







大语言模型技术发展与演进
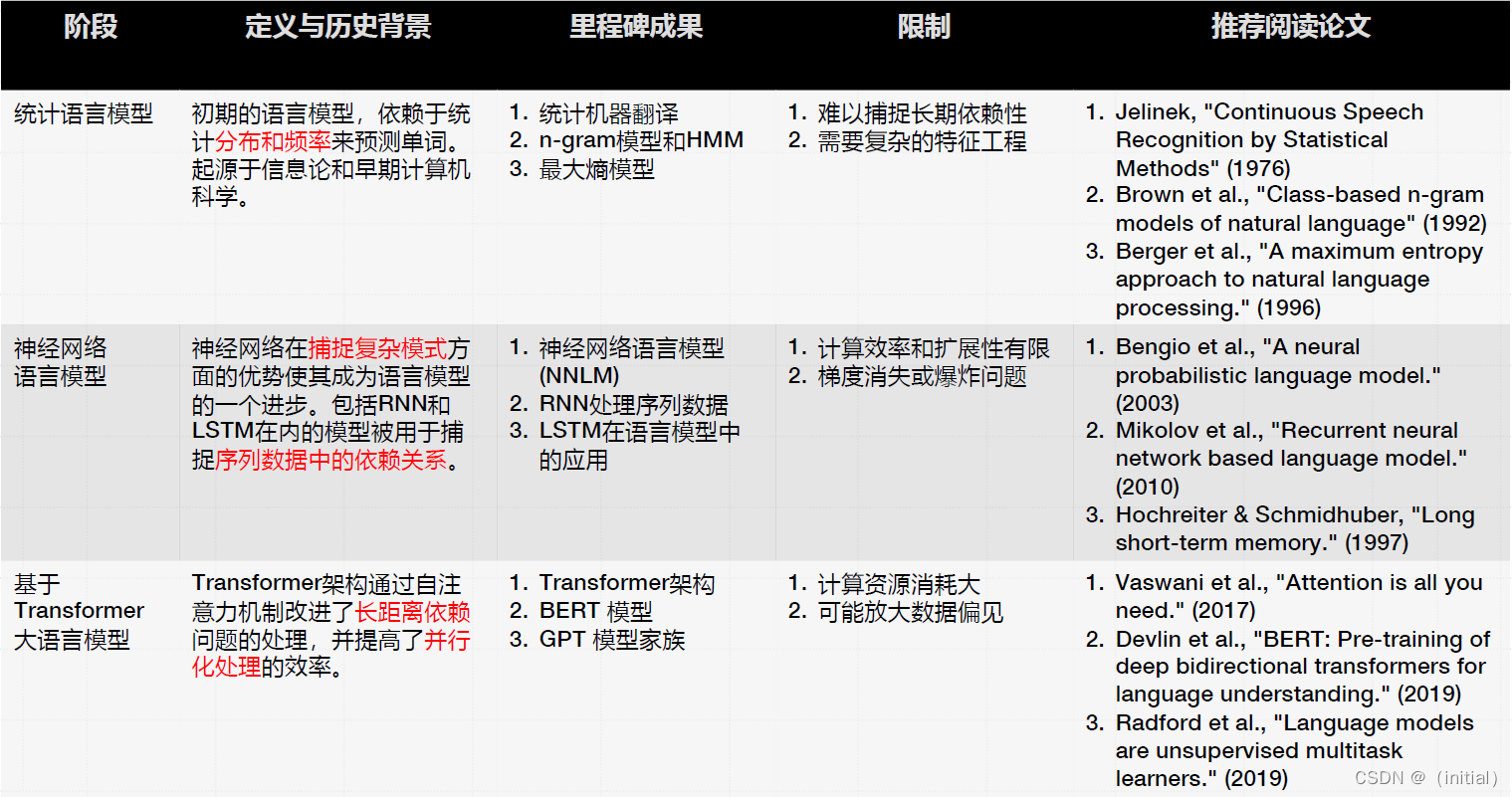
统计语言模型
统计语言模型是什么?

N-gram 模型 与 马尔科夫假设


神经网络语言模型
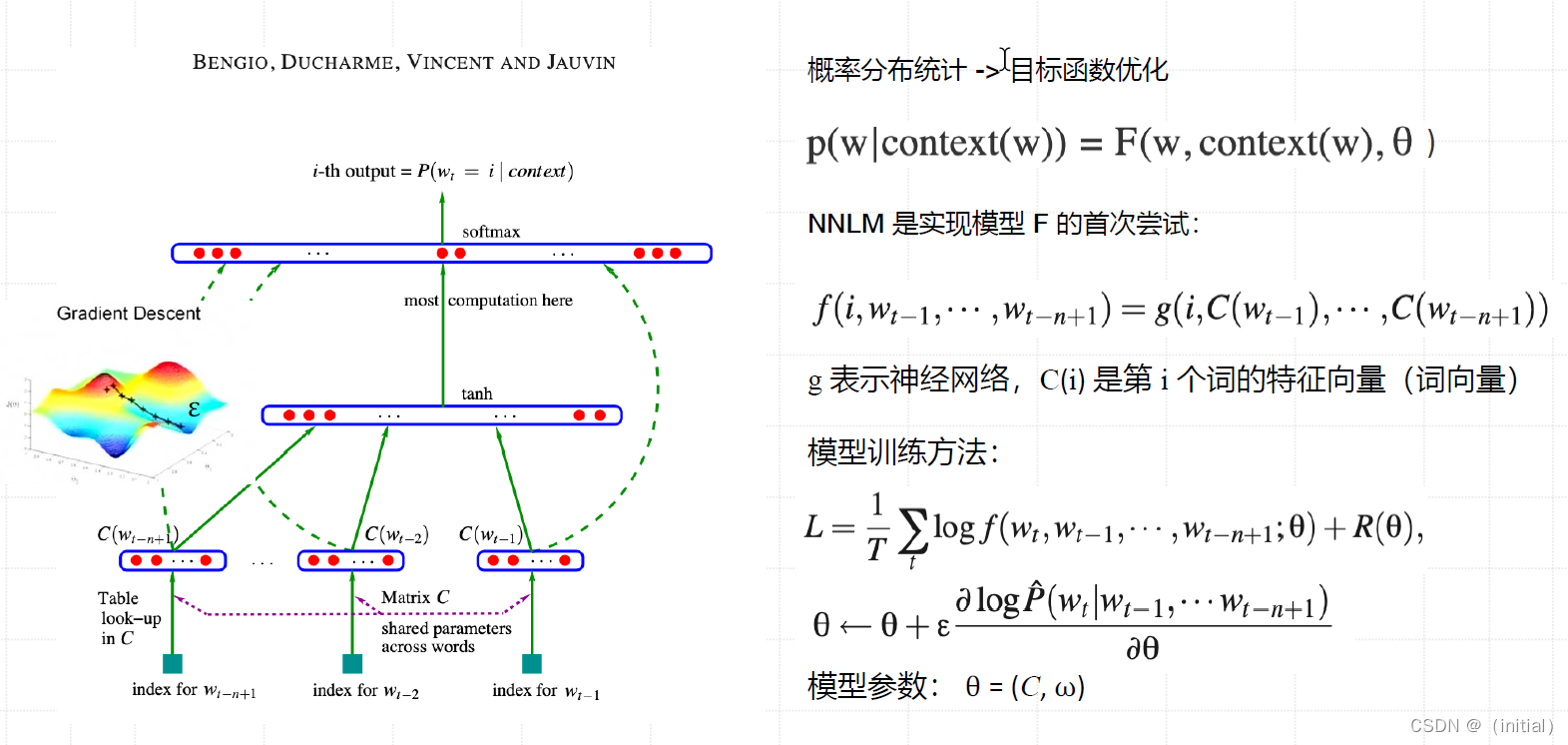
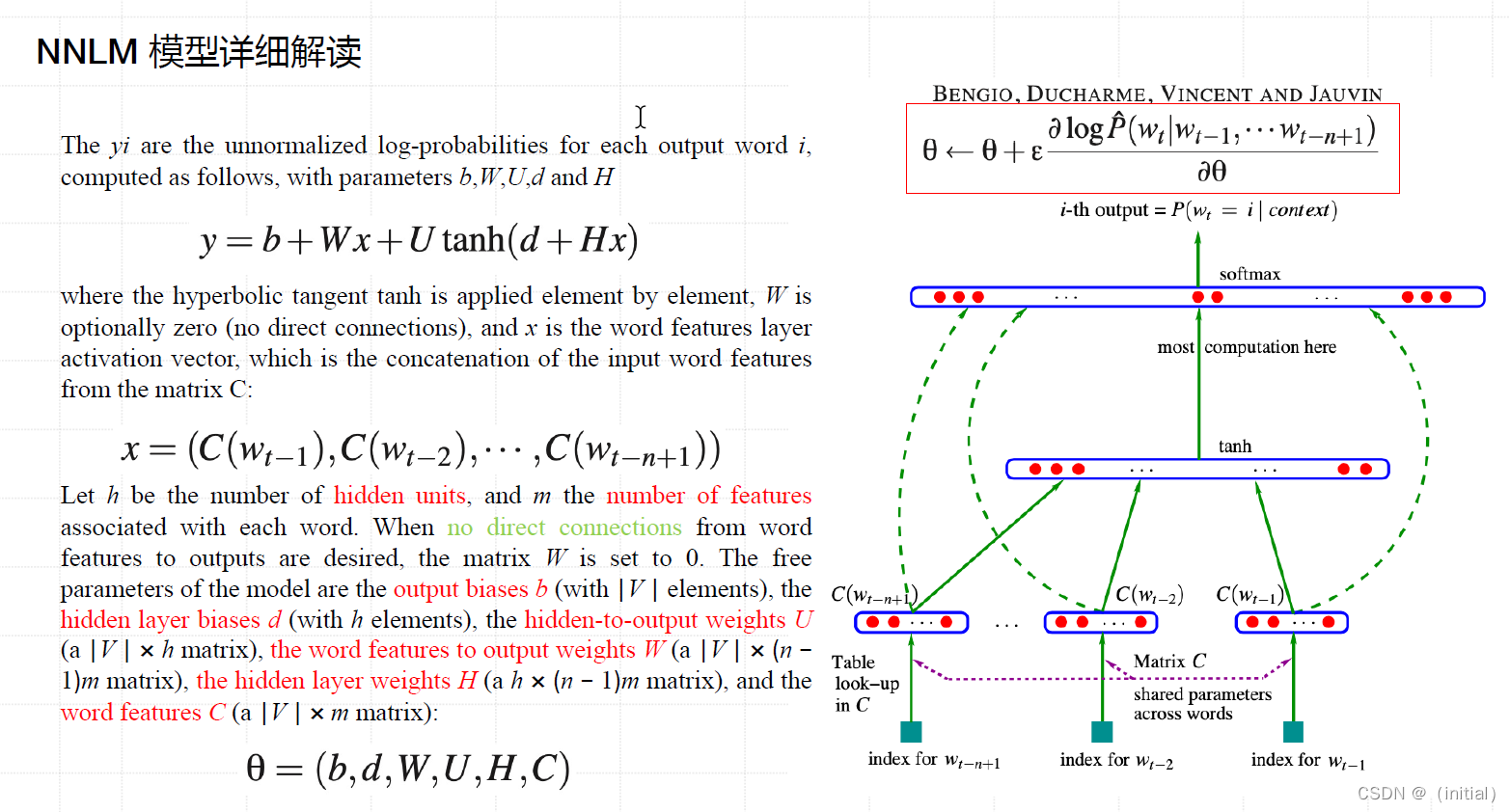
开山之作 Neural Network Language Model (NNLM)
One-hot Representation

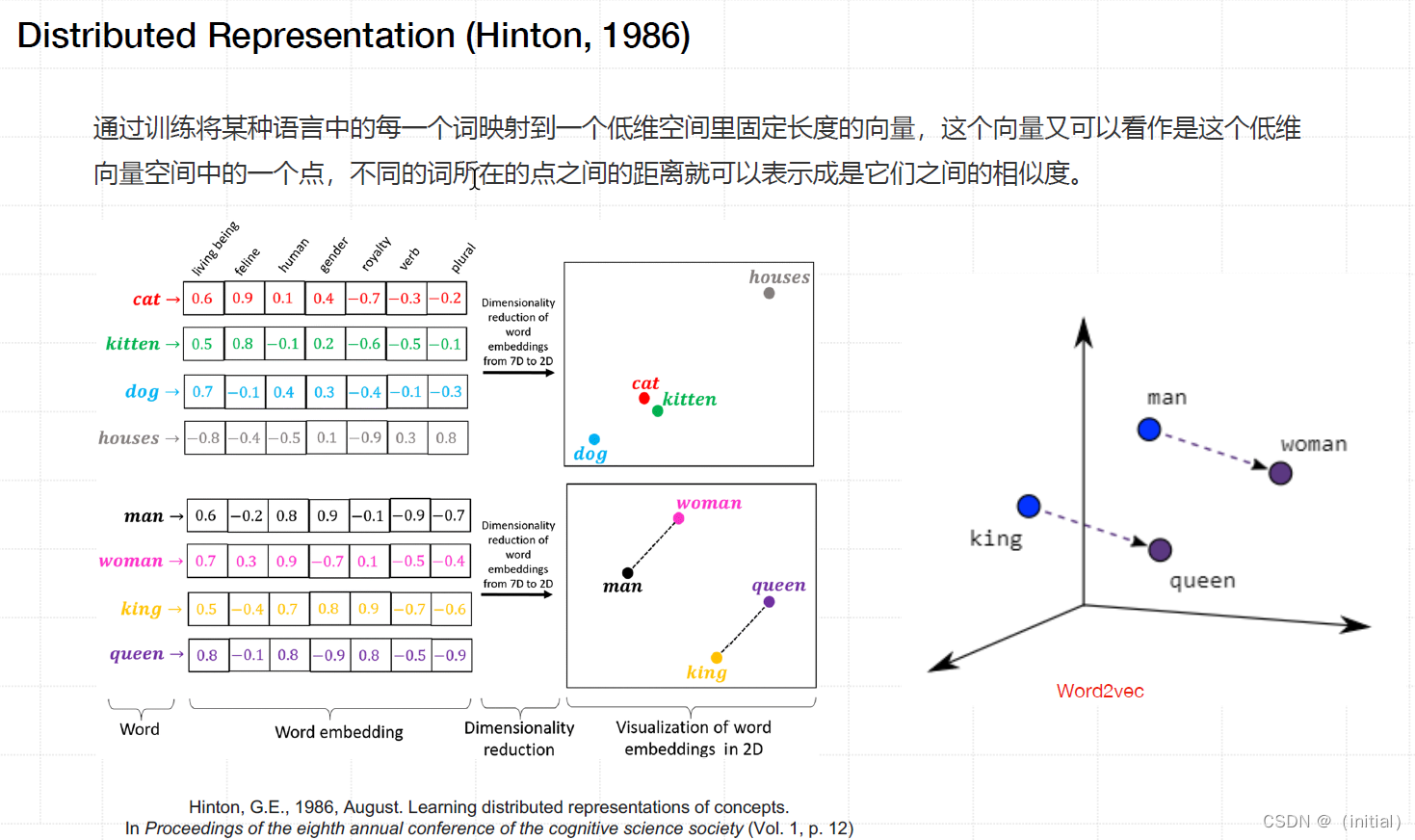
RNN 网络(Mikolov, 2010)
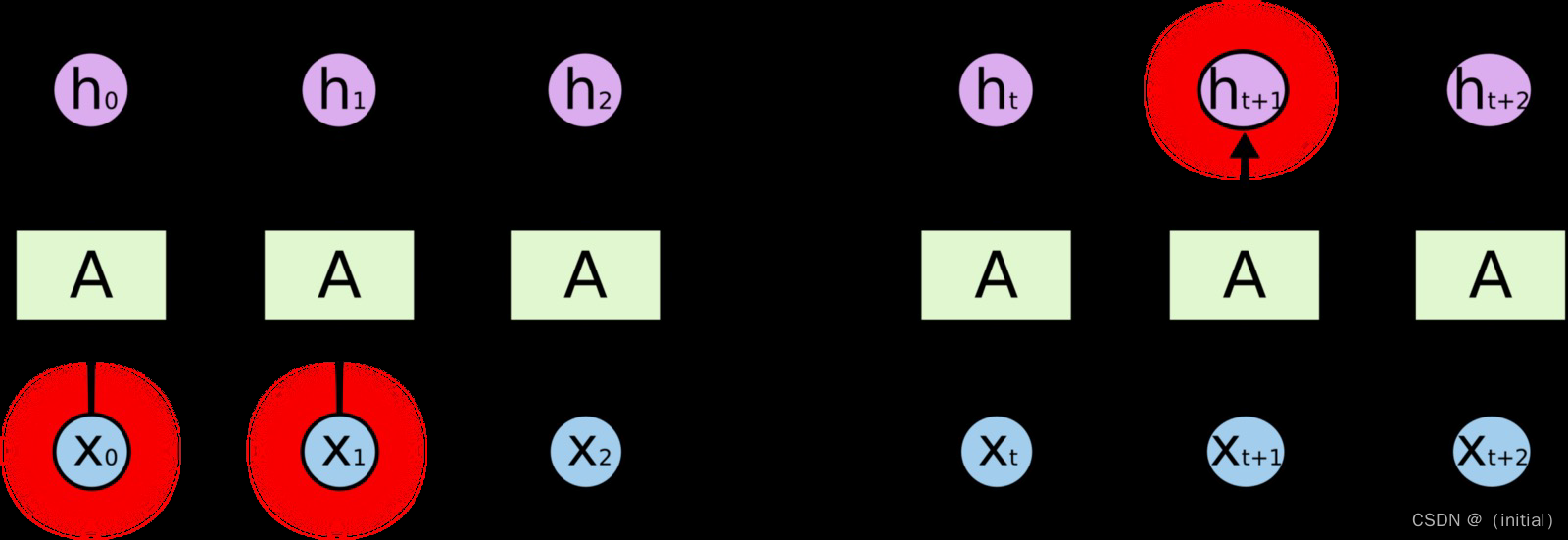
NNLM 普遍采用 RNN / LSTM 作为神经网络
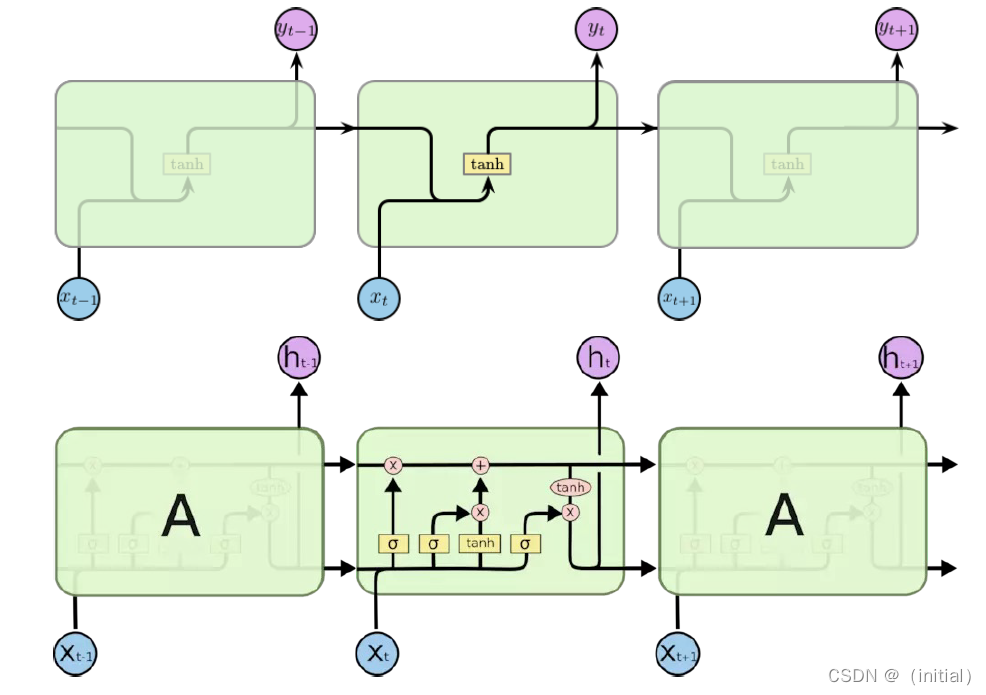
两个问题:
- 长距离依赖(梯度消失)
- 计算效率(RNN 难以并行)
