







贾俊平<统计学>阅读笔记!
参数估计(parameter estimation)和假设检验(hypothesis testing)是统计推断的两个组成部分,它们都是利用样本对总体进行某种推断.但推断的角度不同。
参数估计讨论的是用样本统计量估计总体参数的方法.总体参数产在估计前是未知的。
而在假设检验中,则是先对产的值提出一个假设,然后利用样本信息去检验这个假设是否成立。
参数估计
参数估计是推断统计的重要内容之一,它是在抽样及抽样分布的基础上,根据样本统计量来推断所关心的总体参数.
如果能够掌握总体的全部数据,那么只需要作一些简单的统计描述,就可以得到所关心的总体特征,比如,总体均值、方差、比例,等。
但现实情况比较复杂,有些现象的范围比较广,不可能对总体中的每个单位都进行测定。或者,有些总体的个数很多,不可能也没必要一一测定。这就需要从总体中抽取一部分个体进行调查,进而利用样本提供的信息来推断总体的特征。
参数估计就是用样本统计量去估计总体的参数。比如:
- 用样本均值 x x x直接作为总体均值 μ \mu μ的估计值,
- 用样本比例 p p p直接作为总比例 π \pi π的估计值,
- 用样本方差 s 2 s^2 s2直接作为总体方差 σ 2 \sigma^2 σ2的估计值,等等。
如果,将总体参数笼统的用一个符号 θ \theta θ来表示,而用于估计总体参数的统计量用统计量 θ \theta θ
估计量
在参数估计中,用来估计总体参数的统计量称为估计量,用符号 θ − \theta^- θ−表示。样本均值,样本比例、样本方差,等都可以是一个估计量。
样本估计量是样本的一个函数.(这句话一定要理解!!)
以样本平均数为例,它是总体平均数的一个估计量,如果按照相同的样本容量,相同的抽样方式,反复地抽取样本,每次可以计算一个平均数,所有可能样本的平均数所形成的分布,就是样本平均数的抽样分布。
估计值
而,根据一个具体的样本计算出来的估计量的数值,称为估计值。
参数估计的方法有两种:点估计和区间估计
1 点估计
点估计就是用样本统计量 θ − \theta^- θ−的某个取值,直接作为总体参数 θ \theta θ的估计值。
比如,假定要估计一个班学生考试成绩的平均分,根据抽出的一个随机样本计算的平均分数为80分,用80分作为全班平均考试分数的一个估计值,这就是点估计。
再比如,若要估计一批产品的合格率,根据抽样结果,合格率为96%,将96%直接作为这批产品合格率的估计值,这也是一个点估计。
点估计的问题1
虽然,在重复抽样条件下,点估计的均值可望等于总体均值。 比 如 , E ( x − ) = μ 比如,E(x^-)=\mu 比如,E(x−)=μ
但,由于样本是随机的,抽出一个具体的样本得到的估计值很可能不同于总体均值。
所以,在用点估计值代表总体参数值的同时,还必须给出点估计值的可靠性,也就是说,必须能说出点估计值与总体参数的真实值的接近程度。
但,一个点估计值的可靠性是由它的抽样标准误差来衡量的,这表明一个具体的点估计值无法给出估计的可靠性的度量,因此,就不能完全依赖于一个点估计值,而是围绕点估计值构造总体参数的一个区间。这就是区间估计。
2 区间估计
