







PG是on-policy 也就是每轮训练都需要模型取交互产生reward
PPO是off-policy, 听说openai都用的这个
甚至chatgpt也用的这个
这下不得不学了

观察这两个公式, 上面的是PG, 也就是说 必须从 中采样, 然后算概率和奖励的乘积。
下面是一个公式, 从p分布从采样x 然后把x带入fx 最后可以求Ex 但是分布不知道的时候, 可以采样N个, 用平均值代替。
但是现在不想从p的分布中采样。 只想从另一个分布中采样。 因为这样可以off-policy。 等于之前自己产生奖励, 但现在用其他模型产生动作, 计算奖励。 这样其他模型又不会更新, 产生的数据就可以一直用了。

求均值转化为求积分, 然后上下同乘Q(x) 也就是另一个分布。
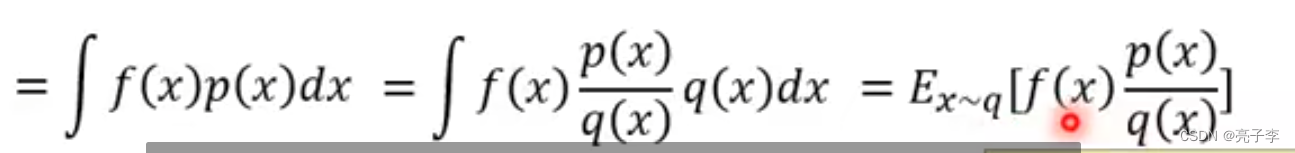
乘以q(x) 也就等于从q(x)的分布求期望。

虽然两个式子均值相等, 但是方差相差很大, 因此p和q的分布应该相差越小越好。

所以上面的式子就可以变为这个。
从 的分布中采样, 然后乘上
和
的一个权重商, 就可以得到模型更新的loss。

所以之前的梯度就变成了现在这样。
A表示某一个动作(a,s)的奖励累加起来的结果 考虑时间和后面所有奖励的结果。
现在不是是对整个事件看作一个整体了, 而是看单独的每一个pair。
然后加入 后 ,就是让
和环境进行互动了。

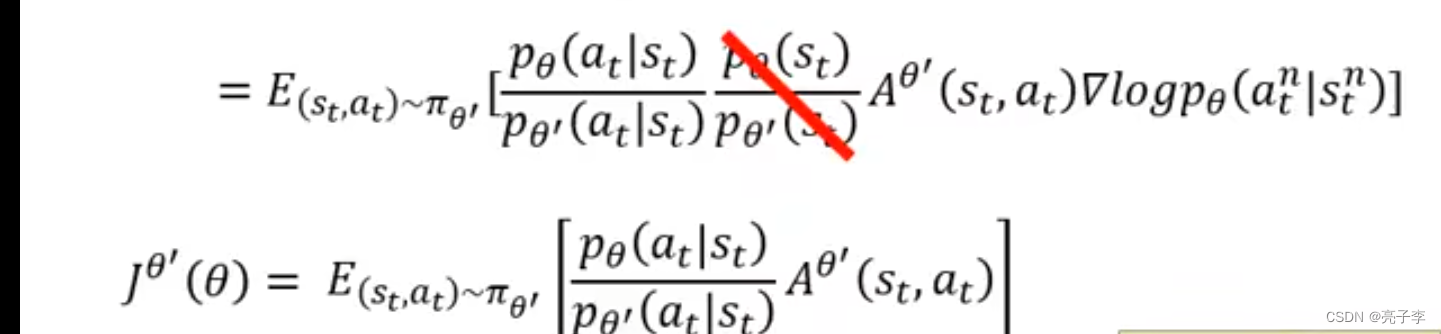
很有意思, 这里有一个概率的变换, 也就是贝叶斯公式。 然后把两个模型下某环境出现的概率强制的看作相同。 就变成了下面的式子。
下面这个J。 就是不再求导了, 相当于要优化的项, 或者说是伪loss。 之所以可以这样优化, 就是因为下面这个蓝色的公式,。

