







 本文深入探讨了Keras实现的Faster-RCNN中涉及的损失函数,包括RPN分类和回归损失以及最终的分类和框回归损失。同时,详细介绍了如何使用xml.etree.ElementTree模块解析PASCAL VOC的XML文件,以提取训练所需的数据。
本文深入探讨了Keras实现的Faster-RCNN中涉及的损失函数,包括RPN分类和回归损失以及最终的分类和框回归损失。同时,详细介绍了如何使用xml.etree.ElementTree模块解析PASCAL VOC的XML文件,以提取训练所需的数据。
Keras版Faster-RCNN代码学习(IOU,RPN)1
Keras版Faster-RCNN代码学习(Batch Normalization)2
Keras版Faster-RCNN代码学习(loss,xml解析)3
Keras版Faster-RCNN代码学习(roipooling resnet/vgg)4
Keras版Faster-RCNN代码学习(measure_map,train/test)5
损失函数
在Faster-RCNN里主要有4种损失,RPN分类损失、RPN框回归损失、最后的分类损失、最后的框回归损失。
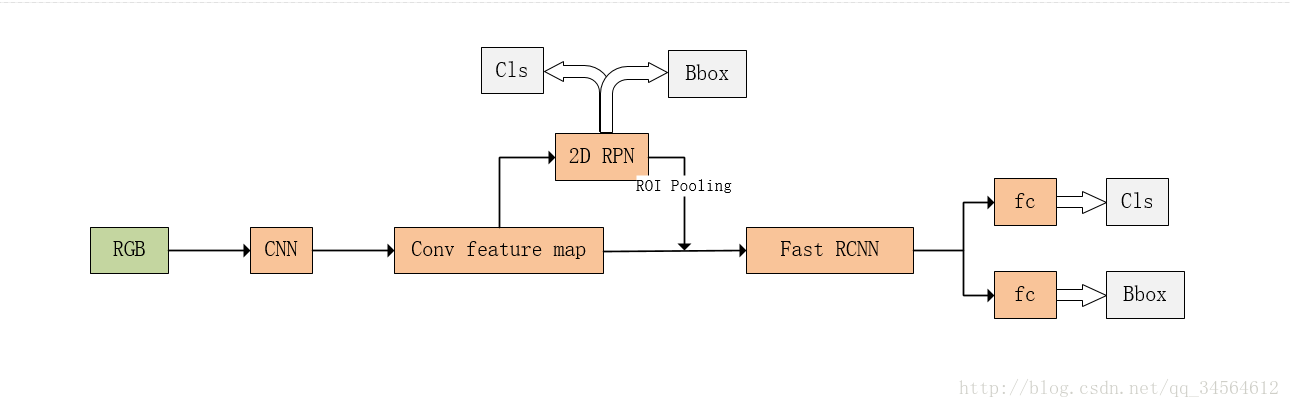
损失函数主要衡量预测值和真实值差异,可以使用基于梯度的学习方法,对参数进行学习。
在keras中,自定义的损失函数以下列两个参数为参数:
- y_true:真实的数据标签,Theano/TensorFlow张量
- y_pred:预测值,与y_true相同shape的Theano/TensorFlow张量
分类为交叉熵,回归用L1smooth,batchsize均为框的数量,且RPN和最后的总损失不一样
losses.py
from keras import backend as K
from keras.objectives import categorical_crossentropy
if K.image_dim_ordering() == 'tf':
import tensorflow as tf
lambda_rpn_regr = 1.0
lambda_rpn_class = 1.0
lambda_cls_regr = 1.0
lambda_cls_class = 1.0
epsilon = 1e-4
#RPN框回归损失,先传递框的数量
def rpn_loss_regr(num_anchors):
def rpn_loss_regr_fixed_num(y_true, y_pred):
if K.image_dim_ordering() == 'th':
x = y_true[:, 4 * num_anchors:, :, :] - y_pred
x_abs = K.abs(x)
x_bool = K.less_equal(x_abs, 1.0)
return lambda_rpn_regr * K.sum(
y_true[:, :4 * num_anchors, :, :] * (x_bool * (0.5 * x * x) + (1 - x_bool) * (x_abs - 0.5))) / K.sum(epsilon + y_true[:, :4 * num_anchors, :, :])
else:
x = y_true[:, :, :, 4 * num_anchors:] - y_pred
x_abs = K.abs(x)
x_bool = K.cast(K.less_equal(x_abs, 1.0), tf.float32)
return lambda_rpn_regr * K.sum(
y_true[:, :, :, :4 * num_anchors] * (x_bool * (0.5 * x * x) + (1 - x_bool) * (x_abs - 0.5))) / K.sum(epsilon + y_true[:, :, :, :4 * num_anchors])
return rpn_loss_regr_fixed_num
#RPN分类损失,先传递框的数量
def rpn_loss_cls(num_anchors):
def rpn_loss_cls_fi 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