在点估计的基础上,给出总体参数估计的一个区间范围,该区间由样本统计量加减估计误差而得到。
抽样误差:
由抽样的随机性引起的样本结果与总体真值之间的误差
标准误差:
衡量抽样误差大小的尺度,是样本统计量的标准差,反映用样本统计量去估计总体参数时,可能出现的平均“差错”
标准差VS标准误差:
标准差:反映样本中的元素对样本均值的离散程度,衡量个体间变异大小
标准误差:反映样本均值对总体均值的变异程度,从而衡量抽样误差的大小
随着样本量n的增大,标准差趋向某个稳定值,即样本标准差s越接近总体标准差σ,而标准误则随着样本量n的增大逐渐减小,即样本均值x越接近总体均值μ
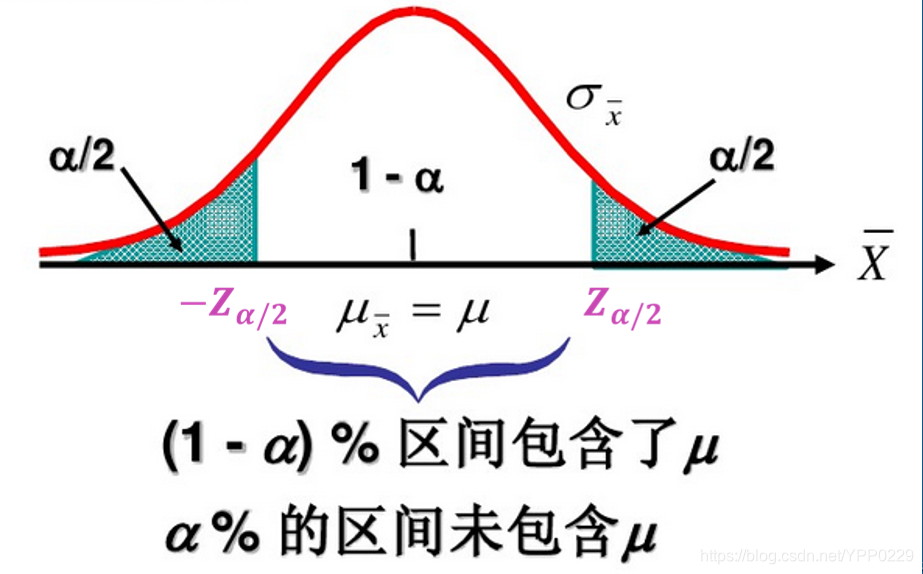
置信区间
在区间估计中,由样本统计量所构造的总体参数的估计区间,称为置信区间。
其中,区间的最小值称为置信下限,最大值称为置信上限。
由于统计学家在某种程度上,确信这个区间会包含真正的总体参数,所以给它取名为置信区间。
置信水平
将构造置信区间的步骤重复很多次,置信区间包含总体参数真值的次数所占的比例称为置信水平。表示为 ( 1 − α ∗ 100 ) (1-\alpha *100) (1−α∗100), α \alpha α是总体参数未在区间内的比例。
常用的置信水平值有 99%, 95%, 90%,相应的 α \alpha α为0.01,0.05,0.10。
评价估计量的标准
参数估计,是用样本估计量 θ − \theta^- θ−作为总体参数 θ \theta θ的估计。
实际上,用于估计 θ \theta θ的估计量有很多,比如,可以用样本均值作为总体均值的估计量,也可以用样本中位数作为总体均值的估计量,等等。
那么,究竟用样本的哪种估计量作为总体参数的估计呢?
自然要用估计效果最好的那种估计量。
什么样的估计量才算是一个好的估计量呢?
这就需要由一定的评价标准,统计学家给出了评价估计量的一些标准,主要有以下几个:
1 无偏性
估计量抽样分布的数学期望等于被估计的总体参数。
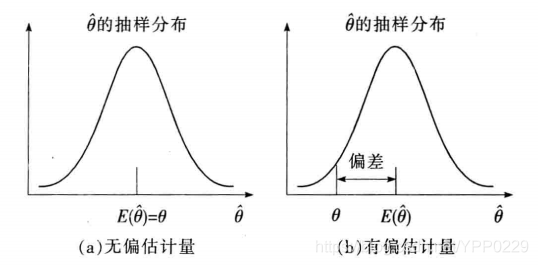
- 无偏性说明,不同的样本得到的 θ − \theta^- θ−不同,可能大于 θ \theta θ,也可能小于 θ \theta θ,多次抽样时, θ − \theta^- θ−的平均值与真实值 θ \theta θ一致。
- 一个好的估计量就某一个具体的估计值而言,可能不等于总体参数值,但平均地看有向估计的参数集中的趋势。
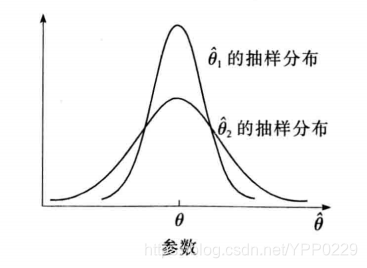
2 有效性
一个无偏的估计量并不就意味着它非常接近被估计的参数,它还必须与总体参数的离散程度比较小。
有效性,是指对同一总体参数的两个无偏估计量,有更小标准差的估计量更有效。
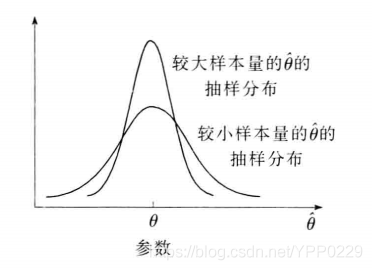
3 一致性
随着样本量的增大,估计量的值越来越接近被估计的总体参数。换言之,一个大样本给出的估计量要比一个小样本给出的估计量更接近总体的参数。















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









