







一步步搭建循环神经网络
将在numpy中实现一个循环神经网络
Recurrent Neural Networks (RNN) are very effective for Natural Language Processing and other sequence tasks because they have "memory". 他们可以读取一个输入 \(x^{\langle t \rangle}\) (such as words) one at a time, 并且通过隐藏层激活 从一个 time-step 传递到下一个 time-step 来记住一些信息(information/context). 这允许单向RNN(uni-directional RNN)从过去获取信息来处理后面的输入,双向RNN(A bidirection RNN) 可以从过去和未来中获取上下文。
Notation:
-
上标(Superscript) \([l]\) 表示 \(l^{th}\) layer.
- Example: \(a^{[4]}\) is the \(4^{th}\) layer activation. \(W^{[5]}\) and \(b^{[5]}\) are the \(5^{th}\) layer parameters.
-
Superscript \((i)\) 表示 \(i^{th}\) example.
- Example: \(x^{(i)}\) is the \(i^{th}\) training example input.
-
Superscript \(\langle t \rangle\) 表示 \(t^{th}\) time-step.
- Example: \(x^{\langle t \rangle}\) 表示输入\(x\) 的 \(t^{th}\) time-step. \(x^{(i)\langle t \rangle}\) 表示输入\(x\) 的 第\(i\)个样本 的\(t^{th}\) timestep.
-
下标(Lowerscript) \(i\) 表示 \(i^{th}\) entry of a vector.
- Example: \(a^{[l]}_i\) 表示 \(l\) 层中的 \(i^{th}\) entry of the activations.
Example:
- \(a^{(2)[3]<4>}_5\) denotes the activation of the 2nd training example (2), 3rd layer [3], 4th time step <4>, and 5th entry in the vector.
import numpy as np
from rnn_utils import *1. Forward propagation for the basic Recurrent Neural Network
实现一个基本的RNN结构,这里,\(T_x = T_y\).
3D Tensor of shape \((n_{x},m,T_{x})\)
- The 3-dimensional tensor \(x\) of shape \((n_x,m,T_x)\) represents the input \(x\) that is fed into the RNN.
Taking a 2D slice for each time step: \(x^{\langle t \rangle}\)
- At each time step, we'll use a mini-batches of training examples (not just a single example).
- So, for each time step \(t\), we'll use a 2D slice of shape \((n_x,m)\).
- We're referring to this 2D slice as \(x^{\langle t \rangle}\). The variable name in the code is
xt.
Definition of hidden state \(a\)
- The activation \(a^{\langle t \rangle}\) that is passed to the RNN from one time step to another is called a "hidden state."
Dimensions of hidden state \(a\)
- Similar to the input tensor \(x\), the hidden state for a single training example is a vector of length \(n_{a}\).
- If we include a mini-batch of \(m\) training examples, the shape of a mini-batch is \((n_{a},m)\).
- When we include the time step dimension, the shape of the hidden state is \((n_{a}, m, T_x)\)
- We will loop through the time steps with index \(t\), and work with a 2D slice of the 3D tensor.
- We'll refer to this 2D slice as \(a^{\langle t \rangle}\).
- In the code, the variable names we use are either
a_prevora_next, depending on the function that's being implemented. - The shape of this 2D slice is \((n_{a}, m)\)
Dimensions of prediction \(\hat{y}\)
- Similar to the inputs and hidden states, \(\hat{y}\) is a 3D tensor of shape \((n_{y}, m, T_{y})\).
- \(n_{y}\): number of units in the vector representing the prediction.
- \(m\): number of examples in a mini-batch.
- \(T_{y}\): number of time steps in the prediction.
- For a single time step \(t\), a 2D slice \(\hat{y}^{\langle t \rangle}\) has shape \((n_{y}, m)\).