基于Transformer的大语言模型
注意力机制
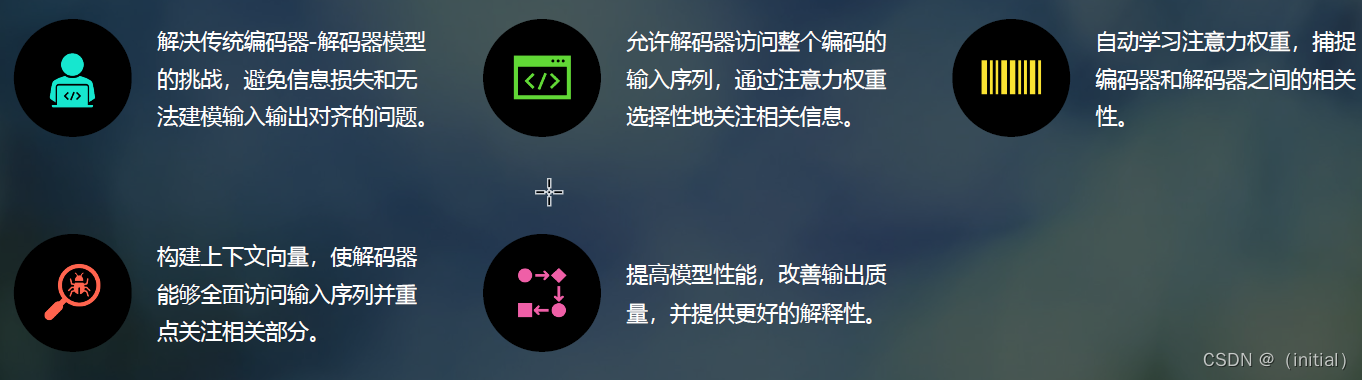
解决RNNs 带来的问题
Encoder decoder architecture
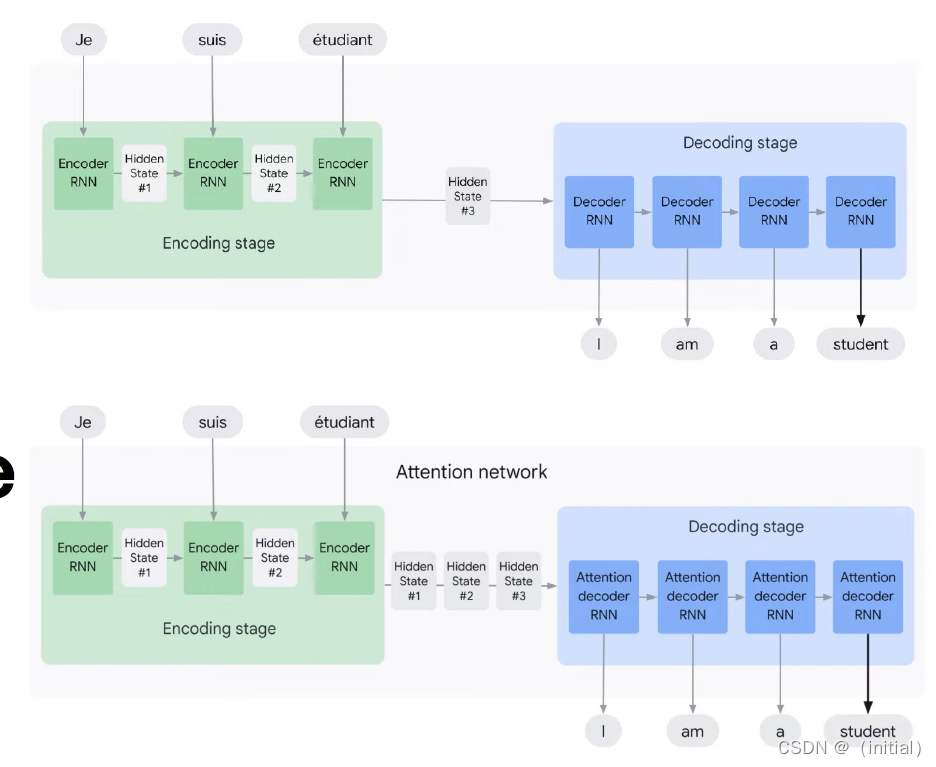
Encoder-decoder Architecture with Attention Model
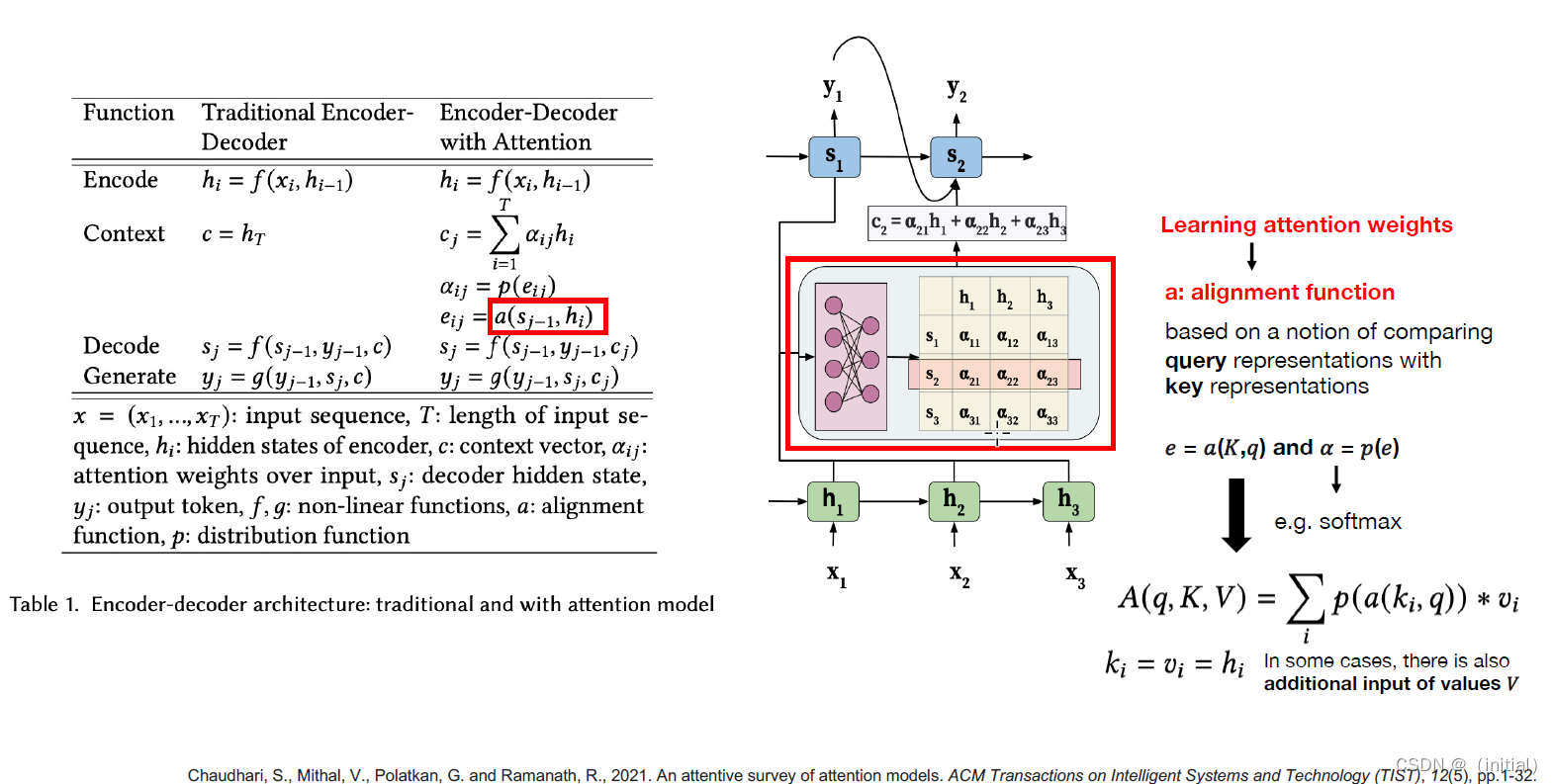
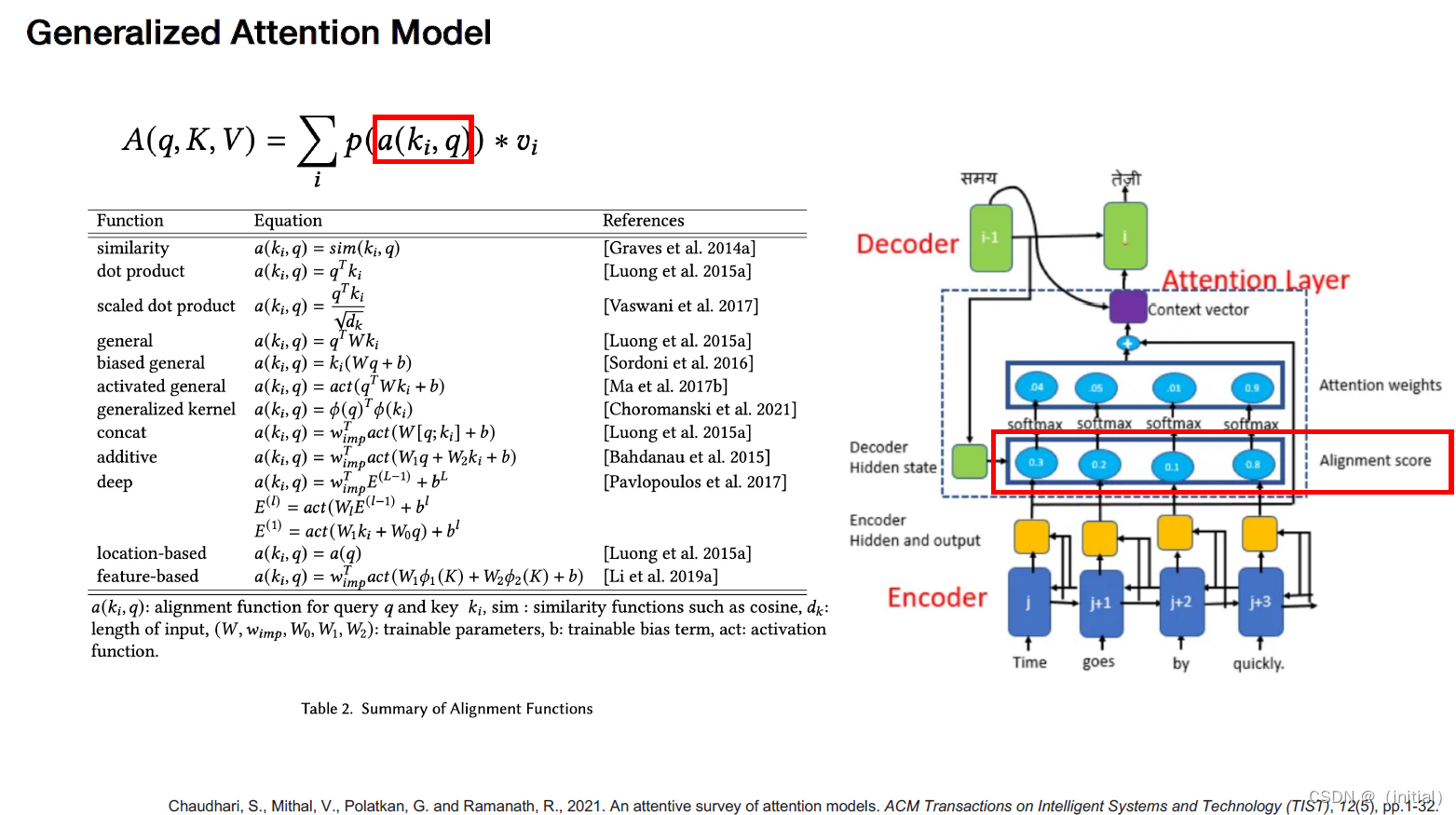
注意力机制的特点和优势
- 注意力机制有助于克服循环神经网络(RNNs)的一些挑战,例如输
入序列长度增加时性能下降和顺序处理输入导致的计算效率低下。 - 在自然语言处理(NLP)、计算机视觉(Computer Vision)、跨模
态任务和推荐系统等多个领域中,注意力机制已成为多项任务中的最
先进模型,取得了显著的性能提升。 - 注意力机制不仅可以提高主要任务的性能,还具有其他优势。它们被
