






最近的DeepSeek-R1模型,在全球范围内掀起一波浪潮,在海外技术论坛引发轰动,甚至有人将它称为最强开源大模型
黑神话悟空的CEO称**“DeepSeek可能是个国运级别的科技成果”,**我们在这就不过多赘述DeepSeek-r1的能力了,
最近由于deepseek的爆火以及不限量管饱的访问,导致全球数以亿计的并发涌入,有点招架不住了,可能会短时间出现了这个聊崩的场面。

”主播主播有没有办法可以把这样功能强大的模型“搬回家”,在自己的电脑上直接运行?“
”有的有的,像这样强的模型有九个“
- DeepSeek-R1-Distill-Qwen-1.5B
- DeepSeek-R1-Distill-Qwen-7B
- DeepSeek-R1-Distill-Llama-8B
- DeepSeek-R1-Distill-Qwen-14B
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Distill-Llama-70B
- DeepSeek-R1-Zero
- DeepSeek-R1
- DeepSeek-R1-Distill
作为开源模型,我们完全可以在自己本地部署一个自己的deepseek-R1(当然是量化后的版本,否则消费级显卡无法承受),
deepseek-r1可能是目前当之无愧的开源模型之王,本地部署,解决了以前开源模型能力不足问题,同时保证了稳定的回复以及信息私密性
接下来,将会用小白都看得懂的教程来完成deepseek-r1的本地部署和使用(文末有deepseek优秀提示词分享)
部署准备工作
在开始部署之前,我们需要了解一些基础知识:
硬件要求
- 显卡配置是关键因素
- 不同型号对应不同显存需求
- 建议使用4GB以上显存的显卡
软件准备
- Ollama运行环境
- 合适的用户界面(UI)
- 稳定的网络环境
详细部署步骤
1、下载ollama
www.ollama.com
选择适合自己的版本,这里我以windows为例
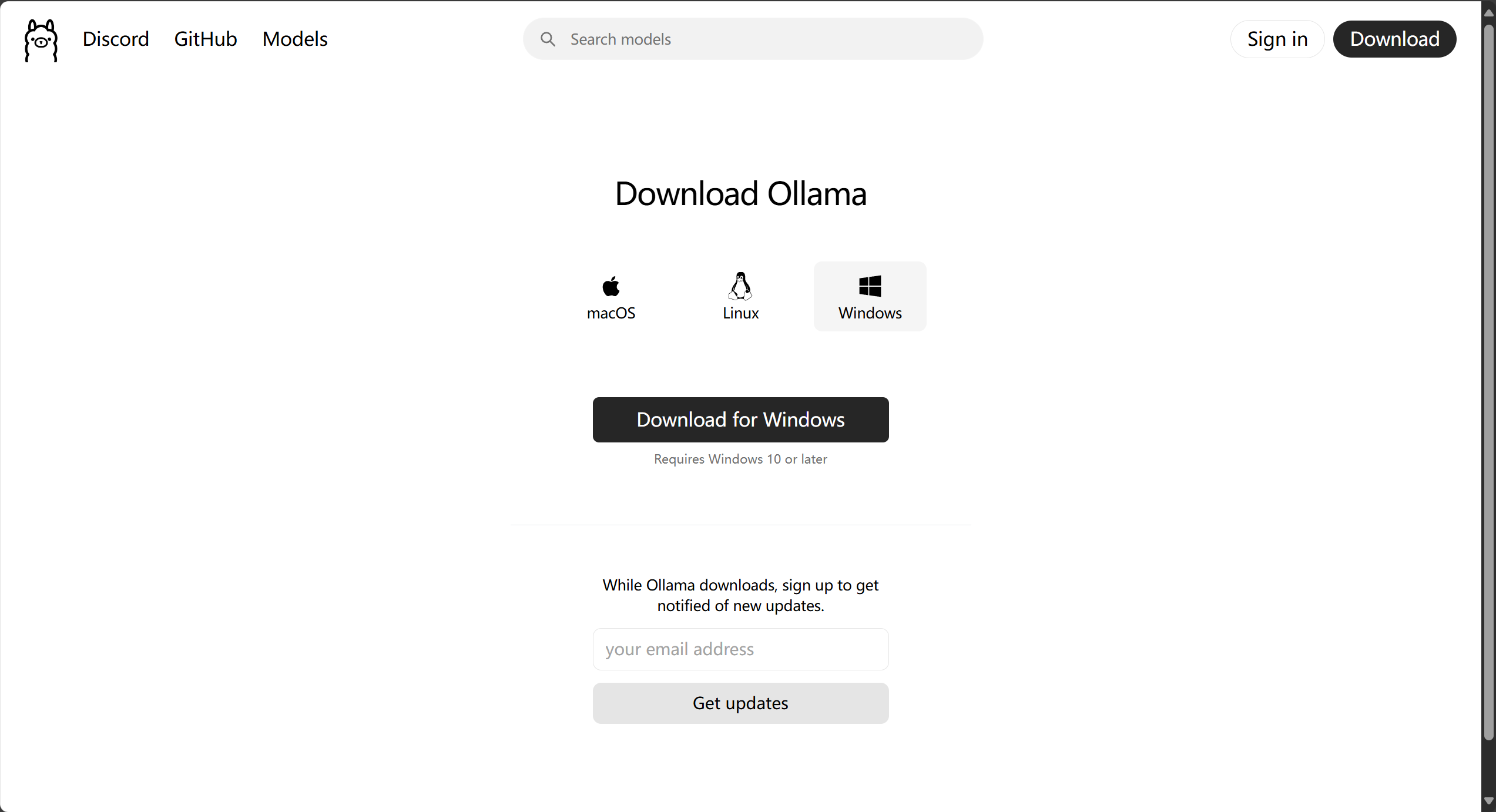
2、拉取deepseek-r1模型
模型参考
这里给一张表,根据量化之后的大小,以及适配的显存和消费级显卡,供大家参考
| 模型名称 | 显存需求 | 显卡推荐 |
|---|---|---|
| DeepSeek-R1 1.5B | 约 1 GB | GTX 1050 及以上 |
| DeepSeek-R1 7B | 约 4 GB | RTX 3060 及以上 |
| DeepSeek-R1 8B | 约 4.5 GB | RTX 3070 及以上 |
| DeepSeek-R1 14B | 约 8 GB | RTX 4070 及以上 |
