






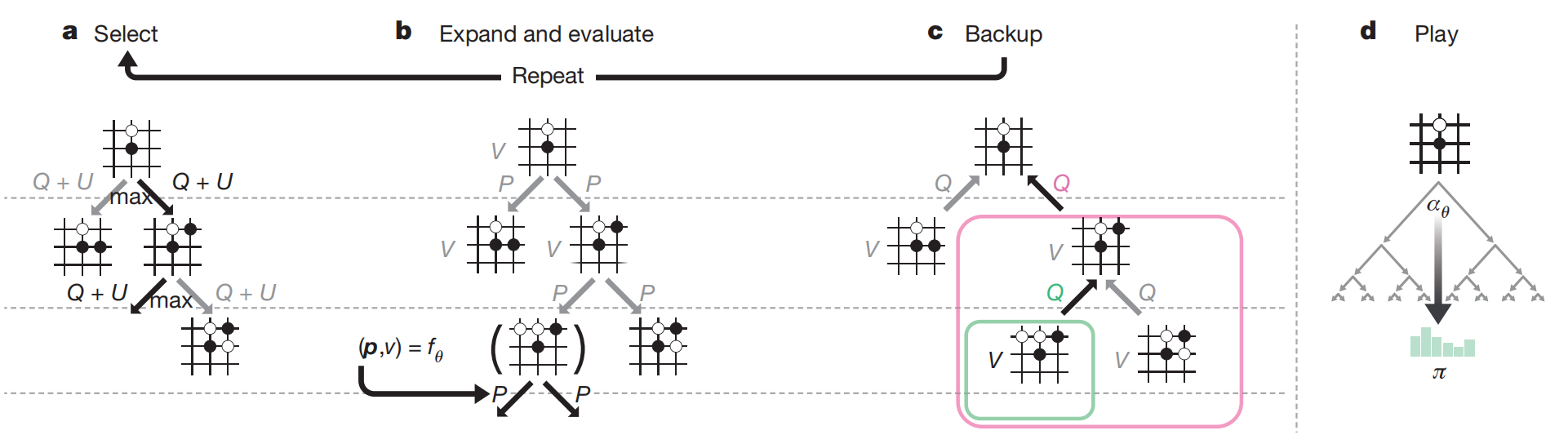
强化学习中上置信边界(Upper Confidence Bound,UCB)的核心思想是在探索(exploration)和利用(exploitation)之间找到一个平衡,用于在不确定的环境中指导决策过程,以最大化长期回报。
具体来说,UCB算法在选择动作时,不仅仅考虑已知的最佳选项(即“利用”已有信息),还会给予那些尚未充分探索的选项一定的机会(即“探索”未知领域)。这种平衡是通过给每个动作分配一个上置信边界来实现的,该边界由两部分组成:
-
动作的预期回报的估计值:这通常是根据历史数据计算得出的,代表了我们对该动作可能带来的回报的当前认知。
-
一个探索项:这个项与动作的访问次数成反比,意味着那些被较少探索的动作会获得更高的探索项值,从而增加被选择的机会。这样,算法就有机会学习到那些初始看起来不太理想但实际上可能很好的动作。
UCB算法的关键在于如何设置这个探索项。比如在AlphaGo Zero中使用的UCB公式为
Q
(
s
,
a
)
+
U
(
s
,
a
) 【U
(
s
,
a
)
∝
P
(
s
,
a
)/ (1+
N
(
s
,
a
))】
Q(s,a)+U(s,a) 表示的是动作 a 在状态 s 下的上置信边界:
-
Q(s,a) 是对动作 a 在状态 s 下的平均回报的当前估计(或者称为“利用”项),它反映了我们到目前为止对该动作的了解。
-
U(s,a) 是探索项,它鼓励算法去尝试那些尚未充分探索的动作。探索项的大小通常与动作 a 在状态 s 下被尝试的次数 N(s,a) 有关,在本公式中它依赖于存储的先验概率P和访问计数N。
doi:10.1038/nature24270
在实际应用中,上置信边界的具体形式要根据问题的特性和需求进行调整和优化。

















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