广泛用于提高神经网络的可解释性,帮助解释模型的决策过程,使得
原本被认为是黑盒模型的神经网络变得更易解释。这对于人们对机器
学习模型的公平性、可追溯性和透明度的关注具有重要意义。

Transformer
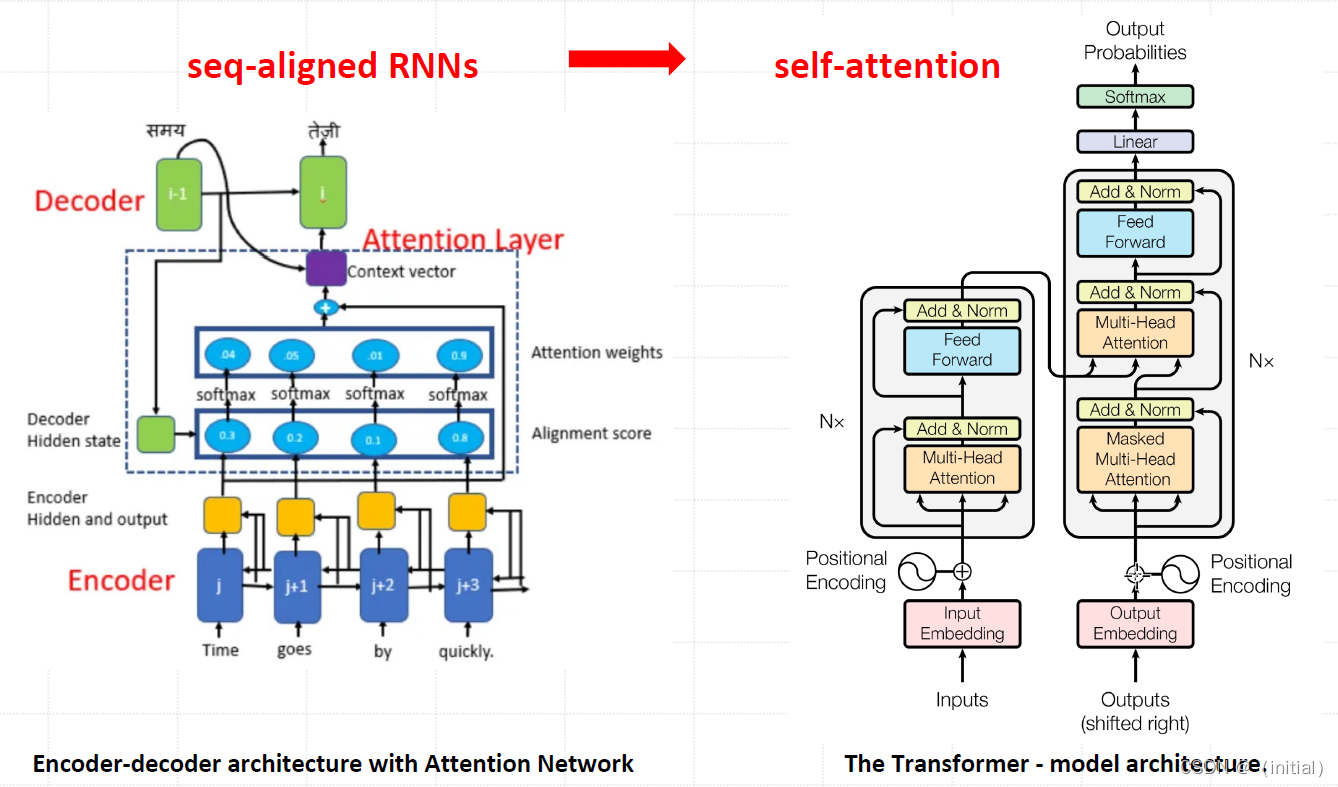
self-attention
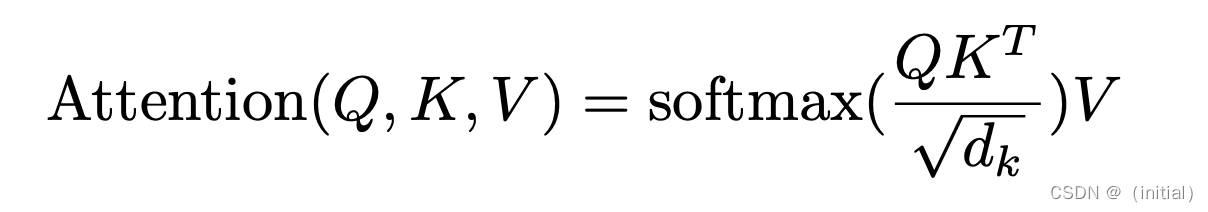
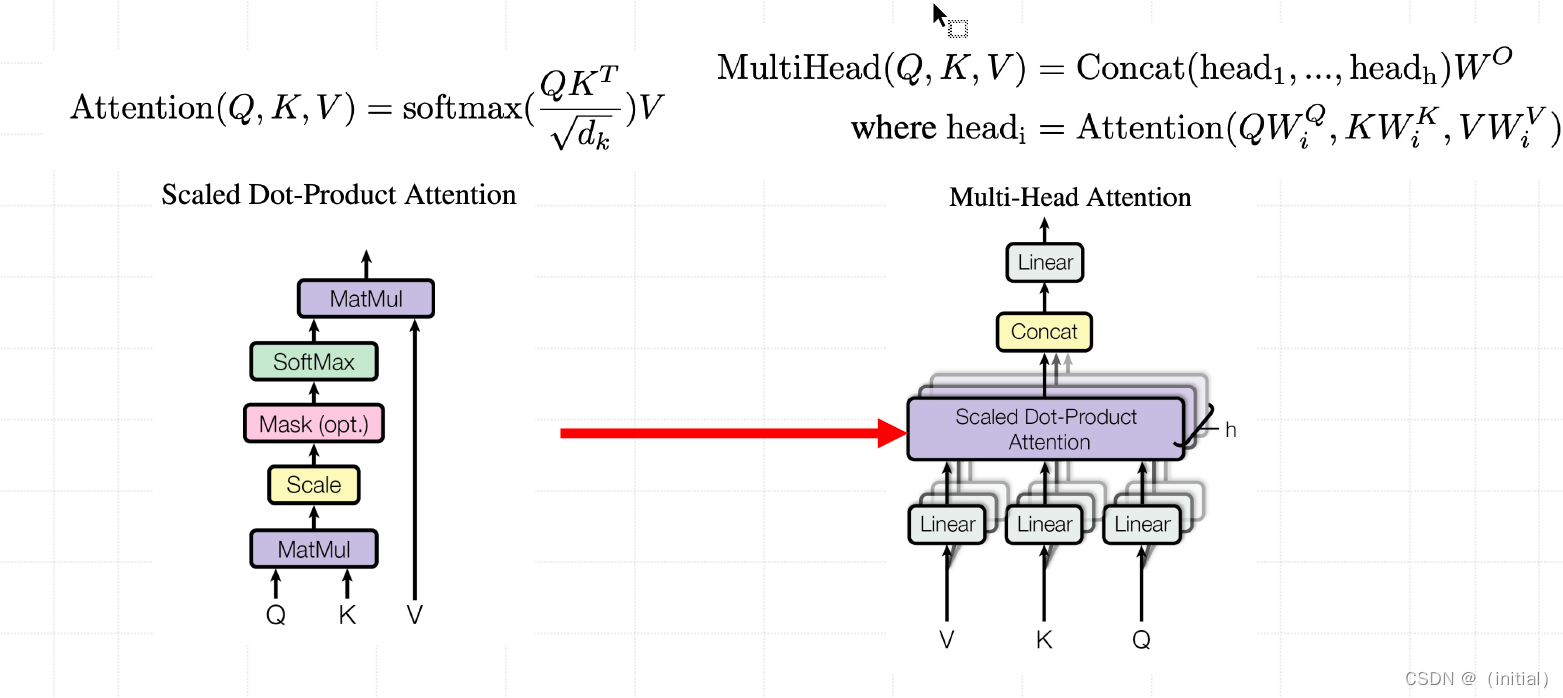
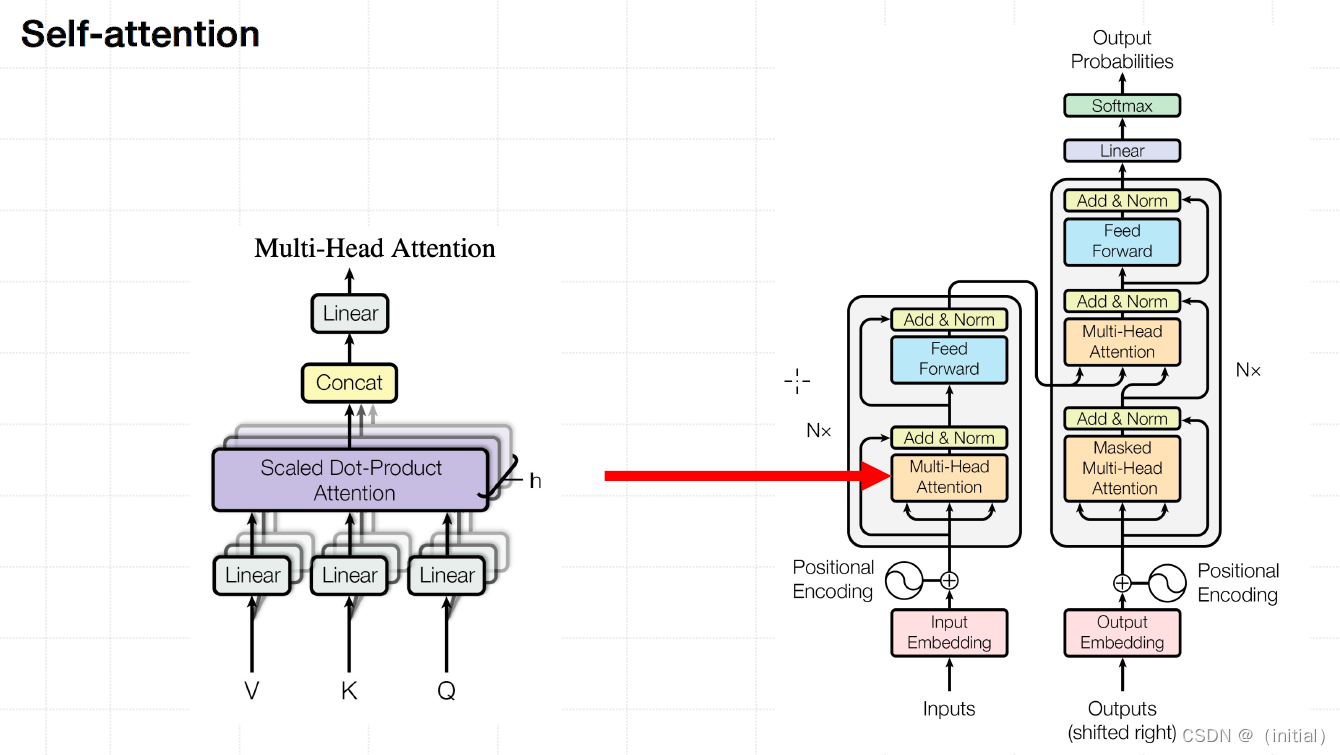
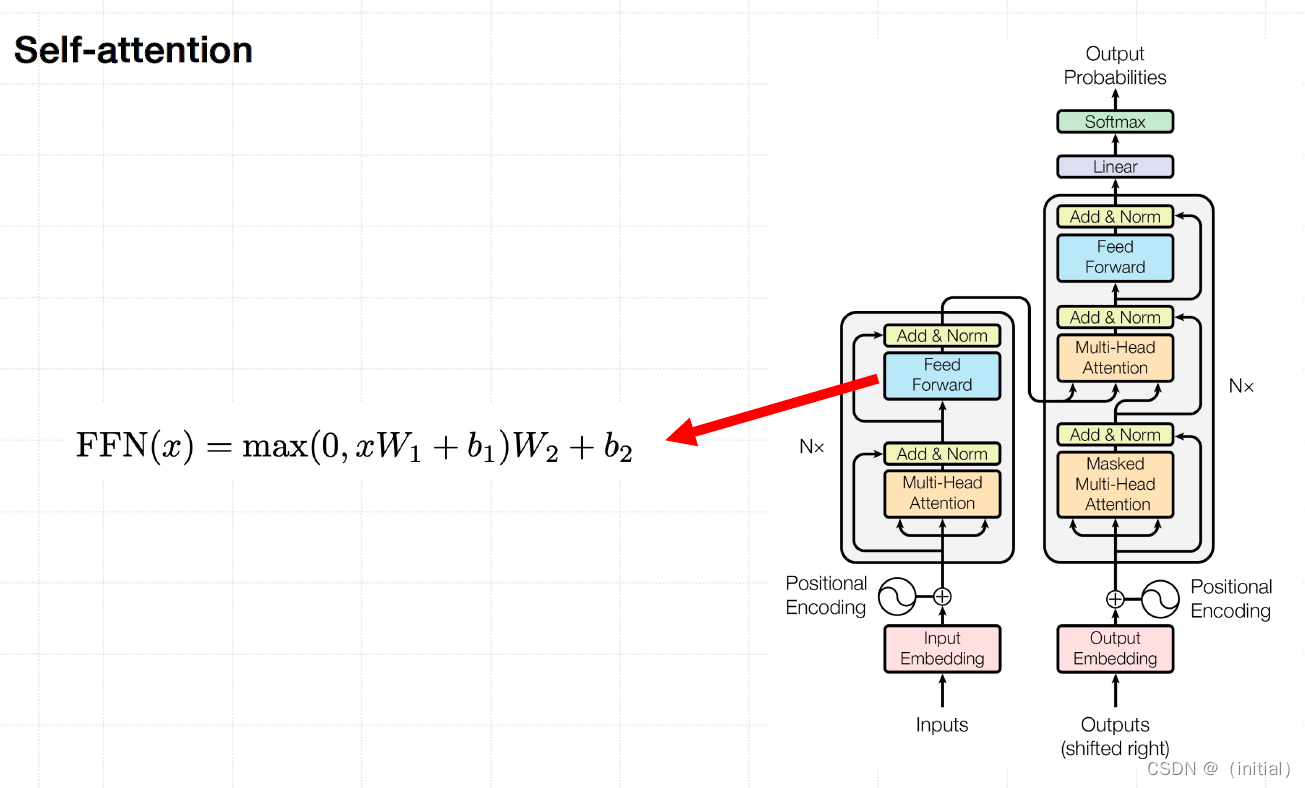
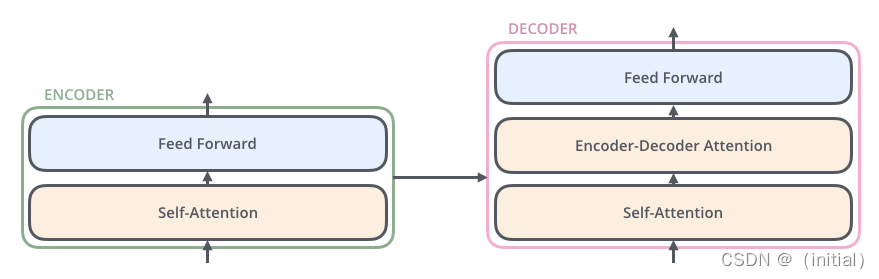
Transformer : Encoder - Decoder
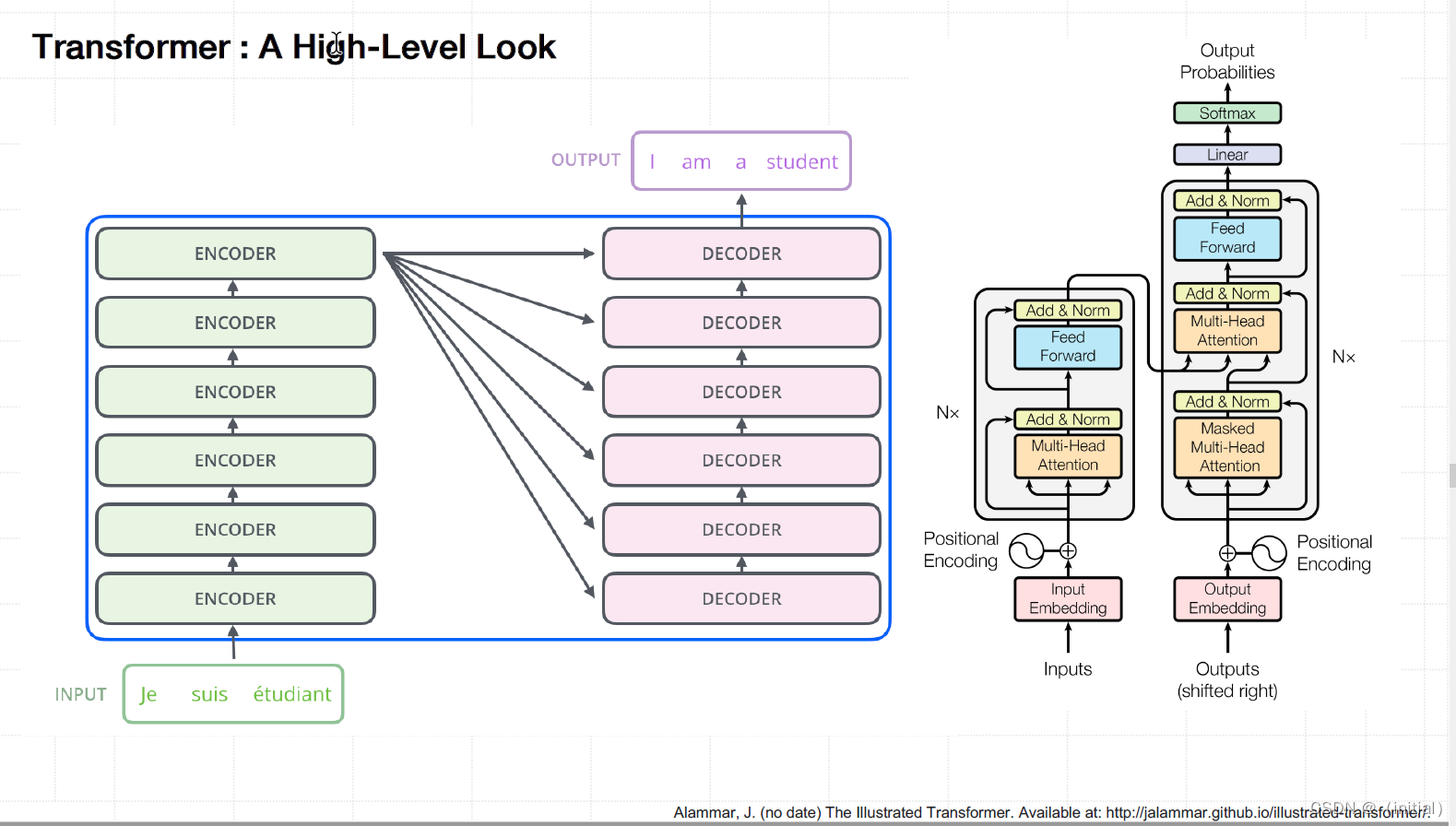
预训练 Transformer 时代

