






【引用格式】:Potje G, Cadar F, Araujo A, et al. XFeat: Accelerated Features for Lightweight Image Matching[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2024.
【网址】:https://arxiv.org/pdf/2404.19174
【参考】:深度学习论文: XFeat: Accelerated Features for Lightweight Image Matching-CSDN博客
目录
1.1 Featherweight Network Backbone
一、瓶颈问题
高计算需求和实现复杂性:现有的图像匹配方法往往需要大量的计算资源和复杂的实现,这在资源受限的设备上是不可行的。
二、本文贡献
- 提出了一种新的轻量级CNN框架,适用于资源受限的平台和需要高吞吐量或计算效率的下游任务。
- 设计了一个最小化、可学习的关键点检测分支,适用于小型提取器骨干网络,并在视觉定位、相机姿态估计和单应性配准中展示了其有效性。
- 提出了一种新的匹配精细化模块,用于从粗略的半密集匹配中获取像素级偏移,而不需要高分辨率特征图。
三、解决方案
1 网络架构
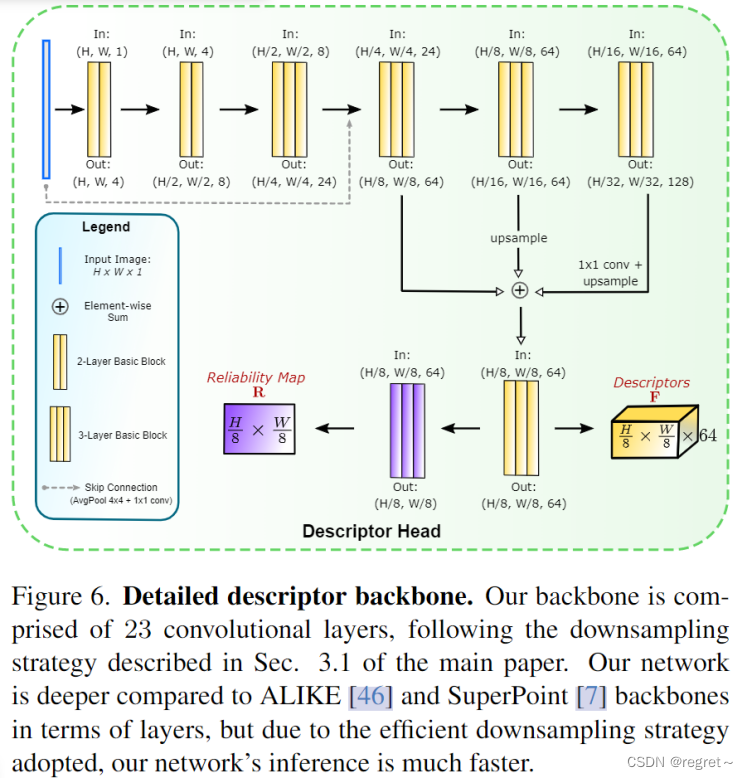
XFeat是一种用于关键点提取的方法,它能够快速生成关键点热图K、64维密集描述符映射F和可靠性热图R。与传统方法不同的是,XFeat将关键点检测分为独立的分支,并使用1×1的卷积在8×8的张量块上快速处理图像。该方法首先通过早期下采样和浅层卷积对图像进行处理,然后在后续编码器中进行更深层次的卷积操作,以实现无与伦比的速度和性能。

1.1 Featherweight Network Backbone
为了减少CNN处理成本,一种常见的方法是从浅层卷积开始,然后逐步将空间维度(Hi, Wi)减半,同时将第i个卷积块中的通道数Ci加倍。然而,即使在简单的小型网络主干中,将高分辨率图像输入网络主干也会增加对不希望的水平的计算要求。【这是因为在局部特征提取中,网络需要处理更大的图像分辨率,因此这种增加通道数的方法会导致计算瓶颈。】另外,天真的修剪通道C会损害其处理不同照明和视点等挑战的能力。为此,文中制定了一种最小化早期层深度和重新配置通道分布的策略:在初始剪辑层尽可能减少通道数 ,并随着空间分辨率的降低,不是加倍而是增加三倍的通道数,知道达到足够的通道数。这种策略有效地重新分配网络的卷积深度,不仅降低了早期阶段的计算负载,而且还通过更有效的卷积深度管理来优化网络的整体容量。
网络结构由称为基础层的块组成,每个块包含2D卷积、ReLU激活函数、批量归一化和步长为2的卷积层。Backbone共有6个这样的块,按顺序减半分辨率并增加深度:{4,8,24,64,64,128},并包含一个融合块来整合多分辨率特征。通过从C=4通道开始,在最终编码器块中增加到C=128通道,实现了在H/32×W/32空间分辨率下的良好的精度和速度的平衡。
with torch.no_grad():
x = x.mean(dim=1, keepdim = True)
x = self.norm(x)
#main backbone
x1 = self.block1(x)
x2 = self.block2(x1 + self.skip1(x))
x3 = self.block3(x2)
x4 = self.block4(x3)
