






Graph上的任务
- 节点分类:预测特点节点的类型。对图上每一个节点是用softmax分类器,RGCN得到的节点表示作为分类器的输入。这个模型以及RGCN参数都是通过优化交叉熵损失学习得到的。
- 连接预测:预测两个节点是否有联系。可视为一个由encoder和decoder组成的自编码器。
- 社区检测:识别密集联系的节点群落
- 网络相似性:两个(子)网络的相似性有多大
图表示学习发展历史
图表示学习的主要目标是:将节点映射为向量表示的时候尽可能多的保留图的拓扑信息
主要分为:基于图结构的表示学习和基于图特征的表示学习
基于图结构的表示学习:基于图结构的表示学习对节点的向量表示只来源于图的拓扑结构的邻接矩阵,只是对图结构的单一表示,缺乏对节点特征消息的表示。
- Embedding:在图上接近的点在向量空间上也接近
- 2014 Deep Walk:通过预测节点的局部邻域(从图上的随机游动中采样)来学习嵌入
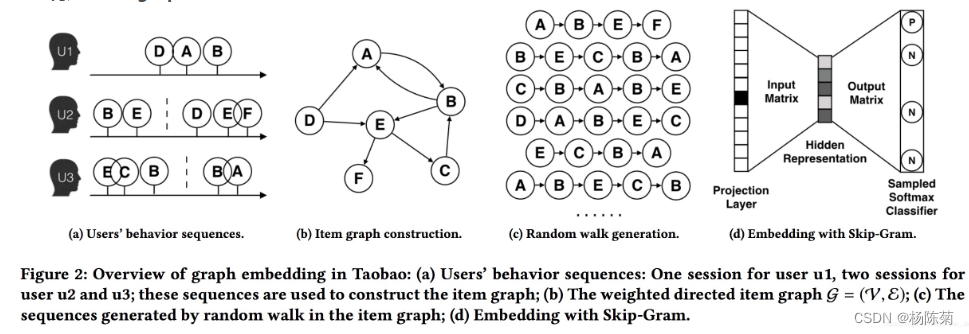
图源:阿里的paper - Node2Vec:通过更复杂的随机游走(广度优先、深度优先搜索)方案扩展了DeepWalk
- Metapath2vec:针对异构图而言,其节点属性不同,采样的方式也与传统的图网络不同,需要按照定义的Meta-Path规则进行采样。采样的样例可类似于“电影-导演-主演”这样的方法进行采样。
- LINE:认为1-hop和2-hop邻近的节点为“接近”节点。
基于图特征的表示学习:有效利用拓扑结构信息,结合现有特征向量得到新的特征表示
对于节点的向量表示既包含了图的拓扑信息的邻接矩阵表达的图结构,又包含了已有的特征向量,如(姓名、年龄、身高等信息)。
- GCN
- RGCN
- GraphSAGE:固定的采样倍率和不同的聚合方式
- GAT:输入不是固定的,而是引入的注意力机制
GCN
接下来细聊GCN原理,感谢原创作者,参考:
ai.plainenglish.io/graph-convolutional-networks-gcn-baf337d5cb6b
https://baijiahao.baidu.com/s?id=1678519457206249337&wfr=spider&for=pc
参考文献:Semi-Supervised Classification with Graph Convolutional Networks [ICLR 2017]
