







yolov1的缺点:
- 对小目标,密集目标检测能力比较差;
- 定位能力比较差;
- 将所有目标全部检测出(recall)的能力较差;

(1)Batch Normalization.(BN,批归一)
把神经元的输出减去均值除以标准差,变成0均值 标准差1的函数
原因: 许多激活函数在0附近是非饱和区域
如果输入太大或者太小就会陷入激活函数饱和区 --------------梯度消失 难以训练
就是强行把输出 变成0附近
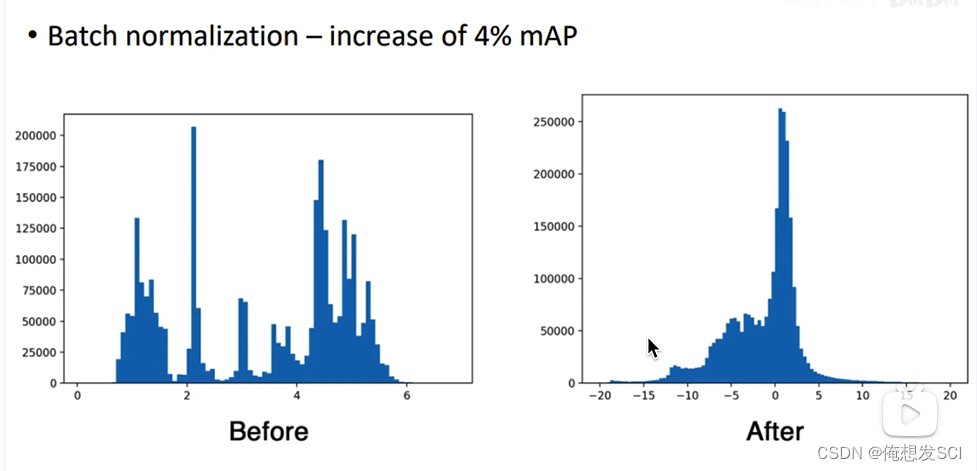
严格意义包含:训练阶段和测试阶段.

bn相关问题就看他!!!!!!!
训练:
batchsize32 意味着 每个batch 步长每个step喂进去32个图片
输出.32个响应值 每个输入都有一个输出
求均值标准差 归一化,这里的归一化应该是标准化 吧神经元的32个输出减去32值的均值 再除以这32个值的标准差
把响应值乘以γ和β 看图叭
效果:把神经元的输出限制在0-1标准差的分布里了
把响应值乘以γ和β 通过一个线性变换还原回了原始空间 弥补信息的丢失
测试:
把那些求出来
