






Intel® Intrinsics Guide
搞懂SSE

寄存器与指令数据细节
SSE指令集推出时,Intel公司在Pentium III CPU中增加了8个128位的SSE指令专用寄存器,称作XMM0到XMM7。这些XMM寄存器用于4个单精度浮点数运算的SIMD执行,并可以与MMX整数运算或x87浮点运算混合执行。
2001年在Pentium 4上引入了SSE2技术,进一步扩展了指令集,使得XMM寄存器上可以执行8/16/32位宽的整数SIMD运算或双精度浮点数的SIMD运算。对整型数据的支持使得所有的MMX指令都是多余的了,同时也避免了占用浮点数寄存器。SSE2为了更好地利用高速寄存器,还新增加了几条寄存指令,允许程序员控制已经寄存过的数据。这使得 SIMD技术基本完善。
SSE3指令集扩展的指令包含寄存器的局部位之间的运算,例如高位和低位之间的加减运算;浮点数到整数的转换,以及对超线程技术的支持。
AVX是Intel的SSE延伸架构,把寄存器XMM 128bit提升至YMM 256bit,以增加一倍的运算效率。

数据结构
由于通常没有内建的128bit和256bit数据类型,SIMD指令使用自己构建的数据类型,这些类型以union实现,这些数据类型可以称作向量,一般来说,MMX指令是__m64 类型的数据,SSE是__m128类型的数据等等
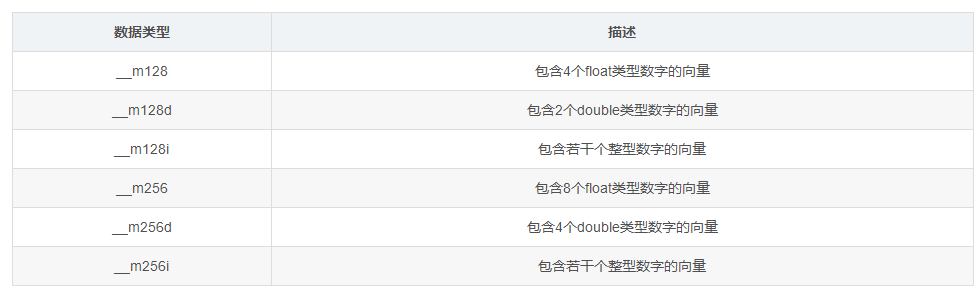
- 每一种类型,从2个下划线开头,接一个m,然后是向量的位长度。
- 如果向量类型是以d结束的,那么向量里面是double类型的数字。如果没有后缀,就代表向量只包含float类型的数字。
- 整形的向量可以包含各种类型的整形数,例如char,short,unsigned long long。也就是说,__m256i可以包含32个char,16个short类型,8个int类型,4个long类型。这些整形数可以是有符号类型也可以是无符号类型
内存对齐
为了方便CPU用指令对内存进行访问,通常要求某种类型对象的地址必须是某个值K(通常是2、4或8)的倍数,如果一个变量的内存地址正好位于它长度的整数倍,我们就称他是自然对齐的。
通常对于各种类型的对齐规则如下:
数组 :按照基本数据类型对齐,第一个对齐了后面的自然也就对齐了。
联合 :按其包含的长度最大的数据类型对齐。
结构体: 结构体中每个数据类型都要对齐
对于SIMD的内存对齐是指__m128等union在内存中存储时的存储方式。
对于各成员变量来说,存放的起始地址相对于结构的起始地址的偏移量必须为该变量的类型所占用的字节数的倍数,各成员变量在存放的时候根据在结构中出现的顺序依次申请空间, 同时按照上面的对齐方式调整位置, 空缺的字节自动填充。
对于整个结构体来说,为了确保结构的大小为结构的字节边界数(即该结构中占用最大的空间的类型的字节数)的倍数,所以在为最后一个成员变量申请空间后,还会根据需要自动填充空缺的字节。
intel官网
https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html
解决报错
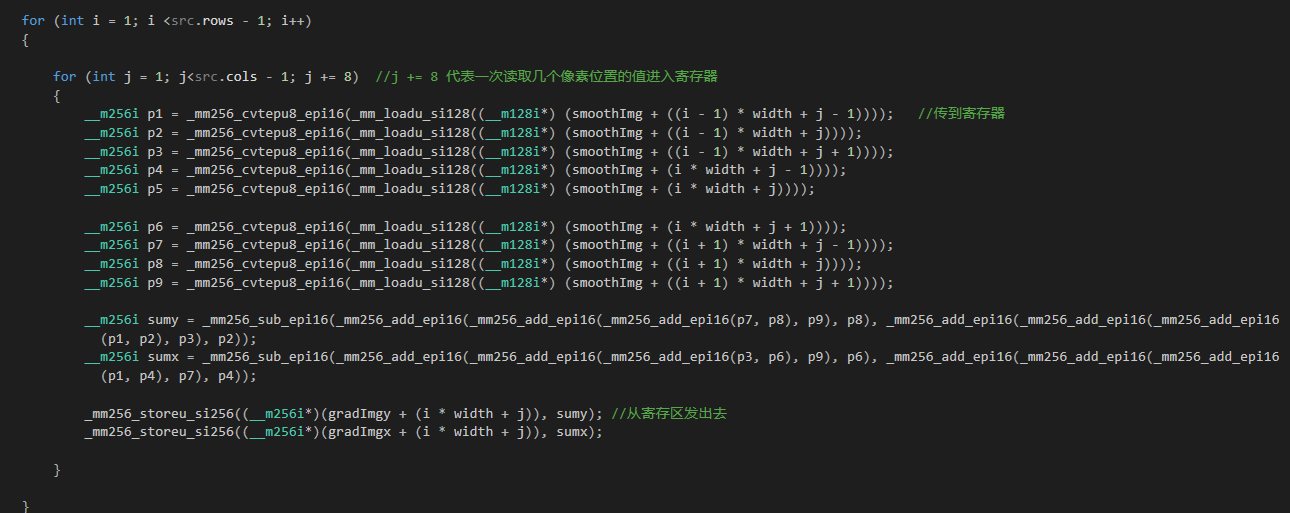
SSE采用“接-化-发”原理
寄存器接收
__m128i _mm_loadu_si128 (__m128i const* mem_addr)
处理转化
__m128i _mm_cvtepu8_epi16 (__m128i a)
__m256i _mm256_sub_epi16 (__m256i a, __m256i b)
......
发送出去
void _mm256_storeu_si256 (__m256i * mem_addr, __m256i a)
项目总结