- GCN – 用于图上的半监督学习
用于半监督学习的多层图卷积网络(GCN)示意图
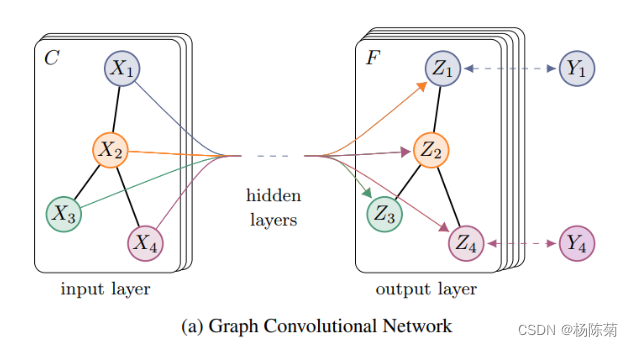
- GCN同时使用节点特征和结构特征进行训练
- GCN的主要思想:取所有邻居节点特征(包括自身节点特征)的加权平均值。度低的节点获得更大的权重。之后我们将得到的特征通过神经网络进行训练。
- 输入:邻接矩阵、特征矩阵;输出:新的特征矩阵
图网络建立
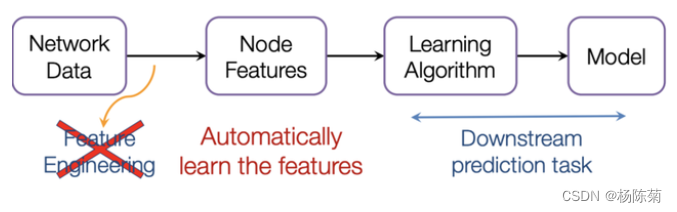
我们希望图能够自己学习 “特征工程”,GCN是一种卷积神经网络,它可以直接在图上工作,并利用图的结构信息。
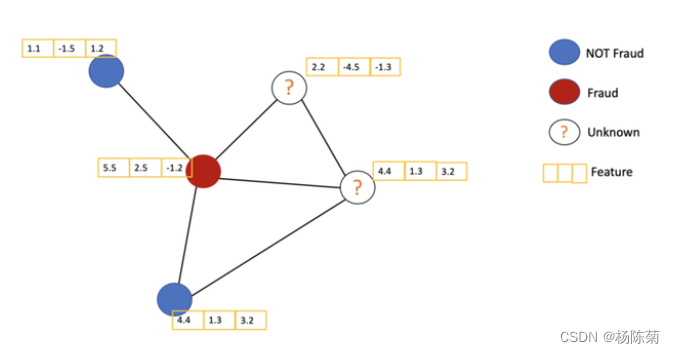
它解决的是对图(如引文网络)中的节点(如文档)进行分类的问题,其中仅有一小部分节点有标签(半监督学习)。
就像"卷积"这个名字所指代的那样,这个想法来自于图像,之后引进到图(Graphs)中。
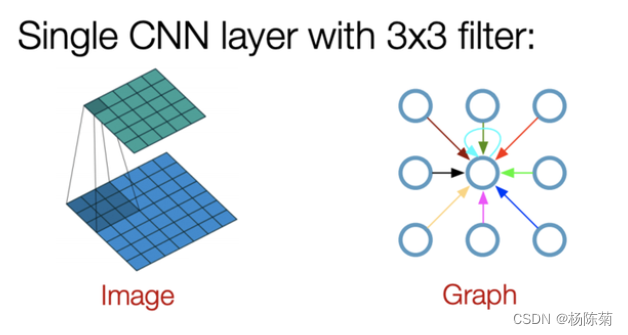
GCN的基本思路:对于每个节点,我们从它的所有邻居节点处获取其特征信息,当然也包括它自身的特征。假设我们使用average()函数。我们将对所有的节点进行同样的操作。最后,我们将这些计算得到的平均值输入到神经网络中。
在下图中,我们有一个引文网络的简单实例。其中每个节点代表一篇研究论文,同时边代表的是引文。我们在这里有一个预处理步骤。在这里我们不使用原始论文作为特征,而是将论文转换成向量(通过使用NLP嵌入,例如tf-idf)。
让我们考虑下绿色节点。首先,我们得到它的所有邻居的特征值,包括自身节点,接着取平均值。最后通过神经网络返回一个结果向量并将此作为最终结果。
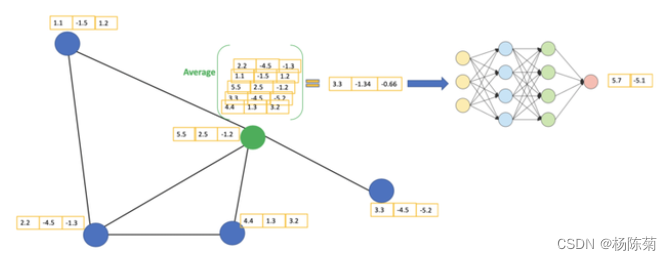
在实际操作中,我们可以使用比average函数更复杂的聚合函数。
图表示学习
- 节点特征(代表节点的数据)
- 图的结构(表示节点如何连接)
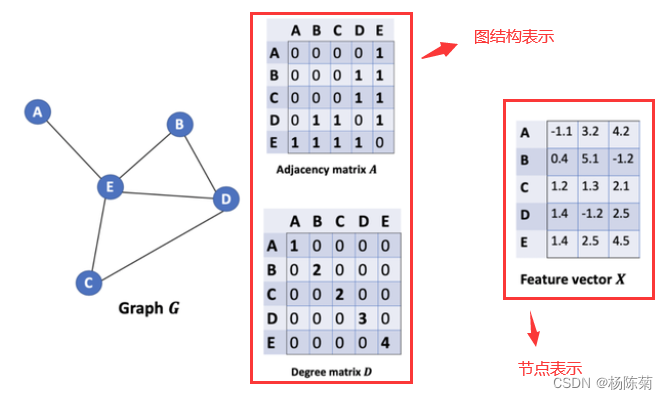
从图G中,我们有一个邻接矩阵A和一个度矩阵D。同时我们也有特征矩阵X。
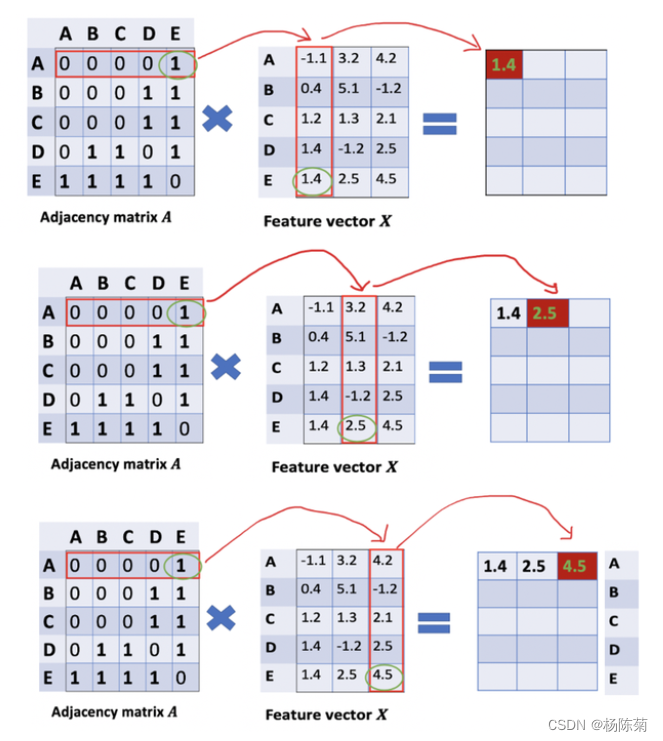
那么我们怎样才能从邻居节点处得到每一个节点的特征值呢?解决方法就在于A和X的相乘。
