






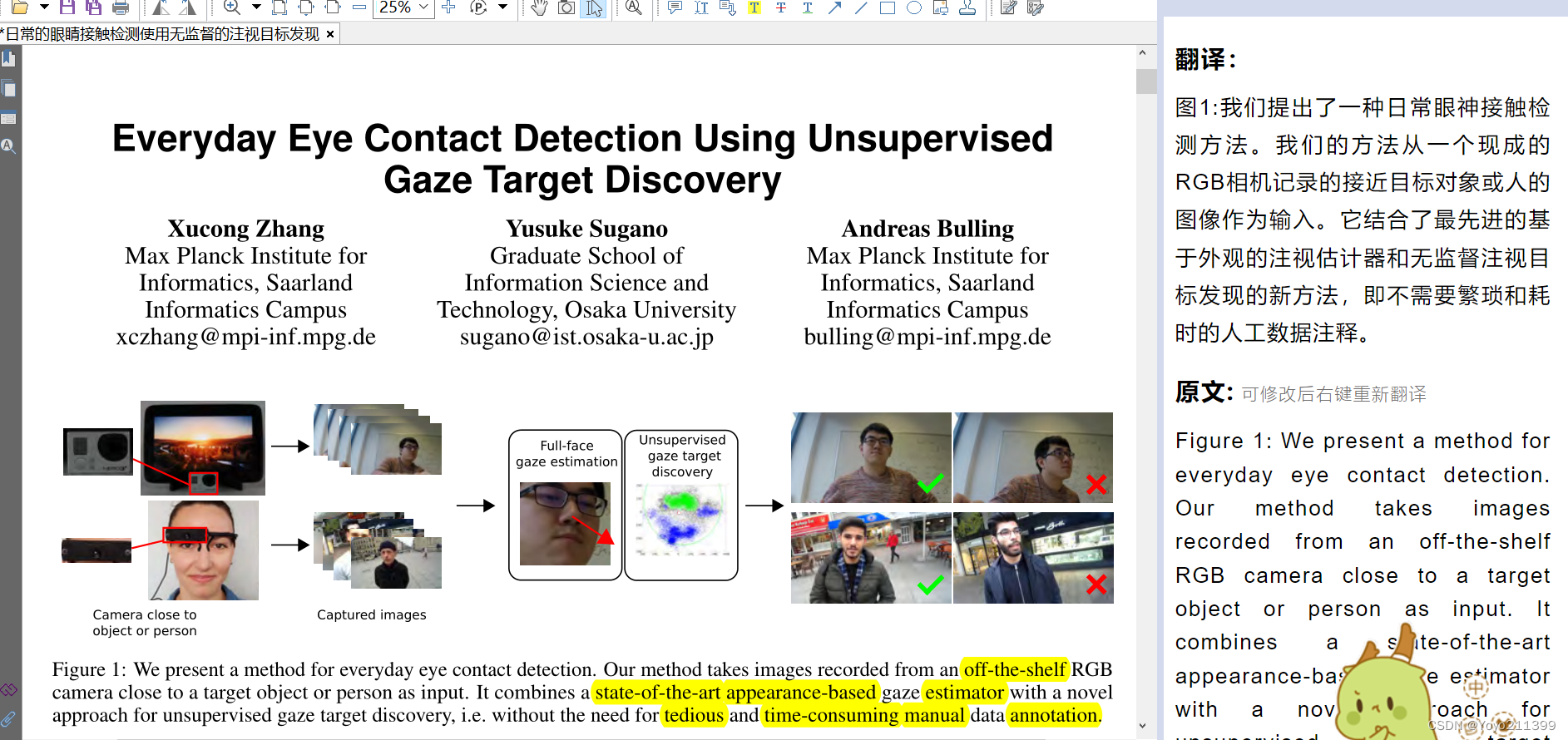
介绍图1 我们提出的是啥方法 。
我们提出了一种日常眼神接触检测方法。
一个现成的RGB相机, 去接近目标对象或人的图像 --------作为输入。
它结合了最先进的基于外观的注视估计器和无监督注视目标发现的新方法,
即不需要繁琐和耗时的人工数据注释。

【先说困难】
在社交信号处理中,眼神交流是一种重要的非语言信号,在人机交互和用户界面中被认为是一种表征注意力的重要手段。然而,对不同用户之间的眼神交流、凝视目标、相机位置和照明条件进行稳健检测是出了名的困难。
【我们提出了..............(和上面一开始说的一样)】
我们在两个真实世界的场景中评估我们的方法:检测工作场所的眼神交流,包括在主要工作展示上
1.安装到目标对象的摄像头
2.人戴的头戴式自我中心摄像头。
【我们的好】
评估两种方法性能:证明了: 独立于目标对象类型和大小、摄像机位置、用户和记录环境的眼睛接触检测方面 的有效性。

【介绍】
眼神交流是重要的, 所以这个目光接触检测也重要 。现在有一些眼动跟踪在眼神接触检测中的应用,but 要求设备等等高 ,用最先进的也不能满足在小物体上的检测;对远距离也有挑战。
 【任务是什么样的呢 前人怎么做呢 是否 有困难】
【任务是什么样的呢 前人怎么做呢 是否 有困难】
注视估计可以看作是:推断任意注视方向的回归任务
目光接触检测则是:输出用户是否在注视目标的二值分类任务
之前的一些工作:通过设计专用的眼睛接触检测器 来转换任务。
(使用由摄像头和红外led组成的嵌入式传感器 或 使用机器学习)
虽然从回归到分类的转变可能会使眼神接触检测任务更容易,但从实用的角度来看,仍然存在两个基本挑战

