







[Title]Continual Instruction Tuning for Large Multimodal Models
Paper的任务
提升大型多模态模型在持续指令调整过程中的性能
任务的科学问题
本文任务虽然是:在大型多模态模型(LMMs)中实现有效的持续指令调整以学习新任务,但其实其本质科学问题是:如何在模型连续学习新任务的同时,减少对先前学习任务知识的灾难性遗忘。
原因是:持续学习的核心挑战在于如何平衡新知识的获取与旧知识的保留,这是由于神经网络在新任务上的微调可能导致对旧任务知识的遗忘。
challenges
在大型多模态模型(LMMs)中实现持续指令调整时,如何有效地维持对先前任务的记忆,同时学习新任务,避免因新任务学习而导致的灾难性遗忘。(因为LMMs现在要面对的是不断增长的任务数量和更多样化的数据类型)。
文章在Argue什么?
- 灾难性遗忘的问题:尽管现有的大型多模态模型在多任务学习中表现出色,但它们在持续学习新任务时仍然会遭受灾难性遗忘,即在学习新任务时遗忘旧任务的知识。
- 现有方法的局限性:现有的持续学习方法在应用到大型多模态模型的持续指令调整时存在局限性,特别是正则化方法在没有预先在多任务上进行指令调整的模型上效果不佳。
motivation
- 利用任务相似性:通过分析和利用不同任务之间的相似性,可以更有效地重用模型在先前任务上学到的知识,从而提高持续学习的效率。(现有的持续学习方法没有充分利用不同任务之间的相似性来增强模型的抗遗忘能力和迁移学习能力)
- 适应不断变化的数据:在实际应用中,视觉-语言任务是不断被创建和更新的。所以要通过持续学习,使模型能够灵活地适应这些不断变化的数据和任务。
方法及框架图
-
方法
-