看看邻接矩阵的第一行,我们看到节点A与节点E之间有连接,得到的矩阵第一行就是与A相连接的E节点的特征向量(如下图)。同理,得到的矩阵的第二行是D和E的特征向量之和,通过这个方法,我们可以得到所有邻居节点的向量之和。
这里还有一些需要改进的地方:
- 计算忽略了节点本身的特征。计算得到的矩阵的第一行也应该包含节点A的特征。
方法:在A中增加一个单位举证I来解决,得到一个新的邻接矩阵:
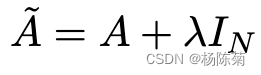
取lambda=1(使得节点本身的特征和邻居一样重要),我们就有=A+I,注意,我们可以把lambda当做一个可训练的参数,但现在只要把lambda赋值为1就可以了,即使在论文中,lambda也只是简单的赋值为1。
通过给每个节点增加一个自循环,我们得到新的邻接矩阵:
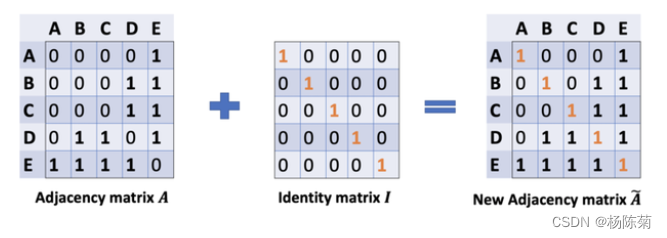
- 我们不需要使用sum()函数,而是需要取平均值,甚至更好的邻居节点特征向量的加权平均值。
原因:在使用sum()函数时,度大的节点很可能会生成的大的v向量,而度低的节点往往会得到小的聚集向量,这可能会在以后造成梯度爆炸或梯度消失(例如,使用sigmoid时)。此外,神经网络似乎对输入数据的规模很敏感。
方法:对这些向量进行归一化,以摆脱可能出现的问题。
对于矩阵缩放,我们通常将矩阵乘以对角线矩阵。在当前的情况下,我们要取聚合特征的平均值,或者从数学角度上说,要根据节点度数对聚合向量矩阵X进行缩放。直觉告诉我们这里用来缩放的对角矩阵是与度矩阵D有关的东西(为什么是D,而不是D?因为我们考虑的是新邻接矩阵 的度矩阵D,而不再是A了)。
如何对向量进行缩放/归一化:
我们如何将邻居的信息传递给特定节点?在这种情况下,D的逆矩阵(即,D^{-1})就会用起作用。基本上,D的逆矩阵中的每个元素都是对角矩阵D中相应项的倒数。
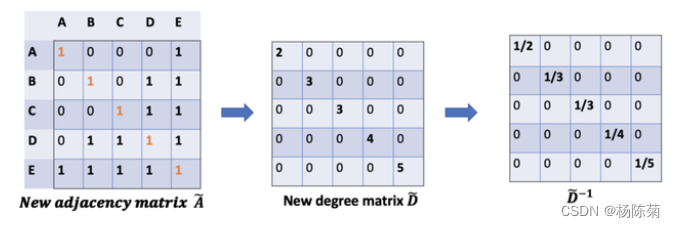
例如,节点A的度数为2,所以我们将节点A的聚合向量乘以1/2,而节点E的度数为5,我们应该将E的聚合向量乘以1/5,以此类推。
因此,通过D取反和X的乘法,我们可以取所有邻居节点的特征向量(包括自身节点)的平均值。
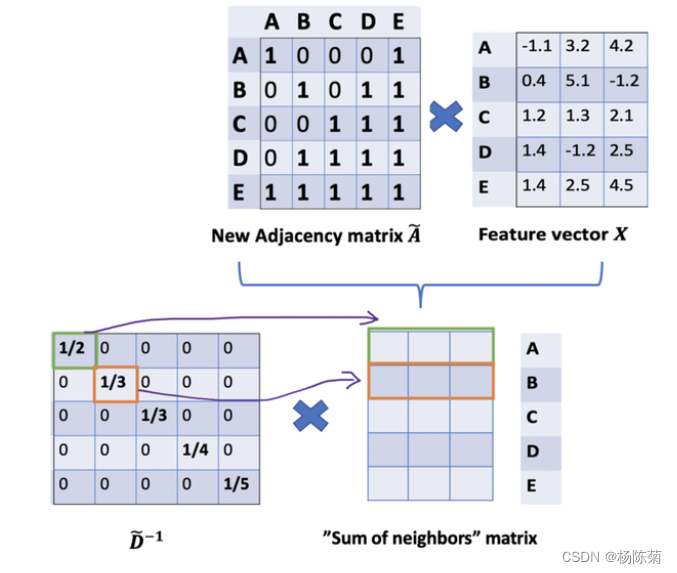
到目前为止一切都很好。但是你可能会问加权平均()怎么样?直觉上,如果我们对高低度的节点区别对待,应该会更好。