【挑战/困难1】
目光接触与非目光接触的分类界限往往取决于目标对象。(我理解 就是看见目标实物就是有目光接触,没看见就是非目光接触 , 所以目标就是一个判断边界)
对于基于学习的眼睛接触检测,算法首先需要识别: 目标物体相对于摄像机的大小和位置,并需要专门的训练数据来训练特定目标的眼睛接触检测器。
如果没有这些先验知识,很难做实验;
其次,处理不同环境的困难仍然阻碍了鲁棒性和准确的检测。
即使使用最先进的机器学习算法,连接训练数据和测试数据之间的差距也是最困难的问题之一,而为目标用户和环境准备适当的训练数据在实际场景中几乎是不可能的。

【以上相当于基于目标的检测; 我们提出的是基于外观的检测】
我们从一个新的角度探讨了基于外观的眼神接触检测。
我们利用了这样一个事实: 视觉注意力倾向于偏向于物体和面孔的中心,注视分布因此在注视目标周围有一个中心环绕结构。
我们的主要想法是:使用无监督数据挖掘方法 来收集现场培训数据。
(开头所说的无监督注视目标发现)
我们的方法在部署过程中自动获取训练数据,并自适应地学习 针对目标用户、对象和环境的眼睛接触检测器,而不是预先训练通用的眼睛接触检测器。
首次使用:
来推断不准确的注视空间分布;结果表明:精度较低的注视数据下,也通过聚类分析来识别眼神接触图像。
聚类结果用于创建积极和消极训练标签,并训练一个专用的眼神接触检测器。
只要假设目标是突出的,并且离相机最近的物体,我们方法将 靠近目标物体的任意摄像机 转换为目光接触传感器,

【我们的贡献有三方面】
我们的贡献是三重的。
1. 一个新的基于摄像机的眼睛接触检测方法,该方法能自动适应任意的眼睛接触目标对象。
2. 一个新的野外数据集的眼睛接触检测,在两种不同的和互补的设置:固定的物体安装和移动头戴摄像头。
(上面所说的 检测工作场所的眼神交流,包括在主要工作展示上
1.安装到目标对象的摄像头
2.人戴的头戴式自我中心摄像头。
)
3. 使用数据集,我们量化了我们的方法的性能,并讨论了现有方法在眼睛接触检测的基本局限性。

【相关工作内容 一些介绍 】
(1)用户关注的界面,(2)注视估计,(3)眼睛接触检测

(1)用户注意界面 目光接触是交互系统检测用户视觉注意的最有效方式之一。【过渡句】
一些研究表明,当发出语音命令时,用户确实会查看执行相关任务 在她们的个人设备上。
(有语音提示, 来电话铃声了! 人肯定会去看手机的, 这是有原理的 如下)
这意味着目光接触感应可以用来打开和关闭用户和远程设备之间的沟通渠道,这是一个被称为“Look-to-Talk”的原理。
注意用户界面将这些注视信息作为输入,以优化交互。
这需要估计用户对不同对象的注意力,但稳健的注视估计。but眼睛接触检测仍然是一项具有挑战性的任务,特别是对现实环境中的任意目标。
因此,以前的工作 使用头部方向作为代理来 检测用户是否正在看一个对象。

(2)注视估计
凝视估计方法原则上可以用于检测眼神接触,但在实际应用中存在一些技术局限性。
局限在哪:
- 大多数方法需要额外的红外光和准确的瞳孔检测,这限制了这些方法的短距离和固定设置。
(举例子:虽然越来越多的研究工作只需要一台现成的相机,但从低分辨率图像中进行鲁棒的和独立于人的注视估计仍然是一项困难的任务,即使是最先进的方法)
- 一般来说,适应目标用户和环境是基于学习的注视估计方法面临的最基本挑战之一。
为了解决这一挑战: 之前的几项工作研究了通过侧重于视觉显著性或用户交互信息从用户的自然行为中获取校准或训练数据的隐式方法。该隐式方法还用于收集特定环境的训练数据,用于公众展示注视估计的学习误差补偿函数。
(举例子:同样,行人的行走方向也被用来推断头部姿态估计背景下的训练标签为注视方向。利用潜在的簇结构发现了头部定向的离散目标区域,如注视注意方向。)

我们做的是!!!:
以一种无监督的方式利用 用户的行为来 收集训练数据。
我们的主要贡献是在最先进的 基于外观的注视估计方法的基础上,在现实环境中建立了一种眼睛接触检测方法。


(3)目光接触检测
【有挑战 】前人怎么做的】
直接使用 获得的凝视估计来 检测给定目标物体上的眼神接触,对于任意相机目标配置、可变的面部外观和现实环境都是一个挑战。
【前人怎么做的】
之前的几项工作研究了专用的眼睛接触检测设备和方法。Selker等人;Vertegaal、Shell和Dickie等人;

