_cand
class CoarseMatching(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
# general config
self.thr = config['thr']
self.border_rm = config['border_rm']
# -- # for trainig fine-level LoFTR
self.train_coarse_percent = config['train_coarse_percent']
self.train_pad_num_gt_min = config['train_pad_num_gt_min']
# we provide 2 options for differentiable matching
self.match_type = config['match_type']
if self.match_type == 'dual_softmax':
self.temperature = config['dsmax_temperature']
elif self.match_type == 'sinkhorn':
try:
from .superglue import log_optimal_transport
except ImportError:
raise ImportError("download superglue.py first!")
self.log_optimal_transport = log_optimal_transport
self.bin_score = nn.Parameter(
torch.tensor(config['skh_init_bin_score'], requires_grad=True))
self.skh_iters = config['skh_iters']
self.skh_prefilter = config['skh_prefilter']
else:
raise NotImplementedError()
def forward(self, feat_c0, feat_c1, data, mask_c0=None, mask_c1=None):
"""
Args:
feat0 (torch.Tensor): [N, L, C]
feat1 (torch.Tensor): [N, S, C]
data (dict)
mask_c0 (torch.Tensor): [N, L] (optional)
mask_c1 (torch.Tensor): [N, S] (optional)
Update:
data (dict): {
'b_ids' (torch.Tensor): [M'],
'i_ids' (torch.Tensor): [M'],
'j_ids' (torch.Tensor): [M'],
'gt_mask' (torch.Tensor): [M'],
'mkpts0_c' (torch.Tensor): [M, 2],
'mkpts1_c' (torch.Tensor): [M, 2],
'mconf' (torch.Tensor): [M]}
NOTE: M' != M during training.
"""
N, L, S, C = feat_c0.size(0), feat_c0.size(1), feat_c1.size(1), feat_c0.size(2)
# normalize
feat_c0, feat_c1 = map(lambda feat: feat / feat.shape[-1]**.5,
[feat_c0, feat_c1])
if self.match_type == 'dual_softmax':
sim_matrix = torch.einsum("nlc,nsc->nls", feat_c0,
feat_c1) / self.temperature
if mask_c0 is not None:
sim_matrix.masked_fill_(
~(mask_c0[..., None] * mask_c1[:, None]).bool(),
-INF)
conf_matrix = F.softmax(sim_matrix, 1) * F.softmax(sim_matrix, 2)
elif self.match_type == 'sinkhorn':
# sinkhorn, dustbin included
sim_matrix = torch.einsum("nlc,nsc->nls", feat_c0, feat_c1)
if mask_c0 is not None:
sim_matrix[:, :L, :S].masked_fill_(
~(mask_c0[..., None] * mask_c1[:, None]).bool(),
-INF)
# build uniform prior & use sinkhorn
log_assign_matrix = self.log_optimal_transport(
sim_matrix, self.bin_score, self.skh_iters)
assign_matrix = log_assign_matrix.exp()
conf_matrix = assign_matrix[:, :-1, :-1]
# filter prediction with dustbin score (only in evaluation mode)
if not self.training and self.skh_prefilter:
filter0 = (assign_matrix.max(dim=2)[1] == S)[:, :-1] # [N, L]
filter1 = (assign_matrix.max(dim=1)[1] == L)[:, :-1] # [N, S]
conf_matrix[filter0[..., None].repeat(1, 1, S)] = 0
conf_matrix[filter1[:, None].repeat(1, L, 1)] = 0
if self.config['sparse_spvs']:
data.update({'conf_matrix_with_bin': assign_matrix.clone()})
data.update({'conf_matrix': conf_matrix})
# predict coarse matches from conf_matrix
data.update(**self.get_coarse_match(conf_matrix, data))
@torch.no_grad()
def get_coarse_match(self, conf_matrix, data):
"""
Args:
conf_matrix (torch.Tensor): [N, L, S]
data (dict): with keys ['hw0_i', 'hw1_i', 'hw0_c', 'hw1_c']
Returns:
coarse_matches (dict): {
'b_ids' (torch.Tensor): [M'],
'i_ids' (torch.Tensor): [M'],
'j_ids' (torch.Tensor): [M'],
'gt_mask' (torch.Tensor): [M'],
'm_bids' (torch.Tensor): [M],