但我们只是按行缩放,但忽略了对应的列(虚线框)。
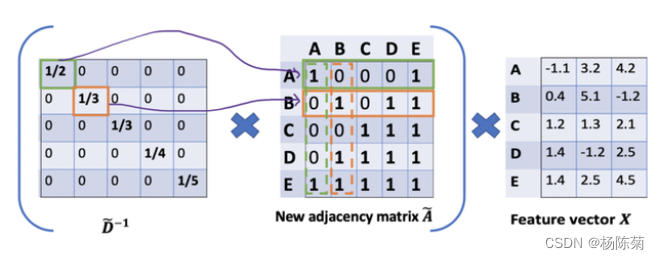
为列增加一个新的缩放器。新的缩放方法给我们提供了 “加权 “的平均值。我们在这里做的是给低度的节点加更多的权重,以减少高度节点的影响。这个加权平均的想法是,我们假设低度节点会对邻居节点产生更大的影响,而高度节点则会产生较低的影响,因为它们的影响力分散在太多的邻居节点上。如下图:
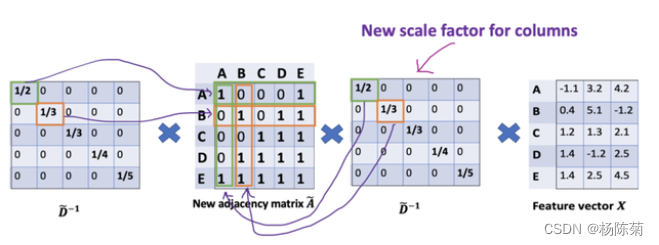
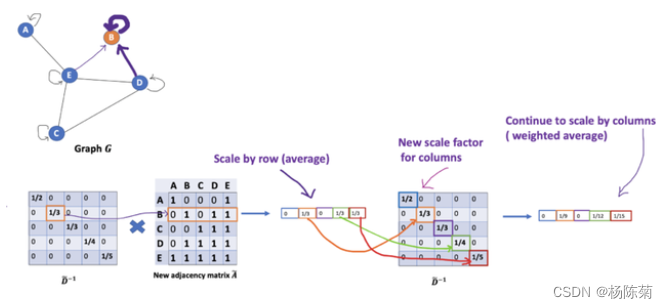
在节点B处聚合邻接节点特征时,我们为节点B本身分配最大的权重(度数为3),为节点E分配最小的权重(度数为5)。

因为我们归一化了两次,所以将”-1 “改为”-1/2”
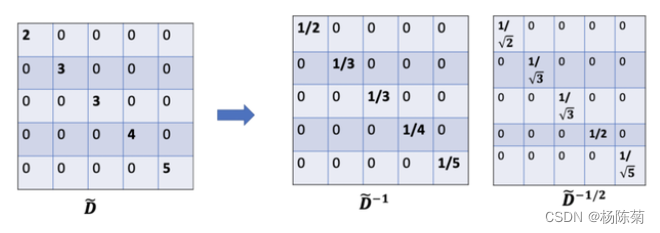
我们考虑具有以下逐层传播规则的多层卷积网络(GCN):
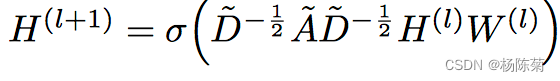
其中
W
l
W^{l}
Wl是一种特定于层的可训练权重矩阵,
H
l
H^{l}
Hl是第l层的输出矩阵
H
0
=
X
H^{0}=X
H0=X
实例
考虑一个两层GCN,用于对称邻接矩阵A的图上的半监督节点分类。
首先在预处理步骤中计算
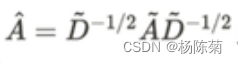
然后模型采用简单的形式:
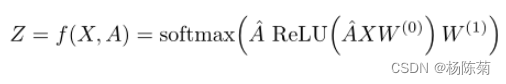
然后评估所有标记的交叉熵误差:
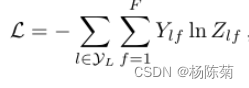
其中
y
L
y_{L}
yL是所有有标签的节点搜索引集,权重更新使用梯度下降方法。
RGCN
论文:Modeling Relational Data with Graph Convolutional Networks
1 任务
提出关系图卷积网络(R-GCN),用于两个知识库的补全任务:连接预测(恢复丢失的三元组)和实体分类
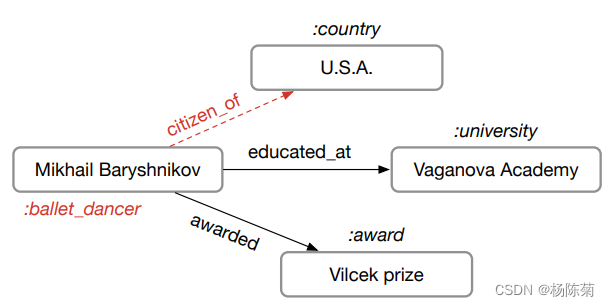
节点是实体,边是用其类型标记的关系,节点用实体类型标记(例如:大学)。以红色显示的边和节点标签是要推断的缺失信息。。
