






二叉树
1、纲领篇
基于labuladong的算法网站,东哥带你刷二叉树(纲领篇)
(1)概述
二叉树的问题基本上可以分解成两类:
- 遍历:
- 能否通过遍历一遍二叉树得到答案?
- 如果可以,用一个traverse函数配合外部变量来实现;
- 分解问题:
- 能否定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案?
- 如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值;
无论那种问题类型,都需要思考,如果单独抽出一个二叉树节点,这个节点需要做什么事情?需要在什么时候(前、中、后序位置)做?
(2)二叉树的重要性
快速排序是二叉树的前序遍历:
快速排序的逻辑是,若要对 nums[lo…hi] 进行排序,我们先找一个分界点 p,通过交换元素使得 nums[lo…p-1] 都小于等于 nums[p],且 nums[p+1…hi] 都大于 nums[p],然后递归地去 nums[lo…p-1] 和 nums[p+1…hi] 中寻找新的分界点,最后整个数组就被排序了。
void sort(int[] nums, int lo, int hi) {
/****** 前序遍历位置 ******/
// 通过交换元素构建分界点 p
int p = partition(nums, lo, hi);
/************************/
sort(nums, lo, p - 1);
sort(nums, p + 1, hi);
}
归并排序是二叉树的后序遍历:
归并排序的逻辑,若要对 nums[lo…hi] 进行排序,我们先对 nums[lo…mid] 排序,再对 nums[mid+1…hi] 排序,最后把这两个有序的子数组合并,整个数组就排好序了。
// 定义:排序 nums[lo..hi]
void sort(int[] nums, int lo, int hi) {
int mid = (lo + hi) / 2;
// 排序 nums[lo..mid]
sort(nums, lo, mid);
// 排序 nums[mid+1..hi]
sort(nums, mid + 1, hi);
/****** 后序位置 ******/
// 合并 nums[lo..mid] 和 nums[mid+1..hi]
merge(nums, lo, mid, hi);
/*********************/
}
(3)深入理解前中后序
二叉树遍历的框架:
void traverse(TreeNode root) {
if (root == null) {
return;
}
// 前序位置
traverse(root.left);
// 中序位置
traverse(root.right);
// 后序位置
}
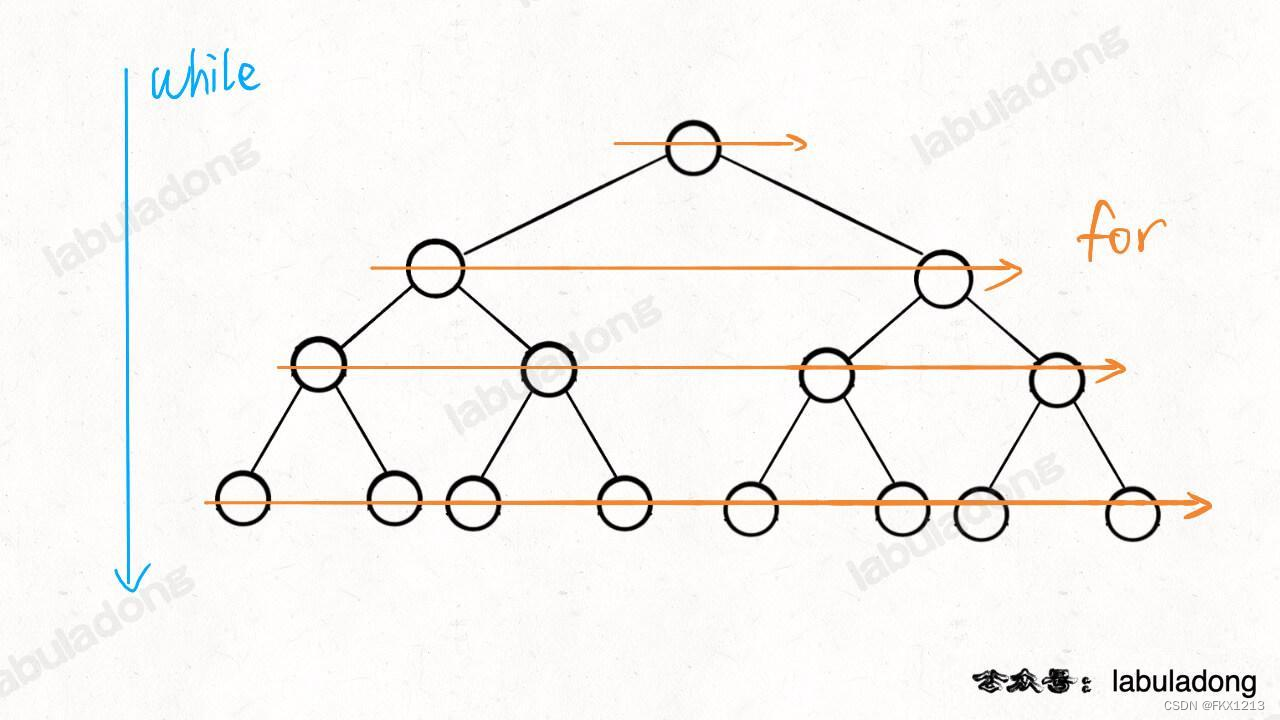
单看traverse函数,前序位置就是刚进入一个节点得到时候,后序位置就是即将离开一个节点的时候,中序位置就是遍历完该节点左子树,即将开始遍历右子树的时候。
数组和链表都可以递归遍历:
/* 递归遍历数组 */
void traverse(int[] arr, int i) {
if (i == arr.length) {
return;
}
// 前序位置
traverse(arr, i + 1);
// 后序位置
}
/* 递归遍历单链表 */
void traverse(ListNode head) {
if (head == null) {
return;
}
// 前序位置
traverse(head.next);
// 后序位置
}
(4)两种解题思路
力扣第104题,二叉树的最大深度,此题可以采用两种解题思路做;
- 遍历:
- 遍历一遍二叉树,用一个外部变量记录每个节点所在的深度,取最大值就可以得到最大深度;
[104]二叉树的最大深度
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int maxDepth(TreeNode root) {
traverse(root);
return res;
}
int res = 0;// 返回的结果,记录最大深度
int depth = 0;// 到达该节点时的深度
void traverse(TreeNode root) {
// base case 如果到达的节点为空节点,就直接返回
if (root == null) {
return;
}
// 进入一个节点时候,就让该节点的深度+1
depth++;
// 是否需要更新返回的结果
if (root.left == null && root.right == null) {
res = Math.max(res, depth);
}
// 递归调用左子树和右子树
traverse(root.left);
traverse(root.right);
// 离开这个节点时候,就需要还原该节点的深度
depth--;
}
}
- 分解子问题
- 返回以root为根节点的最大深度
class Solution {
// 该递归函数的意思是以root为根节点的二叉树的最大深度
public int maxDepth(TreeNode root) {
// base case 如果节点为空,深度就为0
if (root == null) {
return 0;
}