x5 = self.block5(x4)1.2 Local Feature Extraction
使用backbone提取到的局部特征并执行密集匹配。
Descriptor head:
描述符头通过合并编码器中的多尺度特征来获得密集特征图。使用特征金字塔策略,廉价地应用连续的卷积来降低分辨率,增加感受野,直到达到原始分辨率的1/32。然后在三个不同尺度级别上合并中间表示:{1/8,1/16,1/32},通过双线性上采样并将所有中间表示投影到H/8×W/8×64,然后进行逐像素求和。最后,使用由三个基本层组成的卷积融合块将表示组合成最终的特征表示F。另外,应用了一个额外的卷积块来回归可靠性图
,
可以使局部特征
自信地匹配。
self.block_fusion = nn.Sequential(
BasicLayer(64, 64, stride=1),
BasicLayer(64, 64, stride=1),
nn.Conv2d (64, 64, 1, padding=0)
)
self.heatmap_head = nn.Sequential(
BasicLayer(64, 64, 1, padding=0),
BasicLayer(64, 64, 1, padding=0),
nn.Conv2d (64, 1, 1),
nn.Sigmoid()
)
x4 = F.interpolate(x4, (x3.shape[-2], x3.shape[-1]), mode='bilinear')
x5 = F.interpolate(x5, (x3.shape[-2], x3.shape[-1]), mode='bilinear')
feats = self.block_fusion( x3 + x4 + x5 )
#heads
heatmap = self.heatmap_head(feats) # Reliability mapKeypoint head:
SuperPoint提供了提取像素级关键点的最快方法:使用最终编码器中的特征,以原始图像分辨率的1/8,并通过从特征嵌入中对关键点坐标在展平的8×8网络中进行分类,来提取像素级关键点。XFeat使用了一种类似的方法,引入了一种专用的并行分支进行关键点检测,专注于低级图像结构。为了在不牺牲速度的情况下保持空间分辨率,文中将输入图像表示为由每个网络单元上的8×8像素组成的2D网络,并将每个单元重塑为64维特征。这种表示在保留了单个单元内的空间粒度的同时,利用快速1×1卷积回归关键点坐标。经过四个卷积层,得到一个关键点嵌入(+1,表示增加一个dustbin,表示找不到关键点嵌入K),编码了单元内关键点分布的logits,并将关键点分类为64个可能位置之一。在推理中,dustbin被丢弃,热图被重新解释为8×8单元。
def _unfold2d(self, x, ws = 2):
"""
Unfolds tensor in 2D with desired ws (window size) and concat the channels
"""
B, C, H, W = x.shape
x = x.unfold(2, ws, ws).unfold(3, ws, ws)
x = x.reshape(B, C, H//ws, W//ws, ws**2)
return x.permute(0, 1, 4, 2, 3).reshape(B, -1, H//ws, W//ws)
self.keypoint_head = nn.Sequential(
