







Paper的任务
组合零样本学习(Compositional Zero-Shot Learning, CZSL)
任务的科学问题
本文任务虽然是:组合零样本学习(Compositional Zero-Shot Learning, CZSL),
但其实其本质科学问题是:如何通过语言信息增强的分布提示来提升模型对未见组合视觉概念的识别能力。
原因是:CZSL旨在使模型能够识别由已见组合学习后推及到未见组合的视觉概念,文章提出的方法就是通过利用预训练的大型语言模型(LLM)生成的文本描述来构建类别特定的分布,从而增强类别嵌入的多样性和信息量以此提升零样本泛化能力。
challenges
- 类别上下文的多样性和信息量(context diversity、context informativeness):如何确保类别的文本描述不仅多样化,而且富含信息,以便增强在细粒度组成类别上的表现。
- 视觉原语(visual primitives)的纠缠问题:在图像中,视觉原语(如状态和对象)往往是相互纠缠的,如何有效地将它们分解并重新组合,以便对未见过的组合进行识别。
文章在Argue什么?
- 类别上下文缺乏多样性和信息量:现有的硬提示(hard prompt)受限于提示模板的启发式设计,且每个类的单个提示缺乏捕获视觉数据类内变化的多样性。而软提示(soft prompt)虽然提供了一定的改进,但仍然缺乏语言信息量。
- 视觉原语分解的缺失:文章提出,视觉原语(如颜色、形状等)在图像中的纠缠增加了学习可分解视觉表示的难度,但这对于组合泛化至关重要,而在现有方法中并未得到很好的解决(虽然也有一些相关工作在考虑这个问题,但是只利用了纯语言分解和概率级混合,可推广性低)。
motivation