- 任务相似性度量:通过计算不同任务的数据集(图像、文本输入和文本输出)的嵌入表示的平均值来确定任务之间的相似度。
- 任务相似性感知的正则化(Task-Similarity-Informed Regularization, TIR):利用任务相似性度量结果,文章设计了一种正则化方法,通过调整参数的重要性权重来减少对旧任务知识的遗忘。
- 任务相似性感知的模型扩展(Task-Similarity-Informed Model Expansion, EProj):根据任务相似性来决定是否为新任务引入特定的模型结构,以此来控制模型参数的增长。
-
框架图
-
- 任务相似性信息正则化和模型扩展方法示意图。
-
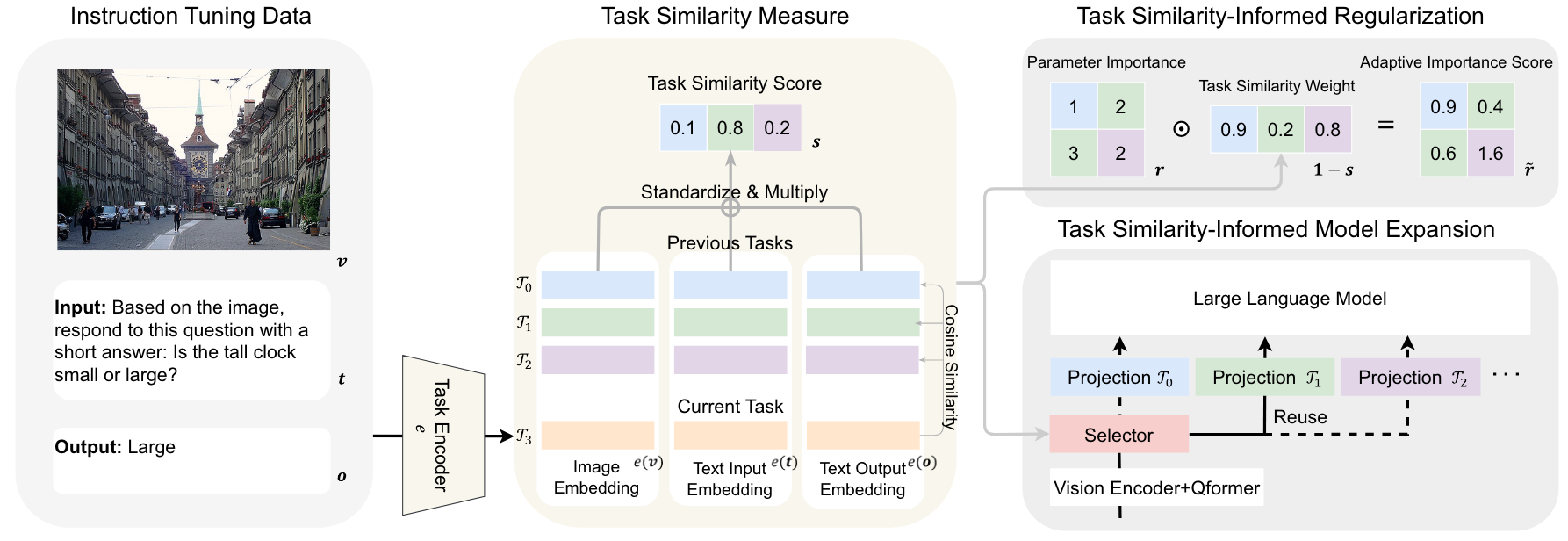
- 指令调优数据中的文本和图像分别通过其对应的任务编码器得到任务嵌入。不同颜色的任务嵌入对应不同的任务。通过融合图像、文本输入和文本输出的相似度,得到新任务与所有旧任务的相似度分数。得到的相似度得分可用于正则化方法中参数重要性的自适应加权,也可用于模型扩展方法中任务特定模块的选择或重用。
-
结果
-
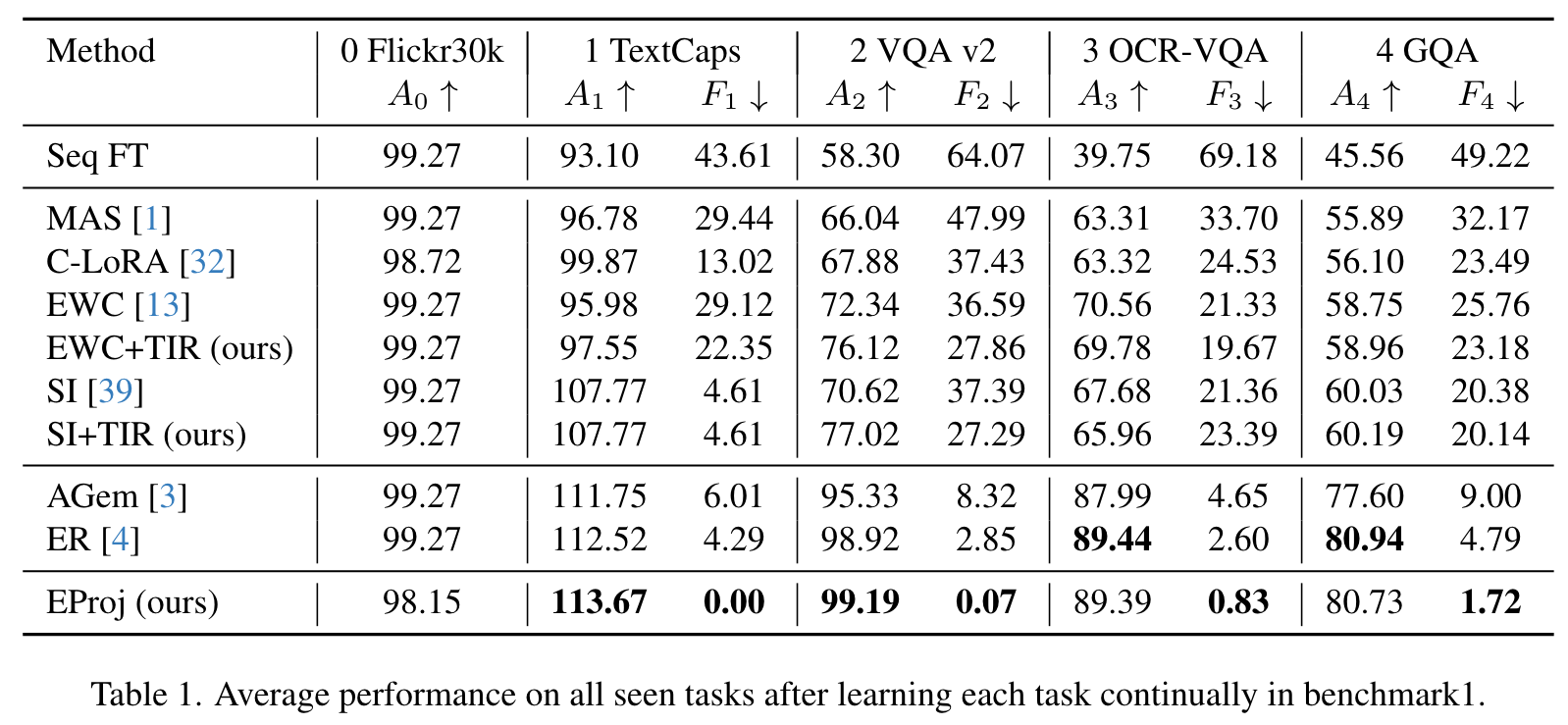
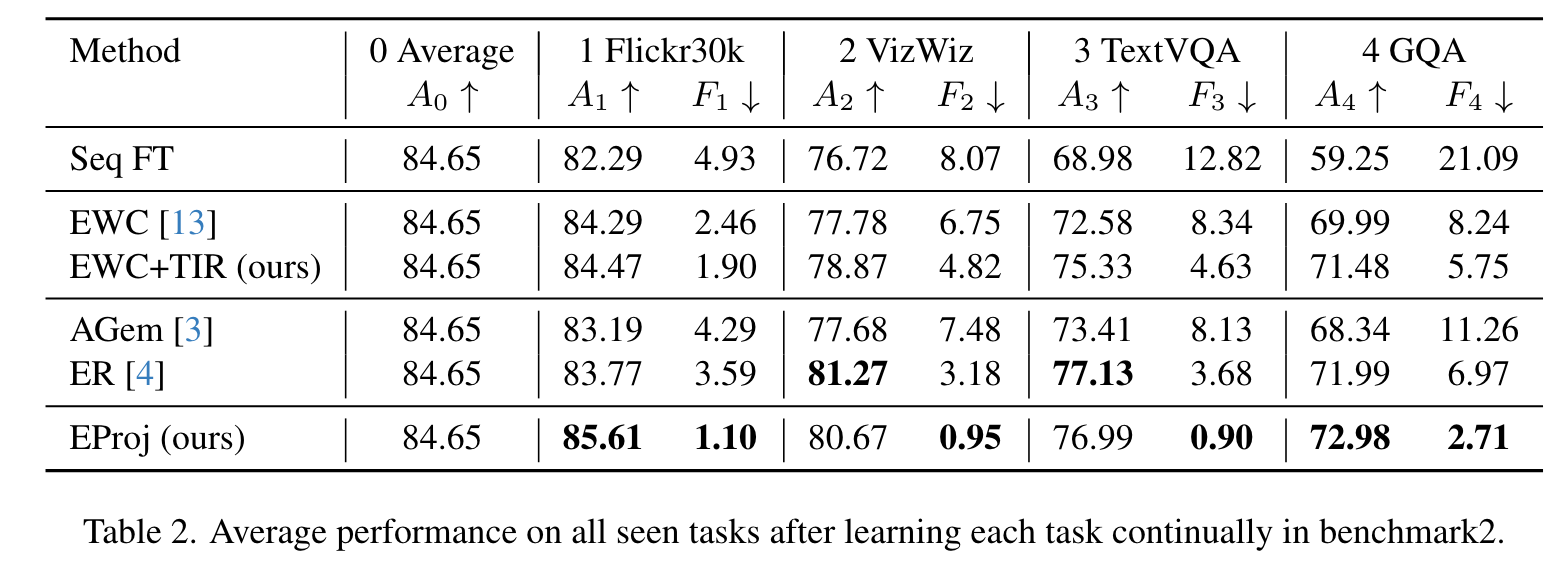
- 通过在两个基准测试(Benchmark 1和Benchmark 2)上的实验,展示了所提出方法的有效性。实验结果表明,TIR(任务相似性感知的正则化)和EProj(任务相似性感知的模型扩展)方法能够显著减少灾难性遗忘,并提高模型在持续学习过程中的性能。
- 特别是EProj(任务相似性感知的模型扩展)方法,在不需要存储旧样本或引入新模型结构的情况下,通过为每个新任务扩展投影层,实现了显著的性能提升。