虽然这些 <基于设备的方法> 可能实现健壮的眼神接触检测,但使用专用的眼神接触传感器来增强目标的需求从根本上限制了它们的使用。
相比之下,我们的方法可以利用越来越多现成的摄像头——比如集成在笔记本电脑里的摄像头、放置在环境里的摄像头,或者戴在身上的摄像头。
其他的研究则:<基于学习的> 眼神接触检测。<一种基于cnn的模型>来预测目光接触目标
这些方法在本质上与基于图像的注视估计方法有相同的局限性:
如果没有针对用户或环境的培训,就无法实现高性能。
另一个局限:得假设预先知道目标物体的大小和位置。
我们的无监督方法通过收集特定相机-目标配置的现场培训数据来解决这两个问题
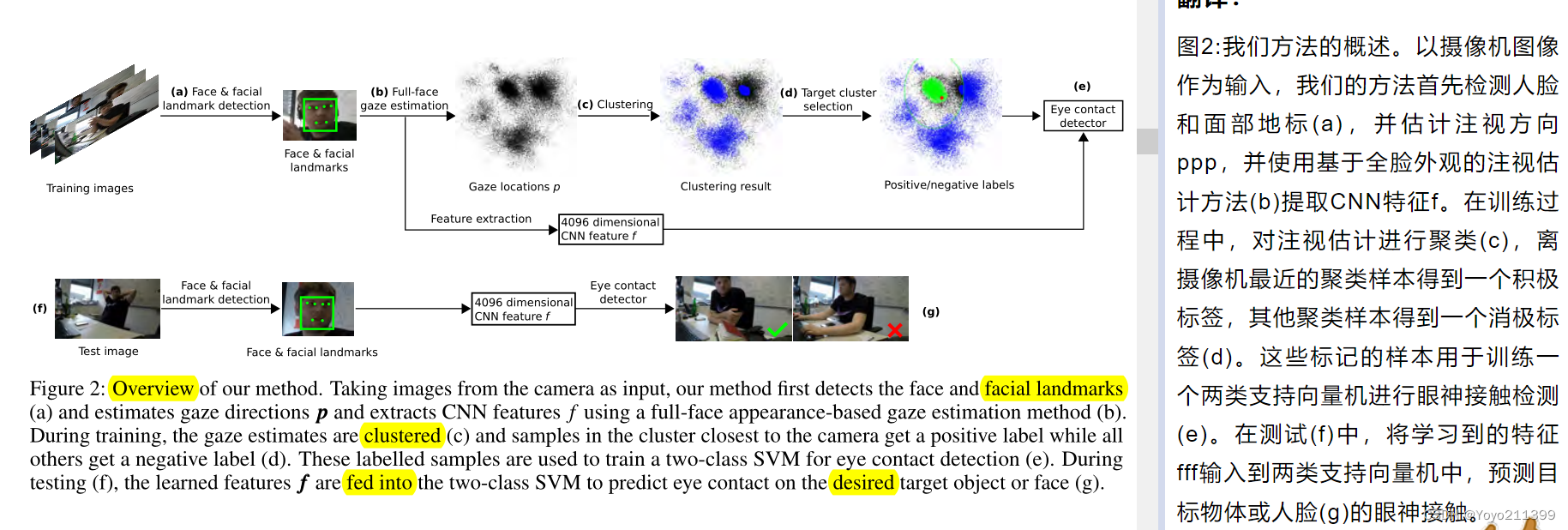
【我们的方法说这么多了 该介绍了 图2 就是概述】
上面一行是训练过程 下面一行是测试过程
1.训练过程:
1.以摄像机拍的 图像作为输入
2.检测人脸和面部地标(a),
1.估计注视方向p:
1. 对注视估计进行聚类(c),得出结果 ,
2.贴标签: 离摄像机最近的聚类样本得到一个积极标签,其他聚类样本得到一个消 极标签(d)。
2.使用基于全脸外观的注视估计方法(b)提取CNN特征f。
(这些标记的样本根据特征f 去训练一个两类支持向量机进行眼神接触检测(e))
2.测试过程 :在测试(f)中,
1.将学习到的特征f输入到两类支持向量机中
2.预测目标物体或人脸(g)的眼神接触。 

