









由于网上搜到关于汉明码矩阵计算的资料比较少,基本上都是(7,4)居多,有些还是用class定义的,感觉很不友好。现在就来补充一点资料吧。
1. 汉明码基础知识
关于汉明码手算基本过程,大家可以参考汉明码手算,对汉明码编码有一个大概了解
1.1 关于判断一个数2的N次幂
一个数如果是2的N次幂,那它的二进制必定只有一个1其余为0,要想判断一个数是否是2的N次幂,只需把这个数减1,然后按位与,判断结果是否为0。
用8来举例子

代码实现如下
if num & num-1 ==0: #Ture则为2的N次幂
1.2 list的index
本代码会涉及到很多list和汉明码位数的使用,list的index是从0开始,而汉明码第一位我们认为是1,所以两者相差了1,打代码要小心。
1.3 校验位,数据位,编码长度的关系
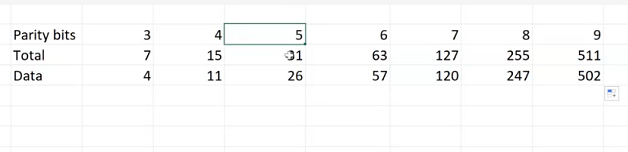
根据excel,我们可以看出他们之间的关系的规律,并得出如下式子
校验位 parity bit 这里简写成P

1.4 汉明码编码(7,4)例题

2.hammingcode(X,Y)实现
2.1计算位数
上面1.3讲过了,三个位数之间是有关系的,我们可以用代码来找,这里为了方便我的data用了4位方便学习,后续可自行改成任意长度
print("welcome to use the code made by Benni-Kang")
data='1101'
len_data=len(data)
Par_bits=0
while(len_data+1>2**Par_bits - Par_bits):
Par_bits+=1
print('Number of Parity Bits=',Par_bits)
2.2 创建G矩阵
2.2.1 创建H矩阵

这是把每一位的2进制写在下面表格,而且是倒着写 如1的二进制001,在这里就是从下往上写。把这个表格拿出来变成矩阵就是H

import numpy as np
import pandas as pd
column = []
j=-1
for i in range(1,total_bits+1): #1 /7
num =bin(i)
while num[j] != "b":
column+=num[j]
j-=1
j=-1
column = list(map(int,column))
if i==1:
col= pd.DataFrame(column,columns=['1'])
else:
column =pd.DataFrame(column,columns=[str(i)])
H_dataframe=pd.concat([col,column],axis=1)
col=H_dataframe
column=[]
H_dataframe.fillna(0,inplace=True)# 空缺补0
H_dataframe.index=H_dataframe.index+1 #从1开始索引
H_matrix = np.array(H_dataframe)
这里的datafame可以看成是一个表格,像excel,并不是矩阵,不过可以转换成矩阵来计算

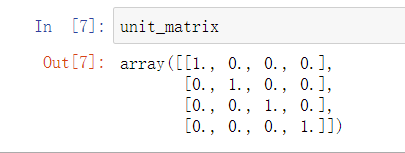
2.2.2创建单位矩阵
unit_matrix=np.eye(len_data)#创建单位矩阵
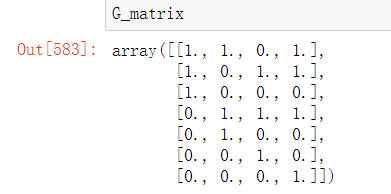
2.2.3创建G矩阵
把H的(1,2,4)列去掉,然后在新的矩阵的1,2,4行按顺序插入单位矩阵,就变成了G矩阵
for i in range(1,total_bits+1):
if i & i-1 == 0:
print(i)
H_dataframe.drop(str(i), axis=1,inplace=True)
g_matrix=H_dataframe