为了让两个分布的差距足够小, 需要他们的KL散度不能太大, 所以这里减去散度。
而这里的散度不是衡量他们参数分布的距离
而是他们面对一个状态, 产生的output的分布的距离、
PPO第一个版本的 的过程如下:

就是很简单。 但是KL不是很好算。 所以有了PPO2
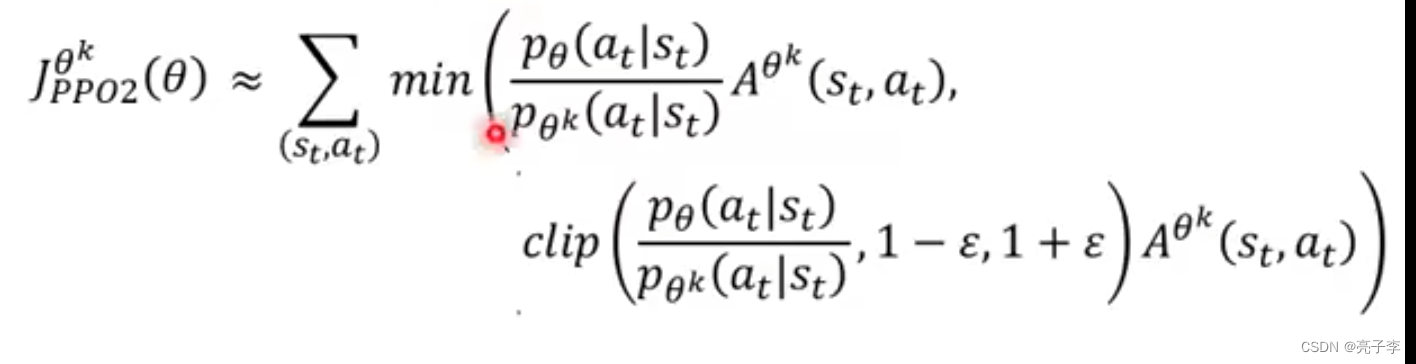
好吧 其实不是非常的懂, 但是我们还是通过代码来理解吧。
代码在这
https://github.com/datawhalechina/easy-rl/blob/master/notebooks/PPO.ipynb
class Config:
def __init__(self) -> None:
self.env_name = "CartPole-v1" # 环境名字
self.new_step_api = False # 是否用gym的新api
self.algo_name = "PPO" # 算法名字
self.mode = "train" # train or test
self.seed = 1 # 随机种子
self.device = "cuda" # device to use
self.train_eps = 200 # 训练的回合数
self.test_eps = 20 # 测试的回合数
self.max_steps = 200 # 每个回合的最大步数
self.eval_eps = 5 # 评估的回合数
self.eval_per_episode = 10 # 评估的频率