例如知道了“小明在北京大学读书”,就能知道“小明”应该归为“人类”,而且知识图谱中一定有(小明,住在,中国)这样一个三元组。
2 神经关系建模
将有向和标记的多重图表示为: G = ( V , ε , R ) G=(V,\varepsilon,R) G=(V,ε,R),其节点(实体) v i ∈ V v_{i}\in{V} vi∈V,标记的边(关系)为 ( v I , r , v j ) ∈ ε (v_{I},r,v_{j})\in\varepsilon (vI,r,vj)∈ε,其中 r ∈ R r \in R r∈R是一个关系类型
3 RGCN
回忆一下,普通GCN卷积操作如下:
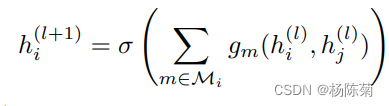

R-GCN的卷积操作如下:
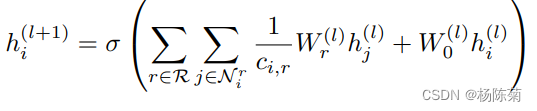

此公式与GCN不同的是,不同边类型所连接的邻居节点,进行一个线性转化,
W
r
(
l
)
W^{(l)}_{r}
Wr(l)的个数也就是边类型的个数,论文中称为relation-specific。当然此处还可以设置更加灵活的函数,例如多层神经网络。
其区别在于R-GCN中,通往一个节点的不同边可以代表不同的关系。在普通的GCN中,所有边共享相同的权重W;在R-GCN中,不同类型的边(关系)使用不同的权重
W
r
W_{r}
Wr,只有同一种关系才会使用同一个权重。
R-GCN模型中单节点更新的计算如图:

用于计算R-GCN模型中单个图节点/实体(红色)更新的图。
收集来自相邻节点(深蓝色)的激活(d维向量),然后分别针对每种关系类型(for both in- and outgoing edges)进行转换。结果表示(绿色)以(标准化的)总和累加并通过激活函数(例如ReLU)传递。可以与整个图上的共享参数并行地计算此每个节点的更新。
“不同关系对应不同权重”的做法大大增加了模型的参数量,为降低参数量和防止过拟合,引入两种单独的方法来对权重规范化(归一化):
- 基分解:
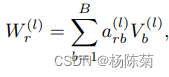
即作为基础变换 V b ( l ) ∈ R d ( l + 1 ) × d ( l ) V^{(l)}_{b} \in R^{d^{(l+1)\times d^{(l)}}} Vb(l)∈Rd(l+1)×d(l)与系数 s r b ( l ) s^{(l)}_{rb} srb(l)的线性组合,使得仅系数取决于r。