- 类别上下文的多样性和信息量:传统的基于视觉的方法和现有的CLIP模型在处理CZSL任务时,未能充分考虑类别上下文的多样性和信息量,文章提出,可以通过LLM生成的描述性文本来构建类别特定的分布,这些描述性文本能够提供更细致的类别上下文,从而增强类别嵌入的多样性和信息量。
- 视觉原语的纠缠问题:在CZSL任务中,视觉原语(如状态和对象)在图像中往往是相互纠缠的,文章提出一个视觉原语分解模块(Visual-Language Primitive Decomposition, VLPD)模块来分解图像数据中的简单原语,从而使得可以从这些原语重新组合出决策。
- 零样本泛化能力:现有的CZSL方法在未见过的组合上泛化能力不足,无法有效识别在训练数据中未出现过的新组合。文章提出,引入随机逻辑混合(stochastic logit mixup,SLM)策略来动态融合直接预测的组合和重新组合的决策。
方法
-
方法
1.语言信息增强的分布提示(Language-Informed Distribution, LID):
-
-
- 利用LLM为每个组合类别生成多样且信息丰富的文本描述。
- 通过LLM生成的描述来构建类别特定的高斯分布,这些分布作为类别嵌入的增强信息。
-
2.视觉-语言原语分解(Visual-Language Primitive Decomposition, VLPD):
-
-
- 采用两个并行的神经网络来将图像特征分解为状态和对象的视觉特征。
- 状态和对象的视觉特征用于计算状态和对象的逻辑,这些逻辑随后用于重新组合出决策。
-
3.随机逻辑混合(Stochastic Logit Mixup, SLM):
-
-
- 在训练过程中,使用Beta分布采样的系数λ来混合直接学习到的组合逻辑和通过VLPD重新组合的逻辑。
- 这种方法允许模型在不同决策之间进行动态融合,增加了模型在训练时的正则化效果。
-
4.损失函数设计:
-
-
- 使用多类交叉熵损失来优化类别嵌入,并通过最小化负对数似然的上界来增强类别间的分离性和类别内的紧凑性。