self.gamma = 0.99 # 折扣因子
self.k_epochs = 4 # 更新策略网络的次数
self.actor_lr = 0.0003 # actor网络的学习率
self.critic_lr = 0.0003 # critic网络的学习率
self.eps_clip = 0.2 # epsilon-clip
self.entropy_coef = 0.01 # entropy的系数
self.update_freq = 100 # 更新频率
self.actor_hidden_dim = 256 # actor网络的隐藏层维度
self.critic_hidden_dim = 256 # critic网络的隐藏层维度
先规定了config 环境是cartpole _v1是一个小车游戏。
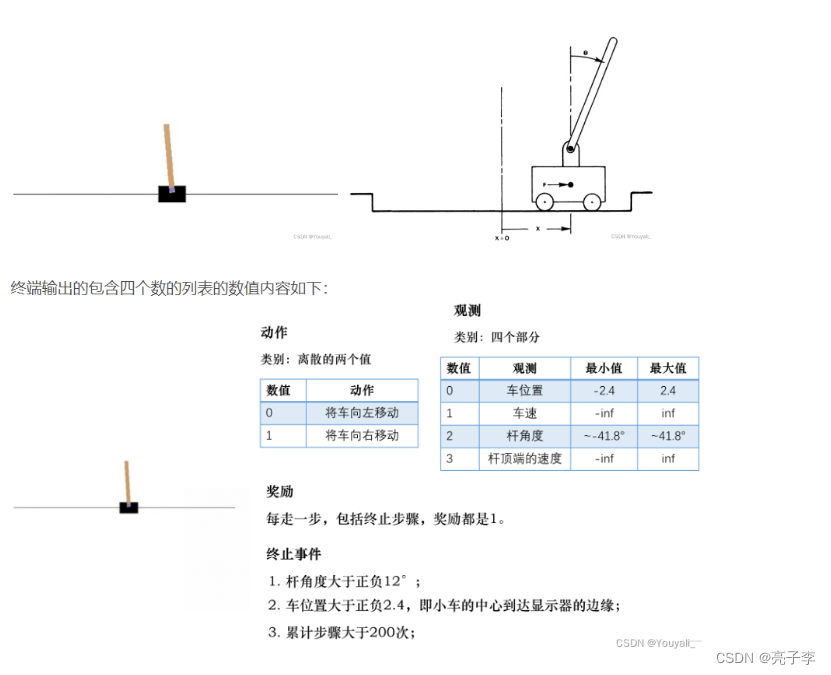
我们用PPO算法。 折扣因子应该关系着奖励的有效期。
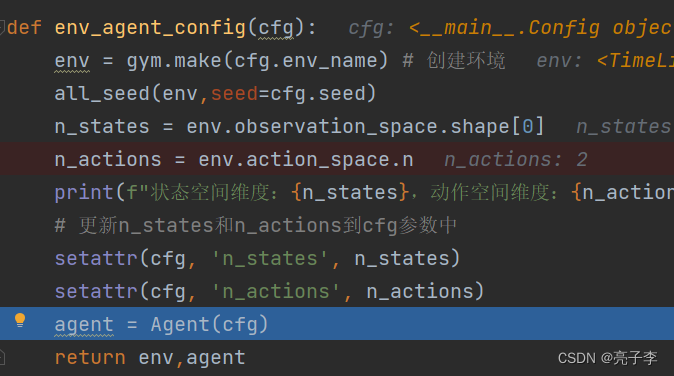
然后 通过设置创建代理。
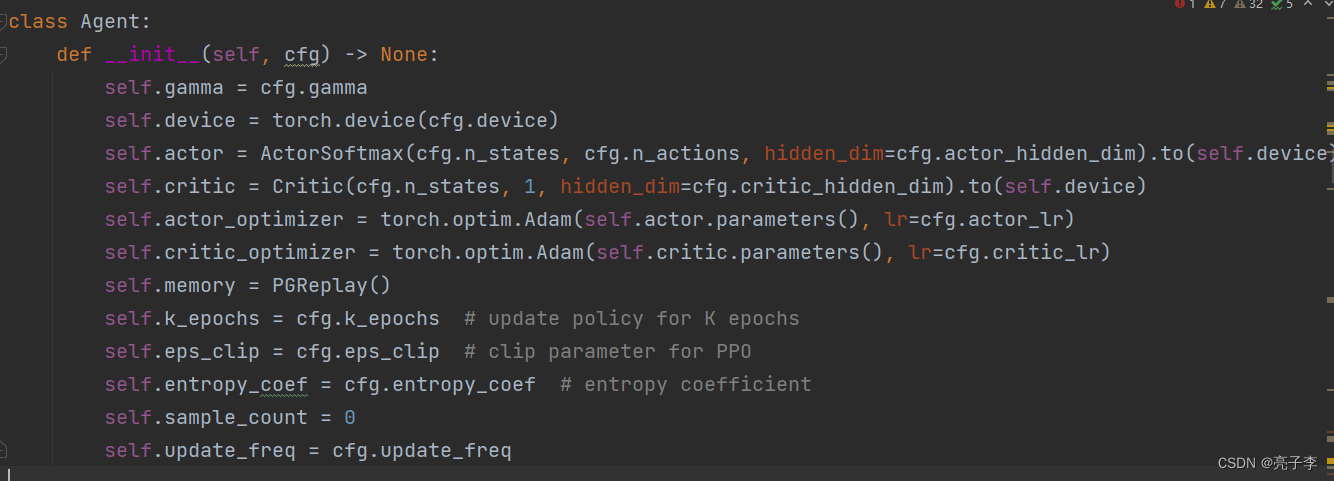
代理中包含了actor critic memory的初始化。 其中, critic我们并没有学到, 好像来估计一个动作的好坏, 比如某步象棋下哪里的得分。 这样可以不用等到结局才知道分数。
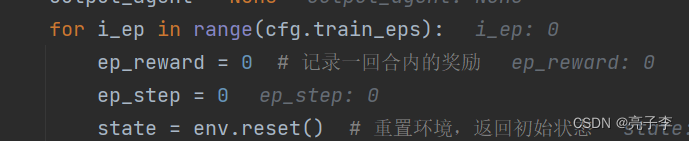
一个episode开始了。 同样的开始, 同样的重置环境。

