






作者丨柒柒@知乎
来源丨https://zhuanlan.zhihu.com/p/401698493
编辑丨3D视觉工坊
论文标题:LIGA-Stereo: Learning LiDAR Geometry Aware Representations for Stereo-based 3D Detector
作者单位:CUHK-SenseTime Joint Laboratory 等
代码:https://github.com/xy-guo/LIGA-Stereo
论文:https://xy-guo.github.io/liga/liga-guo-iccv21.pdf
一句话读论文:
利用Lidar-based detector指导Stereo-based detector。
作者的观点:
1. Stereo-based detector的优缺点是?Stereo-based detector是从stereo images中预测3D物体的方法。
a)优点:此类方法使用深度相机就可以,因此成本较低,部署方便。
Compared with LiDAR sensors, stereo cameras are at a much lower cost and higher resolutions, which makes it a suitable alternative solution for 3D perception.
b)缺点:深度估计误差会对其检测精度产生较大影响。
However, its performance is still inferior compared LiDAR-based algorithms. High-level features learned by stereo-based detectors are easily affected by the erroneous depth estimation due to the limitation of stereo matching.
2. Lidar-based detector的优缺点是?Lidar-based detector是从point clouds中预测3D物体的方法。
a)优点:此类方法可以有效提取3D物体的几何信息。
LiDAR-based detection algorithms take raw point cloud as inputs and then encode the 3D geometry information into intermediate and high-level feature representations. To detect and localize accurate 3D bounding boxes, the model must learn robust local features about object boundaries and surface normal directions, which are essential for predicting accurate bounding box size and orientation.
b)缺点:效率低,成本高。
The high cost of LiDAR sensors has limited its applications in low-cost products.
由以上两种方法的对比不难看出,Stereo-based和Lidar-based detector各有优劣,那么自然而然就会思考,如何结合两者优点呢?作者的思路是:利用Lidar-based detector引导Stereo-based detector学习到更多的几何信息,以此保证检测效率的同时提高检测精度。
3. 这种做法其实与知识蒸馏(knowledge distillation)模型有一些相似。但是作者认为传统知识蒸馏方法并不是很适用于3D检测任务,主要原因是不精确的定位结果会限制检测器的准确率上限。
Comparing with traditional knowledge distillation for recognition tasks, we did not take the final erroneous classification and regression predictions from the LiDAR model as "soft" targets, which we found benefits little for training stereo detection networks. The erroneous regression targets would constrain the upper-bound accuracy of bounding box regression.
这句话怎么理解呢?我们先想清楚一点,如果利用传统的知识蒸馏方法,Lidar-based detector是怎么引导stereo-based detector的呢?其实是将Lidar-based detector的检测结果做为soft label用于训练stereo-based detector。那么,stereo-based detector的准确率上界自然而然会逼近与lidar-based detector的检测结果。此时,如果lidar-based detector提供了错误的检测结果,stereo-based detector自然学习到了错误的物体特征。
因此,在Lidar-based detector引导stereo-based detector的过程中,这个"引导"并不是在检测结果层面的,而是在中间特征层面的。
至此,作者的思路就很清晰了,归纳起来就是:如何让Lidar-based detector引导stereo-based detector学习到更多的几何特征?具体地,网络框架流程可以理解为两个分支:
第一个Stereo images分支:
输入stereo image → 3D空间特征 → bird view特征 → 检测结果。
第二个Lidar points分支:
输入点云数据 → 3D空间特征 → brid view特征 → 检测结果。
这两个分支怎么一致呢?bird view特征一致性约束(imitation loss),如下图:
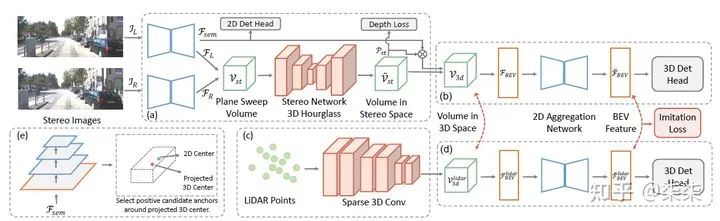
整体框架图
我们先介绍一下整个框架主体步骤,共三步:
第一步,stereo images → 检测结果。简单说就是输入双目图像,如何得到对应的3D特征?作者使用的框架是Deep Stereo Geometry Network (DSGN),对于2D图像上的每一个坐标点,级联其双目图特征,并映射到对应的3D空间即可。得到了3D空间特征,再按照传统的3D检测方法提取BEV feature,输出检测结果。
Given a left-right image pair and their features, a plane-sweep volume is constructed by concatenating left features and corresponding right features for every candidate depth level.
第二步,lidar points → 检测结果。简单说就是输入点云数据,如何得到3D检测结果?作者使用了SECOND网络,很通用的方法,这里不过多介绍了。
Inspired by the above observation, we propose to guide the training of stereo-based detectors using the high-level geometry-aware features from LiDAR models. In this paper, we utilize SECOND as our LiDAR "teacher".
第三步,特征一致性约束。这一步是比较关键的,在一定程度上决定了lidar是否可以有效引导stereo feature的提取。作者是通过BEV feature的损失函数约束,强制性最小化stereo feature及其对应的lidar feature。
Our imitation loss aims at minimizing the feature distances between stereo feature and its corresponding LiDAR feature.
具体公式是:
其实就是计算了stereo feature和lidar feature的欧式距离,只需要注意的是只计算前景点的一致性,背景点并不会考虑在内。
主体就是以上内容,还有一些细节点:比如2D和3D映射过程中的不一致性(Improving Semantic Features by Direct 2D Supervisions),损失函数的改进等,比较简单就不一一介绍了(Modifications to Baseline and Training Losses)。
备注:感谢微信公众号「3D视觉工坊」整理。
实验结果:
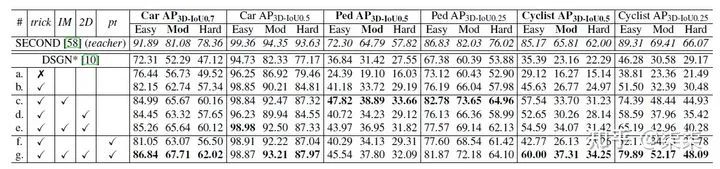
KITTI 验证集实验结果
从结果上看:
第一,特征的一致性约束提升最大,也就是上表的IM模块。
第二,简单样本效果比复杂样本好很多,具体数据可以参照Car AP(3D IoU=0.7) Easy和Hard子集。
第三,Car的准确率比Pedestrian/Cyclist好很多,我猜测是因为人或者人骑车的特征本身就不是很充分,那么通过IM也就是特征一致性模块来约束并不能取得很好的效果。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术
2.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
3.国内首个面向工业级实战的点云处理课程
4.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
5.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
6.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
7.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
干货领取:
1. 在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
2. 在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
3. 在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列三维点云系列结构光系列、手眼标定、相机标定、orb-slam3知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 

















 6988
6988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