- 对于VLPD,定义了状态和对象级别的逻辑边界项,并分别计算状态和对象的分类损失。
-
-
框架图
-
- 整体框架图:
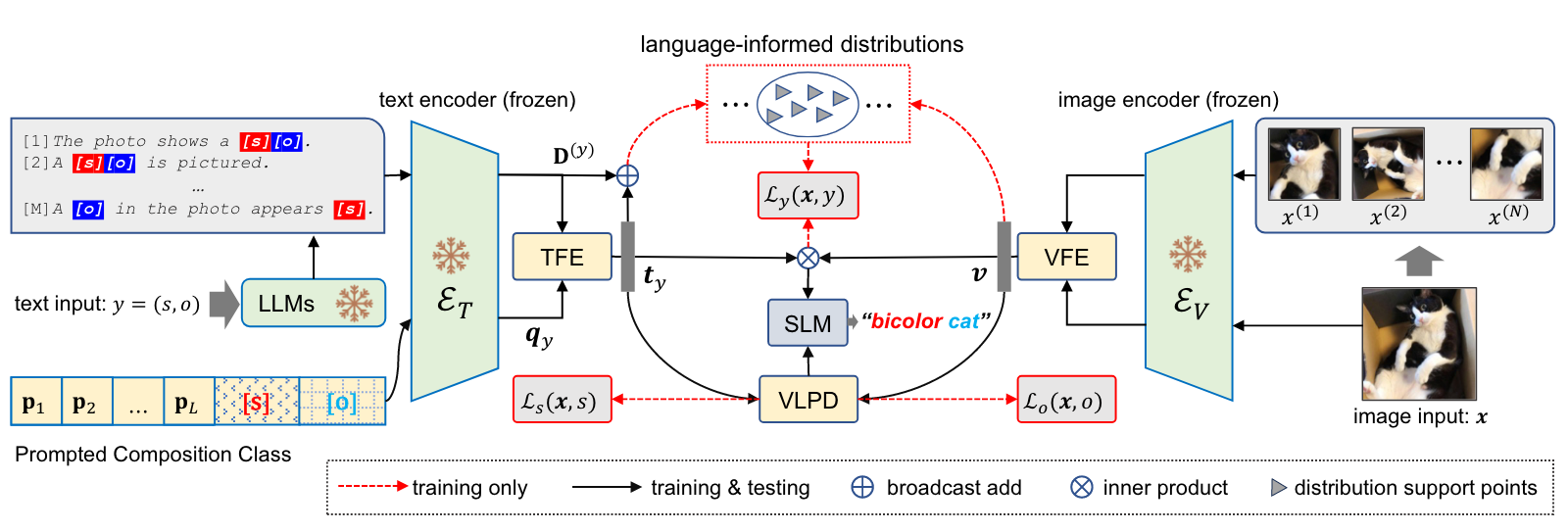
- 整体框架图:
-
- CLIP模型:使用预训练的CLIP模型作为基础,其中包括一个文本编码器(ET)和一个图像编码器(EV),在PLID中这两个编码器是冻结的。
- 文本和图像输入:输入包括一个图像x和一个组合类别y = (s, o),类别y是状态s和对象o的笛卡尔积。
- 语言信息增强(LID):利用LLM生成的类别描述来构建类别特定的分布,这些分布通过软提示(soft prompts)和类别嵌入来增强。
- 文本和视觉特征增强(TFE和VFE):通过交叉注意力机制增强文本和视觉特征。
- 视觉-语言原语分解(VLPD):将图像数据分解为状态和对象的视觉特征,然后在这些原语上进行重组,以增强组合类别的识别。
- 随机逻辑混合(SLM):在组合类别和原语类别之间进行决策融合,通过从Beta分布中采样的系数λ来混合直接学习和重组学习的逻辑。
- 损失函数:模型通过组合类别损失(Ly(x, y))、状态类别损失(Ls(x, s))和对象类别损失(Lo(x, o))进行联合训练。
-
- 混合提示(prompting)来优化类别内(intra-class)和类别间(inter-class)的协方差
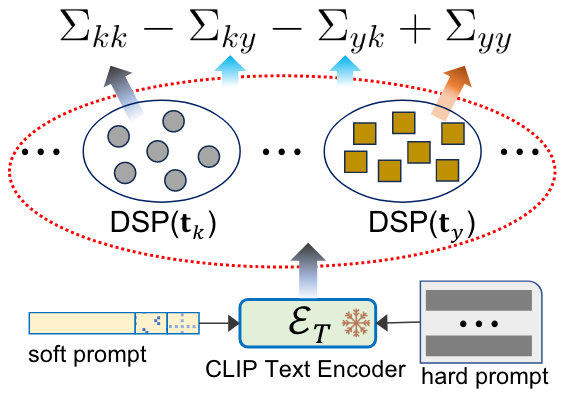
- 混合提示(prompting)来优化类别内(intra-class)和类别间(inter-class)的协方差
-
- CLIP文本编码器:将文本转换为嵌入向量。
- 软提示(soft prompt):可学习的嵌入向量
- 硬提示(hard prompt):预训练的、固定的文本模板,如“a photo of [state][object]”