-
-
实验
-
设置的实验
-
- 基准测试建立:建立了两个持续指令调整的基准测试,通过一系列视觉-语言任务来模拟持续学习的场景。
- 任务相似性度量:实验中使用了BERT和ViT模型来编码文本和图像数据,计算任务之间的相似性。
- 持续学习方法比较:比较了三种类型的持续学习方法:正则化方法、数据重放方法和模型扩展方法。
- 性能指标:使用了如准确度(ACC)和 CIDEr(用于图像描述任务)等指标来评估模型在各个任务上的性能。
-
消去实验
-
- EProj方法的消融研究
-
-
- 重用结构:重用(而不是扩展)模型结构。
- 直接重用与重训练:比较了直接重用结构和在新任务上重新训练模型的性能差异
-
-
- TIR方法的消融研究
-
-
- 自适应任务相似性权重:将自适应任务相似度权重替换为恒定值为0.5,并表明这明显不如TIR有效。这说明TIR的良好表现得益于任务相似度提供的知识。
-
文章有什么用
- 总体结论: 为了提高大型多模态模型(LMMs)在持续指令调整中的性能,特别是在减少灾难性遗忘和提高任务迁移能力方面,是可以使用基于任务相似性感知的正则化和模型扩展方法的。
- 贡献点结论:
-
- 任务相似性度量:通过计算不同任务之间的图像、文本输入和文本输出的嵌入表示的相似性,可以有效地衡量任务之间的相关性。
- 任务相似性感知的正则化(TIR):使用自适应任务相似性权重的正则化方法,可以减少模型在学习新任务时对旧任务知识的遗忘。
- 任务相似性感知的模型扩展(EProj):通过为每个新任务动态扩展模型的投影层,并利用任务相似性来决定是否重用先前任务的结构,可以有效地控制模型参数的增长并提高持续学习的性能。