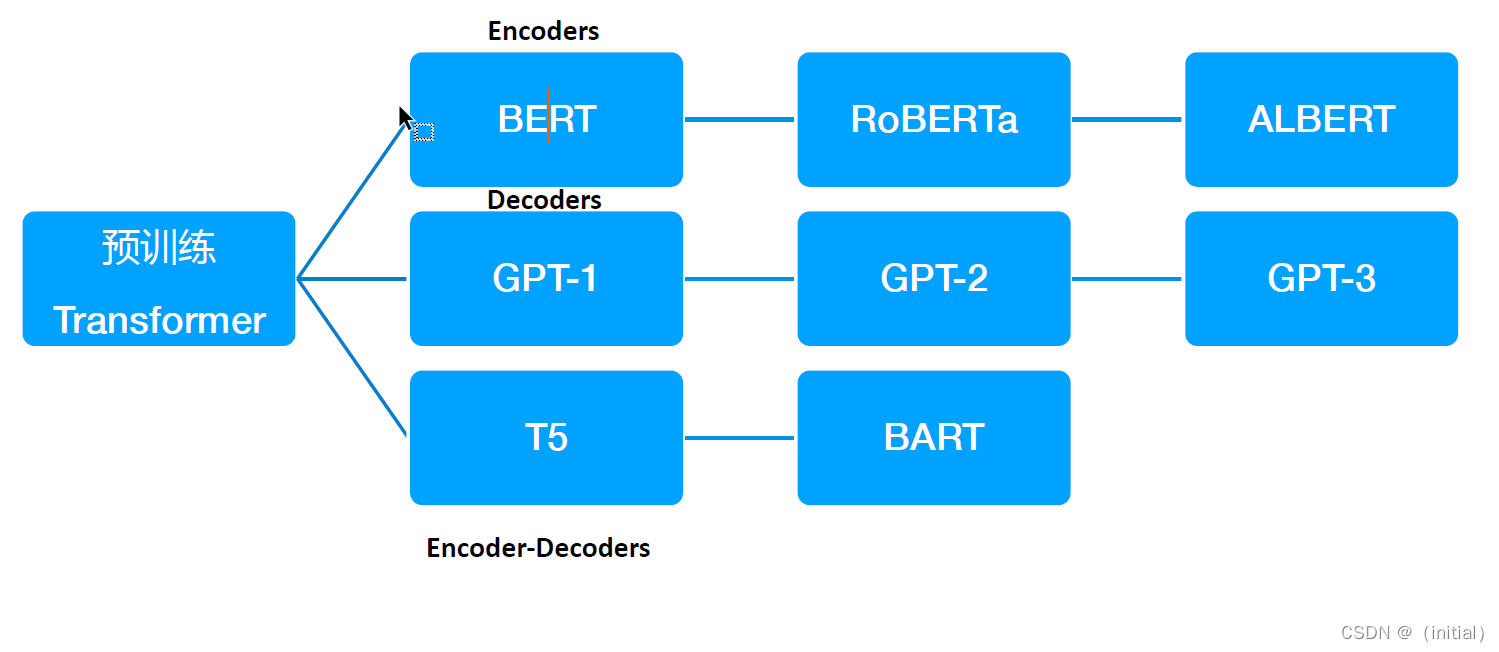
NLP基准测试介绍
-
MNLI-m (Multi-Genre Natural Language Inference, matched):这是一个自然语言推理任务,其中包括了五个不同类型(类型指的是来源,例如口语、小说等)的文本,并且这些文本在训练和测试集上都是匹配的。任务的目标是根据一个给出的前提判断一个假设是蕴含、矛盾,还是无关。
-
MNLI-mm (Multi-Genre Natural Language Inference, mismatched):这也是一个自然语言推理任务,但与
MNLI-m不同的是,训练集和测试集的文本类型是不匹配的。这需要模型具有更好的泛化能力。
-
SNLI (Stanford Natural Language Inference):这是一个由斯坦福大学创建的自然语言推理任务,包含了大约55万个人类注释的英文句子对。任务的目标同样是根据一个给出的前提判断一个假设是蕴含、矛盾,还是无关。
-