- In the code, the variable names are:
y_pred: \(\hat{y}\)yt_pred: \(\hat{y}^{\langle t \rangle}\)
实现RNN具体步骤:
-
Implement the calculations needed for one time-step of the RNN. (实现 RNN的一个时间步 所需要计算的东西)
-
Implement a loop over \(T_x\) time-steps in order to process all the inputs, one at a time. (在 \(T_x\) 时间步上实现一个循环,以便一次处理所有输入)
1.1 RNN cell
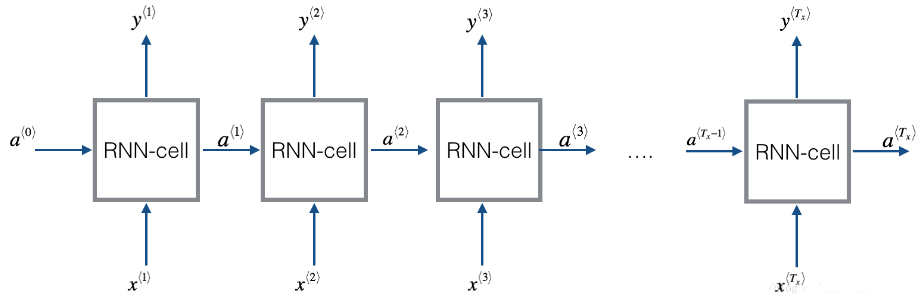
循环神经网络可以看作是单元的重复(repetition),首先要实现单个时间步的计算,下图描述了RNN单元的单个时间步的操作。

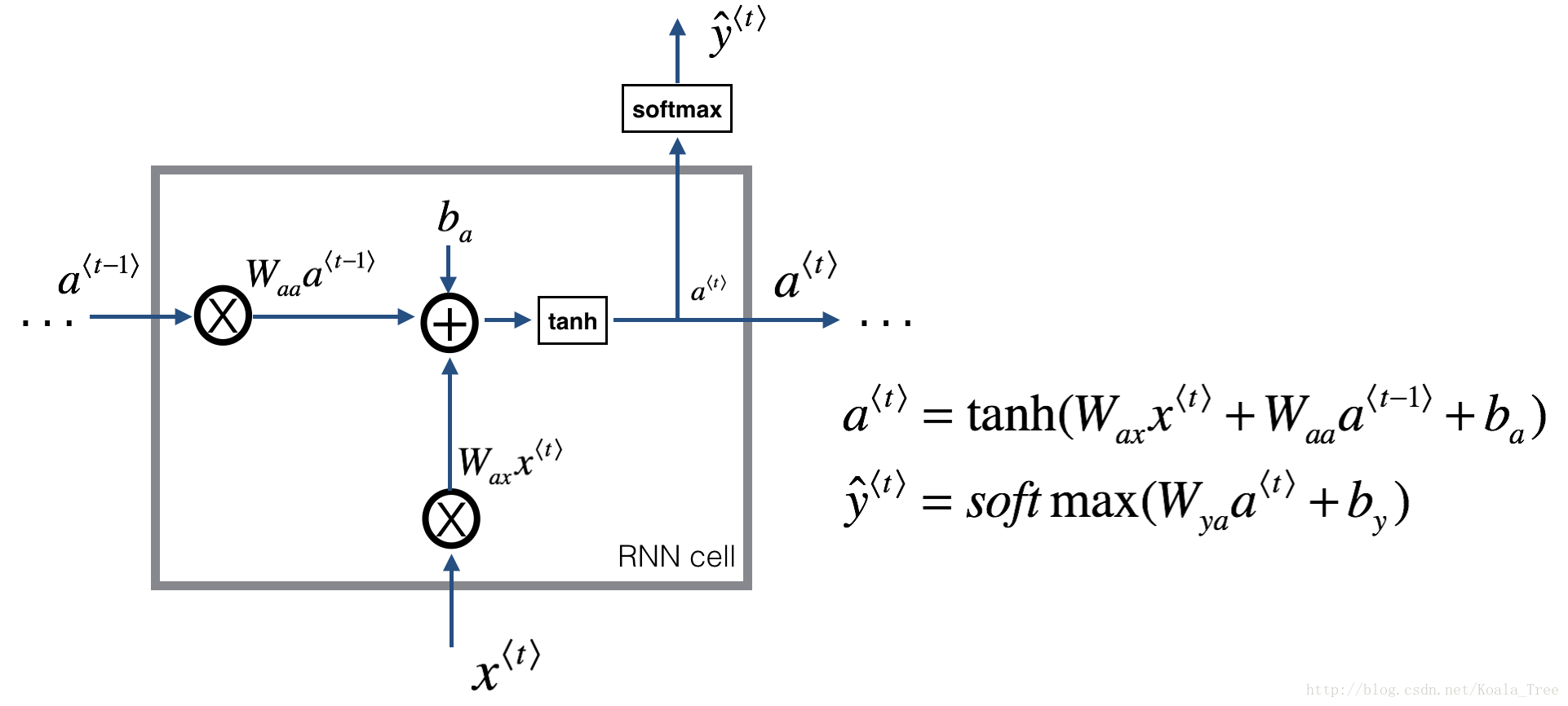
Figure 2: Basic RNN cell. Takes as input \(x^{\langle t \rangle}\) (current input) and \(a^{\langle t - 1\rangle}\) (previous hidden state containing information from the past), and outputs \(a^{\langle t \rangle}\) which is given to the next RNN cell and also used to predict \(y^{\langle t \rangle}\)
Instructions:
-
Compute the hidden state with tanh activation: \(a^{\langle t \rangle} = \tanh(W_{aa} a^{\langle t-1 \rangle} + W_{ax} x^{\langle t \rangle} + b_a)\).
-
Using your new hidden state \(a^{\langle t \rangle}\), compute the prediction \(\hat{y}^{\langle t \rangle} = softmax(W_{ya} a^{\langle t \rangle} + b_y)\). We provided you a function:
softmax. -
Store \((a^{\langle t \rangle}, a^{\langle t-1 \rangle}, x^{\langle t \rangle}, parameters)\) in cache
-
Return \(a^{\langle t \rangle}\) , \(y^{\langle t \rangle}\) and cache
We will vectorize over \(m\) examples. Thus, \(x^{\langle t \rangle}\) will have dimension \((n_x,m)\), and \(a^{\langle t \rangle}\) will have dimension \((n_a,m)\).
# GRADED FUNCTION: rnn_cell_forward
def rnn_cell_forward(xt, a_prev, parameters):