均值用训练阶段许多的batch均值的期望
方差 的方差做无偏估计

γ 和deta 训练的时候通过所有batch全局求出来的常数
在测试阶段进行前向传播的时候
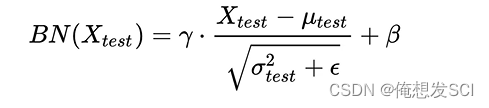
在测试阶段:
在训练阶段:
相当于吧神经元输出压缩 大大加快收敛 防止过拟合 梯度消失 加快训练速度

多层神经网络
对神经元来说 一个batch32个输入就有32个响应
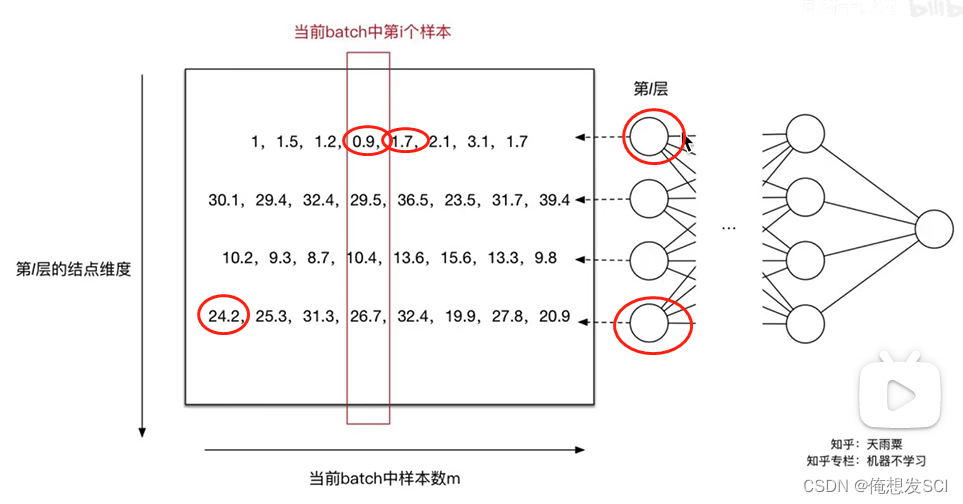
batchsize=8
就有8张图片 8个输入
0.9 就是第一个神经元对第四个输入的响应
1.7 第一个神经元对第五个输入的响应
24.2 最后一个神经元 对第一个输入的响应
对于每一个神经元单独做标准化 第一个神经元对8输入有8输出 求出这8个值的(输出)的均值标准差 然后每个数减去均值除以标准差 再乘以这个神经元对于的γ和β(beta) 就得到BN的结果
图中大格里面是没有经过 乘以这个神经元对于的γ和β(beta)的 我们能看见 确实把神经元的输出限制在0-1标准差的分布里了 在0附近 使得激活函数就是有最大梯度的 容易训练 所以bn操作就是大大加快了收敛