BasicLayer(64, 64, 1, padding=0),
BasicLayer(64, 64, 1, padding=0),
BasicLayer(64, 64, 1, padding=0),
nn.Conv2d (64, 65, 1),
)
keypoints = self.keypoint_head(self._unfold2d(x, ws=8)) #Keypoint map logitsDense matching
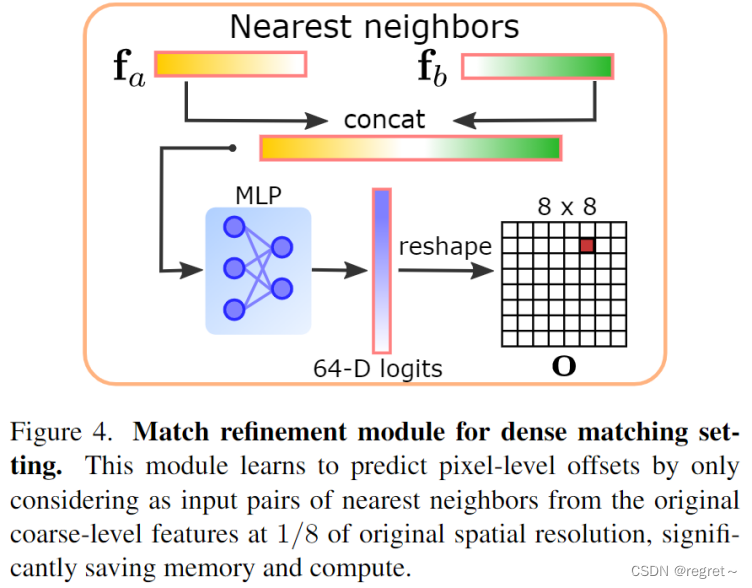
该模块学习通过仅考虑原始粗糙级别特征中原始空间分辨率的1/8处的最近邻对来预测像素级偏移,从而显着节省内存和计算。首先,文中通过根据top-k获取可靠性分数前tok-k个图像区域,并将它们缓存以进行未来的匹配来控制内存和计算占用。其次,提出了一种简单而轻量级的多层感知器(MLP),在没有高分辨率特征映射的情况下执行从粗到细的匹配,使我们能够在资源受限的设置中执行半密集匹配。
对于两幅图中提取的密集局部特征图F1,F2,设fa∈F1和fb∈F2是由图像对的传统最近邻匹配得到的两个匹配特征,然后预测偏移量o = MLP(concat(fa, fb)),对偏移量(x,y)进行分类,获得原始分辨率下实现正确的像素级匹配。
self.fine_matcher = nn.Sequential(
nn.Linear(128, 512),
nn.BatchNorm1d(512, affine=False),
nn.ReLU(inplace = True),
nn.Linear(512, 512),
nn.BatchNorm1d(512, affine=False),
nn.ReLU(inplace = True),
nn.Linear(512, 512),
nn.BatchNorm1d(512, affine=False),
nn.ReLU(inplace = True),
nn.Linear(512, 512),
nn.BatchNorm1d(512, affine=False),
nn.ReLU(inplace = True),
nn.Linear(512, 64),
)
@torch.no_grad()
def match(self, feats1, feats2, min_cossim = 0.82):
cossim = feats1 @ feats2.t()
cossim_t = feats2 @ feats1.t()
_, match12 = cossim.max(dim=1)
_, match21 = cossim_t.max(dim=1)
idx0 = torch.arange(len(match12), device=match12.device)
mutual = match21[match12] == idx0
if min_cossim > 0:
cossim, _ = cossim.max(dim=1)
good = cossim > min_cossim
idx0 = idx0[mutual & good]
idx1 = match12[mutual & good]
else:
idx0 = idx0[mutual]
idx1 = match12[mutual]
return idx0, idx1"""
"XFeat: Accelerated Features for Lightweight Image Matching, CVPR 2024."