SciTail:这是一个开放的自然语言推理任务,所有的问题和答案都来自科学领域的教材。任务的目标是根据一个给出的前提判断一个假设是蕴含还是矛盾。
-
QNLI (Question Natural Language Inference):这是一个基于问答的自然语言推理任务,数据来源于SQuAD数据集。任务的目标是根据给出的上下文判断一个假设(问题)是否被蕴含。
-
RTE (Recognizing Textual Entailment):这是一个文本蕴含识别任务,数据来源于多个版本的PASCAL RTE挑战赛。任务的目标是根据一个给出的前提判断一个假设是蕴含还是矛盾。
以上基准测试都是关于自然语言推理的任务,目的是检验模型是否能够理解句子之间的逻辑关系,例如蕴含、矛盾或无关。这些任务在许多自然语言处理任务中都是非常重要的,例如问答、文本摘要、机器翻译等。
NLP基准测试介绍


以前方法的问题
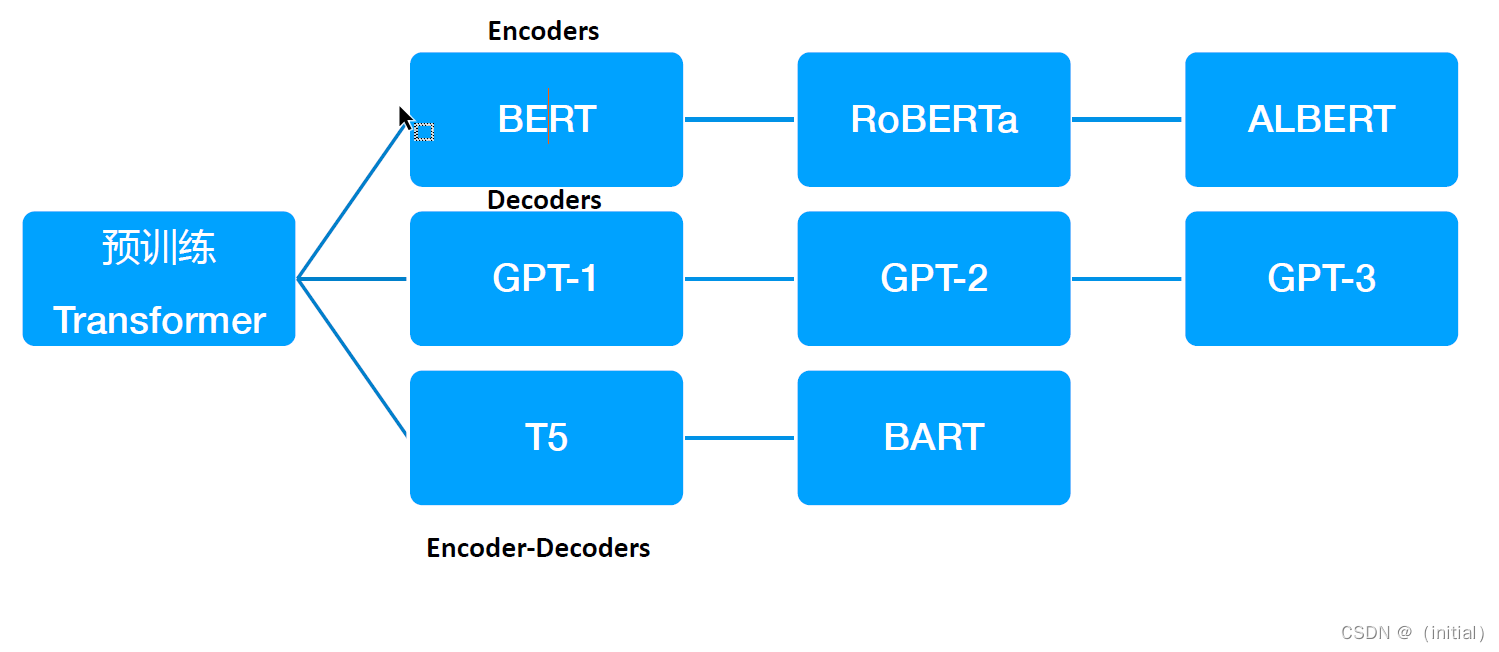
• 问题:语言模型仅使用左上下文或右上下文,但语言理解是双向的。
为什么 LM 是单向的?