BN论文中的
 在标准化之后为什么又做了个scale and shift的变换。从作者在论文中的表述看,认为每一层都做BN之后可能会导致网络的表征能力下降,所以这里增加两个调节参数(scale和shift),对变换之后的结果进行反变换,弥补网络的表征能力。 ------------------就是乘以γ和β
在标准化之后为什么又做了个scale and shift的变换。从作者在论文中的表述看,认为每一层都做BN之后可能会导致网络的表征能力下降,所以这里增加两个调节参数(scale和shift),对变换之后的结果进行反变换,弥补网络的表征能力。 ------------------就是乘以γ和β
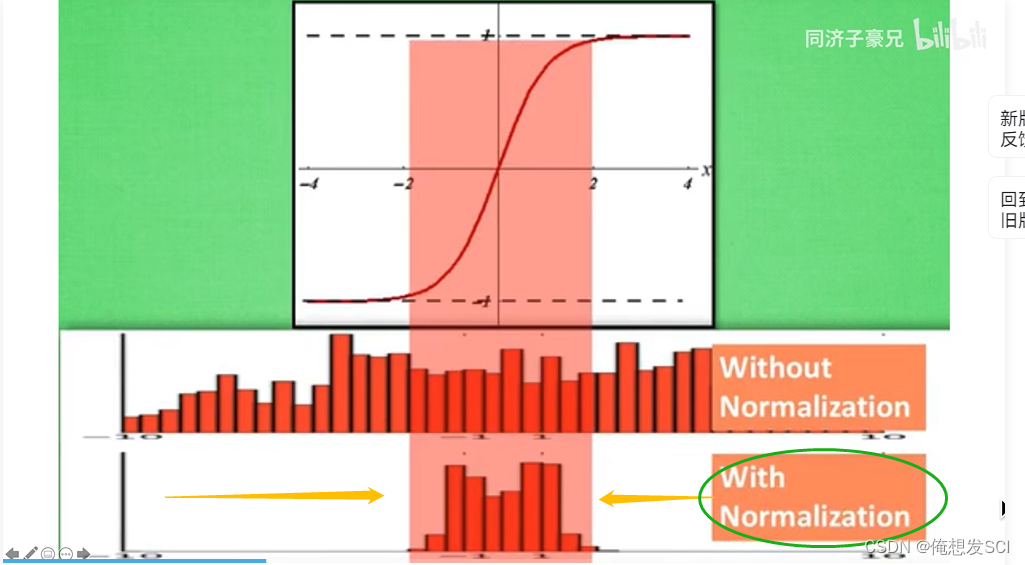 看到下面确实压缩到0-1
看到下面确实压缩到0-1
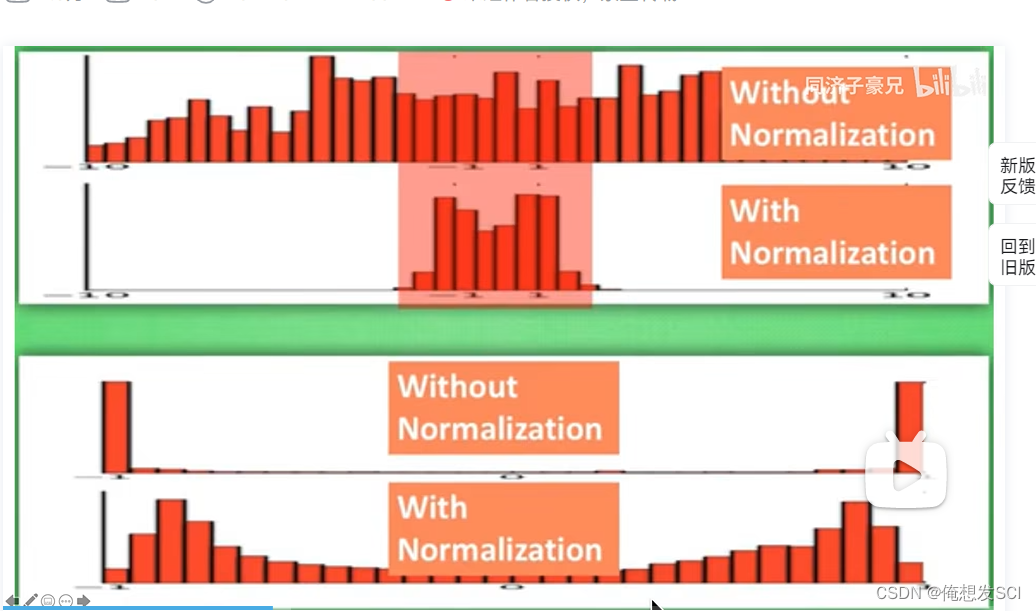
往中间凑了凑 起码能优化训练
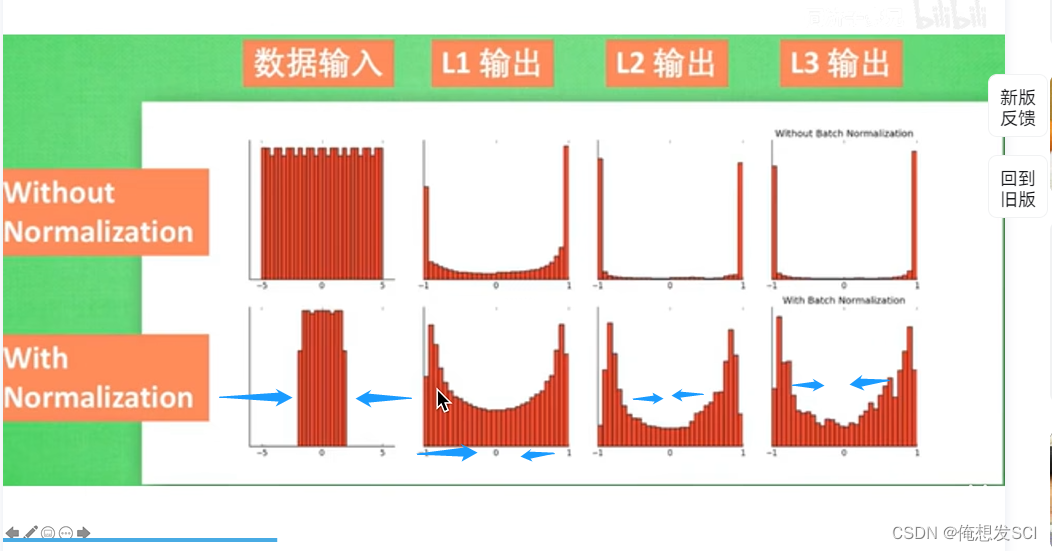