'mkpts0_c' (torch.Tensor): [M, 2],
'mkpts1_c' (torch.Tensor): [M, 2],
'mconf' (torch.Tensor): [M]}
"""
axes_lengths = {
'h0c': data['hw0_c'][0],
'w0c': data['hw0_c'][1],
'h1c': data['hw1_c'][0],
'w1c': data['hw1_c'][1]
}
_device = conf_matrix.device
# 1. confidence thresholding
mask = conf_matrix > self.thr
mask = rearrange(mask, 'b (h0c w0c) (h1c w1c) -> b h0c w0c h1c w1c',
**axes_lengths)
if 'mask0' not in data:
mask_border(mask, self.border_rm, False)
else:
mask_border_with_padding(mask, self.border_rm, False,
data['mask0'], data['mask1'])
mask = rearrange(mask, 'b h0c w0c h1c w1c -> b (h0c w0c) (h1c w1c)',
**axes_lengths)
# 2. mutual nearest
mask = mask \
* (conf_matrix == conf_matrix.max(dim=2, keepdim=True)[0]) \
* (conf_matrix == conf_matrix.max(dim=1, keepdim=True)[0])
# 3. find all valid coarse matches
# this only works when at most one `True` in each row
mask_v, all_j_ids = mask.max(dim=2)
b_ids, i_ids = torch.where(mask_v)
j_ids = all_j_ids[b_ids, i_ids]
mconf = conf_matrix[b_ids, i_ids, j_ids]
# 4. Random sampling of training samples for fine-level LoFTR
# (optional) pad samples with gt coarse-level matches
if self.training:
# NOTE:
# The sampling is performed across all pairs in a batch without manually balancing
# #samples for fine-level increases w.r.t. batch_size
if 'mask0' not in data:
num_candidates_max = mask.size(0) * max(
mask.size(1), mask.size(2))
else:
num_candidates_max = compute_max_candidates(
data['mask0'], data['mask1'])
num_matches_train = int(num_candidates_max *
self.train_coarse_percent)
num_matches_pred = len(b_ids)
assert self.train_pad_num_gt_min < num_matches_train, "min-num-gt-pad should be less than num-train-matches"
# pred_indices is to select from prediction
if num_matches_pred <= num_matches_train - self.train_pad_num_gt_min:
pred_indices = torch.arange(num_matches_pred, device=_device)
else:
pred_indices = torch.randint(
num_matches_pred,
(num_matches_train - self.train_pad_num_gt_min, ),
device=_device)
# gt_pad_indices is to select from gt padding. e.g. max(3787-4800, 200)
gt_pad_indices = torch.randint(
len(data['spv_b_ids']),
(max(num_matches_train - num_matches_pred,
self.train_pad_num_gt_min), ),
device=_device)
mconf_gt = torch.zeros(len(data['spv_b_ids']), device=_device) # set conf of gt paddings to all zero
b_ids, i_ids, j_ids, mconf = map(
lambda x, y: torch.cat([x[pred_indices], y[gt_pad_indices]],
dim=0),
*zip([b_ids, data['spv_b_ids']], [i_ids, data['spv_i_ids']],
[j_ids, data['spv_j_ids']], [mconf, mconf_gt]))
# These matches select patches that feed into fine-level network
coarse_matches = {'b_ids': b_ids, 'i_ids': i_ids, 'j_ids': j_ids}
# 4. Update with matches in original image resolution
scale = data['hw0_i'][0] / data['hw0_c'][0]
scale0 = scale * data['scale0'][b_ids] if 'scale0' in data else scale
scale1 = scale * data['scale1'][b_ids] if 'scale1' in data else scale
mkpts0_c = torch.stack(
[i_ids % data['hw0_c'][1], i_ids // data['hw0_c'][1]],
dim=1) * scale0
mkpts1_c = torch.stack(
[j_ids % data['hw1_c'][1], j_ids // data['hw1_c'][1]],
dim=1) * scale1
# These matches is the current prediction (for visualization)
coarse_matches.update({
'gt_mask': mconf == 0,
'm_bids': b_ids[mconf != 0], # mconf == 0 => gt matches
'mkpts0_c': mkpts0_c[mconf != 0],
