







 本文研究了对比学习方法在遥感图像中的应用,发现现有方法与监督学习存在差距。为此,提出了一种新的自监督学习框架,利用遥感图像的时空结构和地理位置信息。通过构建时间正对和地理定位前置任务,提高了无监督学习在图像分类、目标检测和语义分割等任务上的性能。实验表明,这种方法在fMoW和GeoImageNet数据集上显著优于标准对比学习方法和监督学习方法。
本文研究了对比学习方法在遥感图像中的应用,发现现有方法与监督学习存在差距。为此,提出了一种新的自监督学习框架,利用遥感图像的时空结构和地理位置信息。通过构建时间正对和地理定位前置任务,提高了无监督学习在图像分类、目标检测和语义分割等任务上的性能。实验表明,这种方法在fMoW和GeoImageNet数据集上显著优于标准对比学习方法和监督学习方法。
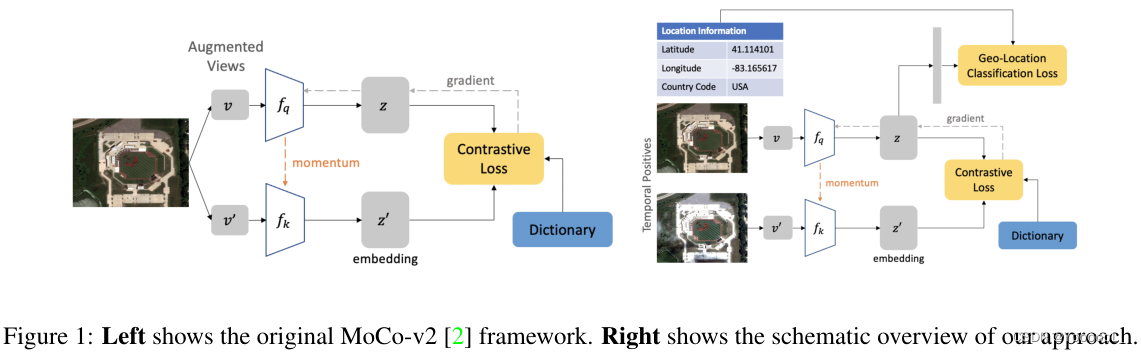
对比学习方法在计算机视觉任务上显著 缩小了有监督学习和无监督学习之间的差距。在本文中,探讨了它们 在地理定位数据集上的应用,例如遥感,其中未标记的数据通常很丰富,但标记的数据很少。本文首先表明,由于它们的不同特点,在标准基准上的对比学习 和 监督学习之间存在着不小的差距。为了缩小差距,本文提出了 利用 遥感数据 时空结构 的新训练方法。
本文利用 随着时间 空间对齐的图像 在对比学习中构建 时间正对,和利用 地理位置 来设计前置任务。实验表明,本文提出的方法 缩小了对比学习和监督学习在图像分类、目标检测 和 遥感语义分割方面的差距。此外,本文证明了所提出的方法 也可以应用于 地理标记的 ImageNet 图像,从而提高各种任务的下游性能。
Introduction:
受自监督学习方法 [2, 12] 成功的启发,本文探索了它们在大规模遥感数据集(卫星图像)和地理标记自然图像数据集中的应用。最近的研究表明,自监督学习方法在传统计算机视觉数据集上的图像分类、目标检测 和 语义分割[20,9,12,2,1] 上表现得相当好,甚至比它们的监督学习方法更好。然而,尽管收集和标记遥感图像的成本特别高,因为注释 通常需要 领域专业知识[33,15,4],但它们在遥感图像中的应用 在很大程度上尚未得到探索。
在这个方向上,本文首先 通过实验 评估 现有的自监督对比学习方法 MoCo-v2 [12] 在遥感数据集上的性能,发现与使用标签的监督学习的性能差距。例如,在 Functional Map of the World (fMoW) 图像分类基准 [4] 中,本文观察到 监督和自监督方法之间的 top 1 准确度存在 8% 的差距。
为了弥合这一差距,本文提出了 地理感知对比学习 来 利用遥感数据的时空结构。与典型的计算机视觉图像相比,遥感数据 通常是 地理定位的,并且 随着时间的推移 可能会提供同一位置的多个图像。对比方法 鼓励 可能在语义上相似的图像表示(正对)的接近性。与传统的 计算机视觉图像的对比学习 不同,其中同一图像的不同视图(增强)用作正对,本文建议 使用 随着时间的推移空间对齐的图像 的时间正对。
利用这些信息可以 使 表示 对随时间的细微变化(例如,由于季节性)保持不变。这反过来可以 为 关注空间变化的任务(例如 目标检测 或 语义分割)带来更多的判别特征(但不一定适用于涉及时间变化的任务,例如变化检测)。
此外,本文设计了一种新颖的无监督学习方法,该方法 利用了地理位置信息,即关于图像拍摄地点的知识。更具体地说,本文考虑了 预测图像 来自世界何处的 前置任务,类似于 [10, 11]。这可以通过 鼓励 反映地理信息的表示 来 补充 自监督学习方法 通常使用的信息论目标,这在遥感任务中通常很有用。