斯坦福课程提到线性层后面 激活函数前面 我们YOLOv2 和下面图不是一样的哈 就是要了解位置大概在哪 以及优点


 笔试的东西。。。
笔试的东西。。。(2)High Resolution Classifier.(高分辨率的分类器)
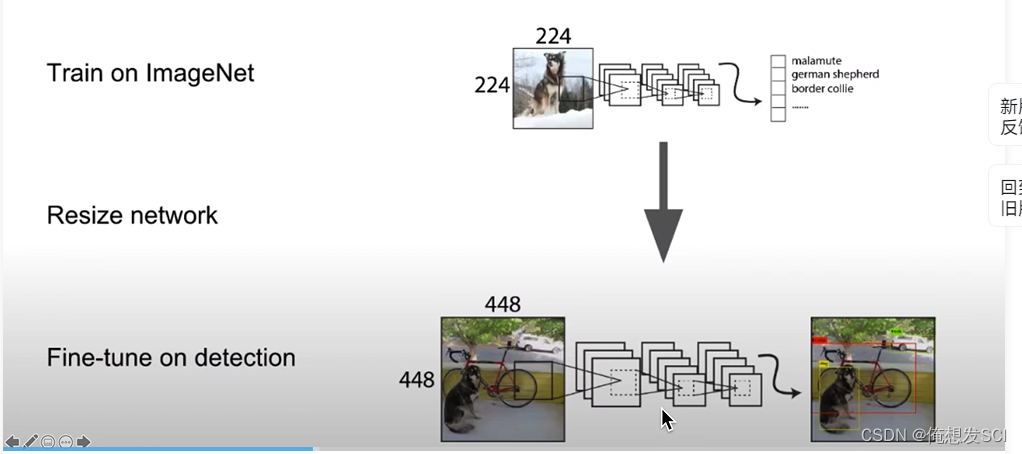
从小分辨率224*224切换到大分辨率448*448 无疑会带来性能降低和麻烦
YOLOv2
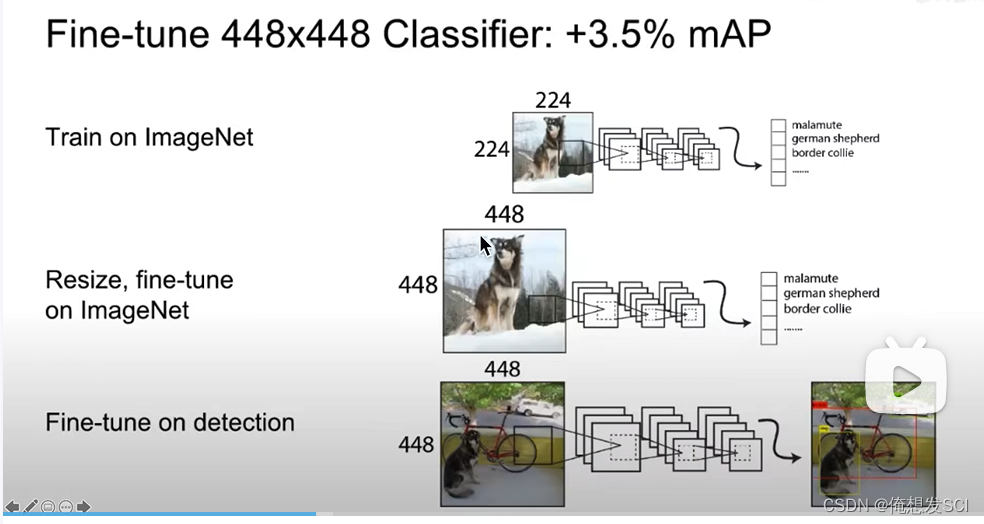
YOLOv2: 直接在448*448的图像分类数据集上进行训练 把骨干网络训练适应大分辨率了
先224*224 训练一会 在448*448训练十个epoch 然后再448*448目标检测数据集上进行finetune
这样网络就能适应大分辨率的输入。
对于目标检测而言,图片分辨率高的话会让定位和识别分类更加精准,所以在yolo v1中,作者预训练时用的是imagenet分类数据集是224 * 224的,后面微调的时候将224 * 224 图片变成448 * 448的尺寸(目标检测)输入网络,这样改变尺寸,网络就要多重新学习一部分,会带来性能损失。
