






一、Transformer
Transformer模型,无疑是大型语言模型的坚实基石,它开启了深度学习领域的新纪元。在早期阶段,循环神经网络(RNN)曾是处理序列数据的核心手段。尽管RNN及其变体在某些任务中展现出了卓越的性能,但在面对长序列时,它们却常常陷入梯度消失和模型退化的困境,令人难以攻克。为了解决这一技术瓶颈,Transformer模型应运而生,它如同黎明中的曙光,照亮了前行的道路。
随后,在2020年,OpenAI提出了举世闻名的“规模定律”,这一发现深刻揭示了模型性能与参数量、数据量以及训练时长之间呈现出令人惊异的指数级增长关系。在此背景下,研究人员纷纷将重心转向大型语言模型基座,基于Transformer的GPT、Bert等大模型在自然语言处理领域取得了令人瞩目的成就,它们如同璀璨的明星,照亮了人工智能的天空。
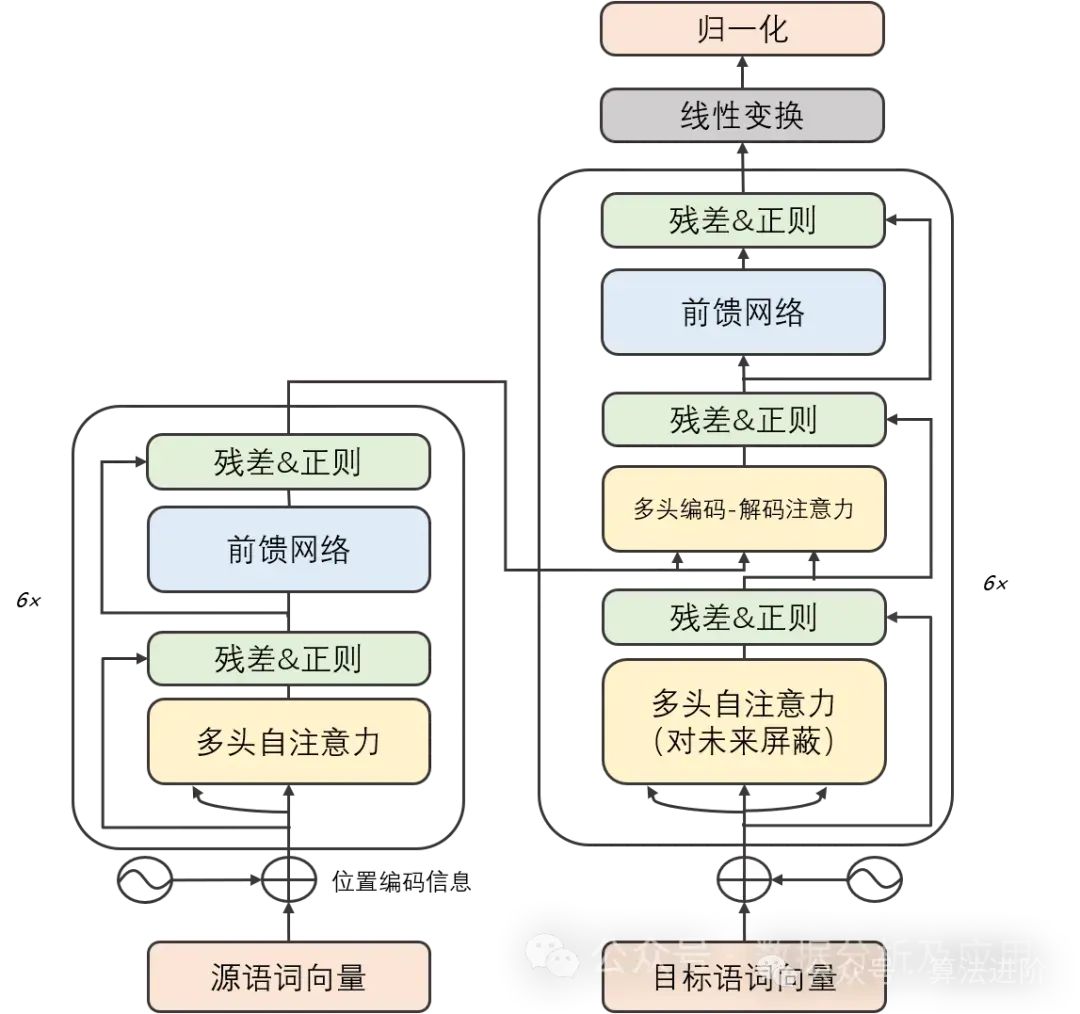
模型原理:
Transformer模型由编码器和解码器组成,由多个层堆叠而成,包含自注意力子层和线性前馈神经网络子层。自注意力子层生成输入序列位置的独特表示,线性前馈网络生成信息丰富的表示。编码器和解码器包含位置编码层以捕捉位置信息。
模型训练:
依赖反向传播和优化算法(如随机梯度下降)训练Transformer模型。通过计算损失函数梯度并调整权重以最小化损失。为提高速度和泛化能力,采用正则化和集成学习策略。
优点:
-
解决梯度消失和模型退化问题,捕捉长期依赖关系。
-
并行计算能力强,支持GPU加速。
-
在机器翻译、文本分类和语音识别等任务中表现优秀。
缺点:
-
计算资源需求高。
-
对初始权重敏感,可能训练不稳定或过拟合。
-
处理超长序列受限。
应用场景:
广泛应用于自然语言处理领域,如机器翻译、文本分类和生成。也应用于图像识别和语音识别等领域。
Python示例代码(简化版):
import torch
self.transformer_decoder = nn.TransformerDecoder(decoder_layers, num_decoder_layers)
self.decoder = nn.Linear(d_model, d_model)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
batch_size, tgt_len, tgt_vocab_size = tgt.size(0), tgt.size(1), self.decoder.out_features
src = self.pos_encoder(src)
output = self.transformer_encoder(src)