取一个动作,
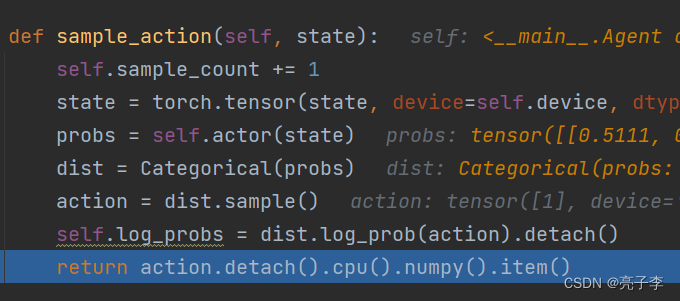
还顺便算出来取这个动作的概率的ln值。

动作带入,得到新状态, 这步动作的奖励, 是否完成, 全部存入memory 包括这步动作的概率对数。

记录步数和这一eposide的奖励。
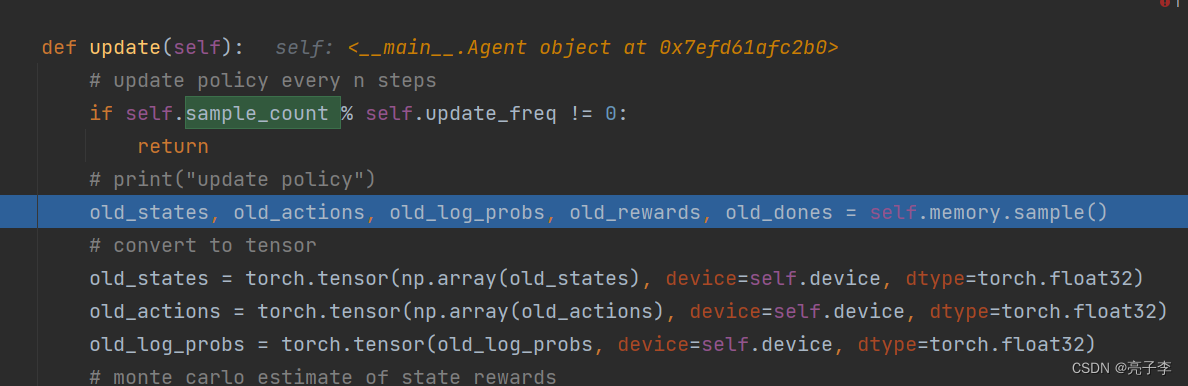
在update中,每取100步就更新一次模型。