在块对角分解(block-diagonal decomposition)中,我们通过在一组低维矩阵上的直接求和定义每个 W r ( l ) W^{(l)}_{r} Wr(l)

基函数分解(3)可以看作是不同关系类型之间有效权重共享的一种形式,而块分解(4)可以看作是每种关系类型对权重矩阵的稀疏约束。块分解结构编码了一种直觉,即可以将潜在特征分组为变量集,这些变量集在组内比在组间更紧密地耦合。两种分解都减少了学习高度多关系数据(例如,现实的知识库)所需的参数数量。同时,我们期望基本参数化可以缓解稀疏关系的过度拟合,因为稀疏关系和更频繁关系之间共享参数更新。
整个R-GCN模型采用以下形式:我们按照(2)的定义堆叠 L LL 层-上一层的输出是下一层的输入。如果不存在其他特征,则可以将第一层的输入选择为图中每个节点的唯一 one-hot 向量。对于块表示,我们通过单个线性变换将此 one-hot 映射为密集表示。然而,我们在这项工作中仅考虑了这种无特征的方法,我们注意到,在 Kipf 和 Welling(2017)中表明,此类模型可以利用预定义的特征向量(例如,与特定节点关联的文档的词袋(bag-of-words)描述)。
4 实体分类
对于实体的半监督分类,只需堆叠R-GCN层,并在最后一层的输出上激活softmax() 激活每个实体。我们将所有标记节点上的以下交叉熵损失最小化(而忽略未标记节点):
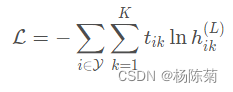
其中
y
y
y 是具有标签的节点索引的集合,而
h
i
k
(
L
)
h^{(L)}_{ik}
hik(L)是第 i 个标记节点的网络输出的第 k 个条目。
t
i
k
t_{ik}
tik表示其各自的真实标签。实际上,我们使用(全批次)梯度下降技术训练模型。
实体分类模型的示意图如图(a):
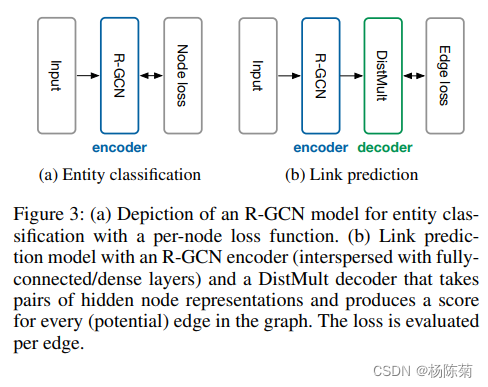
5 链接预测
链接预测用于预测新事实(即三元组(subject, relation, object))
形式上,知识库由有向标记图
G
=
(
V
,
ε
,
R
)
G=(V,\varepsilon,R)
G=(V,ε,R),而不是完整的边
ε
\varepsilon
ε,我们只得到了不完整的子集
ε
^
\hat{\varepsilon}
ε^任务是为可能的边
(
s
,
r
,
