






文章和代码链接:
https://blog.keras.io/building-autoencoders-in-keras.html
首先我们在已有的MINIST基础上加噪音:
from keras.datasets import mnist
import numpy as np
#导入minist
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
noise_factor = 0.5
#生成均值为0,标准差为1的随机正态分布噪音
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
#使加了噪音后的数据满足在0到1区间内
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
呈现有噪音后的图像:
n = 10
plt.figure(figsize=(20, 2))
for i in range(n):
ax = plt.subplot(1, n, i)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
 接下来创建一个autoencoder模型:
接下来创建一个autoencoder模型:
#encode
input_img = Input(shape=(28, 28, 1))
#创建第一层卷积层 -----> (28,28,32)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img)
#创建第一层池化层 -----> (14,14,32)
x = MaxPooling2D((2, 2), padding='same')(x)
#第二层卷积层 -----> (14,14,32)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
#第二层池化层 -----> (7,7,32)
encoded = MaxPooling2D((2, 2), padding='same')(x)
#decode
#创建第一层卷积层 -----> (7,7,32)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(encoded)
#创建第一层upsampling -----> (14,14,32)
x = UpSampling2D((2, 2))(x)
#第二层卷积层 -----> (14,14,32)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
#第二层upsampling -----> (28,28,32)
x = UpSampling2D((2, 2))(x)
#第三层卷积层 -----> (28,28,1)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
模型创建好之后,通过autoencoder.fit我们训练x_train_noisy去 “fit” x_train。
autoencoder.fit(x_train_noisy, x_train,
epochs=100,
batch_size=128,
shuffle=True,
validation_data=(x_test_noisy, x_test),
callbacks=[TensorBoard(log_dir='/tmp/tb', histogram_freq=0, write_graph=False)])
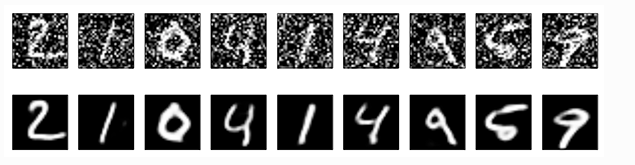














 4224
4224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









