







文章目录
前言
最近在研究LoFTR,一种基于Transformer的特征点提取和匹配方法,运行了Demo在给定的测试集上效果很好,但是我发现这些数据都存在一个明显的特点,即匹配的对象都是针对同一个物体进行的特征提取和匹配,而我想将这种方法应用于无人机摄影测量,不清楚LoFTR在连续图像之间的匹配情况如何,不过感觉应该可行,需要修改一下预测的pipeline。此外LoFTR的训练数据仅在两个大型的公开数据集上进行了训练,即indoor和outdoor,直接将预训练模型应用去其他场景,模型的性能是否还能保持,这有待验证,因此需要重新对LoFTR进行训练,当然不可能完全从0开始训练,使用预训练权重作为参数初始化,应该会极大的降低训练的难度。但在训练之前首先要搞懂数据结构,但是找遍了网络没有一篇是关于LoFTR训练的教程,大都只是停留在论文解读。因此有了这篇博客。
项目地址:LoFTR: Detector-Free Local Feature Matching with Transformers
如果想要用自己的数据训练LoFTR,请见我的这篇blog:用自己的数据训练LoFTR,这可能是全网你唯一能找到的教程了

提示:以下是本篇文章正文内容,下面案例可供参考
一、环境安装
LoFTR的环境配置还是比较友好的,根据README中的方法直接安装即可,麻烦的是数据集
# For full pytorch-lightning trainer features (recommended)
conda env create -f environment.yaml
conda activate loftr
二、数据下载
1.下载MegaDepth数据
这个教程仅以MegaDepth数据集为例,ScanNet数据还需要申请比较麻烦。

尽管官方在README里提到需要下载两个数据,但是D2-Net preprocessed images对应的网盘数据已经失效了,因此不能再用了。只需要下载绿色箭头的数据即可,一共200G,留好存储空间
下载完成后,解压完会得到这样一个路径phoenix\S6\zl548\MegaDepth_v1,千万不要自己修改数据的路径,因为在.npz文件中image_path就包含有这个路径名,改了之后代码会找不到图片。
2.下载indices数据

下载地址:Dataset indices,下载时需要使用魔法
解压后会得到下面三个目录:

将这三个目录赋值到LoFTR项目中的data/megadepth/index目录下:

3.移动MegaDepth数据
按照图中的文件结构,将MegaDepth数据中的0015和0022数据文件夹剪切到test\phoenix\S6\zl548\MegaDepth_v1文件夹中(因为测试集就用的这两个数据),phoenix\S6\zl548\MegaDepth_v1这几个文件夹需要自己创建:

然后将MegaDepth中剩余的全部数据移动到train\phoenix\S6\zl548\MegaDepth_v1文件夹中,最终的数据结构如下:

scene_info_0.1_0.7_no_sfm和scene_info_val_1500_no_sfm文件夹一开始是没有的,需要在下一步数据准备中才会产生
三、数据准备
这一步是比较麻烦的,也是看了issue:How to train in MegaDepth without D2-Net data才知道该怎么弄,不过他的回答的最后一点有个小错误,下面我贴上我整理后的代码:
# -*- coding: utf-8 -*-
# Data: 2024-09-02 10:45
# Project: LoFTR
# File Name: process_megadepth.py
# Author: KangPeilun
# Email: 374774222@qq.com
# Description:
import numpy as np
from numpy import load
import os
from PIL import Image
def modify_npz_index(directory1, directory2):
"""1.第一步修改索引文件
您需要更改索引中的 NPZ 文件。在训练之前,运行这个脚本
:param directory1: 'PATH_TO_LOFTR/data/megadepth/index/scene_info_0.1_0.7' example
:param directory2: 'PATH_TO_LOFTR/data/megadepth/index/scene_info_val_1500'
:return:
"""
# change scene_info_0
for filename in os.listdir(directory1):
f_npz = os.path.join(directory1, filename)
data = load(f_npz, allow_pickle=True)
for count, image_path in enumerate(data['image_paths']):
if image_path is not None:
if 'Undistorted_SfM' in image_path:
data['image_paths'][count] = data['depth_paths'][count].replace('depths', 'imgs').replace('h5', 'jpg')
data['pair_infos'] = np.asarray(data['pair_infos'], dtype=object)
no_sfm_data_dir = r'PATH_TO_LOFTR/data/megadepth/index/scene_info_0.1_0.7_no_sfm/'
os.makedirs(no_sfm_data_dir, exist_ok=True)
new_file = no_sfm_data_dir + filename
np.savez(new_file, **data)
print("Saved to ", new_file)
# change scene_info_val_1500
for filename in os.listdir(directory2):
f_npz = os.path.join(directory2, filename)
data = load(f_npz, allow_pickle=True)
for count, image_path in enumerate(data['image_paths']):
if image_path is not None:
if 'Undistorted_SfM' in image_path:
data['image_paths'][count] = data['depth_paths'][count].replace('depths', 'imgs').replace('h5', 'jpg')
data['pair_infos'] = np.asarray(data['pair_infos'], dtype=object)
no_sfm_data_dir = r'PATH_TO_LOFTR/data/megadepth/index/scene_info_val_1500_no_sfm/'
os.makedirs(no_sfm_data_dir, exist_ok=True)
new_file = no_sfm_data_dir + filename
np.savez(new_file, **data)
print("Saved to ", new_file)
def modify_suffix_jpg(root_directory):
"""2.将数据集图片后缀中的非jpg后缀,改为jpg后缀
然后,还要运行以下脚本,以确保所有图像都有结尾 'jpg' (数据集中有一些隐藏的 JPG 和 png)
:param root_directory: '/PATH_TO_DATASET/phoenix/S6/zl548/MegaDepth_v1' example
:return:
"""
for folder in os.listdir(root_directory):
four_digit_directory = os.path.join(root_directory,folder)
for dense_folder in os.listdir(four_digit_directory):
image_directory = os.path.join(four_digit_directory,dense_folder,'imgs')
for image in os.listdir(image_directory):
if 'JPG' in image:
new_name = image.replace('JPG', 'jpg')
old_path = os.path.join(image_directory, image)
new_path = os.path.join(image_directory, new_name)
os.rename(old_path, new_path)
if 'png' in image:
new_name = image.replace('png', 'jpg')
old_path = os.path.join(image_directory, image)
new_path = os.path.join(image_directory, new_name)
png_img = Image.open(old_path)
png_img.save(new_path)
"""
3.修改megadepth数据的配置文件
更改了 LoFTR/configs/data/megadepth_trainval_640.py 中的以下行:
cfg.DATASET.TRAIN_NPZ_ROOT = f"{TRAIN_BASE_PATH}/scene_info_0.1_0.7_no_sfm"
cfg.DATASET.VAL_NPZ_ROOT = cfg.DATASET.TEST_NPZ_ROOT = f"{TEST_BASE_PATH}/scene_info_val_1500_no_sfm"
4.修改megadepth.py中的代码
需要在 LoFTR/src/datasets/megadepth.py 中将 第47行代码改为以下代码,将类型转换为dict:
self.scene_info = dict(np.load(npz_path, allow_pickle=True))
"""
if __name__ == '__main__':
directory1 = r"E:\Pycharm\3D_Reconstruct\LoFTR\data\megadepth\index\scene_info_0.1_0.7"
directory2 = r"E:\Pycharm\3D_Reconstruct\LoFTR\data\megadepth\index\scene_info_val_1500"
root_directory = r"E:\Pycharm\3D_Reconstruct\LoFTR\datasets\MegaDepth_v1"
# modify_npz_index(directory1, directory2)
modify_suffix_jpg(root_directory)
其中你要修改PATH_TO_LOFTR为你的项目主目录
上面的代码,首先运行modify_npz_index函数,然后运行modify_suffix_jpg函数,3、4步跟着注释操作