- 类别特定的分布:通过使用软提示和硬提示,每个类别可以被表示为一个分布,其中分布的支持点(distribution support points, DSP)是通过对类别描述进行编码得到的。
-
- 视觉-语言原语分解(VLPD)
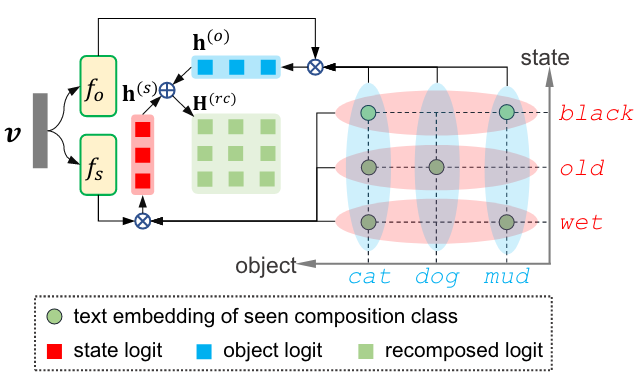
- 视觉-语言原语分解(VLPD)
-
- 视觉特征分解:图像特征通过两个并行的网络(fs和fo)被分解为状态视觉特征和对象视觉特征。
- 状态和对象的逻辑:对于给定的状态和对象,计算状态逻辑(state logit)和对象逻辑(object logit)。(通过状态和对象的视觉特征与对应的文本嵌入之间的相似度来计算)
- 重组逻辑:通过将状态逻辑和对象逻辑进行笛卡尔积,得到重组的逻辑矩阵
-
结果
-
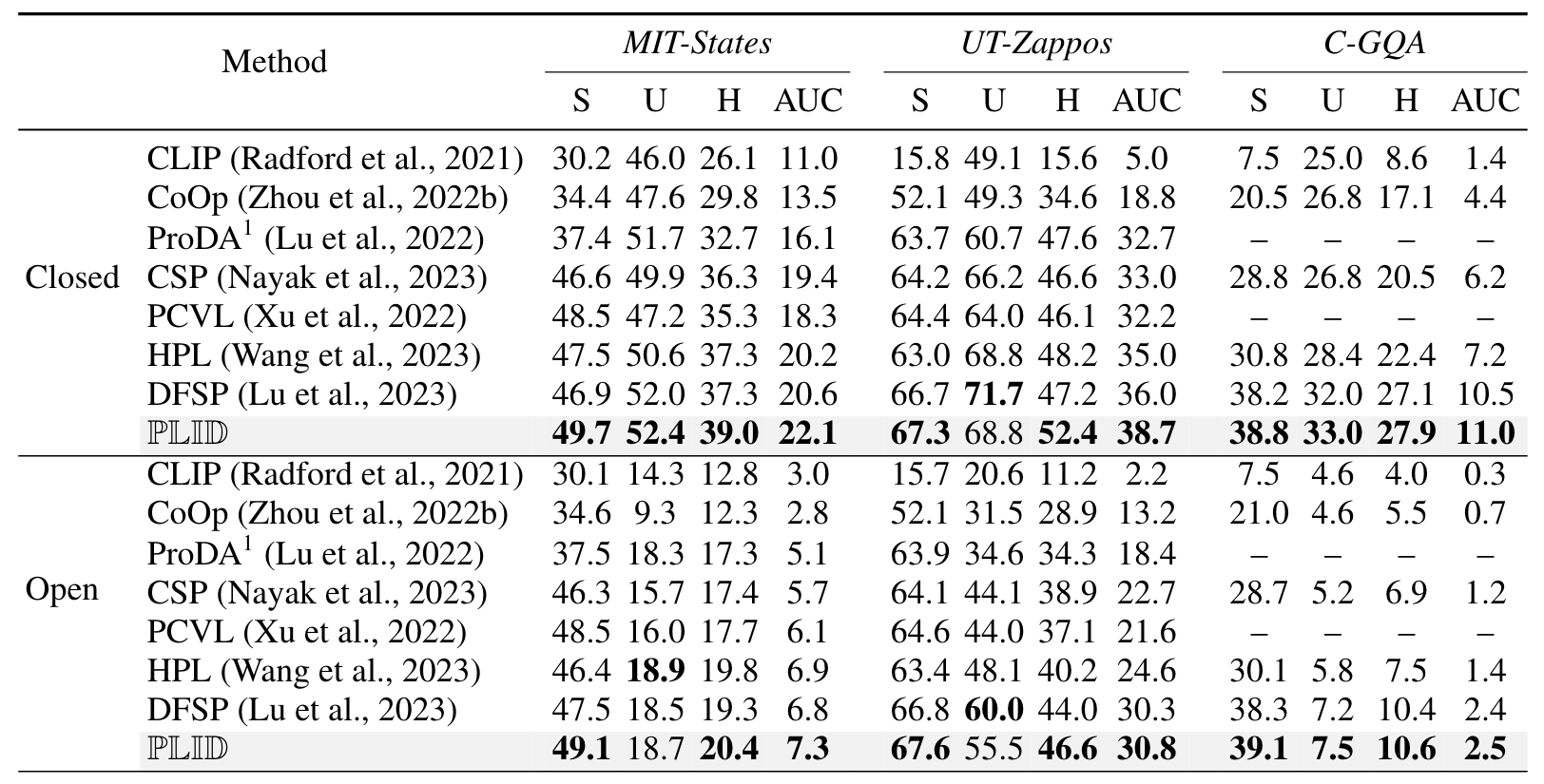
- 3个数据集的封闭世界和开放世界(Closed- and Open-World)场景下的CZSL结果
- 逐步增加组件的消融实验
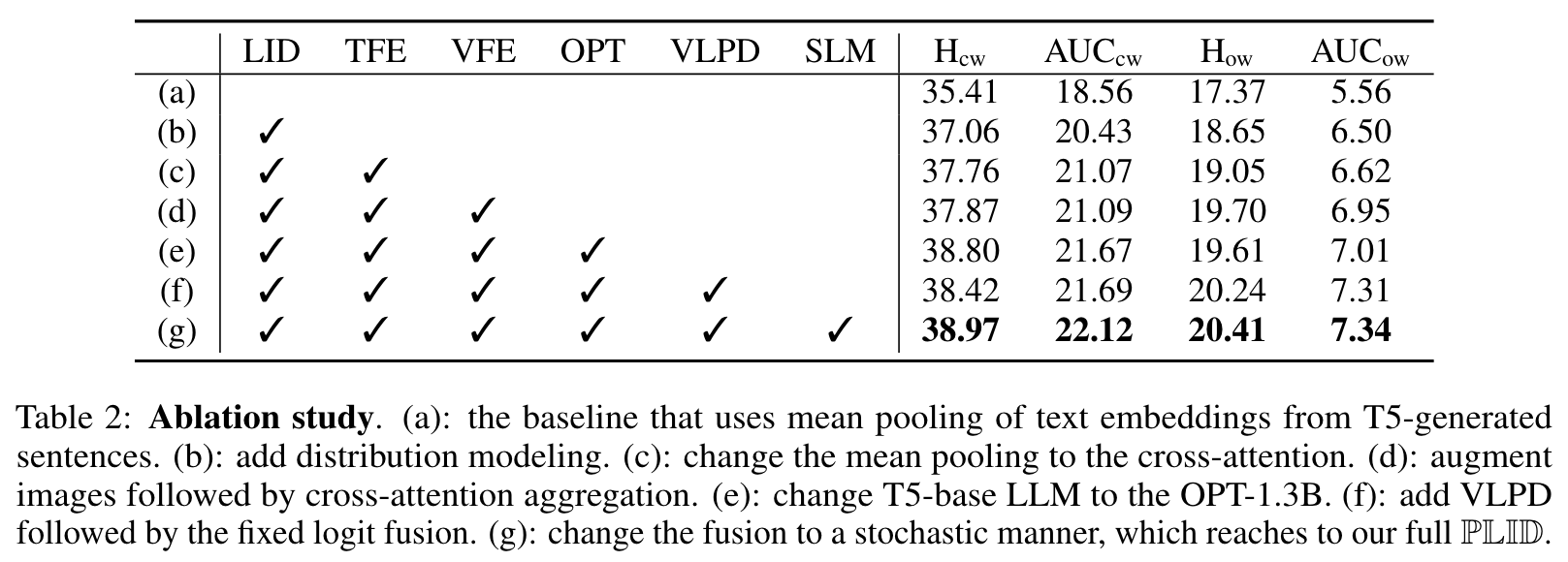
- LLM选择:评估不同LLM(T5和OPT)在生成类别描述时对模型性能的影响。
-

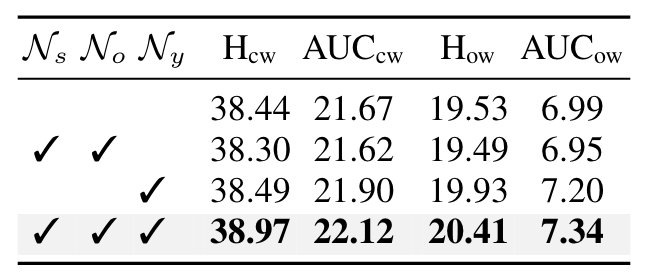
- LID效果:研究在状态(Ns)、对象(No)和组合(Ny)类别上应用LID的效果。
-
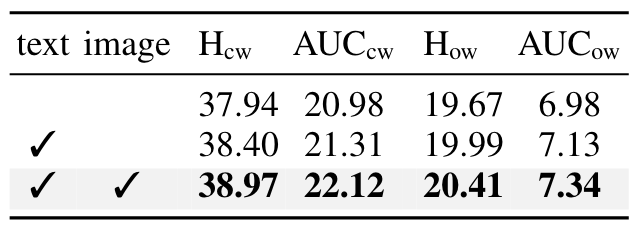
- VLPD效果:验证VLPD模块的不同设计选择,包括不进行分解、仅文本分解和视觉与文本的都分解。
-
- 3个数据集的封闭世界和开放世界(Closed- and Open-World)场景下的CZSL结果