• 原因1:需要方向性来生成格式良好的概率分布。(我们不关心这个)
• 原因2:单词可以在双向编码器中“see themselves”。
单向和双向模型
单向上下文增量构建表示;双向上下文单词可以“see themselves”
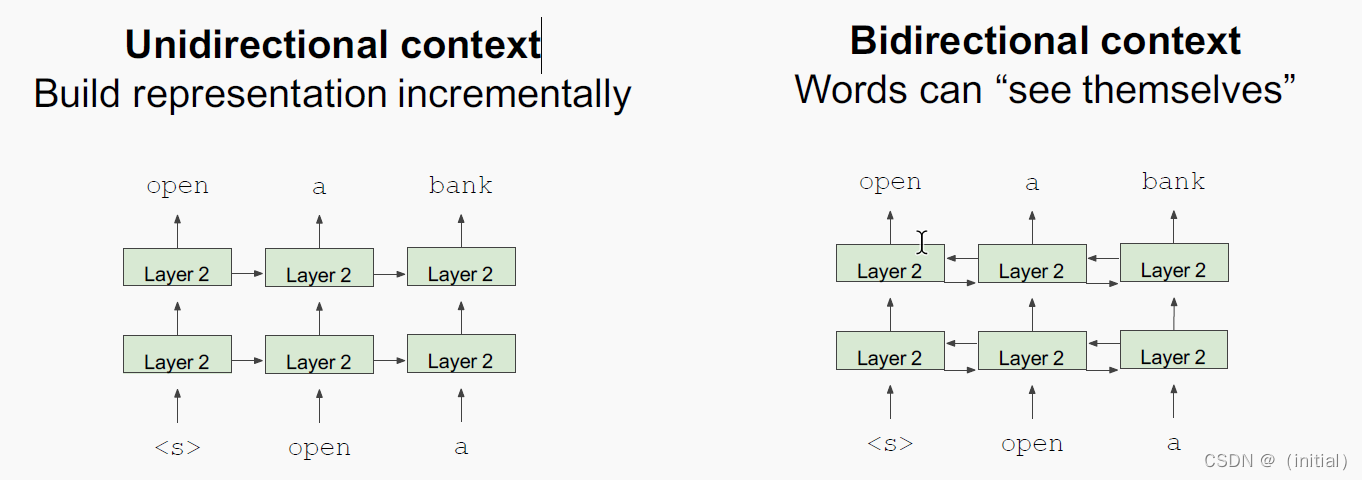
Masked LM


Next Sentence Prediction

| 基准测试 | 描述 |
|---|---|
| GLUE Benchmark | 一个包含九个自然语言理解任务的基准测试,例如:文本蕴含识别、语义角色标注、情感分析等。BERT在多项任务中刷新了记录。 |
| SQuAD v1.1 | 斯坦福问答数据集(Stanford Question Answering Dataset),是一个阅读理解型问答任务的基准测试。BERT在此任务中超过了人类的表现。 |
| SQuAD v2.0 | 与v1.1版本类似,但增加了一部分问题并没有答案的情况,这对模型的理解能力提出了更高的要求。BERT也在此任务中取得了最优成绩。 |
| SWAG | 一个多选问答任务,需要根据前文预测下一句话的内容。BERT在这个任务中也刷新了最好的成绩。 |
| CoNLL-2003 NER | 命名实体识别(Named Entity Recognition)的基准测试,BERT在此任务上表现优异。 |