大佬说:这个正常情况下用一维的就可以了,有必要的时候才用2维的
大致意思是 公司一般用一维就够用了,因为二维的会多出来一个维度,公司的电脑是8核的 使用二维会增大好多计算量。 我理解 90%的情况是一维的

yr:我们目前好像都是用一维的 , 我们一般都是对 row分割 . 理由大概率是这个吧 所以一般tbb对于大图像的提速会好一点
加速时会消耗内存以提高速度 , 消耗内存就是空间换时间
算法分为空间复杂度和时间复杂度,一般在工作中时间要求更高,可以改变算法逻辑,必要情况下,哪怕提高空间复杂度也要降低时间复杂度
并发算法都是压榨设备的性能,特别是现在的多核处理器。但是如果设备性能不够高,即使很高的并发也实现不了,而且将串行修改成并行或者并发,都是要额外付出时间的,所以leader说没必要用二维度的range,就是因为公司电脑性能带不动二维,强行使用带不来较一维明显的效果,还压榨设备性能,也会造成硬件的加速老化。
实际项目中往往牺牲内存提升速度,通过开辟更大的内存,即扩大空间复杂度。来降低算法实现的时间复杂度 所以同样的效果其实可以有很多实现方式,而且优劣分明。
加速算法主要就是在空间复杂度和时间复杂度上下文章
电脑提速从而减少浪费内存
1、tbb和OpenMP都是多线程的无法结合进行加速,尝试结合后,时间迸发;
2、tbb加速比较实用的还是lambda表达式的形式;
3、OpenMP使用需要配置VS属性:
在项目上右键->属性->配置属性->C/C++->语言->OpenMP支持,选择“是”即可。提供指向 OpenMP API 中使用的构造的链接。
4、SSE支持的数据类型是4个32位(共计128位)浮点数集合,就是C、C++语言中的float[4],并且必须是以16位字节边界对齐的。因此这也给输入和输出带来了不少的麻烦,实际上主要影响SSE发挥性能的就是不停地对数据进行复制以适用应它的数据格式。
5、用AVX指令集必须做好合适的IDE配置。
在C/C++ ->代码生成的启用增强指令集里
+++++++++++++++++++++++++++++++++++++++++++++++++++
使用注意事项
该代码段使用Intel SSE (Streaming SIMD Extensions) 指令集进行图像处理。通过看代码,它似乎对图像中的每个像素执行一些操作,具体地,它似乎是对两张图像执行了某种差异检测。
以下是我观察到的一些问题及建议:
- 拼写错误:
-
- m_offest 应该是 m_offset。在 if (filterPtr[c] - srcPtr[c] <m_offest) 中确保变量名是正确的。
- 可能的内存对齐问题:
-
- 当使用 _mm_loadu_si128 时,它从非对齐的内存加载数据。对于最佳性能,如果您的数据是对齐的,使用 _mm_load_si128 会更快。但这取决于 m_srcImage.ptr<const uchar>(r) 返回的数据是否已经对齐。
- 越界访问:
-
- 在SSE循环中,确保您不会越过图像的尾部。(m_srcImage.cols) - 32 可能导致您在最后几列中丢失一些像素。但在您的代码中,之后的非SSE循环应该会处理这些,只要确保这两个循环之间没有重叠或遗漏。