实验设置
-
实验
-
- 主要实验:在三个CZSL数据集上评估PLID模型的性能,与现有方法进行比较。
- 消融实验
- Beta先验参数:分析Beta分布的超参数(a, b)对随机逻辑混合(SLM)效果的影响。
- 定性分析:使用t-SNE可视化技术来展示文本嵌入和学习到的分布支持点(DSP)。
- LLM选择:评估不同LLM(T5和OPT)在生成类别描述时对模型性能的影响。
- LID效果:研究在状态(Ns)、对象(No)和组合(Ny)类别上应用LID的效果。
- VLPD设计选择:验证VLPD模块的不同设计选择,包括不进行分解、仅文本分解和视觉与文本的完整分解。
-
消去实验都消去了什么?
-
- 基线模型:使用T5生成的句子的均值池化作为基线。
- 分布建模:添加分布建模来增强类别嵌入。
- 特征增强:使用交叉注意力机制来增强文本和视觉特征。
- LLM选择:比较了使用T5和OPT两种不同的LLM。
- VLPD模块:研究了是否进行原语分解以及如何分解(仅文本、仅视觉或两者兼有)。
- SLM策略:从固定逻辑融合到随机逻辑混合。
文章有什么用?
- 总体结论: 可以通过利用大型预训练语言模型(LLM)生成的描述性文本来增强模型的类别嵌入,从而提升模型的零样本学习能力。
- 贡献点结论:
-
- 使用语言信息增强的分布提示(LID),可以为CZSL任务中的细粒度类别提供更多样化和信息丰富的文本上下文,从而改善类别嵌入的质量和模型的识别性能。
- 引入视觉-语言原语分解(VLPD)模块,可以有效地将图像数据分解为状态和对象的视觉原语,进而通过重组这些原语来增强对未见组合的识别能力。
- 采用随机逻辑混合(SLM)策略,可以在训练过程中动态地融合直接学习和重组学习的决策,增加了模型的正则化效果,并提高了对未见类别的识别准确率。
笔记
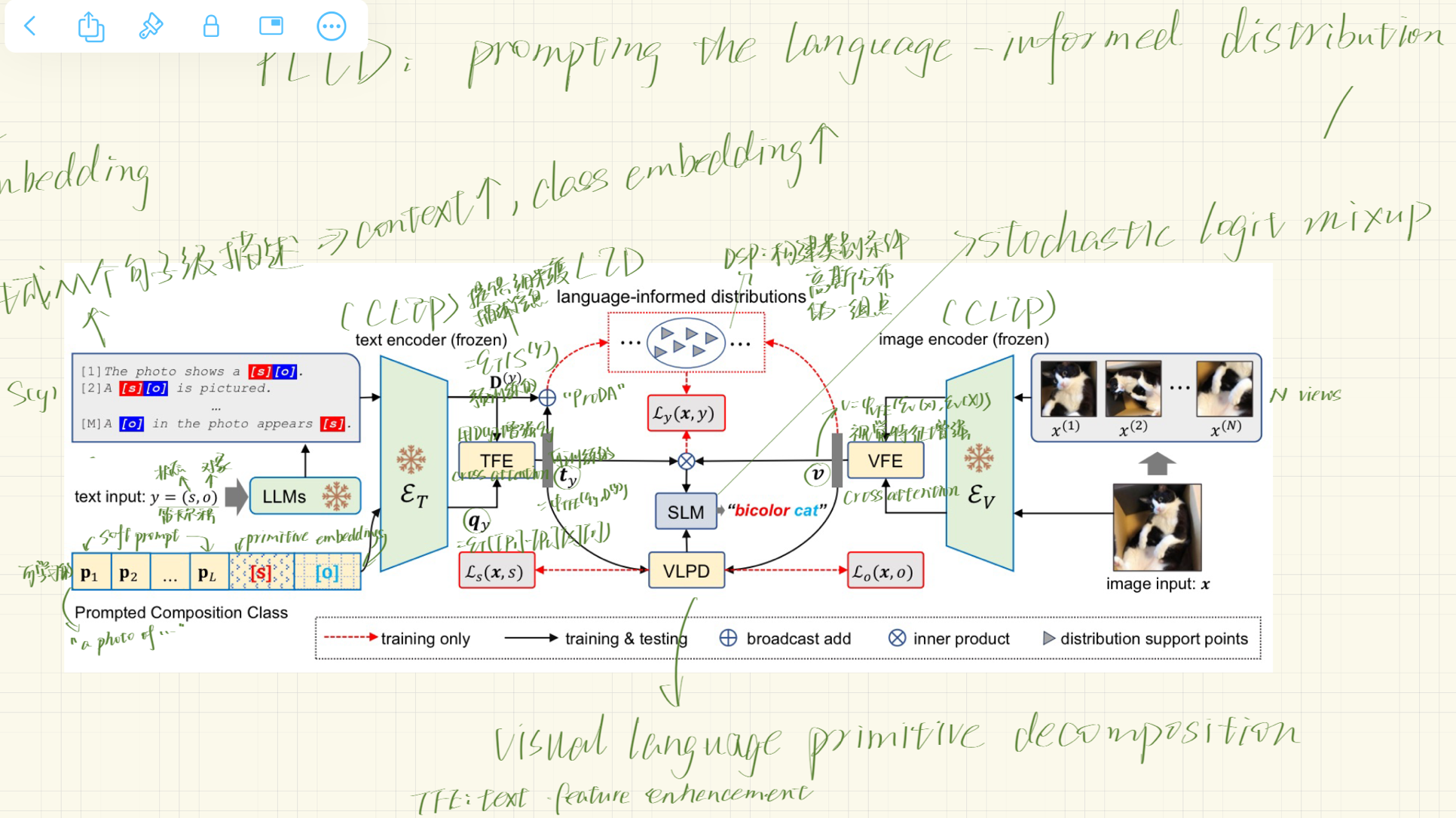