o
)
(s,r,o)
(s,r,o)分配函数
f
(
s
,
r
,
o
)
f(s,r,o)
f(s,r,o),以确定这些便属于
ε
\varepsilon
ε的可能性。
通过函数
s
:
R
d
×
R
×
R
d
→
R
s:R^{d}\times R \times R^{d} \rightarrow R
s:Rd×R×Rd→R对(subject, relation, object)-triples 进行评分。链接预测模型如图(b)所示。
链接预测模型:可视为由一个encoder和一个decoder组成的自编码器。(用卷积网络和因式分解组合来解决链接预测问题)
1)encoder:R-GCN为实体生成隐层的特征表示;
2)decoder:张量的分解模型,利用encoder生成的表示预测边的label。
按理说decoder可以使用任何一种形式的分解/打分模型,作者使用了简单并且最有效的分解方法:DistMult。
在DistMult中,每个关系r与对角矩阵
R
r
∈
R
d
×
d
R_{r} \in R^{d\times d}
Rr∈Rd×d关联,并且将三元组
(
s
,
r
,
o
)
(s,r,o)
(s,r,o)记为:

使用负采样来训练模型。对于每个观察到的例子,我们对 ω 负样本进行采样。我们通过随机破坏每个正面示例的主题或对象来进行采样。我们针对交叉熵损失进行了优化,以使模型的可观察三元组得分高于负三元组:
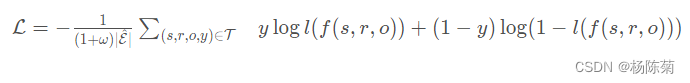
其中
T
T
T是真实和损坏的三元组的总集合,
l
l
l是 logistic sigmoid function,
y
y
y 是一个指示符,
y
=
1
y = 1
y=1 对于正的三元组,
y
=
0
y = 0
y=0对于负的三元组。
6 指标
MMR
是一个国际上通用的对搜索算法进行评价的机制,即第一个匹配结果,分数为1,第二个匹配结果分数为0.5,第n个匹配结果分数为1/n,如果没有匹配的句子分数为0.最终的分数为所有的得分之和。
Hit@10
每个testing triple正确答案是否排在序列的前10,如果在的话就计数+1,最终排在前十的个数/总个数,就是Hit@10。


















 1082
1082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