| DeepSeek-R1 32B | 约 18 GB | RTX 4080 及以上 |
| DeepSeek-R1 70B | 约 40 GB | RTX 4090 或 A100 |
说明:
- 显存需求:基于 4-bit 量化模型的显存需求。
- 显卡推荐:根据显存需求和显卡性能推荐的显卡型号。
- 适用性:
- 资源有限的用户:推荐使用 1.5B 或 7B 模型,它们可以在单张消费级显卡上运行。
- 需要更高性能的用户:可以选择 14B 或 32B 模型,但需要多 GPU 配置。
- 高端计算环境:70B 模型适合高端计算环境,需要多张高端 GPU 支持。
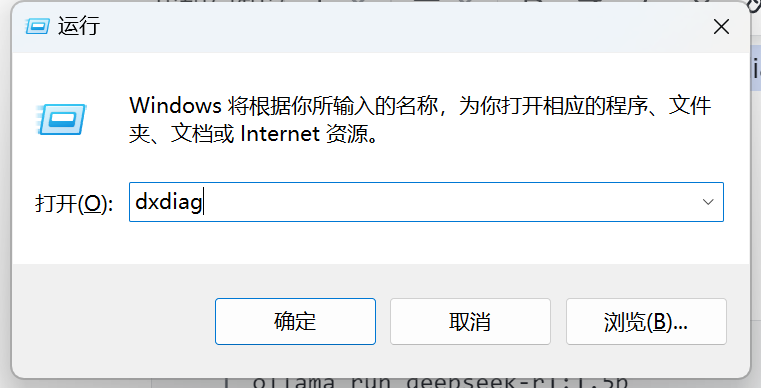
如何查看自己电脑的显存
我如何知道自己电脑的显存大小or显卡配置
按下Win+R组合键,打开运行对话框,输入“dxdiag”并回车。在DirectX诊断工具窗口中,点击“显示”选项卡,即可查看显存信息。
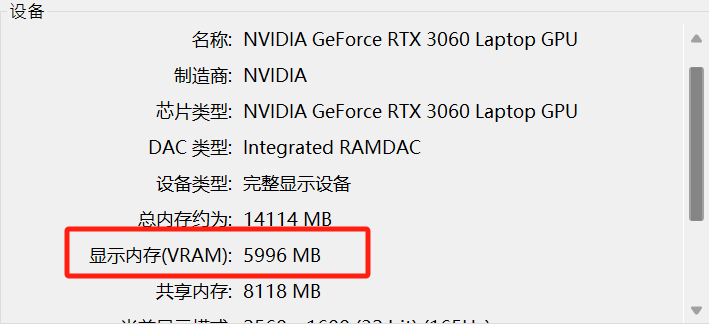
例如我的显存是6G,因此选择7B模型
**ollama run**** 命令:**
- 1.5B Qwen DeepSeek R1:
ollama run deepseek-r1:1.5b
- 7B Qwen DeepSeek R1:
ollama run deepseek-r1:7b