- 持续学习性能提升:实验结果表明,所提出的方法在多个基准测试中均能显著提升模型在持续学习过程中的性能,减少遗忘,并提高对新任务的适应能力。
笔记
- 持续学习(Continual Learning): 持续学习是机器学习的一个领域,专注于构建能够随着时间的推移而不断学习新任务的模型,同时保留之前学到的知识。这类似于人类的学习过程,即在学习新技能时不会忘记已经掌握的技能。
- 灾难性遗忘(Catastrophic Forgetting): 当一个神经网络模型在学习新任务的过程中,突然丧失了之前已经学到的任务的知识,这种现象被称为灾难性遗忘。它是持续学习领域中一个主要的挑战。
- 任务相似性(Task Similarity): 任务相似性是指不同学习任务之间的相似度,这可以通过比较任务的数据特征、输出结果或其他相关指标来衡量。在持续学习中,任务相似性可以被用来指导模型如何更有效地利用已有的知识来学习新任务。
- 正则化方法: 正则化是机器学习中用来减少模型过拟合的技术。过拟合是指模型在训练数据上表现得很好,但在未见过的测试数据上表现差。正则化通过在损失函数中添加额外的惩罚项来限制模型的复杂度,从而提高模型的泛化能力。
- 数据重放(Data Replay): 数据重放是一种持续学习策略,它涉及在训练新任务时重新使用或“重放”旧任务的数据。这种方法有助于减少灾难性遗忘,因为它允许模型在学习新知识的同时复习旧知识。
- 模型扩展(Model Expansion): 模型扩展是一种持续学习策略,它通过为模型添加新的参数或结构来适应新任务的需求。这种方法可以使模型在不破坏已有知识的情况下,增加新任务所需的知识容量。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