【无监督眼睛接触检测】跟上面图2 差不多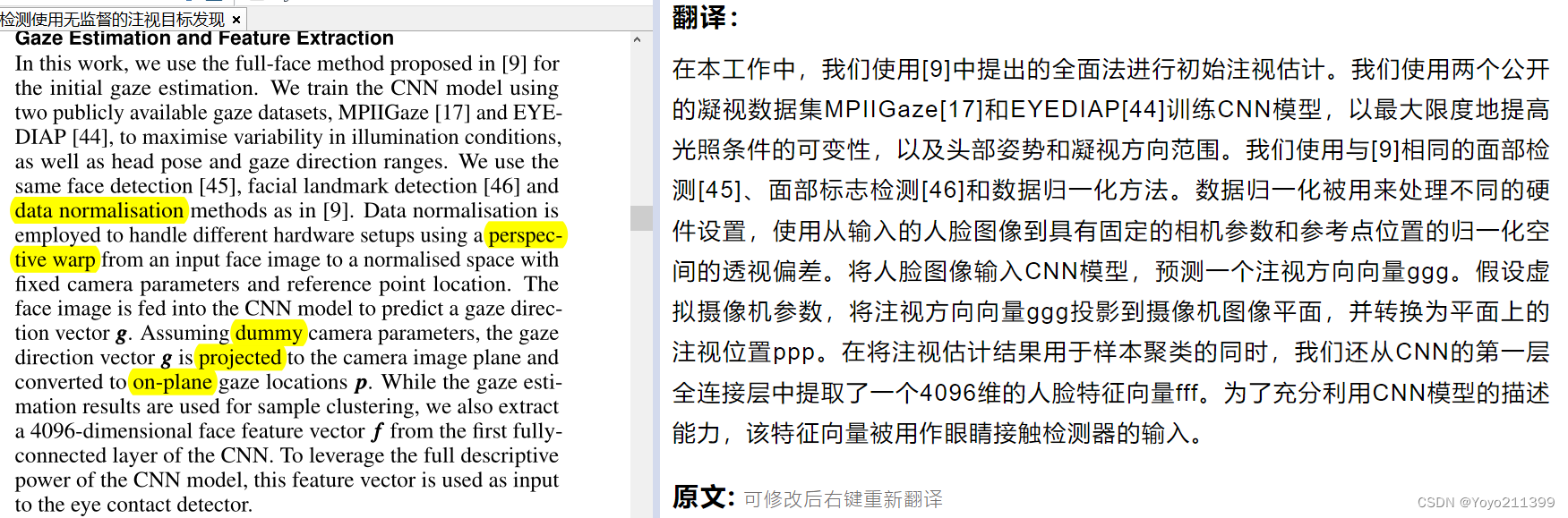
【凝视估计与特征提取】
1.使用[9]中提出的全脸方法 进行初始注视估计。
2.使用两个公开的凝视数据集MPIIGaze[17]和EYEDIAP[44]训练CNN模型,以最大限度地提高光照条件的可变性,以及头部姿势和凝视方向范围。
3.使用在[9]中 相同的面部检测[45]、面部标志检测[46]和数据归一化方法。
数据归一化被用来处理不同的硬件设置,使用从输入的人脸图像到具有固定的相机参数和参考点位置的归一化空间的透视偏差。
4.将人脸图像输入CNN模型,预测一个注视方向向量p。
工作流程: 假设虚拟摄像机参数,
将注视方向向量p投影到摄像机拍照的图像平面中,
并转换为平面上的注视位置p。
5. 在将注视估计结果用于样本聚类的同时,
我们还从CNN的第一层全连接层中提取了一个4096维的人脸特征向量f
为了充分利用CNN模型的描述能力,该特征向量被用作眼睛接触检测器(应该就是SVM吧)的输入。
【9】张旭聪,Y usuke Sugano, Mario Fritz和Andreas Bulling。它写在你的脸上:基于整个脸的注视估计。计算机视觉与模式识别学术会议,2017。
Xucong Zhang, Y usuke Sugano, Mario Fritz, and Andreas Bulling. It’s written all over your face: Full-face appearance-based gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2017.
【45】 戴维斯·e·王。Dlib-ml:机器学习工具包。机器学习研究,10(1):1 - 7
Davis E. King. Dlib-ml: A machine learning toolkit. Journal of Machine Learning Research, 10:1755–1758,2009.
【46】Tadas Baltrušaitis, Peter Robinson和Louis-Philippe Morency。Openface:一个开源的面部行为分析工具包。计算机视觉应用(WACV), 2016年IEEE冬季会议,页1-10。IEEE 2016。
Tadas Baltrušaitis, Peter Robinson, and Louis-Philippe Morency. Openface: an open source facial behavior analysis toolkit. In Applications of Computer Vision (WACV), 2016 IEEE Winter Conference on, pages 1–10. IEEE, 2016.


【样本聚类与目标选择】
即使 用最先进的方法, 估计的注视方向g也不准确
但是,它至少从摄像机位置指示相对注视方向,从而可以观察到与物理对象相对应的注视方向簇。因此,在下一步中,凝视方向被聚集成不同的簇,这些簇被认为对应于不同的对象。最后选择离摄像机位置最近的簇为 目标对象。【目标选择】

【处理样本 样本聚类】
负训练样本:
从聚类过程中过滤出不可靠(面部标志对齐评分低于阈值θ)的样本,由于这些不可靠的样本往往对应于非正面的面孔,我们在训练过程中作为负样本。
(
聚类方法:
使用OPTICS算法[47]对样本进行聚类。
由于OPTICS算法是分层聚类算法,它倾向于在具有相同质心的父簇的中心创建子簇。在我们的方法中,我们摒弃了这种递归的层次结构,而采用与其他集群空间分离的最大集群。
)
正训练样本:
我们的方法中, 假设摄像机与目标物体很接近,使用离摄像机位置最近的簇(摄像机图像平面的原点)中的样本。
假设其他簇与其他对象相对应,并将这些簇中的样本用作负样本。
此外,考虑到OPTICS算法标记为噪声的样本往往较多,我们在正簇周围设置了一个安全边缘d,我们也使用安全边缘之外的样本作为负样本
除了 聚类出来 是和摄像机最近的簇 是正样本;
其他面部标志对齐评分低于阈值θ(非正面的面孔)、不是和摄像机最近的簇、安全边缘d以外 是负样本。
【47】Mihael Ankerst, Markus M Breunig, Hans-Peter Kriegel,and Jörg Sander. Optics: ordering points to identify the clustering structure. In ACM Sigmod record, volume 28,pages 49–60. ACM, 1999.光学:排序点识别聚类结构。在ACM Sigmod记录,卷28,页49-60。ACM, 1999年
【目光接触检测】
1.上一步获得的标有标签的样本 训练 眼神接触分类器。(因为正和负样本的数量非常不平衡,所以, 用加权SVM分类器[48])
2.如前所述,用 从注视估计CNN中提取的高维特征向量f 来利用更丰富的信息,而不仅仅是注视位置。
3.我们首先应用PCA对训练数据进行降维,使PCA子空间保留95%的方差。
4.训练阶段结束后, 将有人脸和人脸地标检测的图像 作为输入 送入相同的预处理管道,并从相同的注视估计CNN中提取fff特征。然后将其投影到PCA子空间,并将SVM分类器应用于输出的眼神接触标签
【48】Petros Xanthopoulos and Talayeh Razzaghi. A weighted support vector machine method for control chart pattern recognition. Computers & Industrial Engineering,70:134–149, 2014
控制图模式识别的加权支持向量机方法

【实验】
收集了两个真实世界数据集: 在目标对象类型和大小、固定和移动设置以及单用户和多用户假设方面具有互补特征的。
在两个数据集上评估了我们的方法和不同的基线,并分析了不同对象、相机位置和训练数据收集持续时间的 性能 。