四、其他项目代码修改
因为我实在Windows上进行测试,且只有一个GPU 12G,因此无法使用源码的DDP分布式训练,因此需要对代码进行部分修改,弃用分布式训练:
1.训练命令修改
可以参考我的命令参数:
E:\Pycharm\3D_Reconstruct\LoFTR\configs\data\megadepth_trainval_640.py
E:\Pycharm\3D_Reconstruct\LoFTR\configs\loftr\outdoor\loftr_ds_dense.py
--exp_name
megadepth
--gpus
1
--num_nodes
1
--batch_size
1
--num_workers
4
--pin_memory
True
--check_val_every_n_epoch
1
--log_every_n_steps
1
--flush_logs_every_n_steps
1
--limit_val_batches
1.
--num_sanity_val_steps
10
--benchmark
True
--max_epochs
30
不使用--accelerator="ddp"
2.修改 src/lightning/data.py 文件
修改该文件的第113行之后的内容,如下图所示:
这是为了不使用分布式加载数据,windows上用不了ddp

修改该文件的大概在第307行的内容,如下图所示:

3.修改train.py文件
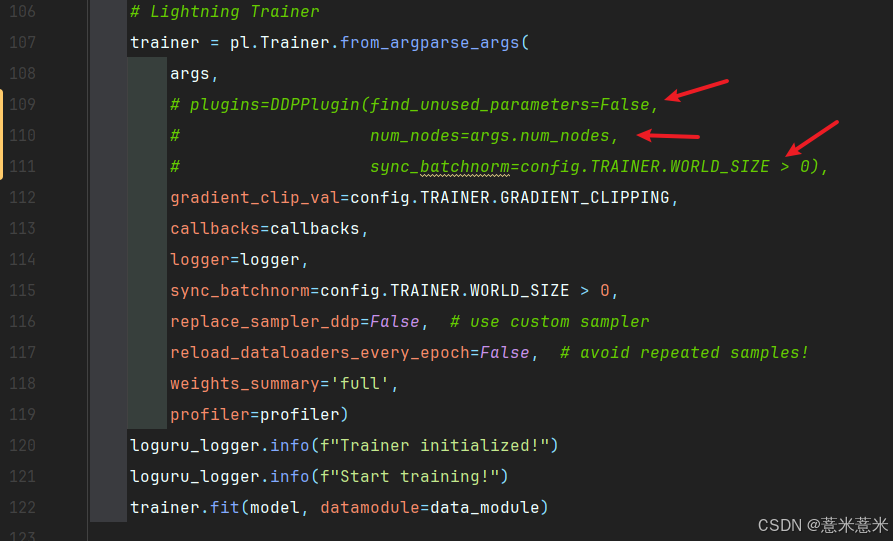
注释掉该文件的第109-111行的内容,如下图所示:
这是为了不使用分布式加载数据,windows上用不了ddp
之后就可以愉快的开启训练了,下面贴一张成功训练的截图,以及我的pycharm训练设置:



Tip: 训练显存不够
因为只是为了debug模型,因此不需要把所有的数据都加载进来,加载数据只是为了使得整个项目能够正常运行,然后方便我们学习。可以修改src/lightning/data.py文件中大概在第183行位置的代码,我们只加载前一个数据集,这样显存的压力就小了很多。

总结
了解一个新的模型一定要完整的了解数据结构,模型结构这两个重要的部分,在明白了数据结构之后才能够制作自己的数据,在了解了模型结构并结合论文才能够深刻的明白论文中的创新点,才能将之转换为自己的东西。

















 5017
5017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