取出之前存的值, 转为张量。

倒着来算奖励, 也就是下面的红色圈圈。
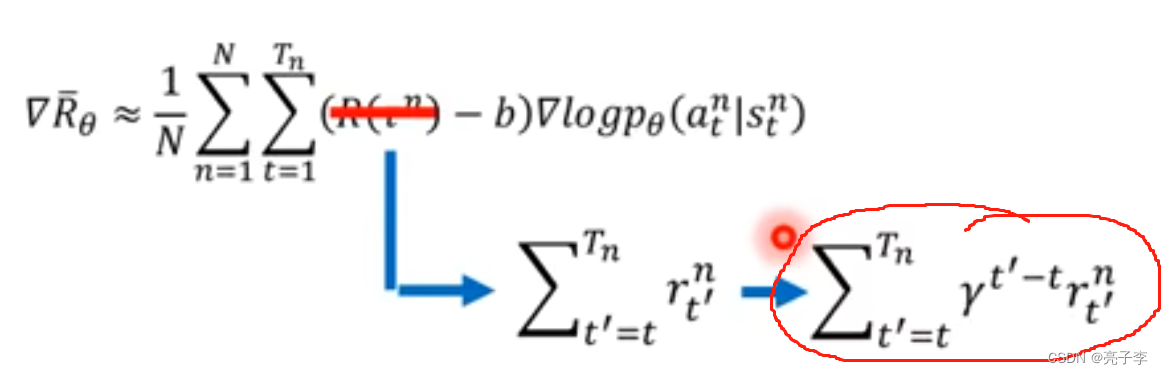

转为张量并且归一化。

这里为当前的状态打分,所谓打分,就是预测这个状态后可能得到的reward。
然后优势等于回报减去critic预测的价值。想了解这个的含义必须知道critic的工作方式。