- 分布提示 (Distributional Prompting):在这种方法中,提示不是一个单一的嵌入向量,而是在嵌入空间中定义的一个分布。这允许模型在多个可能的提示示例上进行泛化,而不是仅仅依赖于一个固定的示例。
- 视觉原语 (Visual Primitives):视觉原语是构成复杂视觉场景的基本构建块,可以是简单的形状、颜色、纹理或更复杂的模式。
- 随机逻辑混合 (Stochastic Logit Mixup, SLM):SLM是一种正则化技术,它通过随机混合不同的决策路径来增加模型训练时的不确定性。
- 类别嵌入 (Class Embeddings):指将类别标签转换为连续的、低维的向量表示,这些向量可以被用来进行各种下游任务,如分类、聚类等。
- 负对数似然 (Negative Log-Likelihood, NLL):是一种常用的损失函数,用于衡量模型预测的概率分布与真实数据分布之间的差异。
- “封闭世界”(Closed World)和“开放世界”(Open World):描述模型泛化能力的两种不同的测试设置
- 封闭世界 (Closed World):
-
- 在封闭世界设置中,模型的训练和测试都限制在已知的类别集合内。也就是说,模型在训练阶段见过的类别和在测试阶段需要识别的类别是相同的。
- 这种设置假设模型在实际应用中遇到的所有类别在训练时都已经出现过,这允许对模型的准确性进行评估,但它并没有测试模型对未见过的类别的识别能力。
-
- 开放世界 (Open World):
-
- 开放世界设置是一种更具有挑战性的测试环境,它不仅包括模型在训练阶段见过的类别,还包括在训练阶段未出现过的新类别。















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