int leftDepth = maxDepth(root.left);// 左子树的最大深度
int rightDepth = maxDepth(root.right);// 右子树的最大深度
int res = Math.max(leftDepth, rightDepth) + 1;
return res;
}
}
总结:遇到一个二叉树的问题的通用思考过程为:
- 能否一遍遍历完二叉树后,得到结果?(traverse函数配上一个外部变量);
- 是否可以定义一个递归函数,通过子树的答案得到原问题的答案?(写出递归函数的定义,充分利用递归函数的返回值);
(5)前中后序的特别之处
前序位置的代码执行是自顶向下的,而后序位置的代码是自底向上的;意味着前序位置的代码只能从函数参数中获取父节点传递来的数据,而后序位置的代码还可以获取到子树通过函数返回值传递回来的数据。
一旦题目和子树有关,大概率就需要给函数设置合理的定义和返回值了,在后序位置写代码。
比如力扣第543题,二叉树的直径;结果和子树的结果有关,需要在后序位置写代码:
class Solution {
public int diameterOfBinaryTree(TreeNode root) {
traverse(root);
return res;
}
int res = 0;// 定义一个变量作为结果返回值
// 该递归函数的返回值为以root为根节点的二叉树的深度
int traverse(TreeNode root) {
if (root == null) {
return 0;
}
int leftDepth = traverse(root.left);// 左子树的深度
int rightDepth = traverse(root.right);// 右子树的深度
// 得到左子树的深度和右子树的深度后更新结果
res = Math.max(res, leftDepth + rightDepth);
return Math.max(leftDepth, rightDepth) + 1;
}
}
(6)层序遍历
层序遍历的代码模板:
// 输入一棵二叉树的根节点,层序遍历这棵二叉树
void levelTraverse(TreeNode root) {
if (root == null) return;
Queue<TreeNode> q = new LinkedList<>();
q.offer(root);
// 从上到下遍历二叉树的每一层
while (!q.isEmpty()) {
int sz = q.size();
// 从左到右遍历每一层的每个节点
for (int i = 0; i < sz; i++) {
TreeNode cur = q.poll();
// 将下一层节点放入队列
if (cur.left != null) {
q.offer(cur.left);
}
if (cur.right != null) {
q.offer(cur.right);
}
}
}
}
2、思路篇
(1)翻转二叉树
力扣第226题,翻转二叉树
- 遍历:
[226]翻转二叉树
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
// 翻转以root为根节点的二叉树,并返回新的根节点
public TreeNode invertTree(TreeNode root) {
traverse(root);
// 返回该节点
return root;
}
// 遍历该二叉树,反转二叉树
void traverse(TreeNode root) {
if (root == null) {
return;
}
TreeNode left = root.left;
root.left = root.right;
root.right = left;
traverse(root.left);
traverse(root.right);
}
}
- 分解子问题:
class Solution {
// 翻转以root为根节点的二叉树,并返回新的根节点
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
// 翻转
TreeNode left = root.left;
root.left = invertTree(root.right);
root.right = invertTree(left);
// 返回该节点
return root;
}
}
(2)填充节点的右侧指针
力扣第116题,填充每个节点的下一个右侧节点指针
- 方法一:利用层序遍历的队列实现(但是不满足题目要求使用常量级的额外空间)
[116]填充每个节点的下一个右侧节点指针
/*
// Definition for a Node.
class Node {
public int val;
public Node left;
public Node right;
public Node next;
public Node() {}
public Node(int _val) {
val = _val;
}
public Node(int _val, Node _left, Node _right, Node _next) {
val = _val;
left = _left;
right = _right;
next = _next;
}
};
*/
class Solution {
// 借用层序遍历的方法
public Node connect(Node root) {