target_input = tgt[:, :-1].contiguous().view(batch_size * tgt_len, -1)
output2 = self.transformer_decoder(target_input, output).view(batch_size, tgt_len, -1)
prediction = self.decoder(output2).view(batch_size * tgt_len, tgt_vocab_size)
return prediction[:, -1], prediction
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1).float()```python
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
-(torch.log(torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
#超参数
d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward = 512, 8, 6, 6, 2048
#实例化模型
model = Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward)
#随机生成数据
src, tgt = torch.randn(10, 32, 512), torch.randn(10, 32, 512)
#前向传播
prediction, predictions = model(src, tgt)
print(prediction)

二、预训练技术
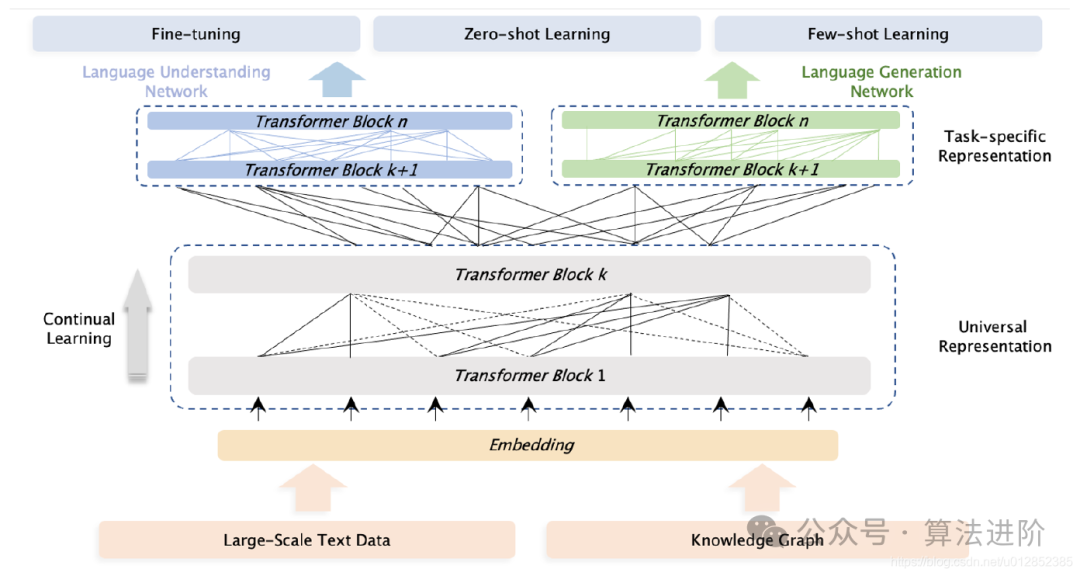
GPT可视为预训练范式,基于Transformer架构,通过大数据预训练学习通用特征,广泛应用于计算机视觉、自然语言处理等领域。
核心原理:大模型预训练技术通过海量数据提取语言知识和语义信息。预训练阶段,模型利用自注意力机制学习文本规律;微调阶段,通过有监督学习适应具体任务需求。
训练过程:包括数据收集与预处理、模型选择、预训练和微调。预训练使用无标签数据学习语言结构和语义;微调则针对具体任务使用有标签数据调整模型参数。
预训练技术作用:提升性能,通过学习更多语言知识提高准确率、泛化能力和鲁棒性;加速训练,提供准确初始权重,避免梯度问题,节省时间和资源;提高泛化能力,减少过拟合风险,适应不同任务和领域。
三、RLHF