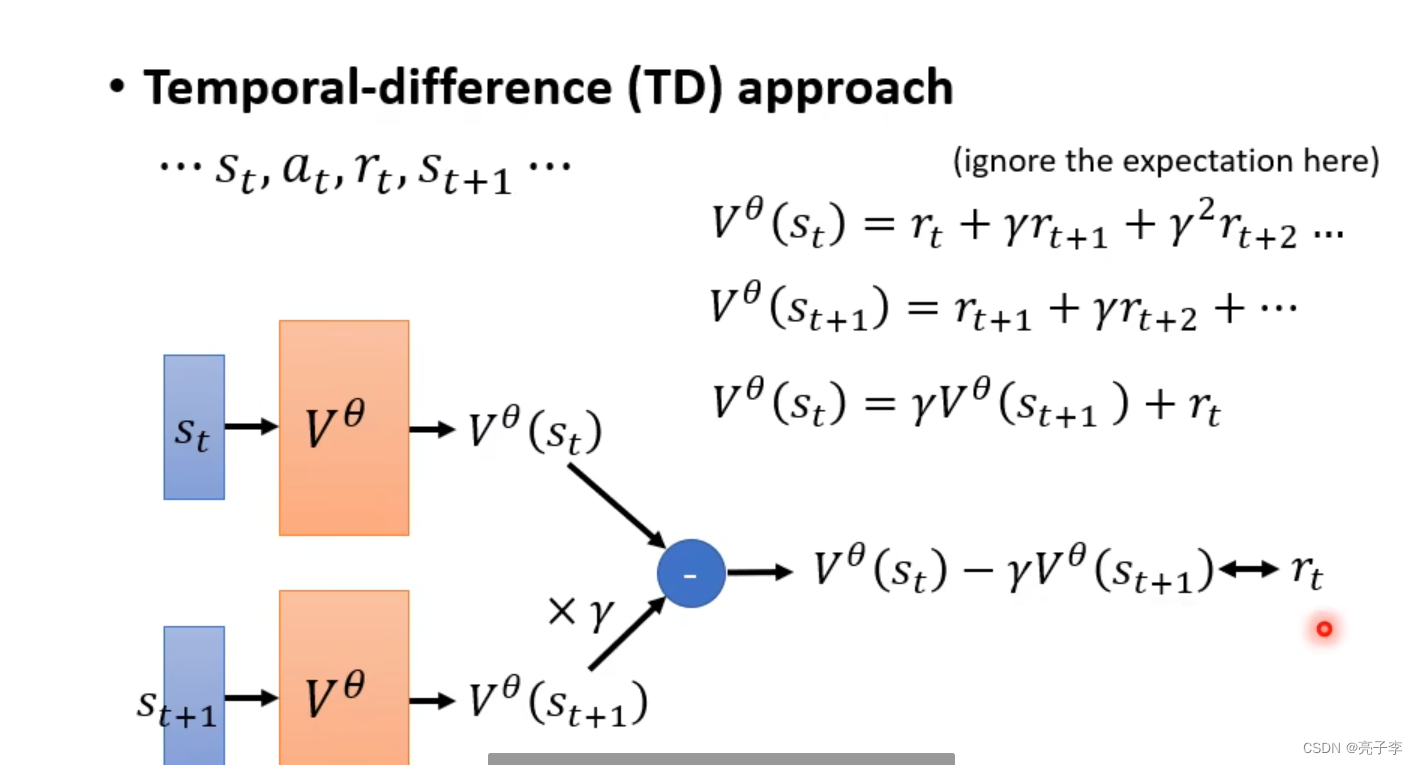
这是一种TD的训练方式。 看上图, 和
代表了相邻两步的预测的价值 。 这里是相当于用解方程的方式来训练网络的。 也就是说,
和
这两步相差的价值,有着上图第三个公式的关系。 当时间因子为1的时候,
当然这是训练时的方法。