- 8B Llama DeepSeek R1:
ollama run deepseek-r1:8b
- 14B Qwen DeepSeek R1:
ollama run deepseek-r1:14b
- 32B Qwen DeepSeek R1:
ollama run deepseek-r1:32b
- 70B Llama DeepSeek R1:
ollama run deepseek-r1:70b
如果下载过慢要考虑科学上网,至此就可以正常于deepseek-r1 7B的量化版本对话了,
不过还是在终端上进行对话,
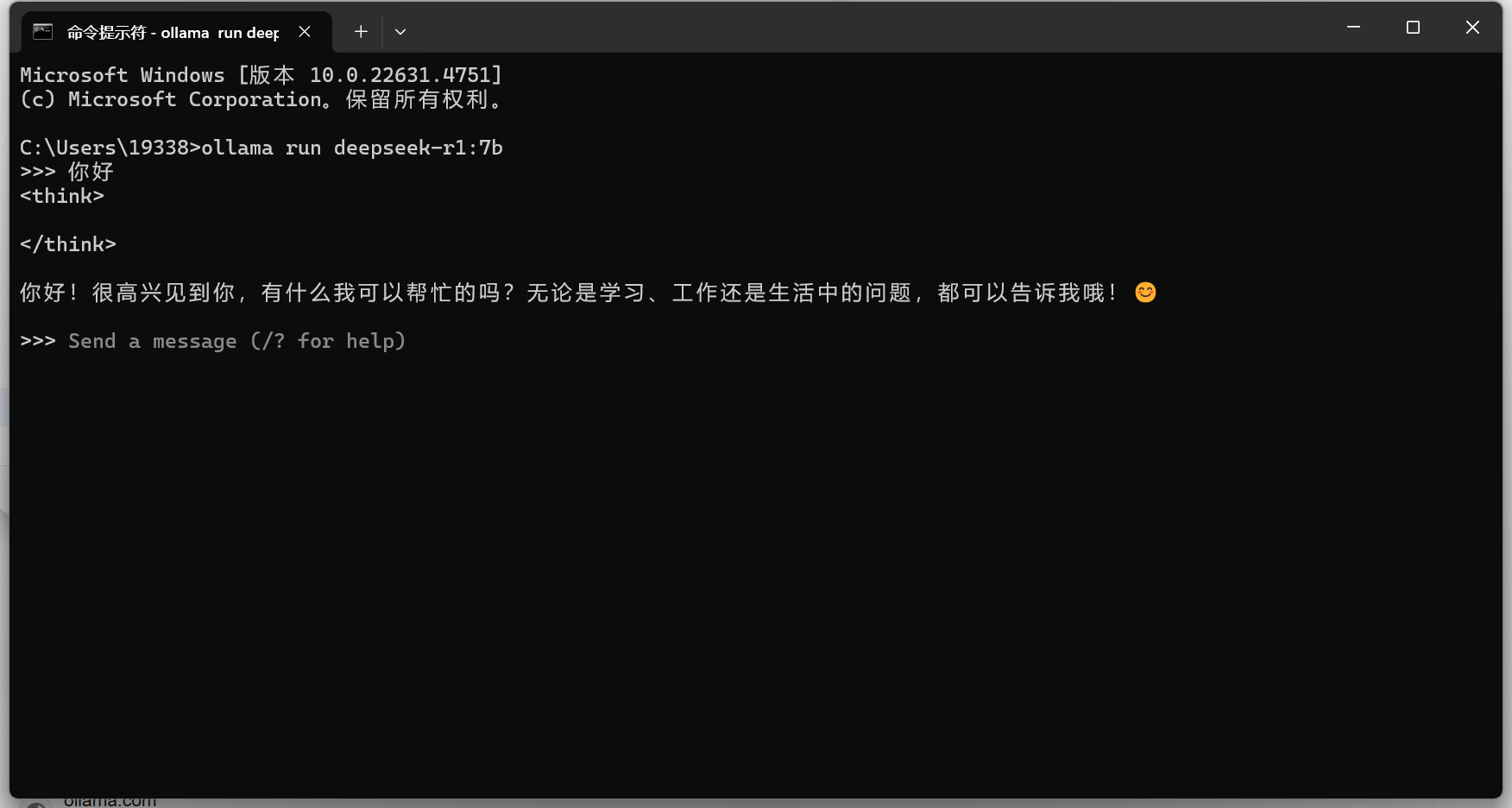
因此我们可以选择一个合适的对话UI
3、部署chat-UI
Page Assist(网页端)
- 便捷的浏览器插件
- 自动识别本地端口
- 操作简单直观
https://chromewebstore.google.com/detail/page-assist-%E6%9C%AC%E5%9C%B0-ai-%E6%A8%A1%E5%9E%8B%E7%9A%84-web/jfgfiigpkhlkbnfnbobbkinehhfdhndo
Chatbox(客户端)
- 功能更加全面
- 支持多种模型接入
- 配置灵活多样
https://chatboxai.app/zh