https://www.verlab.dcc.ufmg.br/descriptors/xfeat_cvpr24/
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
class BasicLayer(nn.Module):
"""
Basic Convolutional Layer: Conv2d -> BatchNorm -> ReLU
"""
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, dilation=1, bias=False):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d( in_channels, out_channels, kernel_size, padding = padding, stride=stride, dilation=dilation, bias = bias),
nn.BatchNorm2d(out_channels, affine=False),
nn.ReLU(inplace = True),
)
def forward(self, x):
return self.layer(x)
class XFeatModel(nn.Module):
"""
Implementation of architecture described in
"XFeat: Accelerated Features for Lightweight Image Matching, CVPR 2024."
"""
def __init__(self):
super().__init__()
self.norm = nn.InstanceNorm2d(1)
########### ⬇️ CNN Backbone & Heads ⬇️ ###########
self.skip1 = nn.Sequential( nn.AvgPool2d(4, stride = 4),
nn.Conv2d (1, 24, 1, stride = 1, padding=0) )
self.block1 = nn.Sequential(
BasicLayer( 1, 4, stride=1),
BasicLayer( 4, 8, stride=2),
BasicLayer( 8, 8, stride=1),
BasicLayer( 8, 24, stride=2),
)
self.block2 = nn.Sequential(
BasicLayer(24,
24, stride=1),
BasicLayer(24, 24, stride=1),
)
self.block3 = nn.Sequential(
BasicLayer(24, 64, stride=2),
BasicLayer(64, 64, stride=1),
BasicLayer(64, 64, 1, padding=0),
)
self.block4 = nn.Sequential(
BasicLayer(64, 64, stride=2),
BasicLayer(64, 64, stride=1),
BasicLayer(64, 64, stride=1),
)
self.block5 = nn.Sequential(
BasicLayer( 64, 128, stride=2),
BasicLayer(128, 128, stride=1),
BasicLayer(128, 128, stride=1),
BasicLayer(128, 64, 1, padding=0),
)
self.block_fusion = nn.Sequential(
BasicLayer(64, 64, stride=1),
BasicLayer(64, 64, stride=1),
nn.Conv2d (64, 64, 1, padding=0)
)
self.heatmap_head = nn.Sequential(
BasicLayer(64, 64, 1, padding=0),