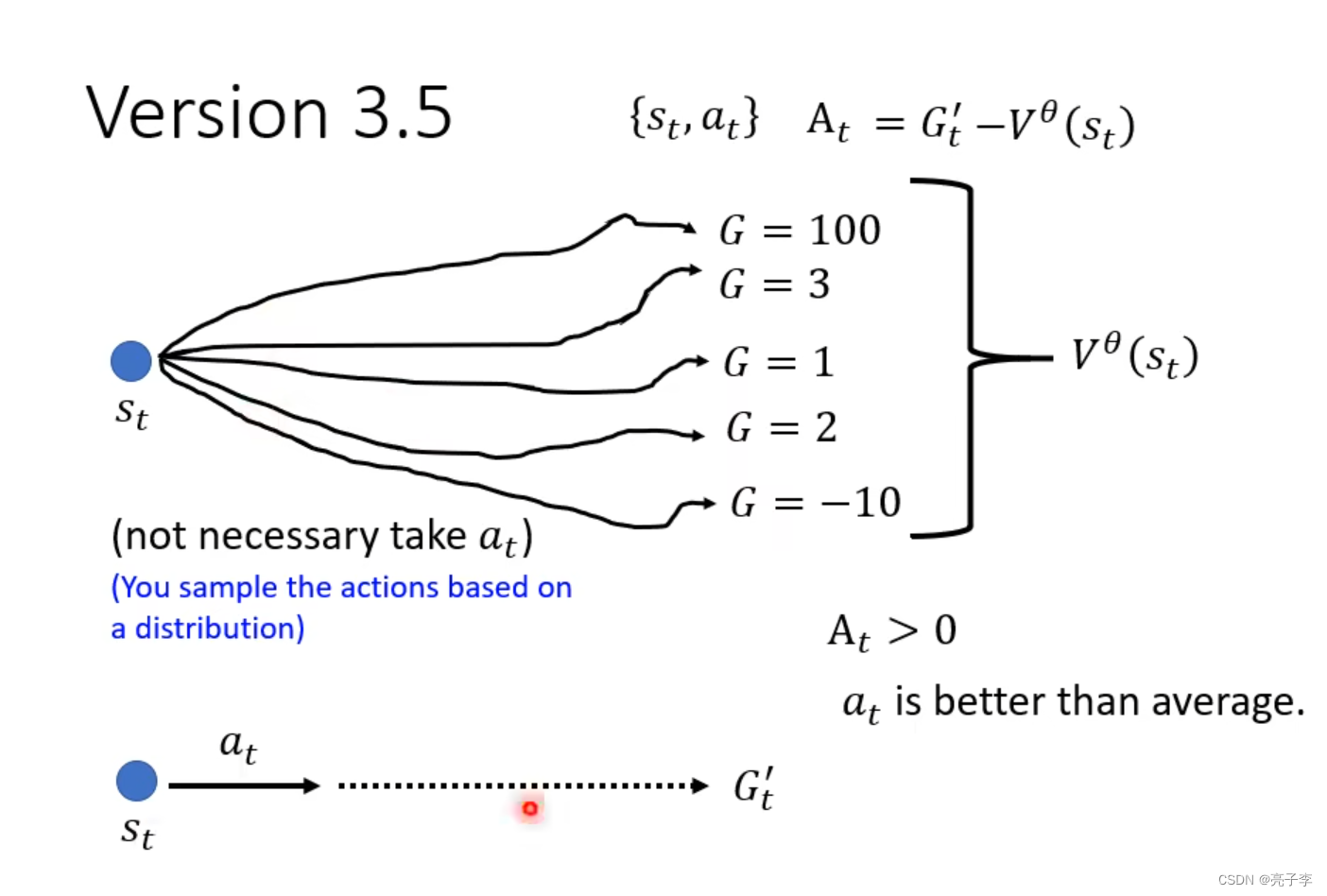
这个进阶的版本是这样的, 我们让优势函数等于当前状态执行动作at得到的奖励减去critic预测的奖励V。 因为critic预测的是一个均值, 因此如果得到的优势函数At大于0, 说明当前动作at是一个好动作,。
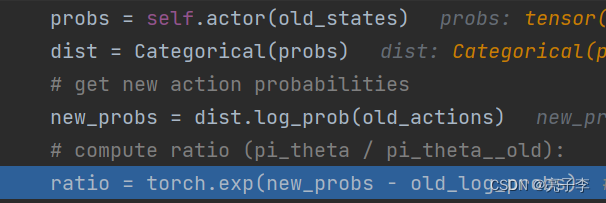