大黑竖线左边是安装到物体上 右边是安装人头上


【数据收集】
两个具有挑战性的现实场景进行:
1.(见图3,左)
摄像头安装在物体上---------检测单个用户在其工作场所的日常工作中与这些目标对象的眼神接触。
我们使用参与者的主要工作显示器(电脑)作为目标,并将摄像机置于三个不同但不精确定义的位置:显示器上方、下方和旁边。 图中只展示了 在电脑显示器的上方和下方
还放置了一个平板电脑或时钟作为目标物,并在它们旁边放置了一个摄像头。
(这款平板电脑模拟了一个数字相框,循环显示不同的视频和图像。人可能看各种屏幕中的位置,使数据集在目标对象的显著性/分散性,以及目标大小和相对于用户和相机的位置方面更加多变。)
总共记录了14名参与者(5名女性),每个人都记录了4个视频:一个是关于时钟的,一个是关于平板的,两个是关于显示器的(有两个不同的摄像头位置)。录音时长为3 ~ 7小时。
2.(见图3,右)
用户戴着一个头戴式摄像头。进行日常社交互动
这个场景是对办公室场景的补充,因为用户的头/脸是目标,我们的目的是检测不同对话者的眼神交流。我们招募了三名录音人员(全部为男性),并记录了他们在街上采访的多个人。总共5个小时的视频覆盖了28个社交互动。
图3可以看出,我们实验中使用的头戴式相机相当笨重,我们不能排除可能引起了第二个人的注意,而不是脸。(可能不是我们正对着的对话者,但是他也在看摄像头)

然而,相机的位置靠近脸部的中心,因此我们预计产生的误差非常低,对图像的随机子集的视觉检查证实了这一预期。、
前75%的数据用于训练我们的方法(训练集),其余25%用于测试(测试集)。
该训练的训练,然后处理测试集
我们从测试集中统一采样了5000张图像,并让两名标注者用“接地真实”二值眼神接触标签手工标注它们,即这个人是否在看目标(物体或人)。
两个注释器分别注释测试集的不同部分。
我们还请了第三个注释器来检查这些注释,并对不正确的进行标记,标记过的图像由同一个相应的注释器再次进行注释。
标注者被要求从被检测到的面孔中判断眼神接触,并详细了解每个记录的物理设置,包括目标物体和相机位置。
【实现细节】
各种设值 之前提到的人脸检测的阈值 每簇的大小 安全边缘d

【基线的方法】
1.注视锁定
从以下方法得到的灵感吧
[14]中提出的GazeLocking方法使用带有地面真实标签的眼睛图像数据集,以完全监督的方式训练SVM分类器,实现眼睛接触检测。
它假设使用下巴托的人的脸是对齐的。
为了进行公平的比较,我们采用了GazeLocking方法,使用与我们提出的方法(无监督)相同的基于cnn的分类架构来训练来自哥伦比亚数据集的眼睛接触检测器。在哥伦比亚测试集上进行评估后,证实采用的方法取得了与[14]报告相似的性能(MCC = 0.83)


2.脸部簇集
最近的一些研究[38,42]使用人脸图像来推断粗糙的注视方向。
我们的优势在于,用最先进的基于外观的注视估计器来获取无监督注视目标发现的初始特征。
为了评估这种方法的好处,直接使用从CNN模型提取的人脸特征f作为聚类的输入。
3.目光分类
我们的方法使用人脸特征fff来训练眼睛接触检测器。
为了评估面部特征表征的贡献,我们在样本聚类和眼神接触检测器训练中使用了凝视位置ppp。
4.目光投射
有些研究:原始凝视方向被用来估计公众展示的视觉注意力[34,10]。
我们手动测量目标物体的物理大小及其与相机相关的位置,并将目标物体作为边界框投影到相机图像平面上。
相机拍的图片上 我们给目标物体框上一个框。
如果估计的注视位置在边界框内,则将输入图像归类为目光接触。因此,该方法假设准确地知道目标物体的位置。



【头方向投影】
头部方向也被用于视觉注意估计[49,50,51],特别是当目标人脸图像分辨率较低,无法进行准确的注视估计时。
我们通过将2D人脸地标检测与3D人脸模型(如[17])拟合,从输入的人脸中获得3D头部方向,
并计算头部方向向量与相机图像平面的交集。--------如果交点位于对象边界框内,则输入帧被分类为眼神接触
【总结 各个秒数】