"""
Implements a single forward step of the RNN-cell as described in Figure (2)
Arguments:
xt -- your input data at timestep "t", numpy array of shape (n_x, m).
a_prev -- Hidden state at timestep "t-1", numpy array of shape (n_a, m)
parameters -- python dictionary containing:
Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x)
Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a)
Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
ba -- Bias, numpy array of shape (n_a, 1)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
Returns:
a_next -- next hidden state, of shape (n_a, m)
yt_pred -- prediction at timestep "t", numpy array of shape (n_y, m)
cache -- tuple of values needed for the backward pass, contains (a_next, a_prev, xt, parameters)
"""
# Retrieve parameters from "parameters"
Wax = parameters["Wax"]
Waa = parameters["Waa"]
Wya = parameters["Wya"]
ba = parameters["ba"]
by = parameters["by"]
### START CODE HERE ### (≈2 lines)
# compute next activation state using the formula given above
a_next = np.tanh(np.dot(Waa, a_prev) + np.dot(Wax, xt) + ba)
# compute output of the current cell using the formula given above
yt_pred = softmax(np.dot(Wya, a_next) + by)
### END CODE HERE ###
# store values you need for backward propagation in cache
cache = (a_next, a_prev, xt, parameters)
return a_next, yt_pred, cache测试:
np.random.seed(1)
xt = np.random.randn(3,10)
a_prev = np.random.randn(5,10)
Waa = np.random.randn(5,5)
Wax = np.random.randn(5,3)
Wya = np.random.randn(2,5)
ba = np.random.randn(5,1)
by = np.random.randn(2,1)