这块容易混,再简单说一下,v1中预训练使用的是分类数据集,大小是224 * 224 ,然后迁移学习,微调时使用yolo模型做目标检测的时候才将输入变成448 * 448。
作者在V2中改进,直接在预训练中输入的就是448 * 448的尺寸,微调的时候也是448 * 448。
这一个弥补措施提高了 4%的mAP。
一开始就在448*448上训练
(3)Convolutional With Anchor Boxes.(带有锚的卷积)
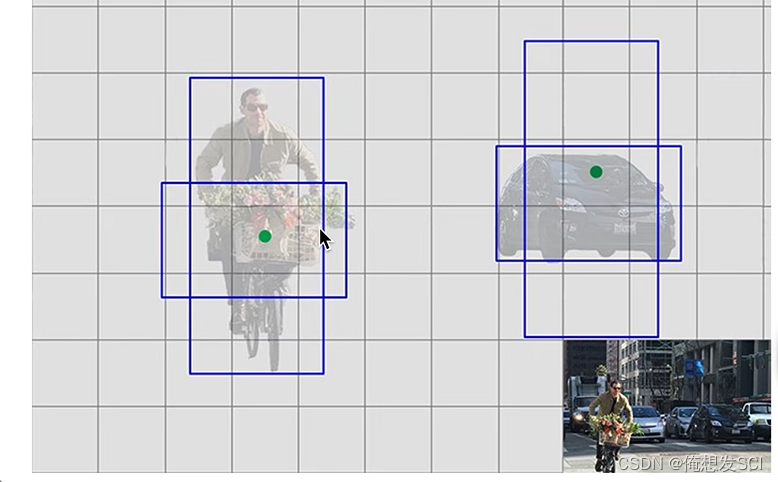
比YOLOv1 改进 就是 适合预测车的框就去预测车 适合预测人的那种竖的框就去预测人
更快一点啦

13*13gridcell 每个cell预测5个长度比例都定好的 anchor。也是通过IOU计算,选出来一个anchor产生的预测框去预测物体。
每个anchor对应一个预测框 ,预测框只需要预测输出 他相对于所在anchor偏移量
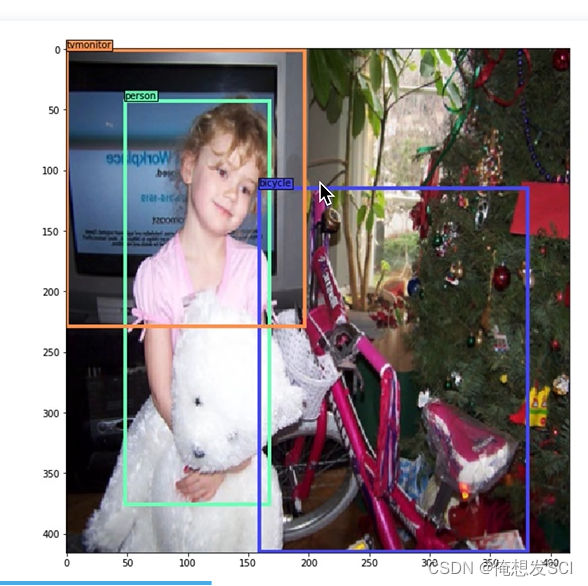