// 先行条件判断
if (root == null) {
return null;
}
LinkedList<Node> queue = new LinkedList<>();
queue.add(root);// 先将头节点加入队列中
// 判断条件
while (!queue.isEmpty()) {
// 先遍历队列中的元素,设置next指针
int size = queue.size();
Node node = queue.get(0);
for (int i = 1; i < size; i++) {
node.next = queue.get(i);
node = queue.get(i);
}
// 依次弹出队列中的元素后将子节点加入到队列中
for (int i = 0; i < size; i++) {
node = queue.remove();
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
}
return root;
}
}
- 方法二:可以通过已经设置好的next指针作为辅助
class Solution {
// 使用已经设置好的next指针作为辅助
public Node connect(Node root) {
// 前置条件过滤
if (root == null) {
return null;
}
// 定义指针方便遍历整个二叉树
Node pre = root;
while (pre.left != null) {
Node node = pre;
while (node != null) {
node.left.next = node.right;
if (node.next != null) {
node.right.next = node.next.left;
}
// 继续向右移动
node = node.next;
}
// 遍历下一层
pre = pre.left;
}
return root;
}
}
(3)将二叉树展开为链表
力扣第114题,二叉树展开为链表
class Solution {
// 该递归函数的意思为将root为根节点的二叉树展开为一个单链表,并且左子指针始终为null
public void flatten(TreeNode root) {
if (root == null) {
return;
}
// 调用递归函数,处理左子树和右子树,将左子树和右子树拉平
flatten(root.left);
flatten(root.right);
// 开始处理拉平后的操作
TreeNode left = root.left;
TreeNode right = root.right;
root.left = null;
root.right = left;
// 定义指针
TreeNode p = root;
while (p.right != null) {
p = p.right;
}
p.right = right;
}
}
3、构造篇
二叉树的构造一般都是使用分解问题的思路:构造整棵树=根节点+构造左子树+构造右子树;
(1)构造最大二叉树
力扣第654题,最大二叉树
[654]最大二叉树
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode constructMaximumBinaryTree(int[] nums) {
return build(nums, 0, nums.length - 1);
}
// 在nums数组中,下标为left到right中构建最大二叉树
TreeNode build(int[] nums, int left, int right) {
// base case 当left的下标大于right下标时,就返回空
if (left > right) {
return null;
}
// 找到数组中最大的元素,并记录下标
int index = left;
int max = nums[left];
for (int i = left + 1; i <= right; i++) {
if (nums[i] > max) {
index = i;
max = nums[i];
}
}
// 构建最大二叉树
TreeNode root = new TreeNode(max);
root.left = build(nums, left, index - 1);
root.right = build(nums, index + 1, right);
return root;
}
}
(2)通过前序和中序遍历结果构造二叉树
力扣第105题,从前序和中序遍历构造二叉树
[105]从前序与中序遍历序列构造二叉树
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode buildTree(int[] preorder, int[] inorder) {
// 遍历中序数组,将元素加入到数组中
for (int i = 0; i < inorder.length; i++) {
map.put(inorder[i], i);
}
return build(preorder, 0, preorder.length - 1,
inorder, 0, inorder.length - 1);
}
// 因为树中没有重复的元素,利用一个hashmap记录元素和其在中序遍历数组中的下标