'mkpts1_c': mkpts1_c[mconf != 0],
'mconf': mconf[mconf != 0]
})
return coarse_matches
1.4 Coarse-to-Fine Module(微调模块)
目的:在建立粗略级别的匹配之后,微调模块是将粗略级别的匹配进一步细化到亚像素精度。
基于相关性的方法:LoFTER采用了一种基于相关性的方法来细化匹配,对于每一对粗略匹配,首先在细级别特征图
和
上定位他们的位置
。
局部窗口裁剪:接着,从细级别特征图中裁剪出大小为 w×w 的局部窗口,并在这些局部窗口上应用较小的LoFTR模块,即执行自注意和交叉注意力。
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops.einops import rearrange, repeat
class FinePreprocess(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.cat_c_feat = config['fine_concat_coarse_feat']
self.W = self.config['fine_window_size']
d_model_c = self.config['coarse']['d_model']
d_model_f = self.config['fine']['d_model']
self.d_model_f = d_model_f
if self.cat_c_feat:
self.down_proj = nn.Linear(d_model_c, d_model_f, bias=True)
self.merge_feat = nn.Linear(2*d_model_f, d_model_f, bias=True)
self._reset_parameters()
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.kaiming_normal_(p, mode="fan_out", nonlinearity="relu")
def forward(self, feat_f0, feat_f1, feat_c0, feat_c1, data):
W = self.W
stride = data['hw0_f'][0] // data['hw0_c'][0]
data.update({'W': W})
if data['b_ids'].shape[0] == 0:
feat0 = torch.empty(0, self.W**2, self.d_model_f, device=feat_f0.device)
feat1 = torch.empty(0, self.W**2, self.d_model_f, device=feat_f0.device)
return feat0, feat1
# 1. unfold(crop) all local windows
feat_f0_unfold = F.unfold(feat_f0, kernel_size=(W, W), stride=stride, padding=W//2)
feat_f0_unfold = rearrange(feat_f0_unfold, 'n (c ww) l -> n l ww c', ww=W**2)
feat_f1_unfold = F.unfold(feat_f1, kernel_size=(W, W), stride=stride, padding=W//2)
feat_f1_unfold = rearrange(feat_f1_unfold, 'n (c ww) l -> n l ww c', ww=W**2)
# 2. select only the predicted matches
feat_f0_unfold = feat_f0_unfold[data['b_ids'], data['i_ids']] # [n, ww, cf]
feat_f1_unfold = feat_f1_unfold[data['b_ids'], data['j_ids']]
# option: use coarse-level loftr feature as context: concat and linear
if self.cat_c_feat:
feat_c_win = self.down_proj(torch.cat([feat_c0[data['b_ids'], data['i_ids']],
feat_c1[data['b_ids'], data['j_ids']]], 0)) # [2n, c]
feat_cf_win = self.merge_feat(torch.cat([
torch.cat([feat_f0_unfold, feat_f1_unfold], 0), # [2n, ww, cf]
repeat(feat_c_win, 'n c -> n ww c', ww=W**2), # [2n, ww, cf]
], -1))
feat_f0_unfold, feat_f1_unfold = torch.chunk(feat_cf_win, 2, dim=0)
return feat_f0_unfold, feat_f1_unfold
局部特征变换:通过次LoFTER模块操作来变换裁剪得到局部特征,得到以
和
为中心的变换局部特征图
和
。
相关性计算:计算中心向量与
中所有向量的相关性,生成一个热图,该热图表示
邻域中每个像素与 匹配的概率。
期望计算:通过对概率分布计算期望,得到最终具有亚像素精度的位置。
import math
import torch
import torch.nn as nn
from kornia.geometry.subpix import dsnt
from kornia.utils.grid import create_meshgrid
class FineMatching(nn.Module):
"""FineMatching with s2d paradigm"""
def __init__(self):
super().__init__()
def forward(self, feat_f0, feat_f1, data):
"""
Args:
feat0 (torch.Tensor): [M, WW, C]
feat1 (torch.Tensor): [M, WW, C]
data (dict)
Update:
data (dict):{
'expec_f' (torch.Tensor): [M, 3],
'mkpts0_f' (torch.Tensor): [M, 2],
'mkpts1_f' (torch.Tensor): [M, 2]}
"""
M, WW, C = feat_f0.shape
W = int(math.sqrt(WW))
scale = data['hw0_i'][0] / data['hw0_f'][0]
self.M, self.W, self.WW, self.C, self.scale = M, W, WW, C, scale
# corner case: if no coarse matches found
if M == 0:
assert self.training == False, "M is always >0, when training, see coarse_matching.py"