BasicLayer(64, 64, 1, padding=0),
nn.Conv2d (64, 1, 1),
nn.Sigmoid()
)
self.keypoint_head = nn.Sequential(
BasicLayer(64, 64, 1, padding=0),
BasicLayer(64, 64, 1, padding=0),
BasicLayer(64, 64, 1, padding=0),
nn.Conv2d (64, 65, 1),
)
########### ⬇️ Fine Matcher MLP ⬇️ ###########
self.fine_matcher = nn.Sequential(
nn.Linear(128, 512),
nn.BatchNorm1d(512, affine=False),
nn.ReLU(inplace = True),
nn.Linear(512, 512),
nn.BatchNorm1d(512, affine=False),
nn.ReLU(inplace = True),
nn.Linear(512, 512),
nn.BatchNorm1d(512, affine=False),
nn.ReLU(inplace = True),
nn.Linear(512, 512),
nn.BatchNorm1d(512, affine=False),
nn.ReLU(inplace = True),
nn.Linear(512, 64),
)
def _unfold2d(self, x, ws = 2):
"""
Unfolds tensor in 2D with desired ws (window size) and concat the channels
"""
B, C, H, W = x.shape
x = x.unfold(2, ws, ws).unfold(3, ws, ws)
x = x.reshape(B, C, H//ws, W//ws, ws**2)
return x.permute(0, 1, 4, 2, 3).reshape(B, -1, H//ws, W//ws)
def forward(self, x):
"""
input:
x -> torch.Tensor(B, C, H, W) grayscale or rgb images
return:
feats -> torch.Tensor(B, 64, H/8, W/8) dense local features
keypoints -> torch.Tensor(B, 65, H/8, W/8) keypoint logit map
heatmap -> torch.Tensor(B, 1, H/8, W/8) reliability map
"""
#dont backprop through normalization
with torch.no_grad():
x = x.mean(dim=1, keepdim = True)
x = self.norm(x)
#main backbone
x1 = self.block1(x)
x2 = self.block2(x1 + self.skip1(x))
x3 = self.block3(x2)
x4 = self.block4(x3)
x5 = self.block5(x4)
#pyramid fusion
x4 = F.interpolate(x4, (x3.shape[-2], x3.shape[-1]), mode='bilinear')
x5 = F.interpolate(x5, (x3.shape[-2], x3.shape[-1]), mode='bilinear')
feats = self.block_fusion( x3 + x4 + x5 )
#heads
heatmap = self.heatmap_head(feats) # Reliability map
keypoints = self.keypoint_head(self._unfold2d(x, ws=8)) #Keypoint map logits