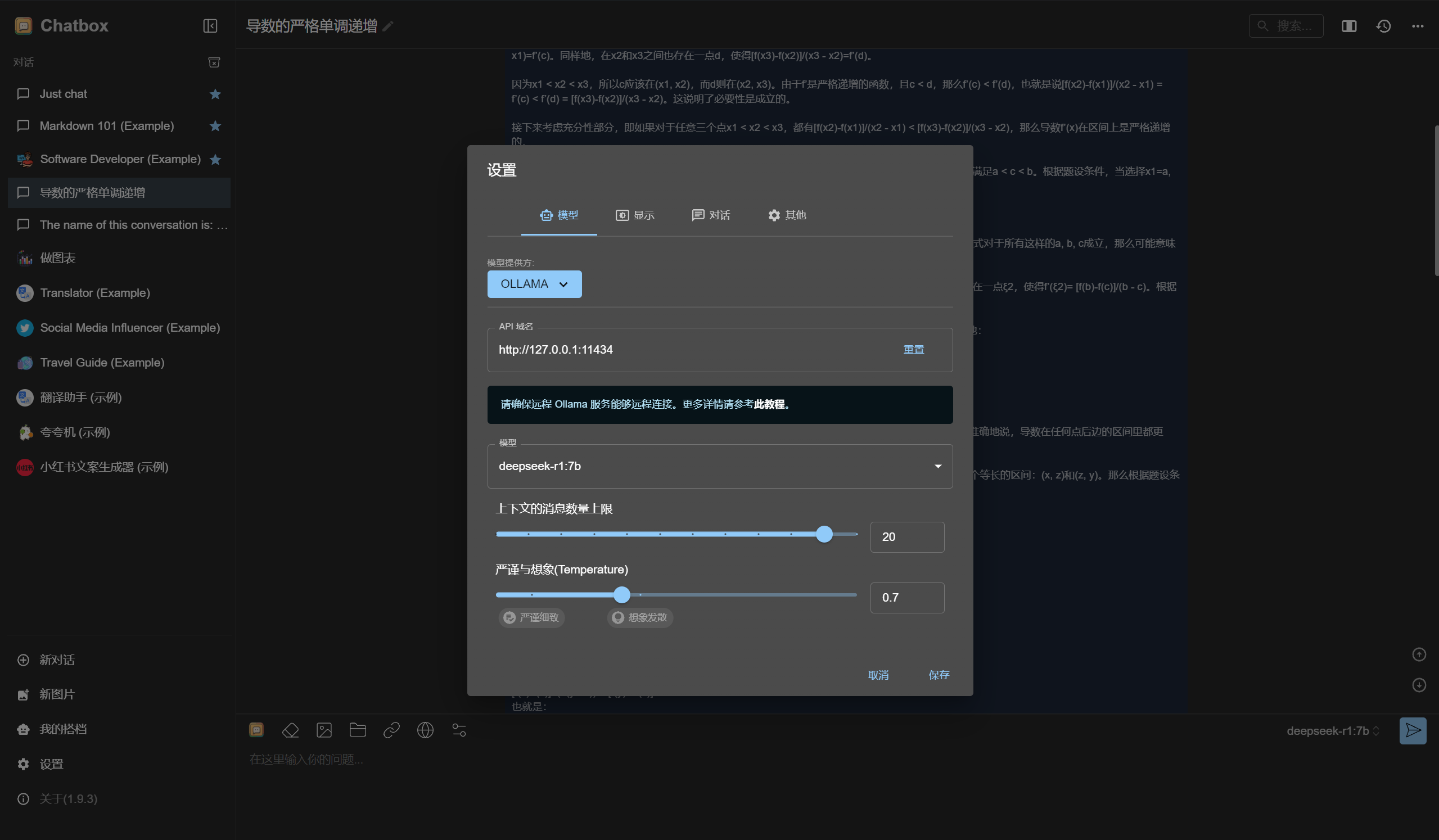
点击设置,选择OLLAMA作为模型提供方,默认API域名即可,如果失败则点击此教程
4、deepseek-r1交互技巧
使用技巧与优化 DeepSeek-R1的特点是注重推理过程和深度思考,建议:
- 提供清晰的上下文
- 循序渐进地提出问题
- 善用追问和引导
这里给大家分享WaytoAGI小伙伴们一起研究的内容,包括详解和实践指南
📚 收录了市面上比较代表性的文章
🌊 引发的现象(英伟达盘前跌幅14%)
🤖 系统提示词套出
📥 技术报告下载
👀 业界锐评(海内外的大V评论)
👤 创始人信息
附提示词使用技巧
总结展望 本地部署DeepSeek-R1不仅能解决稳定性问题,更能保证数据安全。随着技术的发展,相信会有更多优秀的开源模型供我们选择。
嗨,我是Yeadon!
一名人工智能专业的大三学生,正在努力成为AI时代的超级个体~
- 微信:Yeadon888
- 个人主页:Yeadon(伊登)的个人说明书
互动环节 欢迎在评论区分享您的部署经验和使用心得!如果遇到问题,也可以留言讨论。
文末温馨提示:建议收藏本文,方便日后查阅。如果觉得有帮助,别忘了点赞转发哦~

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