# logger.warning('No matches found in coarse-level.')
data.update({
'expec_f': torch.empty(0, 3, device=feat_f0.device),
'mkpts0_f': data['mkpts0_c'],
'mkpts1_f': data['mkpts1_c'],
})
return
feat_f0_picked = feat_f0_picked = feat_f0[:, WW//2, :]
sim_matrix = torch.einsum('mc,mrc->mr', feat_f0_picked, feat_f1)
softmax_temp = 1. / C**.5
heatmap = torch.softmax(softmax_temp * sim_matrix, dim=1).view(-1, W, W)
# compute coordinates from heatmap
coords_normalized = dsnt.spatial_expectation2d(heatmap[None], True)[0] # [M, 2]
grid_normalized = create_meshgrid(W, W, True, heatmap.device).reshape(1, -1, 2) # [1, WW, 2]
# compute std over <x, y>
var = torch.sum(grid_normalized**2 * heatmap.view(-1, WW, 1), dim=1) - coords_normalized**2 # [M, 2]
std = torch.sum(torch.sqrt(torch.clamp(var, min=1e-10)), -1) # [M] clamp needed for numerical stability
# for fine-level supervision
data.update({'expec_f': torch.cat([coords_normalized, std.unsqueeze(1)], -1)})
# compute absolute kpt coords
self.get_fine_match(coords_normalized, data)
@torch.no_grad()
def get_fine_match(self, coords_normed, data):
W, WW, C, scale = self.W, self.WW, self.C, self.scale
