







Tensorflow实现多层感知机
上上篇博客讲述了使用一个softmax Regression(无隐含层),取得了接近92%的手写字识别准确率。
现在我们尝试加入隐含层,并使用减轻过拟合的Dropout、自适应学习速率的Adagrad,以及可以解决梯度弥散的激活函数ReLU。来看看他们的加入对识别准确率的影响。
开干。
和以前一样,导入数据,import tf,激活Session。
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
mnist = read_data_sets('./MNIST_data/',False,one_hot = True)
import tensorflow as tf
sess = tf.InteractiveSession()
接下来进行第一步:定义算法公式
首先,我们给出隐含层的参数初始化,这里in_units是输入节点数,h1_units是隐含层输出节点数设为300,W1,b1是隐含层的权重和偏置,我们将偏置全部设置为0,初始权重设置为截断的正态分布,标准差设置为0.1,使用tf.truncates_normal(shape, mean, stddev) [shape表示生成张量的维度,mean是均值,stddev是标准差实现],这么做的本质其实是给参数加入一点噪声来打破完全对称而且ReLU避免0梯度,最后使用输出层的Softmax,直接将权重W2和偏置b2全部初始化为0(对于Sigmoid在0附近最为敏感、梯度最大)
in_units = 784
h1_units = 300
w1 = tf.Variable(tf.trubcates_normal([in_units, h1_units], stddev = 0.1))
b1 = tf.Variable(tf.zeros([h1_units]))
w2 = tf.Variable(tf.zeros([h1_units, 10]))
b2 = tf.Variable(tf.zeros([10]))
接下来定义输入的x的placeholder,另外与前面不同的时候要placeholder一个Dropout,同时也要设置它的比率keep_prob,在训练时应该是小于1的,用以制造随机性,防止过拟合;在预测时应该等于1,即使用全部特征来预测样本类别。所以把它定义为一个placeholder。
x = tf.placeholder(tf.float32,[None, in_units])
keep_prob = tf.placeholder(tf.float32)
有了参数我们来定义相应的模型结构,首先是输入层后面的隐含层,命名为hidden1,通过tf.nn.relu(tf.matmul(x,W1) + b1)实现带有隐含层的节点,然后使用Dropout随机将一部分节点设置为0来制造随机性,最后是输出层,用softmax。
hidden1 = tf.nn.relu(tf.matmul(x,w1) + b1)
hidden1_drop = tf.nn.dropout(hidden1, keep_prob)
y = tf.nn.softmax(tf.nn.matmul(hidden1_drop,w2) + b2)
自己画的网络,有错误的话谢谢指正,单张图片为例:

接下来进行第二步:定义损失函数和优化器
损失函数继续使用交互熵损失函数
优化器我们选择自适应的优化器Adagrad,学习率设置为0.3,我们直接使用tf.train.AdagradOptimizer。
其中Adagrad解决不同参数应该使用不同的更新速率的问题。**Adagrad自适应地为各个参数分配不同学习率的算法。**我们认为在学习率的最初阶段,我们是距离损失函数最优解很远的,随着更新的次数的增多,我们认为越来越接近最优解,于是学习速率也随之变慢。

y_ = tf.plcaeholder(tf.float32,[None,10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ *tf.log(y),reducetion_indices = [1]))
train_step = tf.train.AdagradOptimizer(0.3).minimize(cross_entropy)
接下来进行第三步:训练
基本与之前相同,全局初始化,设置好训练次数,然后feed进去数据,最后run。
不同的是feed要加keep_prob实现dropout比例。由于加入隐含层因此采用3000个batch,每个batch100条数据,共30万个样本,而训练集有55000个样本,相当于进行了大约5个epoch。
tf.global_variables_initializer().run()
for i in range(3000):
batch_xs, batch_ys = mnist.train.next_batch(100)
train_step.run({x: batch_xs, y_: batch_ys, keep_prob: 0.75})
最后当然是最后一步:查看准确率
与前面基本一样,当然也要feed给keep_prob为1
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(accuracy.eval({x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))

最终结果为0.9773,相比于没有隐含层的0.9128,大概误差下降了6%,究其原因主要是隐含层本身,他能对特征进行抽象和转化。没有隐含层的softmax只能直接从图像的像素点推断是哪个数字,而没有特征抽象的过程。
完整代码:
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
import tensorflow as tf
mnist = read_data_sets("./MNIST_data/", one_hot=True)
sess = tf.InteractiveSession()
in_units = 784
h1_units = 300
W1 = tf.Variable(tf.truncated_normal([in_units, h1_units], stddev=0.1))
b1 = tf.Variable(tf.zeros([h1_units]))
W2 = tf.Variable(tf.zeros([h1_units, 10]))
b2 = tf.Variable(tf.zeros([10]))
x = tf.placeholder(tf.float32, [None, in_units])
keep_prob = tf.placeholder(tf.float32)
hidden1 = tf.nn.relu(tf.matmul(x, W1) + b1)
hidden1_drop = tf.nn.dropout(hidden1, keep_prob)
y = tf.nn.softmax(tf.matmul(hidden1_drop, W2) + b2)
# Define loss and optimizer
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
train_step = tf.train.AdagradOptimizer(0.3).minimize(cross_entropy)
# Train
tf.global_variables_initializer().run()
for i in range(3000):
batch_xs, batch_ys = mnist.train.next_batch(100)
train_step.run({x: batch_xs, y_: batch_ys, keep_prob: 0.75})
# Test trained model
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(accuracy.eval({x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
反三
- 增加训练次数为6000

结果:
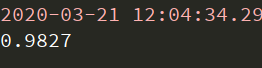
- 改变优化器
1)
结果:

2)

结果:

- 改变隐含层节点数
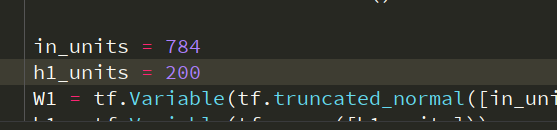
结果有所浮动,但不大。(200-1000)

- 改变隐含层数

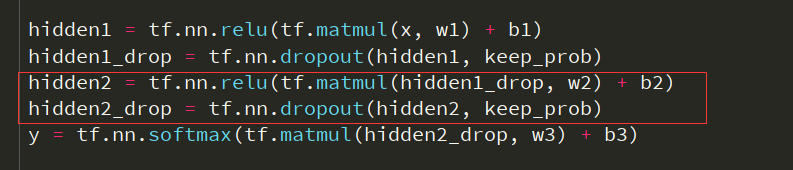
结果: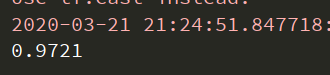
ok到这里,我们下期再见啦拜拜
参考:
https://www.jianshu.com/p/a8637d1bb3fc
https://blog.csdn.net/weixin_40170902/article/details/80092628















 4148
4148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