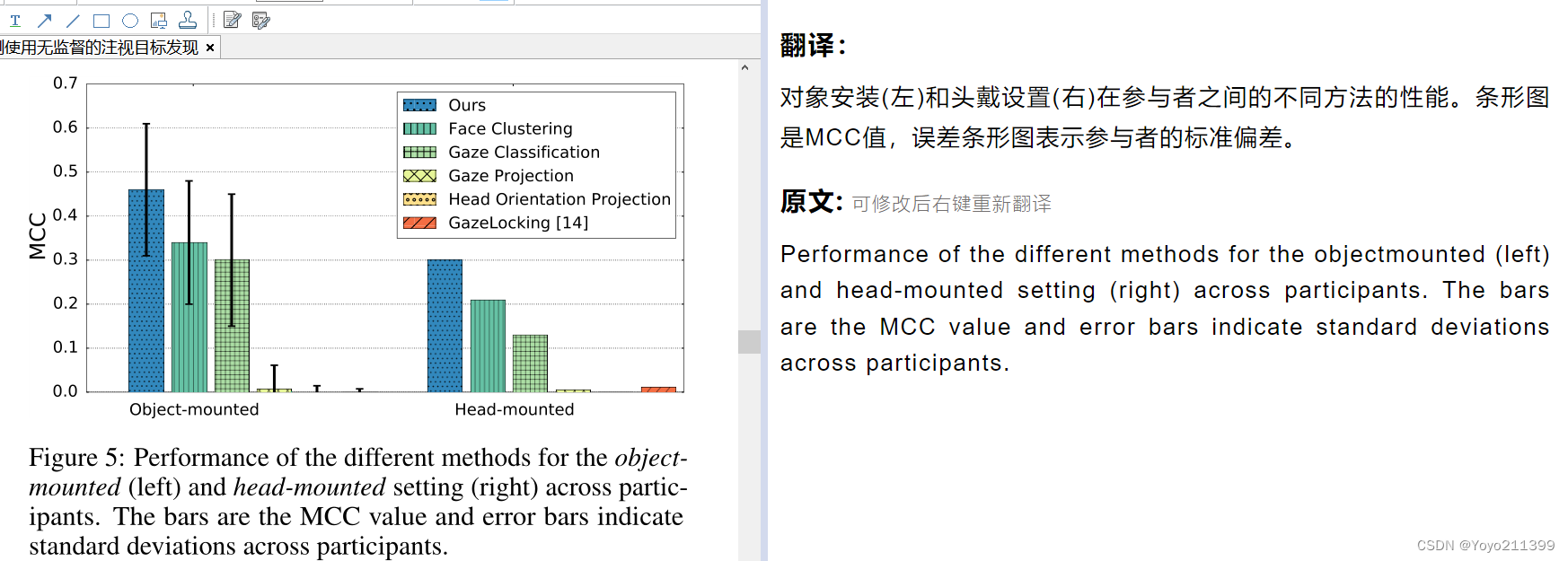
【评估我们的性能】
MCC
机器学习——常用的分类模型性能评价指标_從疑開始的博客-CSDN博客_分类模型的评价指标分类模型的性能评价指标,主要包含准确率,精确率、召回率、f1_score,ROC曲线,AUC等1、分类评价指标先列出混淆矩阵其中:TP:真实值是positive,模型分为positiveFN:真实值是positive,模型分为negativeFP:真实值是negative,模型分为positiveTN:真实值是negative,模型认为是negative1.1、准确度(Accuracy)准确度:对于给定的测试集,模型正确分类的样本数与总样本数之比。公式为:1.2、精确度(precihttps://blog.csdn.net/ll20246033/article/details/113914956【机器学习】马修斯相关系数(Matthews correlation coefficient)_镰刀韭菜的博客-CSDN博客_马修斯相关系数马修斯相关系数(Matthews correlation coefficient)马修斯相关系数是在使用机器学习作为二进制(2类)的质量的度量的分类,通过布赖恩W.马修斯在1975年由生物化学引入它考虑到真和假阳性和假阴性,并且通常是被视为一种平衡的措施,即使这些类别的规模大小不同也可以使用。MC实质上是观察到的类别和预测的二元分类之间的相关系数; 它返回介于-1和+1之间的值。系数+1...
https://blog.csdn.net/ARPOSPF/article/details/84997220




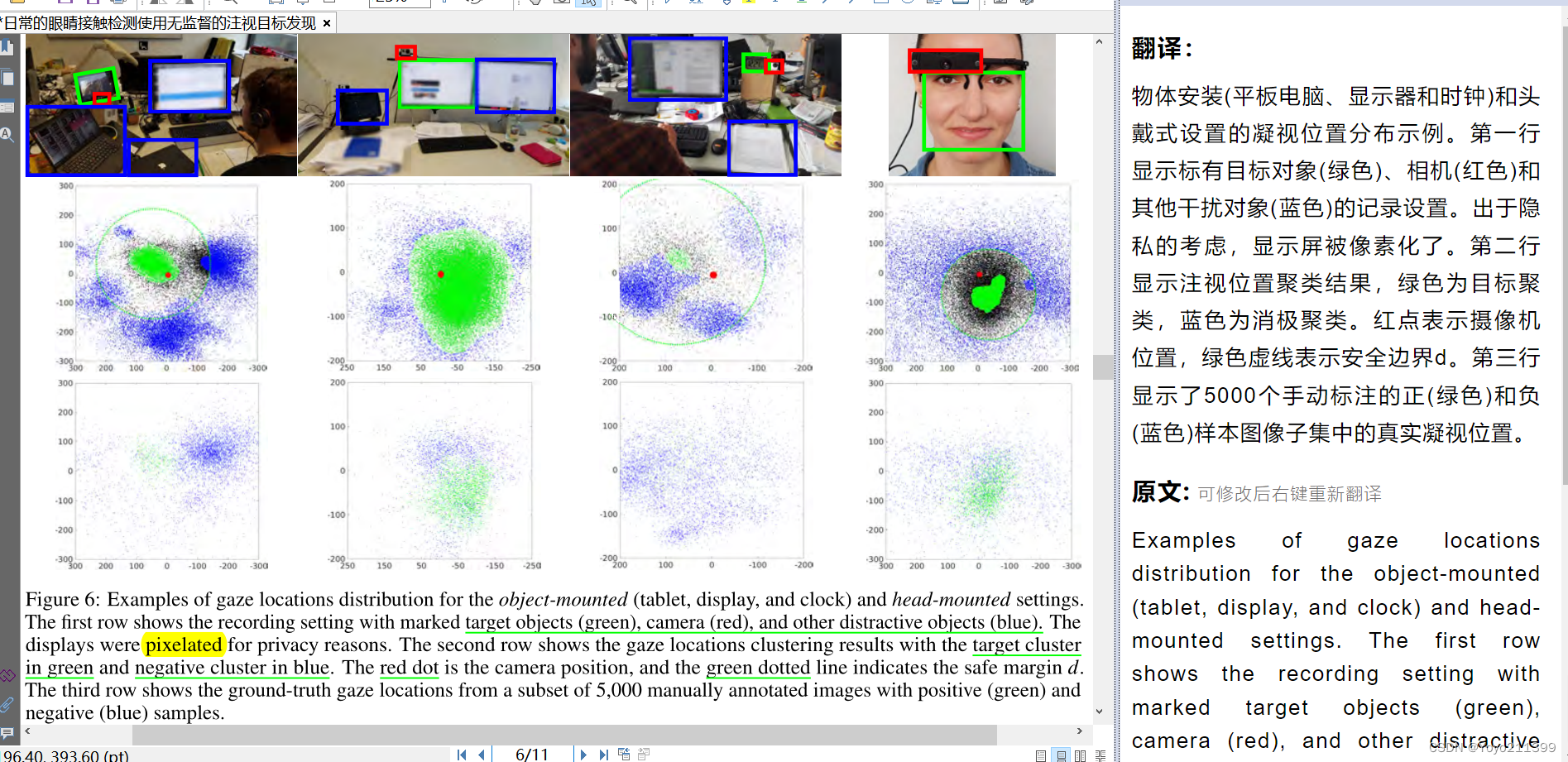
【凝视位置分布示例】
第一行展示的是 物体安装: 绿色框----目标对象 红色----相机 蓝色------其他干扰
第二行展示 注视位置聚类结果 绿色----目标聚类 蓝色-----消极聚类 红色------相机
绿色圈----安全边界
第三行 5000个手动标注的正(绿色)和负(蓝色)样本图像子集中的真实凝视位置
能看出来 预测的位置