这个和PG是一样的, 取一个动作的概率分布, 作为dist 然后从里面算出当时动作的概率。
值得注意的是这里是又算了一遍么????? 和旧的区别在哪里呢?
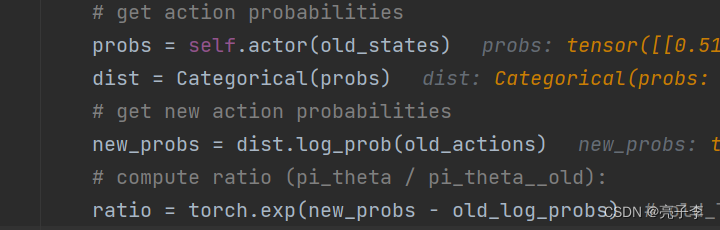
看来这里的新概率 就是, 然后通过指数函数实现和
的除法。 这个old就是
所以我们应该更新的是这里的actor,
但是我很好奇, 这个actor一更新, 不就变了么,那还说是什么off-policy呢 ???

实现loss
也就是PPO2
可以完美的看到各项的对应。


更新critic, 有点像gan了。 就是希望我们的预测价值和真实得到的return越像越好。
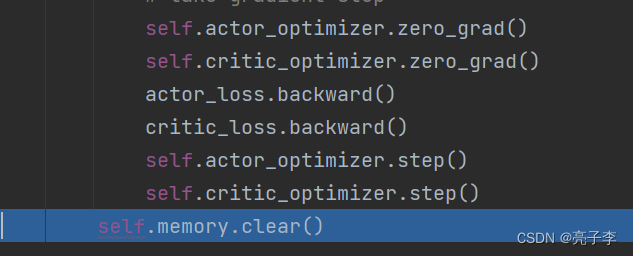
更新完毕, 清空memory。 用新的actor产生动作?
也没看到和GP又多大差别啊喂。
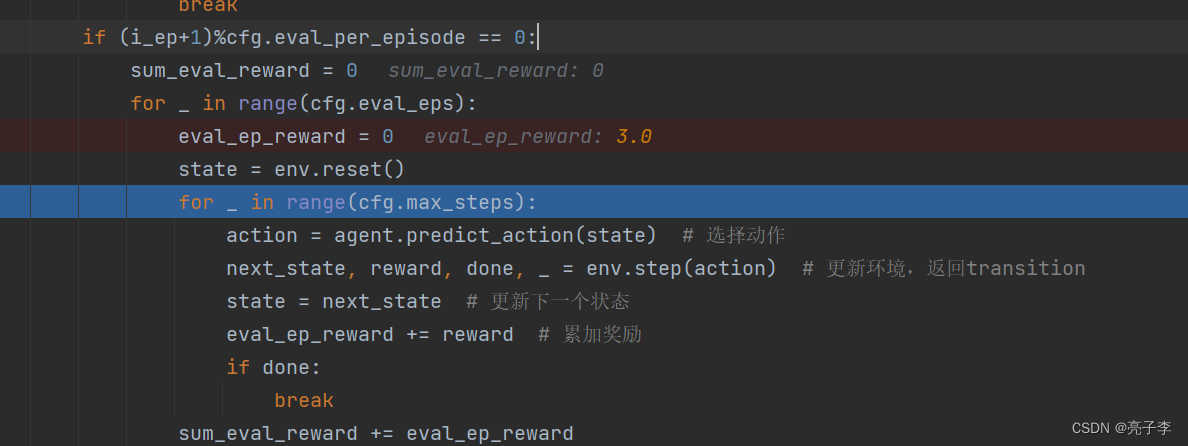
每10轮验证一次。
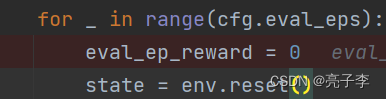
初试化,
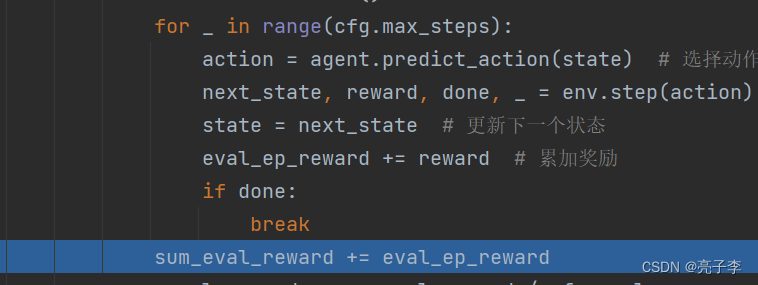
进行一轮, 得到总奖励
总共进行五轮求均值。
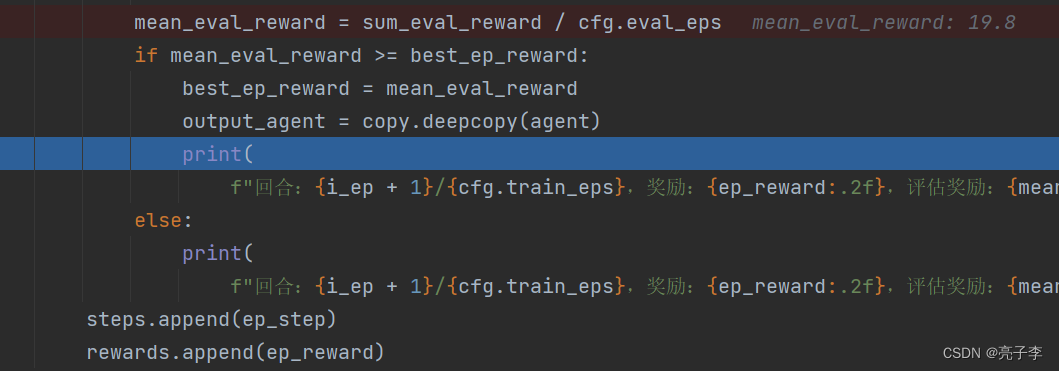
如果比历史最佳值好久保存这个agent
这是第一遍, 我感觉没看很懂, 所以我决定 再看一遍!!!!

















 926
926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