RLHF,即基于人类反馈的强化学习,是一种独特的调优方法,旨在将强化学习与人类智慧深度融合,进而显著提升大模型在特定任务上的表现与可靠性。
这种方法精妙地运用人类的判断作为引导模型行为的奖励信号,使模型得以学习并内化更符合人类价值观的行为模式。在RLHF中,人类反馈的作用至关重要,它不仅能够提供对模型行为的直接反馈,还能帮助模型不断优化其决策过程。
RLHF的训练过程是一系列精心设计的步骤,包括预训练模型的选择与加载、监督微调、奖励模型训练以及近端策略优化等。这些步骤犹如一道道精细的工序,旨在让模型逐步学会如何根据人类的反馈精准调整其行为,从而使其输出更加贴近人类的期望与标准。
在大模型技术的广阔天地中,RLHF发挥着举足轻重的作用。它不仅能够提高模型的性能和可靠性,还能促进模型道德与人类价值观的对齐。通过强化学习与人类反馈的完美结合,RLHF使得模型能够更好地理解和适应特定任务的需求,同时有效减少因环境噪声或数据偏差导致的错误决策。此外,RLHF还能确保模型的行为始终遵循人类的道德标准,避免产生任何不当的输出或决策。
四、模型压缩
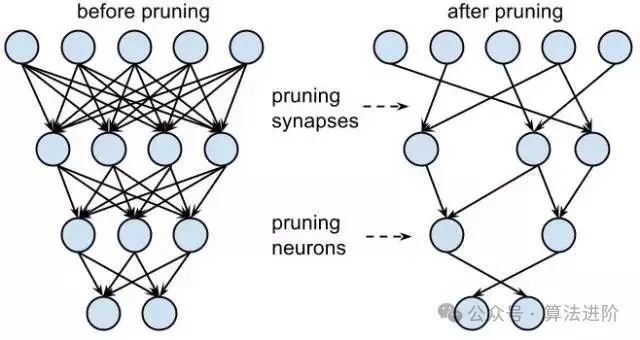
大模型压缩技术,诸如权重裁剪、量化和知识蒸馏等,不仅显著地减小了模型的大小,而且在优化性能方面展现出卓越的效果。其实践应用带来的积极影响主要有以下几个方面:
-
降低存储与计算负担: 模型压缩技术有效减少了所需的存储空间和计算资源,使模型更易于部署在各类受限设备上,同时显著提升了推理速度,为用户带来了更流畅的使用体验。
-
提高部署效率与便捷性: 经过简化的模型在跨设备部署和集成方面展现出更强的适应性,降低了部署的难度和成本,进一步拓宽了深度学习技术在各个领域的应用范围。
-
精准保持模型性能: 通过精心设计的压缩算法和训练策略,模型在压缩过程中性能得以有效保持。这使得模型压缩成为一种高效且实用的优化手段,在降低资源需求的同时确保性能不受影响。
模型压缩技术的核心目标是在保持性能的同时减小模型的大小,以适应不同计算设备的限制并提高部署速度。其主要技术手段包括:
-
权重裁剪: 通过对模型中不重要的权重进行精准识别和移除,有效降低了模型的冗余度,使模型更为紧凑且高效。
-
量化技术: 将原本使用的高精度浮点数参数转换为定点数或低精度浮点数,从而大幅减少模型的体积,降低存储和计算成本。
-
知识蒸馏: 借助大型教师模型向小型学生模型传授知识和经验,使学生在保持性能的同时大幅减小模型大小,实现了高效的知识传承与模型优化。
五、多模态融合
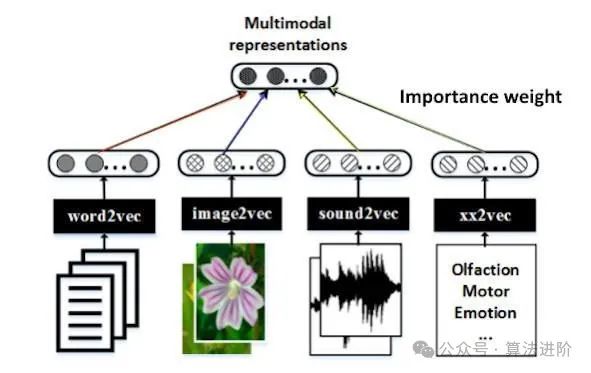
大模型的多模态融合技术通过有效融合各类模态的数据,极大地提升了模型的感知和理解能力,进而显著增强了其性能,并拓宽了应用范围。这一技术在多个领域中发挥着至关重要的作用:
-
优化模型性能: 多模态融合技术使得模型能够更深入地理解输入数据的内涵,从而显著提升其性能表现。无论是图像分类、语音识别,还是情感分析等复杂任务,这一优势均得到了充分的体现。
-
强化鲁棒性: 多模态数据具备更强的抗干扰能力,可以有效抵抗各类噪声和干扰因素。多模态融合技术的应用使得模型能够从不同角度获取信息,进一步增强了其对噪声和干扰的抵御能力,保证了数据的稳定输出。
-
拓展应用场景: 这一技术为模型处理更复杂、多元化的任务提供了可能,使得模型能够应对更多样化的数据类型。例如,在智能客服领域,多模态融合技术使得客服系统能够同时处理文本和语音输入,为用户提供更加自然、流畅的交互体验。
多模态融合技术通过整合来自不同模态的数据,如文本、图像、音频等,实现了对信息的全面、准确捕捉。其关键在于不同模态的数据间蕴含着丰富的互补信息,通过融合这些信息,模型能够更全面地理解数据的内涵,从而增强其感知和理解能力。
在融合过程中,涉及了数据预处理、特征提取以及融合算法等多个关键环节。首先,通过数据预处理阶段,对数据进行清洗、标注和对齐等操作,确保数据的质量和一致性。随后,利用特征提取技术,如卷积神经网络(CNN)提取图像特征,循环神经网络(RNN)提取文本特征等,从不同模态数据中提取出关键信息。最后,通过高效的融合算法将这些特征进行有效整合,生成更全面、准确的特征表示,进一步提升模型的性能和应用能力。
六、Money is all you need!

其实说到底,钞能力是大模型训练的核心驱动力! 大模型的训练与运营无疑是一项资源密集型工程,囊括了算力、人力以及电力等多重资源的巨额投入,每一项都离不开雄厚财力的坚实支撑。
首先,大模型的训练离不开高性能计算机集群的鼎力相助。这些集群装配了海量的CPU、GPU或TPU等处理器,为大规模的并行计算提供了有力支撑。
其次,大模型的训练同样需要一支技艺精湛的专业团队。这支团队汇聚了数据科学家、工程师和研究人员等各路精英,他们在算法、模型和数据等领域均具备深厚的造诣和精湛的技艺。然
最后,高性能计算机集群的运行离不开电力的持续供应。在大规模训练过程中,电力成本占据了相当大的比重。没有足够的财力作为保障,要承担这样大规模的电力消耗无疑是一项艰巨的任务。
总之,基于规模定律的Transformer等技术为我们开启了一个崭新的大模型时代。然而,Money才是扮演着举足轻重的角色,它决定了大模型能够走多远,是否能够持续不断地为我们带来更多的创新和惊喜!
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