g_matrix是去除掉的,现在下面来插入
j=0
for i in range(1,total_bits+1):
if i & i-1 == 0:
# print("1111",i)
G_matrix=np.insert(unit_matrix, i-1, g_matrix.iloc[j], axis=0)
unit_matrix=G_matrix
# print(j)
# print(g_matrix.iloc[j])
j+=1
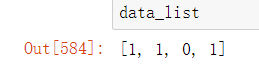
2.3把data变成list类型
这个没有什么好讲的…
data_list=[]
for char in data:
data_list.append(char)
data_list = list(map(int,data_list))
2.4矩阵乘
关于这个矩阵乘的线代计算,可以参考我的numpy学习笔记中2.3.2有提及具体的内容
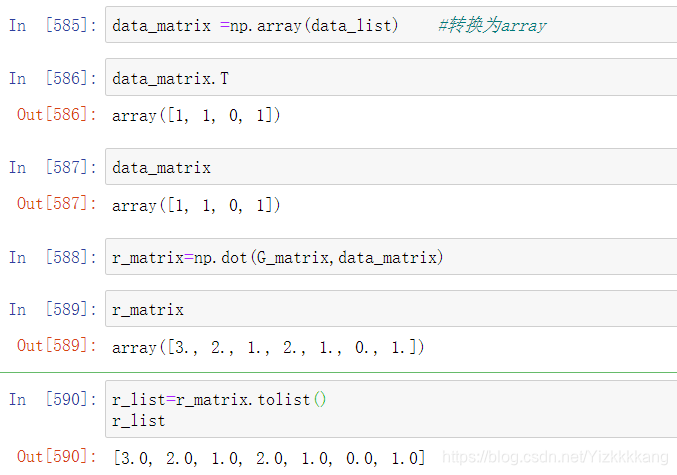
首先当然是转换成矩阵,一维矩阵转置在这里是没有意义的,所以列向量行向量都一样,然后我们把G和data两个矩阵相乘,然后在转换成list类型
data_matrix =np.array(data_list) #转换为array
r_matrix=np.dot(G_matrix,data_matrix)
r_list=r_matrix.tolist()
2.5求膜2
这里的意思就是计算出一个数的二进制的最小位
encode=[]
for num in r_list:
mod2 = num % 2
encode.append(int(mod2))
print("The encoded message is ",encode)
2.6产生误差
产生随机数,并翻转
import random
def flip_bit(message, location):
# This will flip the bit at position e-1 (0->1 and 1->0)
message[location] = 1 - message[location]
print("welcome to use the code made by Benni-Kang")
return message
def flip_random_bit(message):
e = random.randint(1, len(message))
print("Flipping bit (=introducing error) at location: " + str(e))
# This will flip the bit at position e-1 (0->1 and 1->0)
message = flip_bit(message, e-1)
return message
2.7 纠错
纠错就是,拿H矩阵和encoded的矩阵相乘之后如果没错,结果为0,如果有错,结果为错误的位数,而且这里的二进制要倒着写,最高位是H0,最低位反而是Hn(n为校验位个数)

reveiver_message_matrix =np.array(reveiver_message)
Pc=np.dot(H_matrix,reveiver_message_matrix)
Pc_list=Pc.tolist()
print(Pc_list)
receive_bits=[]
for num in Pc_list:
mod2 = num % 2
receive_bits.append(int(mod2))
bi_to_di=''
for i in range(1,len(receive_bits)+1):
bi_to_di+= str(receive_bits[-i])
error_position= int(bi_to_di,2)
if error_position!=0:
message=flip_bit(reveiver_message, error_position-1)
print(message)
3.其他有意思的方法
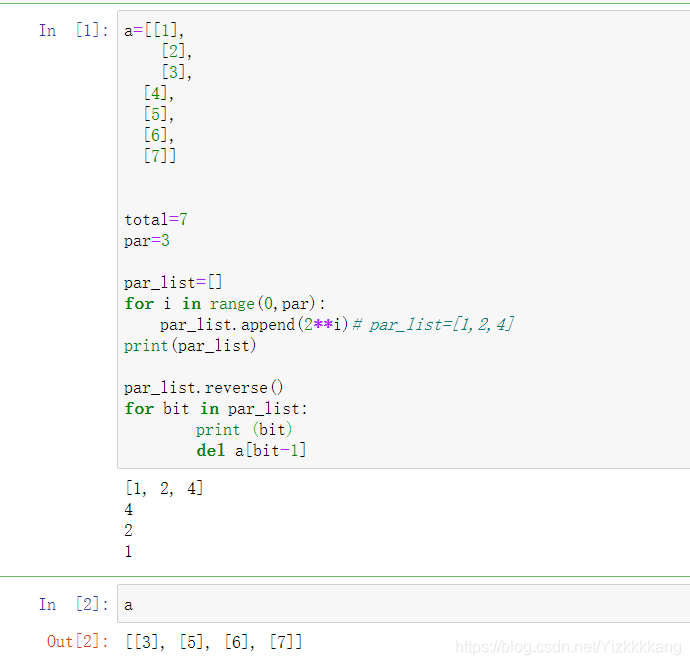
这里用到的方法都是array类型,也有用list做出来同样效果的,比如直接用去掉124位的H和data直接乘,就变成校验位,然后再把校验位插入数据的list就变成了encode message。我这里举些代码例子,只是为了演示想法,不是本体具体解法。
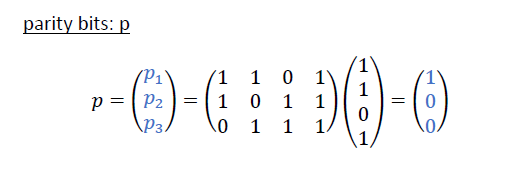
由于删除1,2,4位会导致list的删改,所以我们要用到reserve()函数,从高位开始删除,这样就不会造成错误,可以自行删除看会发生什么
删除list中的1,2,4位代码举例如下:
插入的代码如下
















 1544
1544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