比如说小女孩 ,小女孩的人工标注中心点落在哪个gc就由哪个gc的五个anchor 按照与groundtruth进行iou计算最大的那个anchor进行预测 而这个预测框只需要预测出相较于自己anchor的偏移量就可以了 真的偏移啦 就预测出来啦
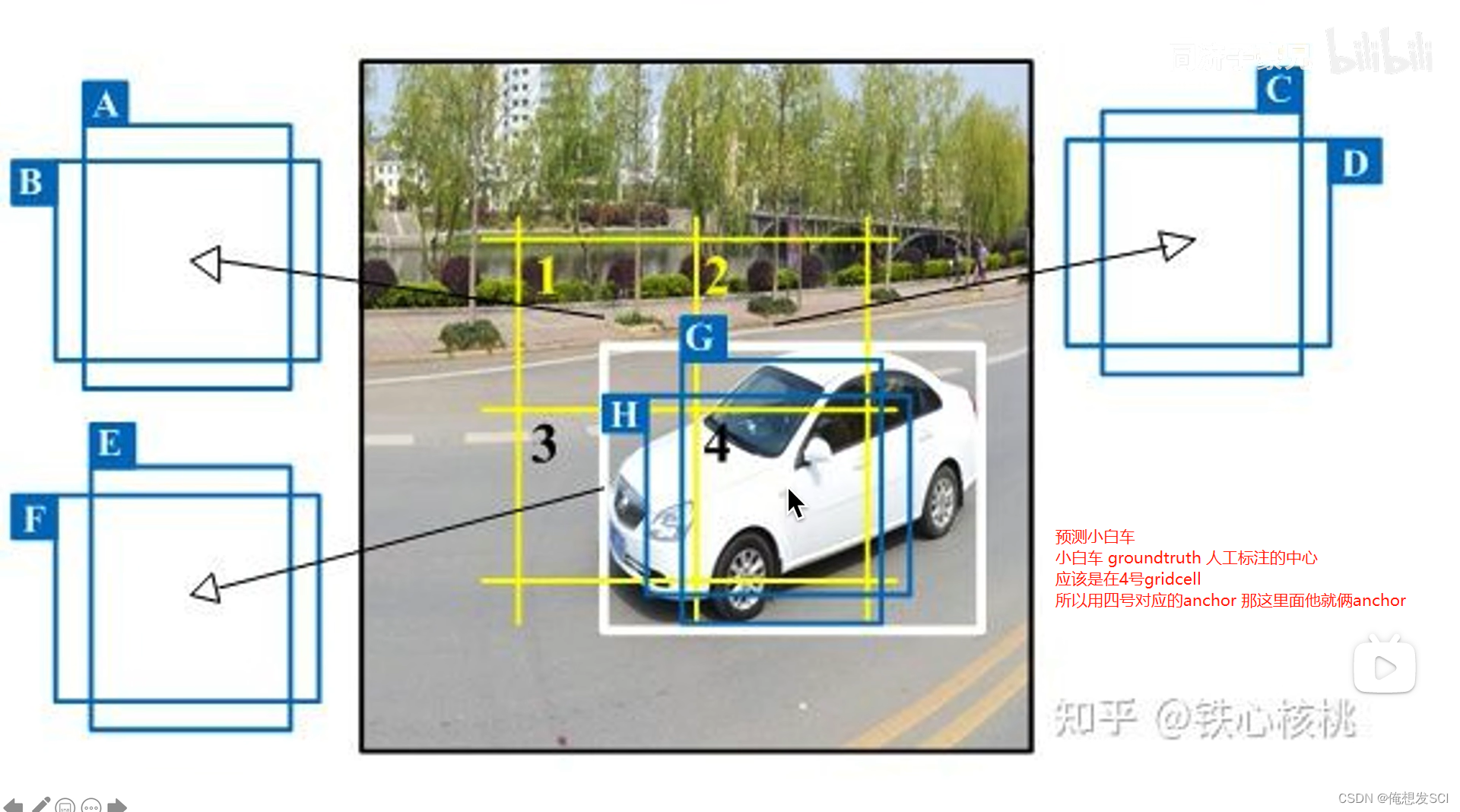
feature map取基数比较好有中心 就是分odd*odd gridcell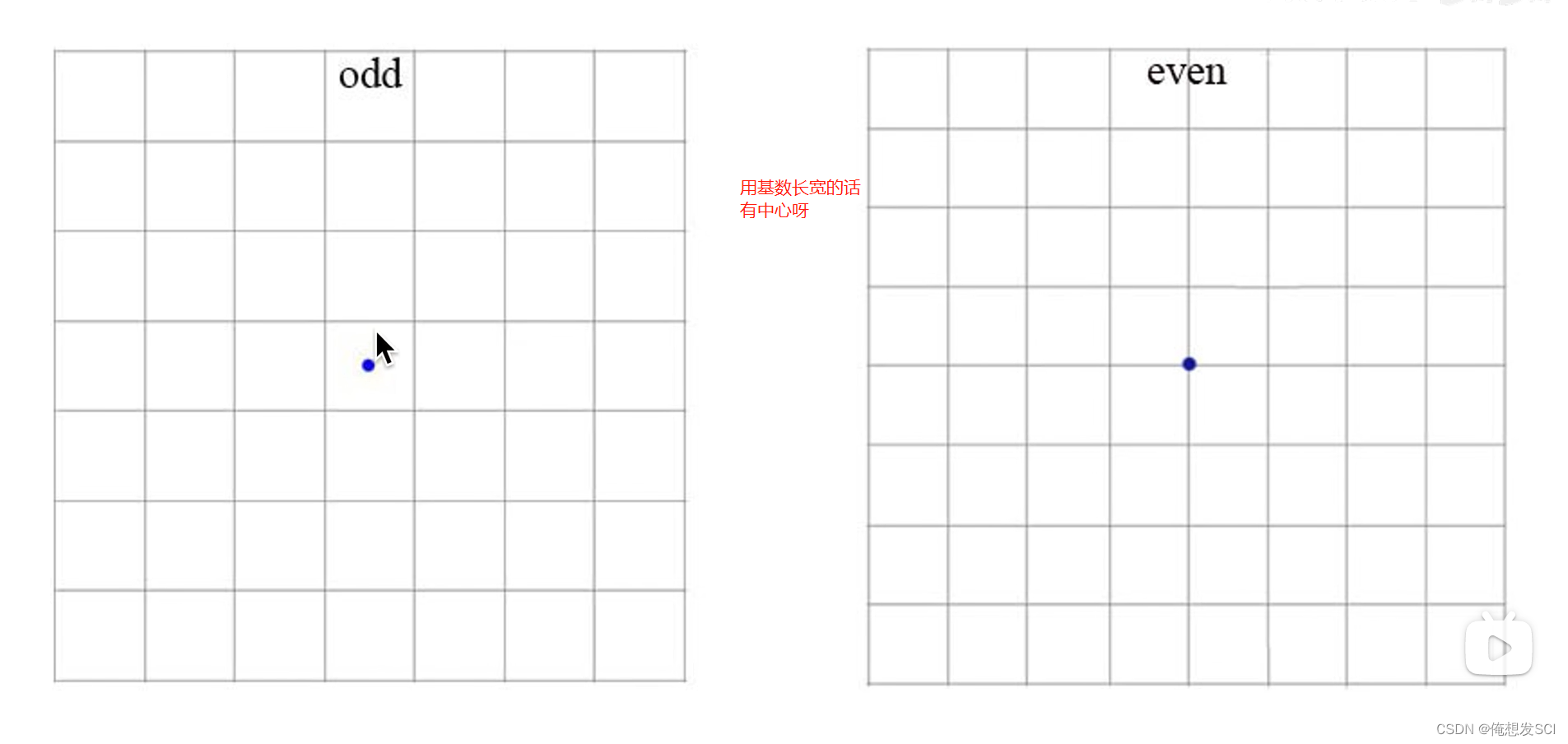
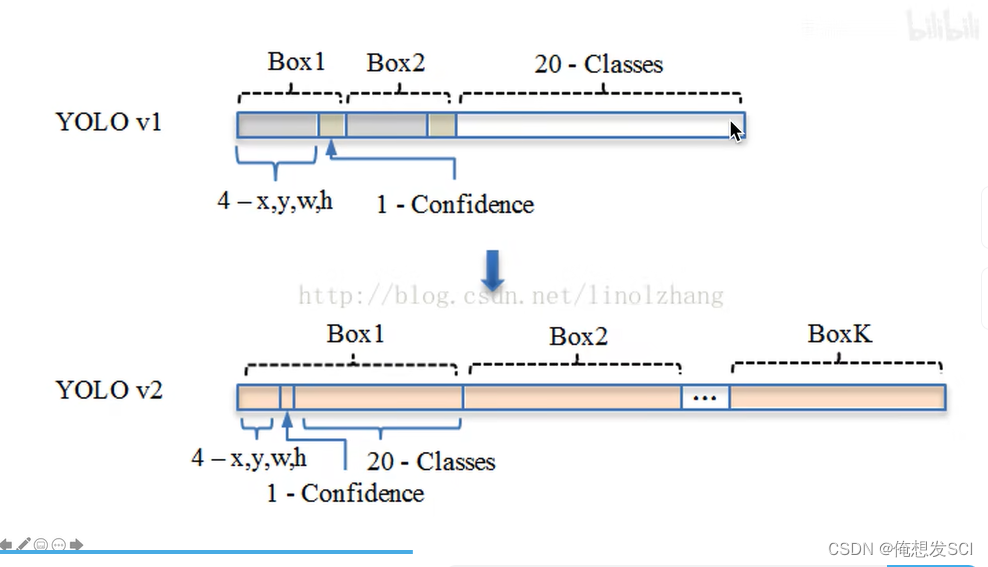
模型变化
YOLOv1
7*7gridcell 每个gc2个 boundingbox
YOLOv2
整个图片13*13 gc
每个gc 5个anchorbox
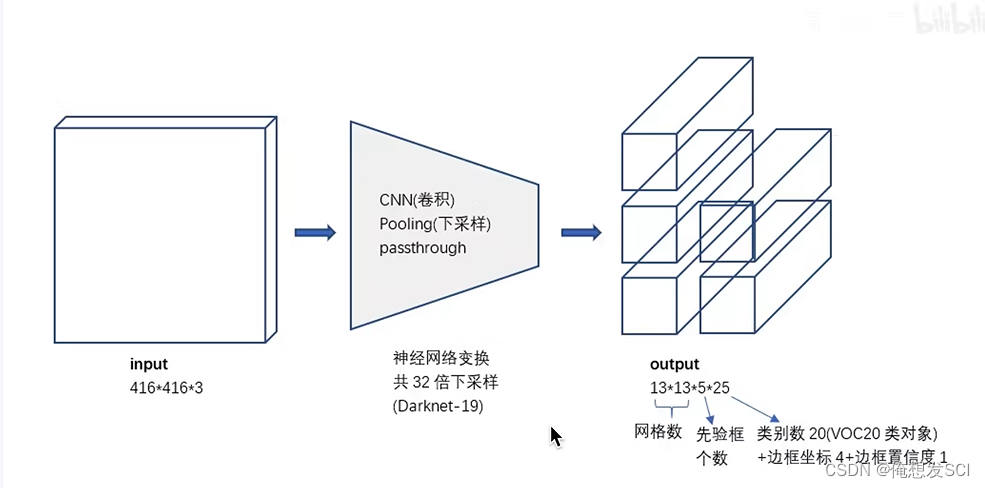
每个anchorbox 4+1+20(条件类别概率) =25个数 一共5*25=125个数 或者5*25维的矩阵
13*13*125维的张量
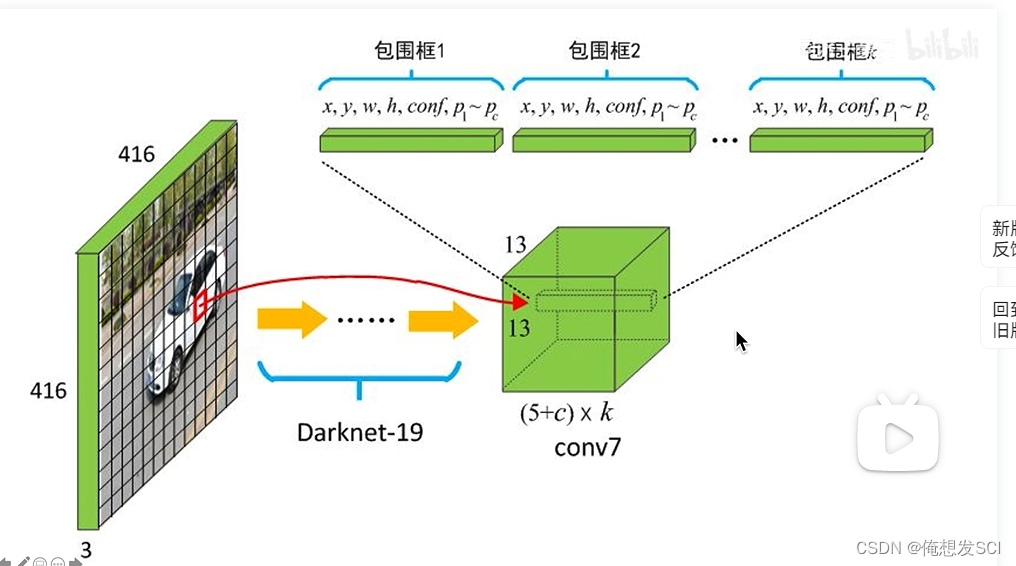
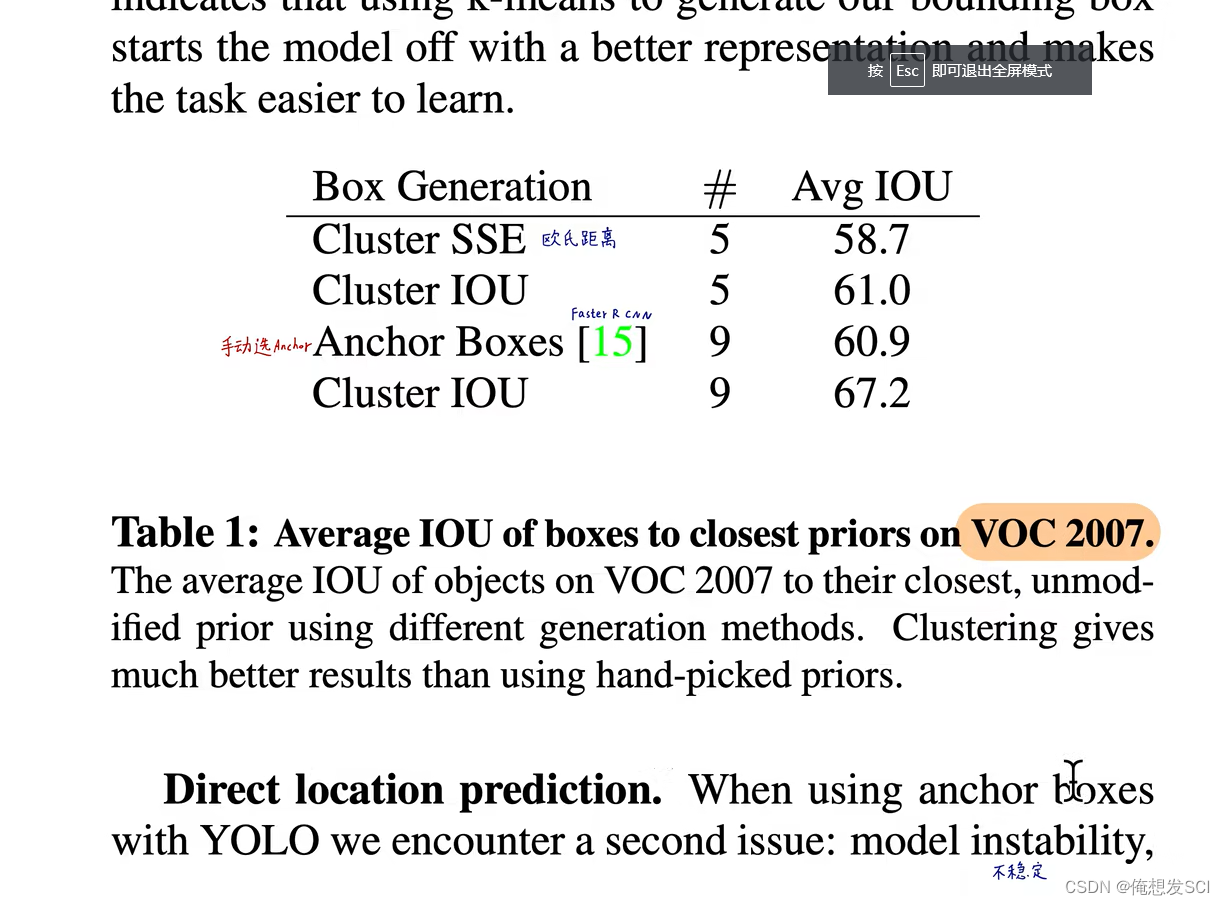