# mkpts0_f and mkpts1_f
mkpts0_f = data['mkpts0_c']
scale1 = scale * data['scale1'][data['b_ids']] if 'scale0' in data else scale
mkpts1_f = data['mkpts1_c'] + (coords_normed * (W // 2) * scale1)[:len(data['mconf'])]
data.update({
"mkpts0_f": mkpts0_f,
"mkpts1_f": mkpts1_f
})
2 模型训练
2.1 训练设置
在ScanNet数据集上训练LoFTER的室内模型和MegaDepth数据集上训练室外模型。使用Adam优化器,初始学习率为,批次大小为。在64个GTX 1080Ti gpu上训练24小时收敛。局部特征CNN使用ResNet-18的修改版本作为backbone。整个模型使用随机初始化的权重进行端到端的训练。
设置为4,
设置为1,
设置为0.2。窗口大小w为5.
2.2 损失函数
最终的损失由粗级和细级的损失组成。
粗级损失:
LoFTER在计算粗级损失时,是基于负对数似然损失的,根据置信度矩阵来计算,其中
通过最优传输层或双softmax算子计算得到。在训练过程中,使用相机姿态和深度图来计算置信度矩阵的真实标签。
细级损失:
LoFTER在计算细级损失时,使用的是平方损失(L2损失),目的是为了优化匹配点的位置,使其达到亚像素级的精度。对于每个查询点,LoFTER通过计算相应热图的总方差
来测量其不确定性。如果在计算损失时,变换后的位置
落在
的局部窗口之外,则忽略该匹配对
。在训练过程中,该梯度不会通过不确定性进行反向传播。
四、实验结果
1 单应性估计
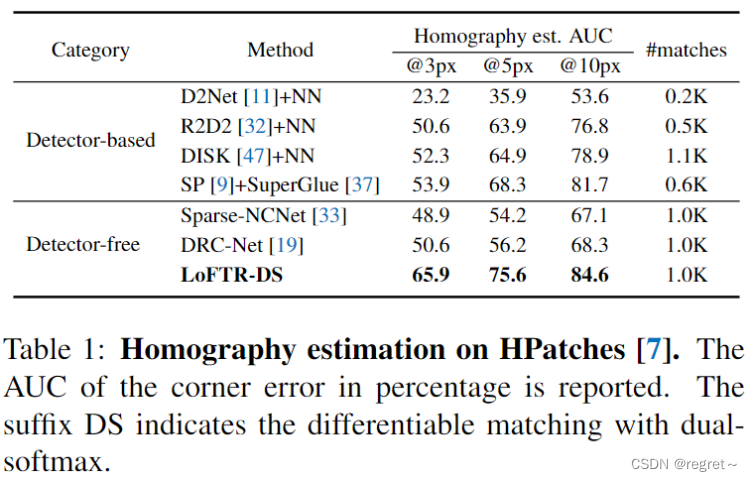
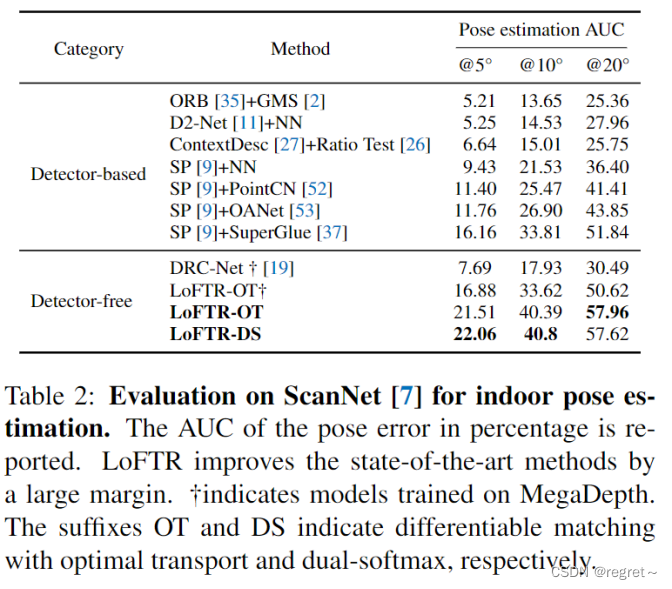
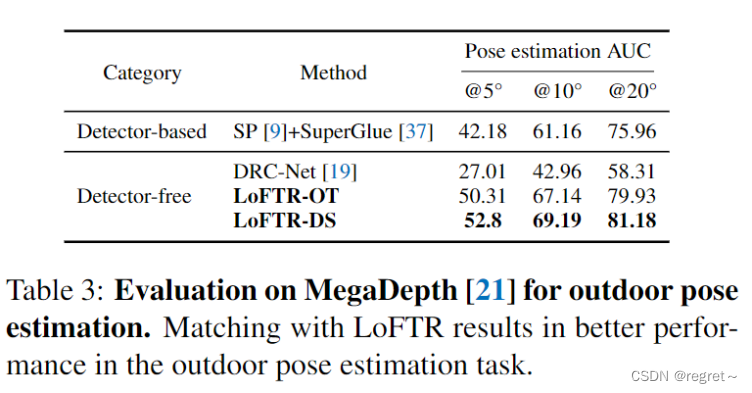
2 相对位姿估计

3 视觉定位
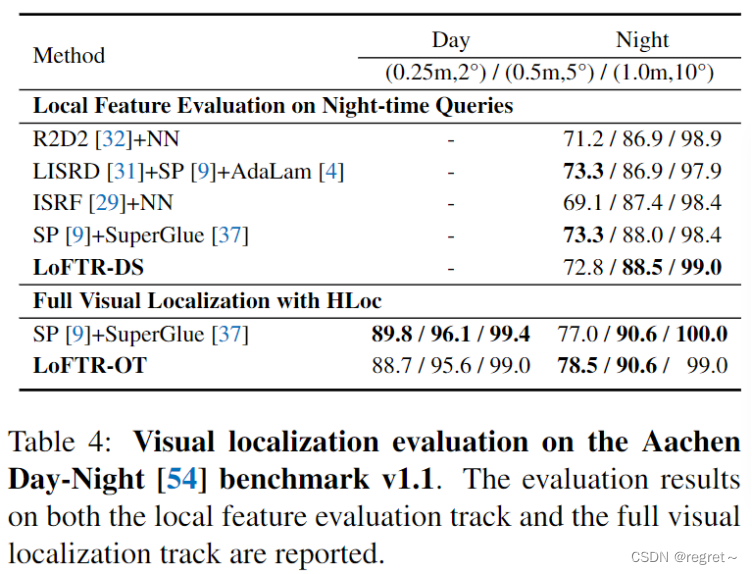
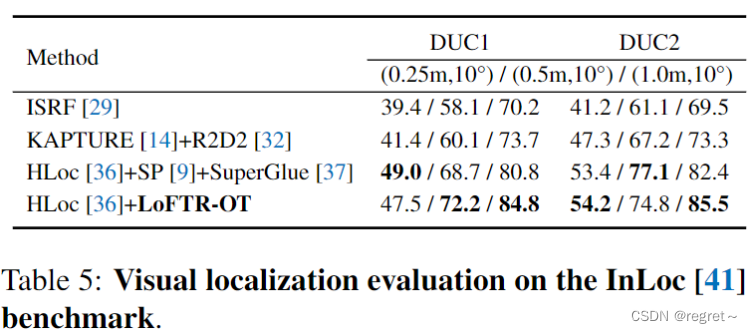
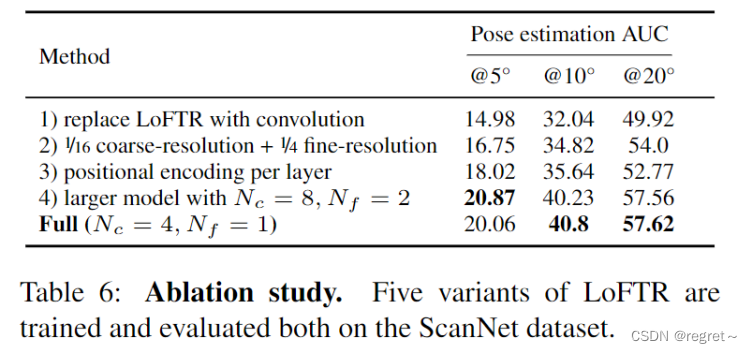
4 消融实验


















 3383
3383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