Map<Integer, Integer> map = new HashMap<>();
// 在前序遍历和中序遍历数组中构建出二叉树返回根节点
TreeNode build(int[] preOrder, int preLeft, int preRight,
int[] inOrder, int inLeft, int inRight) {
// base case
if (preLeft > preRight) {
return null;
}
// 根节点为前序遍历的第一个元素
TreeNode root = new TreeNode(preOrder[preLeft]);
// 找到根节点在中序遍历数组中的元素下标位置
int index = map.get(preOrder[preLeft]);
root.left = build(preOrder, preLeft + 1, preLeft + index - inLeft,
inOrder, inLeft, index - 1);
root.right = build(preOrder, preLeft + index - inLeft + 1, preRight,
inOrder, index + 1, inRight);
return root;
}
}
(3)通过后序和中序遍历结果构造二叉树
力扣第106题,从中序和后序遍历序列构造二叉树
[106]从中序与后序遍历序列构造二叉树
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode buildTree(int[] inorder, int[] postorder) {
// 遍历中序数组将元素全部加入到map中
for (int i = 0; i < inorder.length; i++) {
map.put(inorder[i], i);
}
return build(inorder, 0, inorder.length - 1,
postorder, 0, postorder.length - 1);
}
// 元素不重复,利用map进行快速查询inorder
Map<Integer, Integer> map = new HashMap<>();
// 返回以inorder和postorder构造出来的二叉树的头节点
TreeNode build(int[] inorder, int inleft, int inright,
int[] postorder, int postleft, int postright) {
if (postleft > postright) {
return null;
}
// 通过后序遍历的数组的最后一个元素找到头节点
TreeNode root = new TreeNode(postorder[postright]);
// 在中序遍历数组中找到头节点元素的下标位置
int index = map.get(postorder[postright]);
root.left = build(inorder, inleft, index - 1,
postorder, postleft, postleft + index - inleft - 1);
root.right = build(inorder, index + 1, inright,
postorder, postleft + index - inleft, postright - 1);
return root;
}
}
(4)通过后序和前序遍历结果构造二叉树
力扣第889题,根据前序和后序遍历构造二叉树
[889]根据前序和后序遍历构造二叉树
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode constructFromPrePost(int[] preorder, int[] postorder) {
for (int i = 0; i < postorder.length; i++) {
map.put(postorder[i], i);
}
return build(preorder, 0, preorder.length - 1,
postorder, 0, postorder.length - 1);
}
// preorder是一个无重复值的前序遍历,利用map记录后序遍历的值和下标位置
Map<Integer, Integer> map = new HashMap<>();
TreeNode build(int[] preOrder, int preL, int preR,
int[] postOrder, int postL, int postR) {
// base case
if (preL > preR) {
return null;
}
if (preL == preR) {
return new TreeNode(preOrder[preL]);
}
// 根节点
int numRoot = preOrder[preL];
TreeNode root = new TreeNode(numRoot);
// 假设用前序遍历的第二个元素作为二叉树的左子树的根节点,找到该元素在后序遍历的下标
int numLeft = preOrder[preL + 1];
int index = map.get(numLeft);
// 左子树的元素个数
int size = index - postL + 1;