(4)Dimension Clusters.(维度聚类)
这里的话 k=5 5个anchor C=20 20个条件类别
5不是手动选择的 在fastrcn和ssd是人手工选择 什么比例1:1 2;1什么的 万一并不符合我们的数据集呢
比如长颈鹿 路灯
那对整个数据集进行了长宽比的聚类啦 不同聚类中心聚类个数对应不同的iou 聚类中心越多 anchor能覆盖的iou越大 但是anchor越大 模型越复杂------------------------取5啦
长宽比右图 黑框voc2007数据集的anchor长宽比 蓝色是coco的 coco的变化更多一些更复杂一些
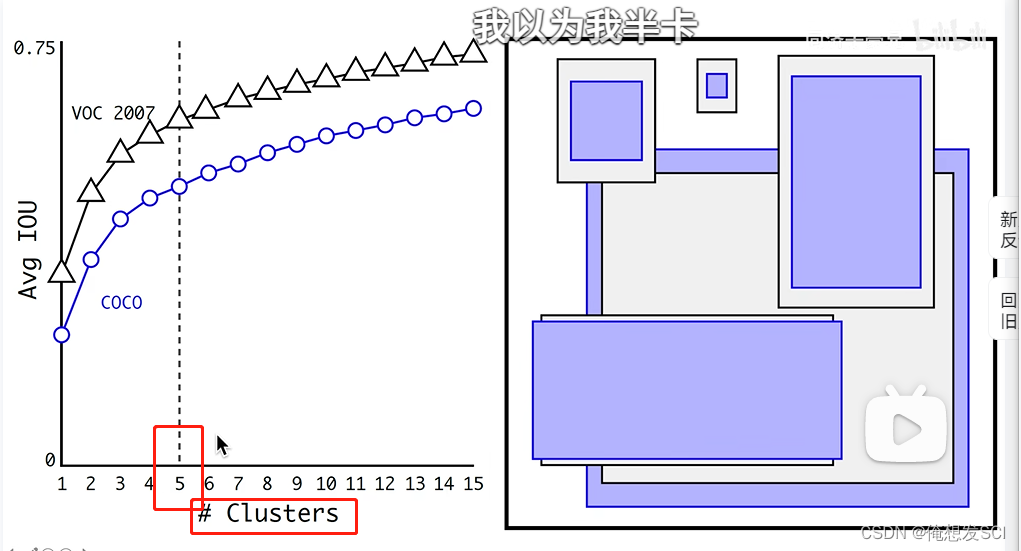

一直到v5也一直沿用聚类选anchor
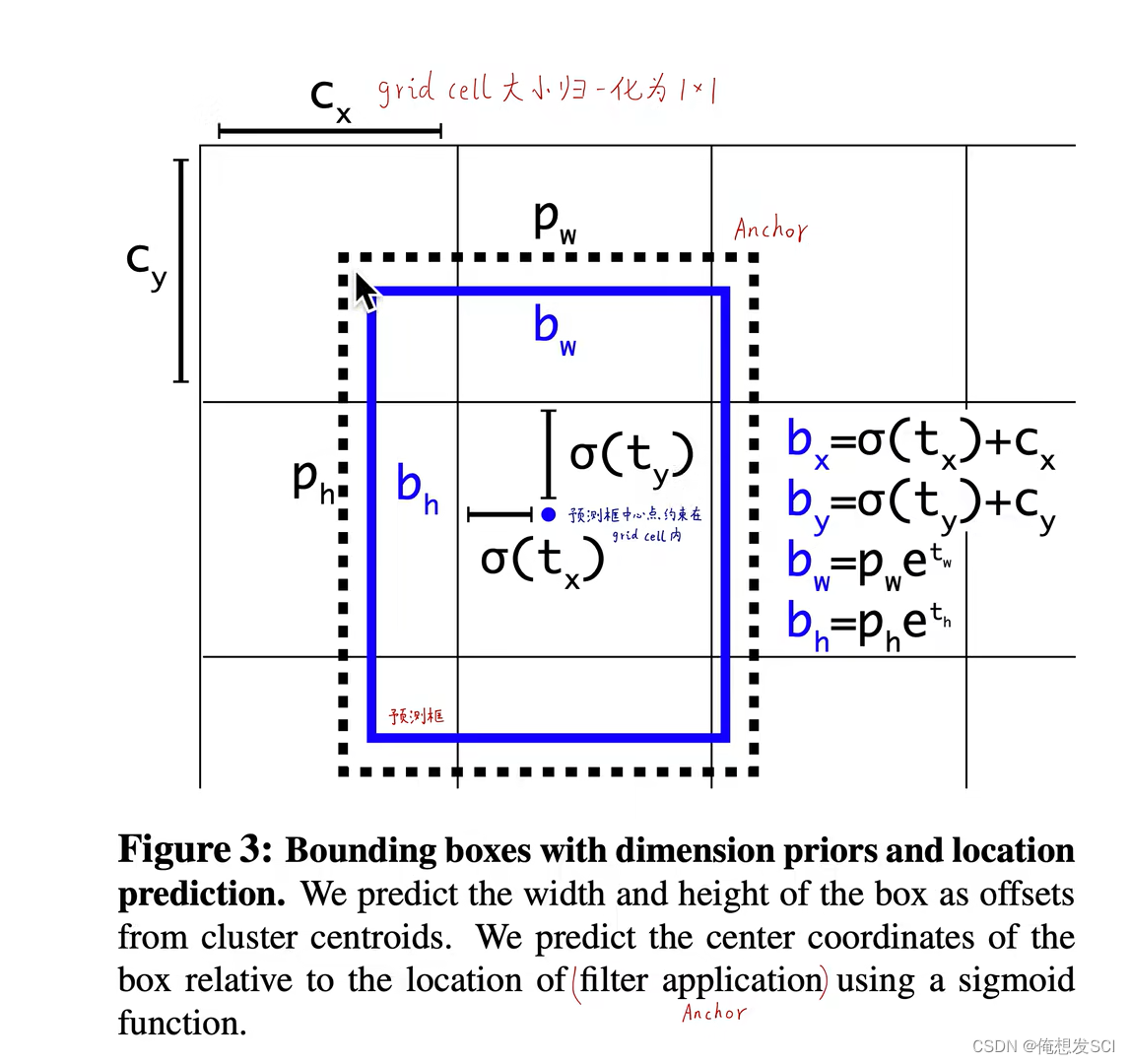
(5)Direct location prediction. (直接预测位置)
tx ty tw th 是偏移量可以是0-+无穷的任意数 也会导致野蛮生长 所以加了xigmo函数哈哈哈![]() 这是如来佛祖压制!!!!