BERT : Pre-training + Fine-Tuning Paradigm
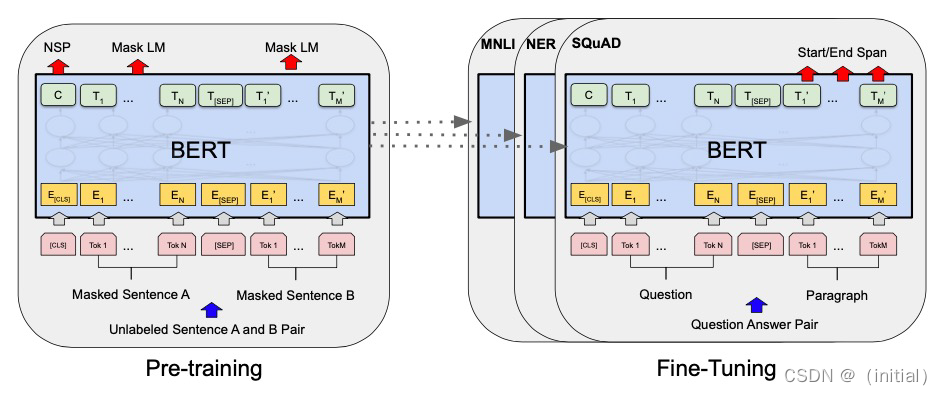
BERT 独特价值
1.全方位上下文理解:与以前的模型(例如GPT)相比,BERT能够双向理解上下文,即同时考虑一个词
的左边和右边的上下文。这种全方位的上下文理解使得BERT能够更好地理解语言,特别是在理解词义、
消歧等复杂任务上有明显优势。
2.预训练+微调(Pre-training + Fine-tuning)的策略:BERT模型先在大规模无标签文本数据上进行预
训练,学习语言的一般性模式,然后在具体任务的标签数据上进行微调。这种策略让BERT能够在少量标
签数据上取得很好的效果,大大提高了在各种NLP任务上的表现。
3.跨任务泛化能力:BERT通过微调可以应用到多种NLP任务中,包括但不限于文本分类、命名实体识
别、问答系统、情感分析等。它的出现极大地简化了复杂的NLP任务,使得只需一种模型就能处理多种
任务。
4.多语言支持:BERT提供了多语言版本(Multilingual BERT),可以支持多种语言,包括但不限于英
语、中文、德语、法语等,使得NLP任务能够覆盖更广的语言和区域。