parameters = {"Waa": Waa, "Wax": Wax, "Wya": Wya, "ba": ba, "by": by}
a_next, yt_pred, cache = rnn_cell_forward(xt, a_prev, parameters)
print("a_next[4] = ", a_next[4])
print("a_next.shape = ", a_next.shape)
print("yt_pred[1] =", yt_pred[1])
print("yt_pred.shape = ", yt_pred.shape)a_next[4] = [ 0.59584544 0.18141802 0.61311866 0.99808218 0.85016201 0.99980978
-0.18887155 0.99815551 0.6531151 0.82872037]
a_next.shape = (5, 10)
yt_pred[1] = [0.9888161 0.01682021 0.21140899 0.36817467 0.98988387 0.88945212
0.36920224 0.9966312 0.9982559 0.17746526]
yt_pred.shape = (2, 10)
1.2 RNN的前向传播
一个RNN是刚刚构建的 cell 的重复, 如果输入的数据序列经过10个时间步,那么将复制RNN单元10次,每个单元将前一个单元中的hidden state(\(a^{\langle t-1 \rangle}\)) 和当前时间步的输入数据(\(x^{\langle t \rangle}\)) 作为输入。它输出当前 time-step的 a hidden state (\(a^{\langle t \rangle}\)) and a prediction (\(y^{\langle t \rangle}\)).
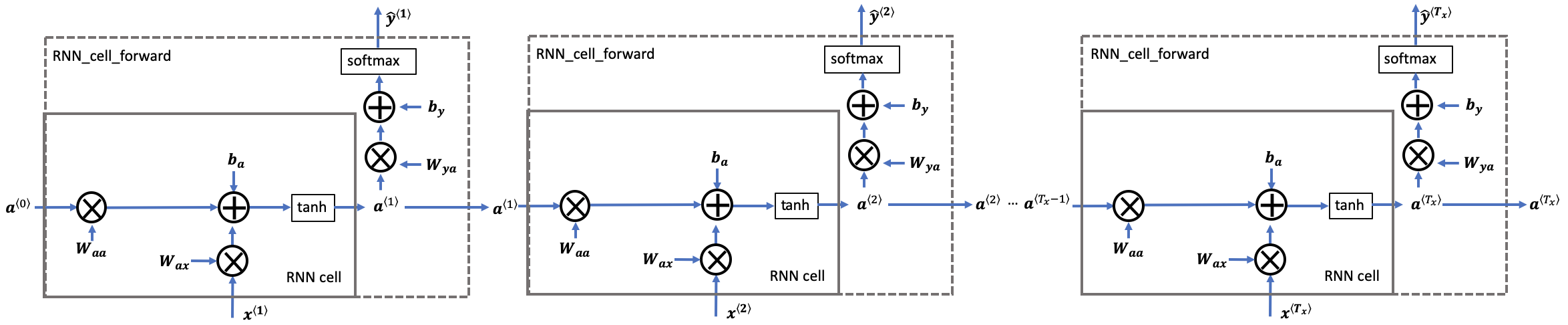
Figure 3: Basic RNN. The input sequence \(x = (x^{\langle 1 \rangle}, x^{\langle 2 \rangle}, ..., x^{\langle T_x \rangle})\) is carried over \(T_x\) time steps. The network outputs \(y = (y^{\langle 1 \rangle}, y^{\langle 2 \rangle}, ..., y^{\langle T_x \rangle})\).
Instructions:
-
创建 维度\((n_{a}, m, T_{x})\) 的零向量zeros (\(a\)) 将保存 由RNN计算的 所有 the hidden states
a. -
使用 \(a_0\) (initial hidden state) 初始化 the "next" hidden state .
-
开始循环所有的 time-step, your incremental index is \(t\) :
-
使用
rnn_cell_forward函数 更新 "next" hidden state and the cache. -
使用 \(a\) 来保存 "next" hidden state (
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 484
484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