从图6中 :我们的样例聚类方法可以取得很好的聚类结果。安全边界也可以很好地找到额外的负样本,特别是在对象安装设置中,其中只创建了一个集群



【对象类别和相机位置 从那几个物体 和相机摆放位置进行分析】
通过除以每行的和 将每个元素归一化 

 图8混淆矩阵能看出来 对平板的性能预测的更好 闹钟的最差 因为他吸引人注意力更少。
图8混淆矩阵能看出来 对平板的性能预测的更好 闹钟的最差 因为他吸引人注意力更少。
所以 看图6第三列 他的积极训练data也少 就一滴滴绿色
虽然对于平板性能很好 but 目光分布并不集中在中心 看图6第二列: 一大片绿 but偏右边
(因为它的物理尺寸更大,使在显示器内部,显示的内容也可以创建不同的目标区域。可能右侧屏幕和我一样 有千玺弟弟)


另外,我们设置了三个位置进行记录,上面显示10个视频,下面显示9个视频,旁边显示7个视频。
图9中这三个不同位置的MCC。对不同的摄像机位置都有较好的效果。
上方显示位置的表现最好,因为通常没有其他显著的对象影响样本聚类,并且可以很好地看到参与者的面部。
下方显示的位置也能很好地看到参与者的脸,但可能有其他物体靠近摄像头,引起了参与者的注意。(例如,我们发现有两种情况,样本聚类选择了属于键盘的簇作为目标簇,使MCC接近于0值。)
当摄像机在显示器旁边,摄像机的视角不是很好,从而有效降低了凝视估计精度,导致样本聚类噪声
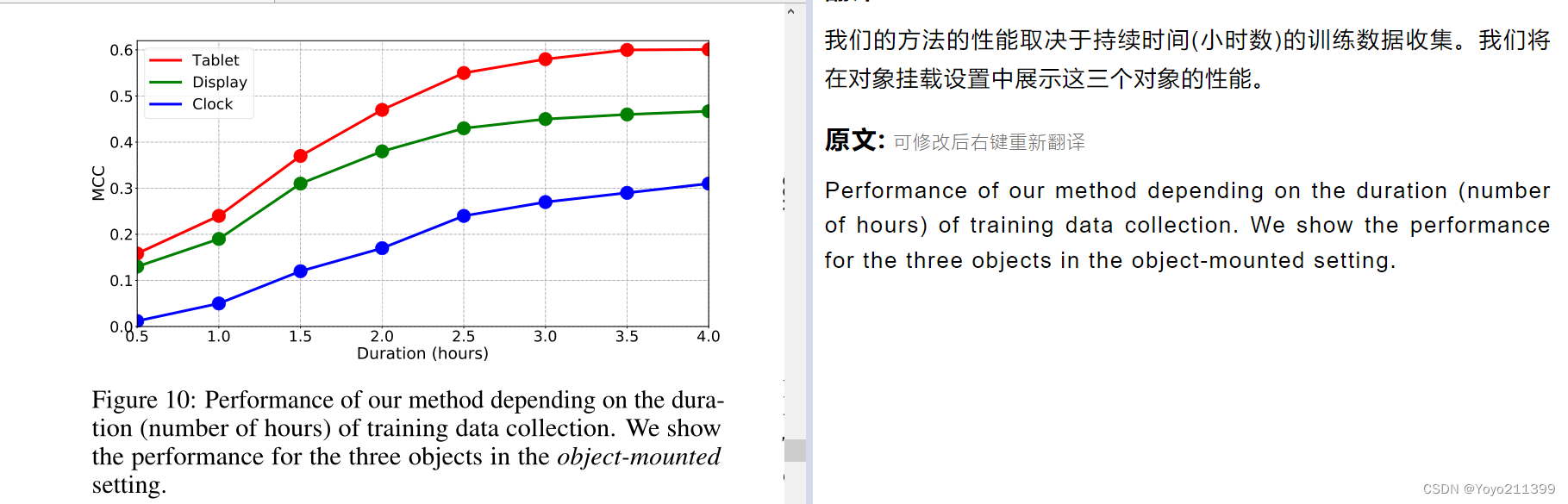