5.性能优异:自BERT模型提出以来,它在多项NLP基准测试中取得了优异的成绩,甚至超过了人类的表
现。它的出现标志着NLP领域进入了预训练模型的新时代。
6.开源和可接入性:BERT模型和预训练权重由Google公开发布,让更多的研究者和开发者可以利用
BERT模型进行相关研究和应用开发,推动了整个NLP领域的发展。


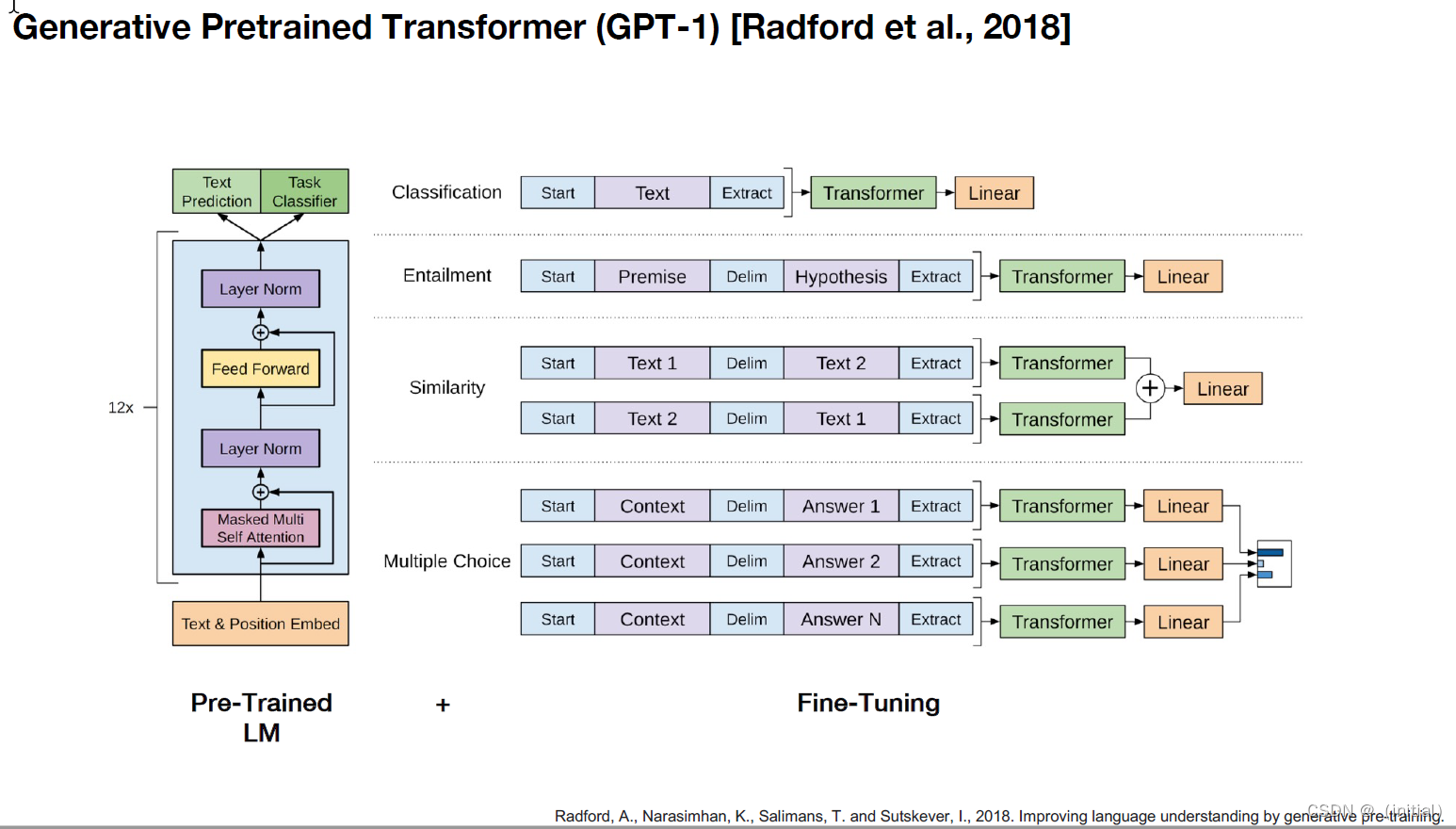
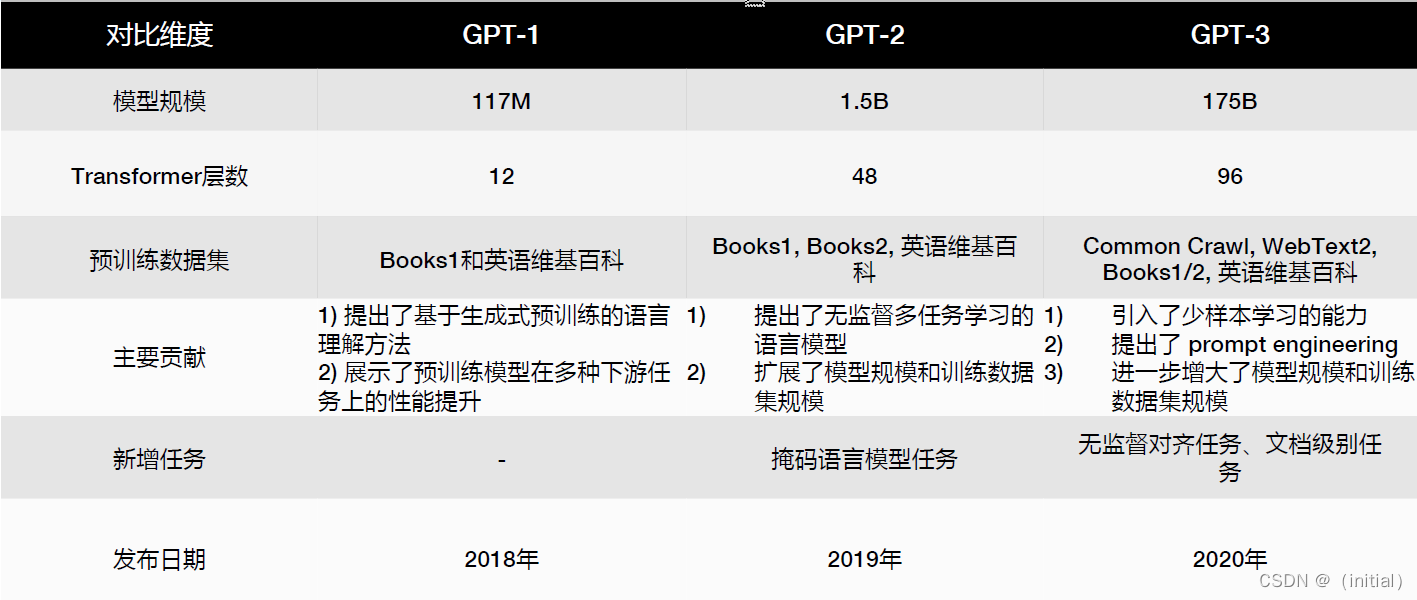
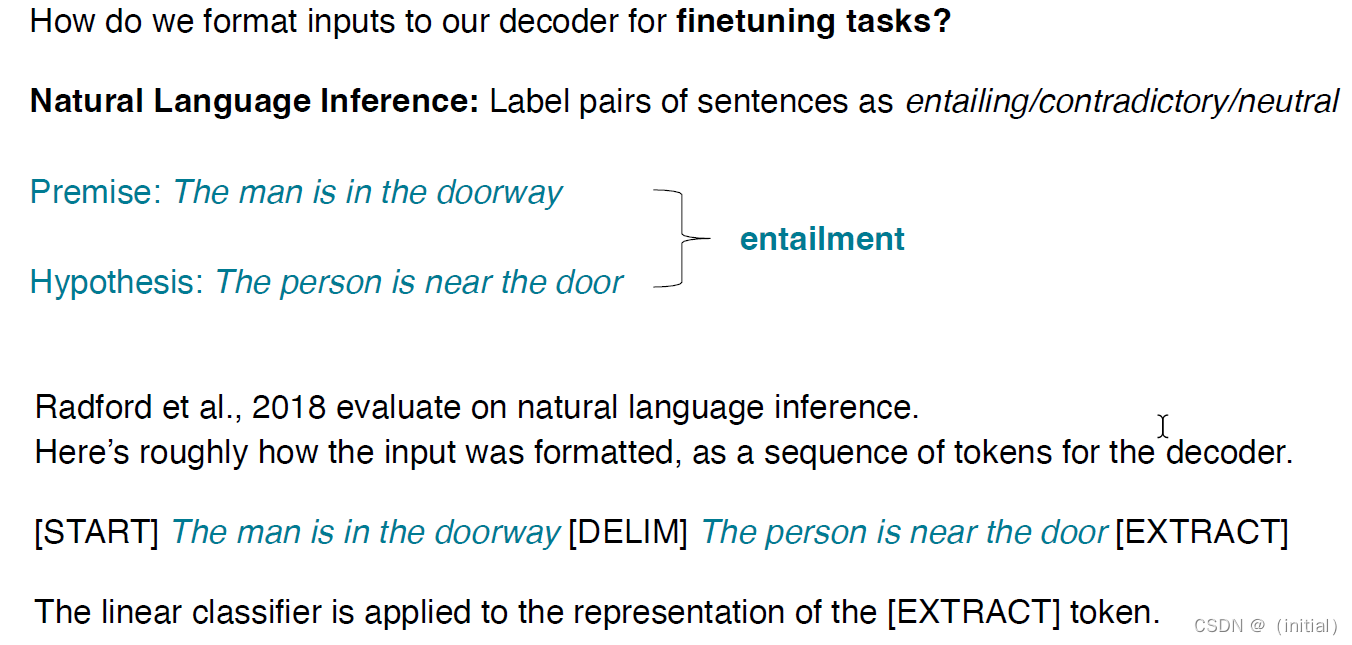
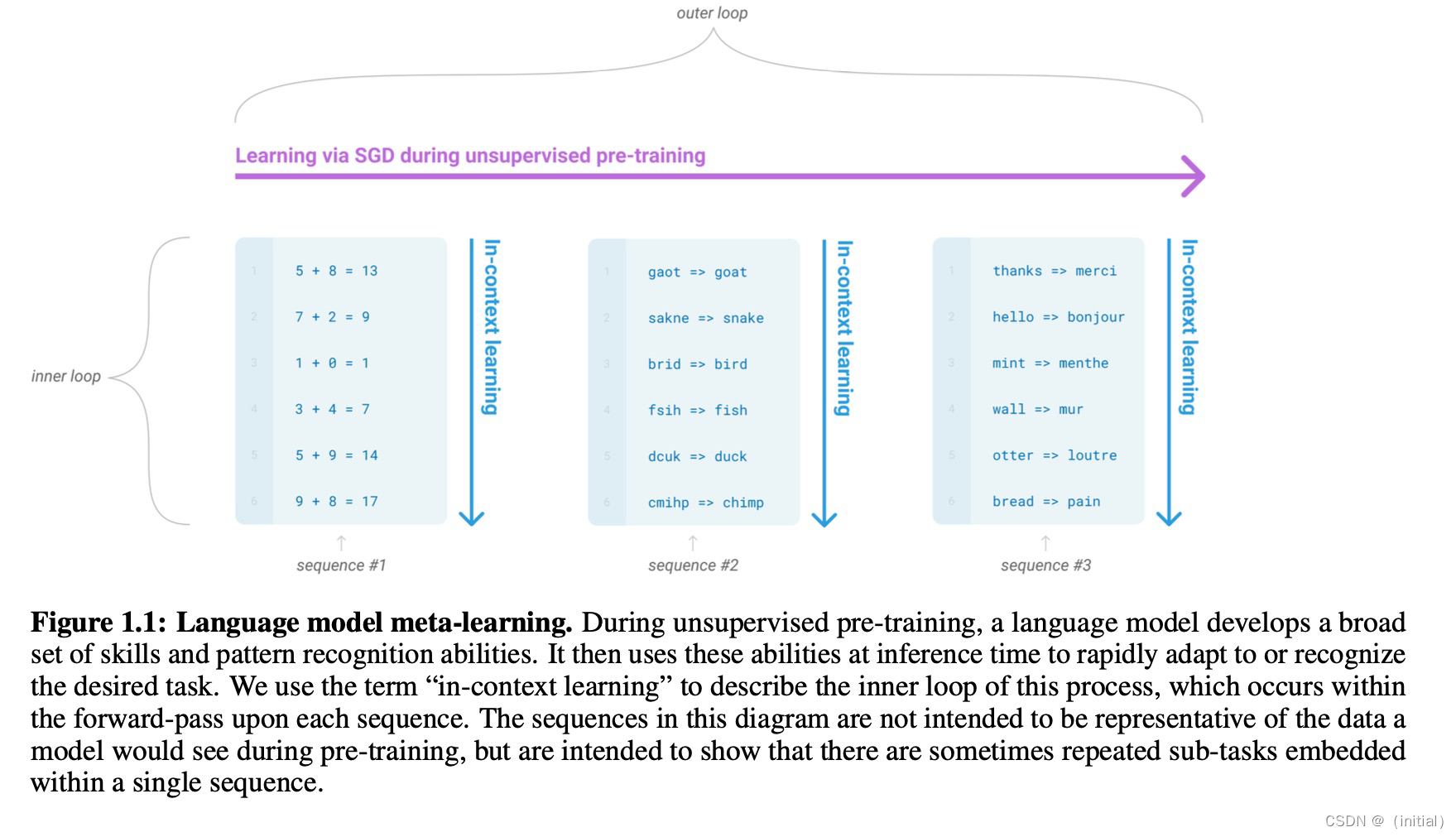
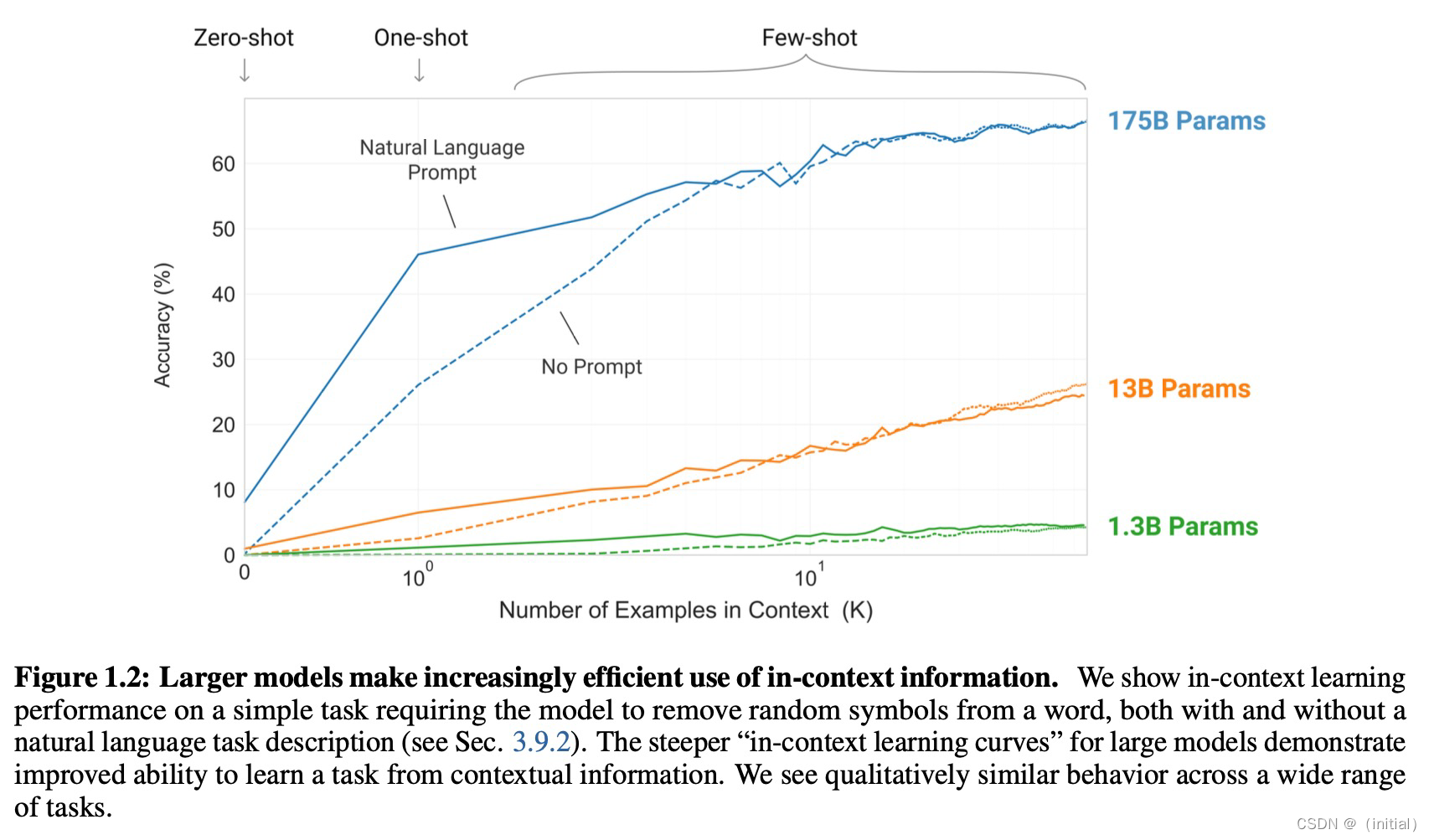
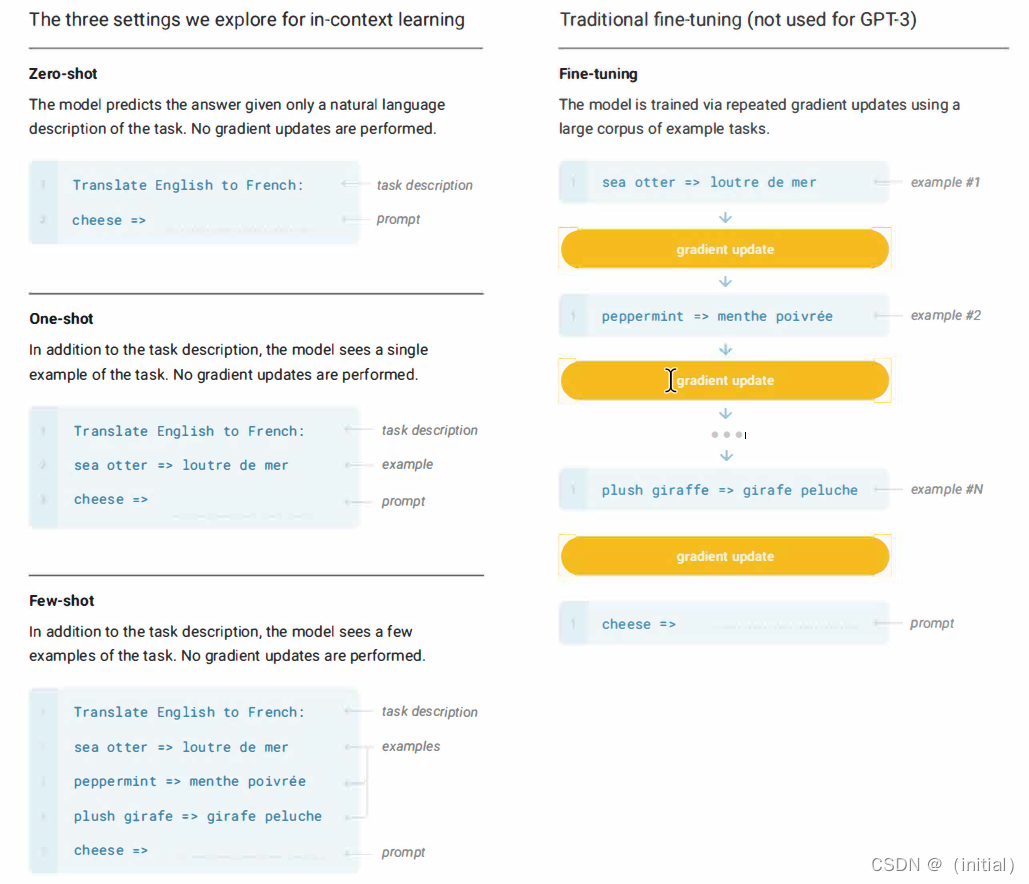
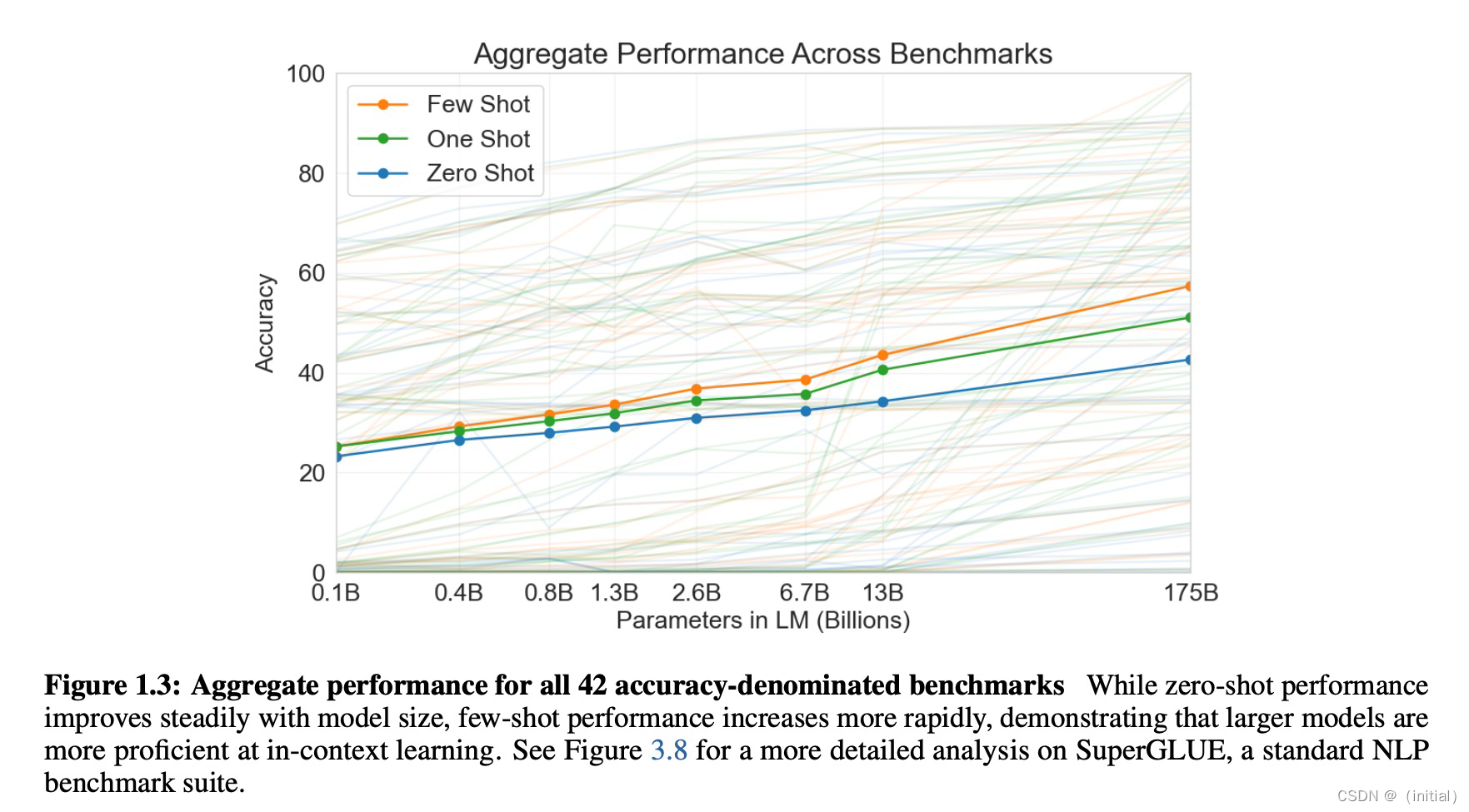
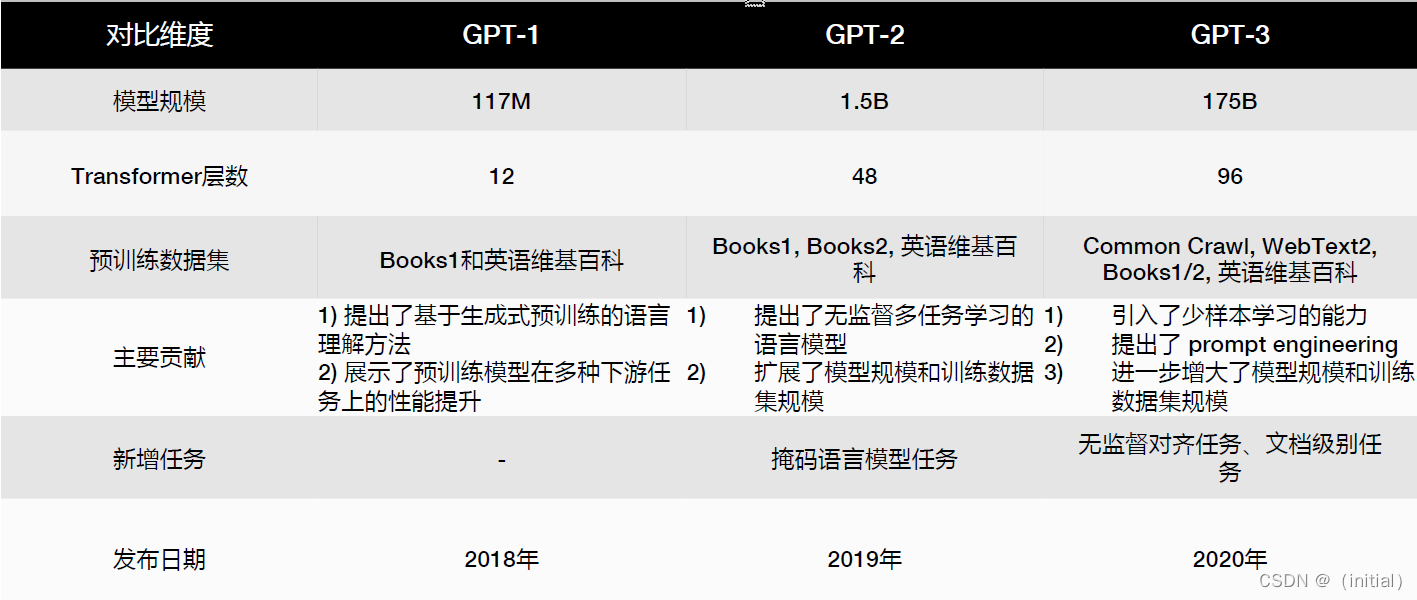
暴力美学 GPT 系列模型





















 51
51











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