return feats, keypoints, heatmap
2 模型训练
2.1 训练设置
XFeat在Pytorch上进行实现,使用6:4的比率在Megadepth和综合扭曲的COCO图的混合上进行训练,图像大小调整为(W = 800, H = 600)。使用Adam优化器训练,单次推理使用10个图像对批次。在NVIDIA RTX 4090 GPU上训练36小时。
2.2 损失函数
Learning local descriptors
为了监督局部特征嵌入F,文中使用了负对数似然(NLL)损失。从密集特征映射F中采样描述子集合F1和F2,通过计算描述子对之间的点积,构建一个相似性矩阵,其中
表示描述子F1(i, :)和F2(j,:)之间的相似性。为了考虑匹配的对称性,使用了双重softmax操作来增强对应描述子之间的相似性。
通过最小化这个损失,网络学习生成的描述子能够使匹配的描述子在特征空间中更接近,而不匹配的描述子更分散,从而提高图像匹配的准确性。
Learning reliability
可靠性图是一种映射,为图像中的每个局部特征分配一个置信度分数,表明该特征能够被成功匹配的可能性。文中使用了L1损失来训练可靠性图,通过双重softmax策略得到的匹配概率作为置信度的代理,其中
和
分別是根据F1和F2计算得到的匹配置信度,具体公式如下。通过最小化这个损失函数,网络学习生成的可靠性图能够准确地反映特征匹配的可靠性。
和
是网络预测的可靠性图,为图像中每个局部特征分配一个置信度分数。
- σ是sigmoid激活函数
Learning pixel offsets
匹配精细化模块用从原始输入图像分辨率的真实对应标签获得像素级偏移量进行监督。在初步的最近邻匹配之后,通过预测一个偏移量来精细化匹配过程,从而获得更精确的匹配结果。文中在MLP操作之后得到的o上使用负对数似然(NLL)损失,公式如下:
是网络预测的偏移量,表示为一个8×8的logits(未经过softmax处理)矩阵,其中每个元素
是偏移量为
,
(
,
是偏移量的分辨率)的概率。
和
是图像匹配点对的真实像素偏移量。
Learning keypoints
文中选择了使用来自更大教师网络的知识蒸馏来促进学习,选择了从它的微小主干中获得ALIKE关键点来监督网络模型。在编码器提取的原始中,将每个单元格
内的教师网络(tx,ty)的关键点坐标映射到线性索引
。当没有检测到关键点时,设置
。最后,利用NLL损失计算关键点损失
。
最终的损失函数为以上损失函数的线性组合:
四、实验结果
1 相对位姿评估
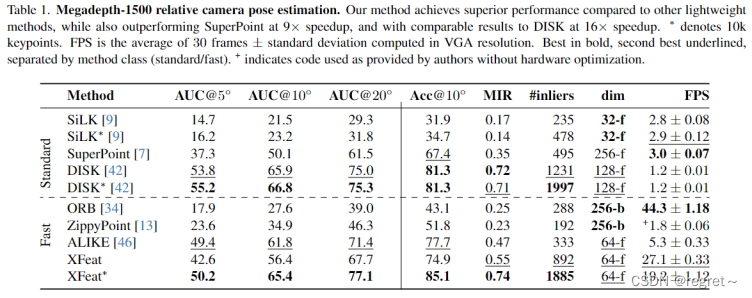
- Standard:这一类方法通常具有较高的准确性,但是计算成本也较高。
- Fast:这一类方法注重计算效率,虽然可能牺牲一些准确性,但是运行速度更快。
- AUC@5,10,20:分别表示在不同角度阈值下的AUC指标。AUC是基于接收者操作特征(Receiver Operating Characteristic, ROC)曲线计算得出的。ROC曲线是一个图形,它将真正例率(True Positive Rate, TPR)绘制在Y轴上,假正例率(False Positive Rate, FPR)绘制在X轴上。
- MIR:Mean Inlier Ratio(平均内点比率),即在RANSAC算法之后,与估计模型一致的匹配点的比例。
- #inliers:成功匹配的内点数量。


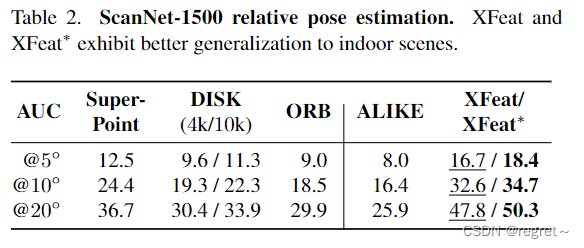
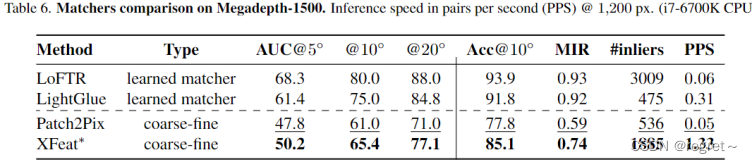
- 学习到的匹配器(learned matcher)、粗到细的策略(coarse-fine)
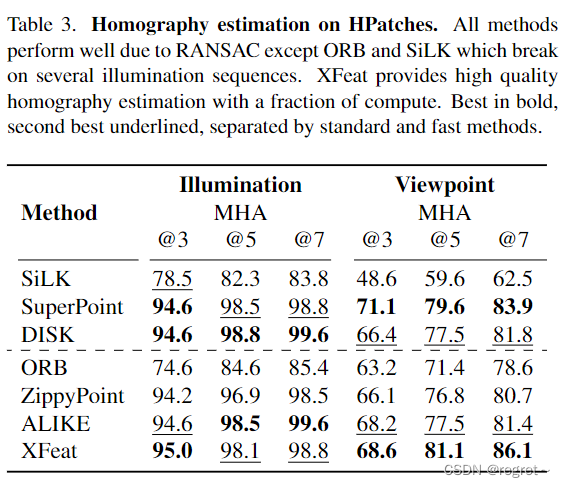
2 单应性估计
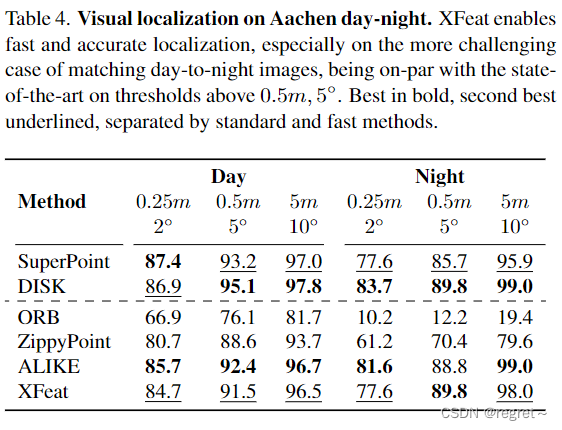
3 视觉定位

















 1372
1372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