【收集培训数据的时间】 (收集大量数据吧)
我们需要一定数量的数据来进行样本聚类
这里我们测试不同时间的训练数据收集的性能。
三个对象进行评估,并按照时间顺序对时间段内采集的样本进行挑选。我们保持测试集与上次评估相同。
在图10中,我们绘制了在收集训练数据的时间范围内的性能。
可以看出,眼睛检测性能一般随着数据采集时间的增加而提高,而在3.0小时左右,性能趋于收敛。BUT 时钟的性能还没有完全收敛,还在提高-------------这表明,对于小对象,较长的训练持续时间可以部分解决上述正样本数量较少的问题。


【跨人 应该就是多人吧】
在所有用户中,评估我们的安装在物体的 数据集的 平板电脑会话。
使用所有参与者的训练数据,在每个测试集上测试,并平均每个个体的表现数字。
模拟一个应用程序场景,多个用户共享一个空间,例如办公室,有一个目标对象,所有用户与其的眼神接触检测都进行l 分析。
如图11所示,我们的方法在MCC 0.43的情况下获得了该设置的最佳性能,比第二好的Face Clustering方法的性能高出34%。、
值得注意的是,本文提出的方法在个体评价中实现了0.61的MCC(图7),即仍有很大的性能改进空间。
与跨用户的对象安装设置(我们的方法实现了0.30的MCC)相比,对象安装设置更容易,因为图像质量更高。????????

【讨论】
有不足 也有贡献

【应用场景】
与最先进的方法相比,我们的方法的主要优势是: 它对相机和目标对象有很少的要求。
只需在目标物体上安装一个摄像头,系统就会自动收集眼神接触检测的证据,并在初始训练阶段后作为眼神接触检测器开始运行。
因此,这种方法允许在部署期间 持续收集训练数据,这也允许该方法处理动态环境。
因此,我们的方法开辟了各种令人兴奋的新应用。
1. 有前景的应用领域是专注的智能家居或办公环境,在这些环境中,眼神接触检测可以作为用户意图开始互动的信号,例如 家用电器

 2.另一个应用领域是智能手机和智能手表等移动设备上的目光接触检测。正如我们的实验所示,我们的方法也允许这样的移动案例,而且由于这些设备通常假设只有一个用户,我们可以期望比最具挑战性的头戴式设置更好的分类精度。因此,我们的方法有很大的潜力实现基于移动一瞥的新型交互。
2.另一个应用领域是智能手机和智能手表等移动设备上的目光接触检测。正如我们的实验所示,我们的方法也允许这样的移动案例,而且由于这些设备通常假设只有一个用户,我们可以期望比最具挑战性的头戴式设置更好的分类精度。因此,我们的方法有很大的潜力实现基于移动一瞥的新型交互。
3.在汽车中感知驾驶员的注意力是在光照条件的动态变化下单个用户的另一个应用领域。
在这种情况下,我们的方法可以学习和检测司机的眼神接触,例如,一个配备摄像头的汽车导航系统。

4. (虽然移动和多用户场景是最具挑战性的设置,但可穿戴摄像头的眼神接触检测有很大的潜力)
例如,从生命日志中提取重要时刻。我们的方法也不局限于头戴式外壳,并为设计新的可穿戴式眼睛接触传感器提供了灵活性。
5.类似地,机器人的眼神交流有许多潜在的应用场景,我们的方法的优势在于,它可以嵌入到几乎任何类型的配置中,包括类人机器人、车辆或无人机。
6.最后,目光接触检测也可以作为公共展示的重要输入线索,我们的方法也允许这种多用户情况。它可以让公共显示器根据观众的目光接触量动态地改变其内容,目光接触的统计数据为分析显示器的使用提供了有价值的信息。与[10]中提出的方法不同,我们的方法也可以用于静态显示、广告牌、海报等分析目的。

【技术上的限制】
该方法的关键要求是: 目光接触的目标 是距离摄像机最近的突出目标。
BUT在某些情况下,我们的方法不能正确处理 :
如果摄像机被精确地放置在两个同样显著的物体之间,就很难稳健地识别两个目标物体。(在我们的实验中,当摄像机安装在显示器和键盘之间时,也会发生这种情况,有时会选择键盘作为目标对象)
在没有任何信息的情况下,从多个候选对象中选择目标对象簇,本质上是一个病态问题。因此,这需要硬件设计方面的考虑,或额外的人工监督。
目标对象的大小也会影响方法的性能。
如果目标对象不够突出,比如实验中的小时钟,则估计的凝视位置在目标位置上没有清晰的簇结构,性能下降。
如果目标对象太大,如我们实验中的公共展示或主作品展示,即使在同一个目标对象内也可能出现多个注意簇。这些问题可以通过引入一个长期的训练阶段或通过开发能够区分或合并大对象的多个集群的新方法来解决。

我们的方法的性能直接与潜在的基于外观的注视估计方法的准确性有关。
因此,改善这些方法的基线性能将是很重要的。
然而,即使具有完美的精确度,我们的方法仍然具有优势,因为
1)它可以利用场景结构找到目标对象和其他对象之间的决策边界,
2)它也可以关注目标用户和环境,预计这将始终优于假设任意用户和环境的一般注视估计器。
虽然目前我们从相同的注视估计CNN提取面部特征,但通过研究为眼睛接触检测任务优化的特征提取网络,也有改进的空间。未来的工作还可以研究利用人类凝视的时间方面的方法。用户自然会在一段时间内关注目标对象,这样的时间信息有助于聚类过程。
【!!!!!创新点!!!!! CNN网络提取特征 利用凝视时间 base-time gaze】

















 5290
5290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