- _x80 和 reg_offset 未定义:
-
- 代码中使用了 _x80 和 reg_offset,但没有给出其定义或赋值。这可能只是提供的代码片段的一部分,但确保这两个变量在上文中有正确的定义和初始化。
- 差异检测逻辑:
-
- SSE循环和非SSE循环似乎有不同的逻辑。在SSE部分,您首先对像素值执行XOR操作,并在减去之前比较它们。在非SSE部分,您只是直接减去它们。这两者可能不完全等价,除非 _x80 仅仅是一个将无符号字节转换为有符号字节的偏移量。
- 比较操作的逻辑:
-
- 在SSE部分,您使用了 _mm_cmplt_epi8,这会比较两个向量中的每个字节,并返回一个掩码,其中每个字节要么是 0xFF (如果a < b),要么是 0x00。这可能与非SSE部分中的逻辑不完全匹配,因为您在那里直接将值设置为 255 或 0。确保两者的逻辑是一致的。
总的来说,除了这些问题和考虑点外,代码似乎是为了性能优化而写的。确保在更改之后进行充分的测试,以确保您的修改不会引入新的问题或性能下降。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
SSE部分和小于部分差异,防止
- 差异检测逻辑:
在使用SSE指令集进行图像处理时,保持一致性非常重要。下面是一种方法,可以使SSE循环和非SSE循环的逻辑保持一致。
差异检测逻辑的统一:
- 定义_x80的用途: _x80 应该是一个常量,其值是 128 (即 0x80 in hexadecimal),它用于将无符号整数转换为有符号整数,反之亦然。这样可以使得原本的 0..255 范围的无符号字节变为 -128..127 的有符号字节。
- 在非SSE循环中应用相同的转换: 为了使非SSE循环与SSE循环保持一致,您需要在处理之前将无符号字节转换为有符号字节。
修改后的非SSE循环部分可以是:
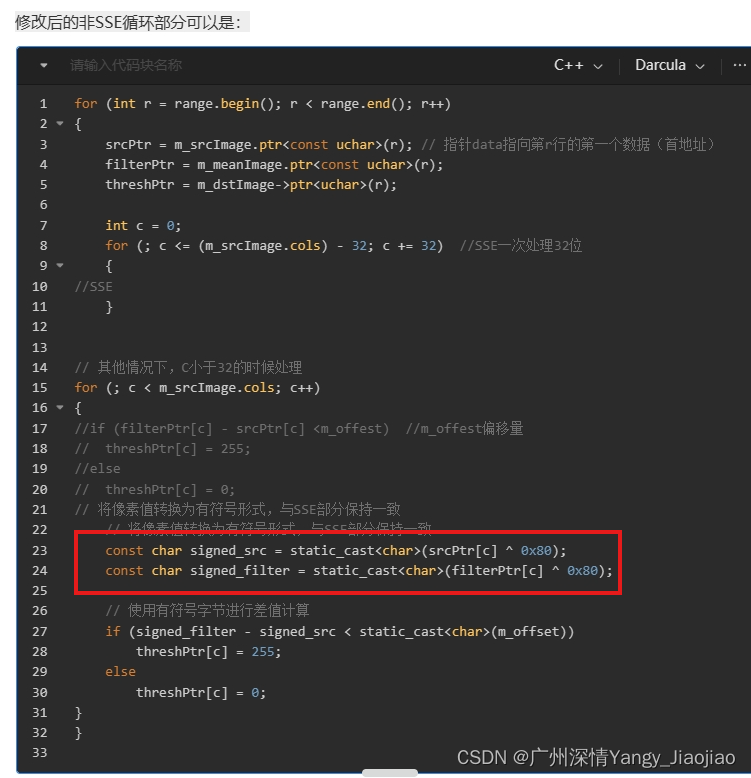
// 其他情况下,C小于32的时候处理
for (; c < m_srcImage.cols; c++)
{
//if (filterPtr[c] - srcPtr[c] <m_offest) //m_offest偏移量
// threshPtr[c] = 255;
//else
// threshPtr[c] = 0;
// 将像素值转换为有符号形式,与SSE部分保持一致
// 将像素值转换为有符号形式,与SSE部分保持一致
const char signed_src = static_cast<char>(srcPtr[c] ^ 0x80);
const char signed_filter = static_cast<char>(filterPtr[c] ^ 0x80);
// 使用有符号字节进行差值计算
if (signed_filter - signed_src < static_cast<char>(m_offset))
threshPtr[c] = 255;
else
threshPtr[c] = 0;
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