最后,本文将两种提出的方法 整合到 一个 地理感知对比学习目标中。
由 高空间分辨率卫星图像 组成的 functional Map of the World [4] 数据集上的实验表明,本文显著改进了 MoCo-v2 基线。特别是,在图像分类上测试学习表示时,本文将其分类准确率提高了 8%,目标检测上的 AP 提高了 2%,语义分割上的 mIoU 提高了 1%,土地覆盖分类的 top-1 准确率提高了 3%。有趣的是,本文的地理感知学习 甚至可以 在时间数据分类上 优于监督学习方法约 2%。
为了进一步证明本文的地理感知学习方法的有效性,使用类似于 [6] 的 FLICKR API 提取 ImageNet 图像的地理位置信息,它为我们提供了 543,435 个地理标记的 ImageNet 图像的子集。本文将提出的方法扩展到 地理定位的 ImageNet,并表明 地理感知学习 可以将 MoCo-v2 在图像分类上的性能提高 2%,表明本文的方法 在任何地理标记数据集上的潜在应用。图 1 详细显示了本文的贡献。
Related Work:
自监督方法使用未标记的数据来学习可迁移到下游任务(例如图像分类、目标检测、语义分割)的表示。两种常见的自监督方法是 前置任务 和 对比学习。
前置任务:
当数据标签不可用时,基于前置任务的学习 [21、35、28、42、37、27] 可用于学习特征表示。 [8]旋转图像,然后训练模型来预测旋转角度。 [41] 训练网络对灰度图像进行着色。 [25] 将图像表示为网格,对网格进行排列,然后预测排列索引。本文 使用 地理定位分类 作为前置任务,以此 训练一个深度网络 来预测图像可能来自世界何处的粗略地理位置。
对比学习:
最近的自监督对比学习方法,如 MoCo [12]、MoCo-v2 [2]、SimCLR [1]、PIRL [21] 和 FixMatch [30] 已展示出卓越的性能,并已成为各种下游任务的先行者。这些方法背后的直觉是 通过 在隐空间中 将来自同一实例的正图像对拉得更近,同时将来自不同实例的负图像对推得更远来学习表示。另一方面,这些方法 在对比损失的类型、正负对的生成 和 采样方法上有所不同。
尽管在自监督学习领域发展迅速,但 对比学习方法尚未在大规模遥感数据集上进行探索。本文提供了一种有原则且有效的方法,用于 改进 使用 MoCo-v2 [12] 用于 遥感数据 以及地理定位的常规数据集的表示学习。
遥感图像中的无监督学习:
与传统的计算机视觉领域不同,遥感领域的无监督学习尚未得到全面研究。大多数研究使用 特定于一个小的地理区域 [3, 16, 29, 14, 18],一些类别 [24] 或 高度特定的模态,即高光谱图像 [22, 40] 的 小规模数据集。这些研究大多集中在 UCM-21 数据集 [39] 上,该数据集包含来自 21 个类别的不到 1,000 张图像。最近的一项研究 [33] 提出了使用 由 卫星图像 和 配对的地理定位维基百科文章 组成的多模态数据集 的大规模弱监督学习。这种方法虽然有效,但需要将每张卫星图像与其对应的文章配对,从而 限制了可以使用的图像数量。
地理感知的 计算机视觉:
地理定位数据 已在先前的工作中进行了广泛的研究。这些研究中的大多数 利用图像的地理位置 作为先验,以提高图像识别的准确性[31
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