root.left = build(preOrder, preL + 1, preL + size,
postOrder, postL, index);
root.right = build(preOrder, preL + size + 1, preR,
postOrder, index + 1, postR - 1);
return root;
}
}
4、序列化篇
基于labuladong的算法网站,东哥带你刷二叉树(序列化篇)
力扣第297题,二叉树的序列化与反序列化
[297]二叉树的序列化与反序列化
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Codec {
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
if (root == null) {
return "";
}
// 按照层序遍历进行解题
StringBuilder sb = new StringBuilder();
LinkedList<TreeNode> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
if (node != null) {
sb.append(node.val).append(",");
queue.add(node.left);
queue.add(node.right);
} else {
sb.append("#,");
}
}
return sb.toString();
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
if (data == "") {
return null;
}
// 根据data按照 , 进行分割
String[] array = data.substring(0, data.length() - 1).split(",");
// 利用层序遍历的队列
LinkedList<TreeNode> queue = new LinkedList<>();
TreeNode root = new TreeNode(Integer.parseInt(array[0]));
queue.add(root);
int i = 1;
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
// 左子树
if (!"#".equals(array[i])) {
node.left = new TreeNode(Integer.parseInt(array[i]));
queue.add(node.left);
}
i++;
// 右子树
if (!"#".equals(array[i])) {
node.right = new TreeNode(Integer.parseInt(array[i]));
queue.add(node.right);
}
i++;
}
return root;
}
}
// Your Codec object will be instantiated and called as such:
// Codec ser = new Codec();
// Codec deser = new Codec();
// TreeNode ans = deser.deserialize(ser.serialize(root));
5、后续篇
基于labuladong的算法网站,东哥带你刷二叉树(后续篇)
一旦发现题目和子树有关,大概率需要给函数设置合理的定义和返回值,在后序位置写代码:
力扣第653题,寻找重复的子树
[652]寻找重复的子树
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<TreeNode> findDuplicateSubtrees(TreeNode root) {
traverse(root);
return res;
}
List<TreeNode> res = new LinkedList<>();// 记录的结果
HashMap<String, Integer> memo = new HashMap<>();// 记录该节点子树的遍历结果
// 返回以root为根节点的字符串结果,中序遍历
String traverse(TreeNode root) {
StringBuilder sb = new StringBuilder();
// base case
if (root == null) {
return "#";
}
String left = traverse(root.left);
String right = traverse(root.right);
sb.append(root.val).append("-");
sb.append(left).append(right);
String tree = sb.toString();
int frequency = memo.getOrDefault(tree, 0);
// 拿到该节点字符串的出现频率次数
if (frequency == 1) {
res.add(root);
}
memo.put(tree, frequency + 1);
return tree;
}
}














 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