这是如来佛祖压制!!!!
会把最终的输出压缩0-1之间 所以就把预测框的中心点限制了在它所在gc里面
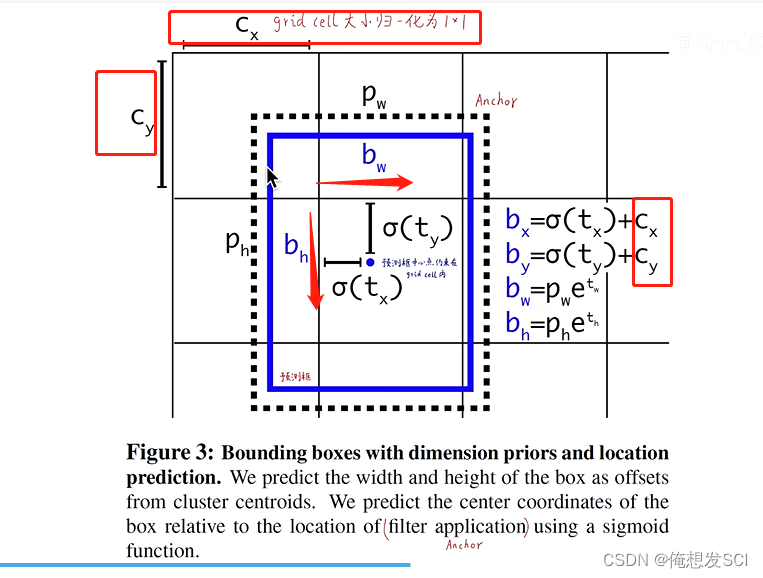

置信度和v1是一样的 相乘

conditional probability条件概率,既满足有物体这一条件下的概率。
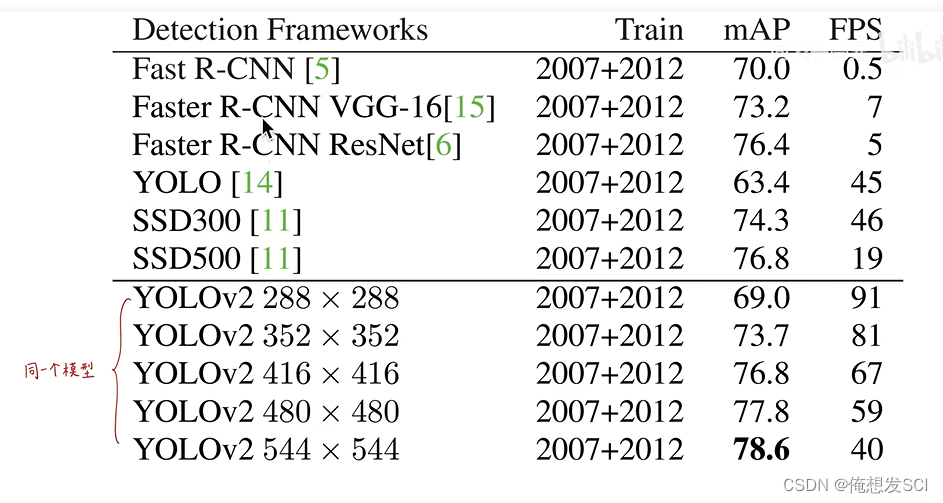
不用anchor:69.5%mAP,recall 81%。
用anchor:69.2mAP,recall 88%。精度下降0.3%,不过recall上升了 7%,v1里就不到一百个框,v2里变成不到一千个框了,多了这么多框recall肯定增加了,不过增加了这么多框,必然带来了更多无用的框,precision下降一点点也是可以理解的。
recall:真正目标被检测出来的比例。
precision:预测框中包含目标的比例。recall表示得找全,precision表示得找准。
损失函数 并没有特别提出 但是可以与v1进行比较
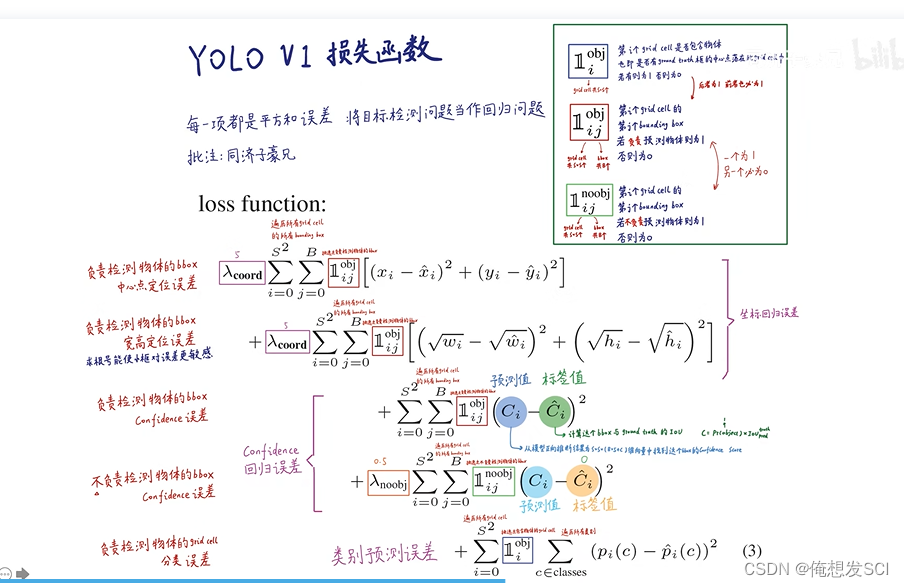
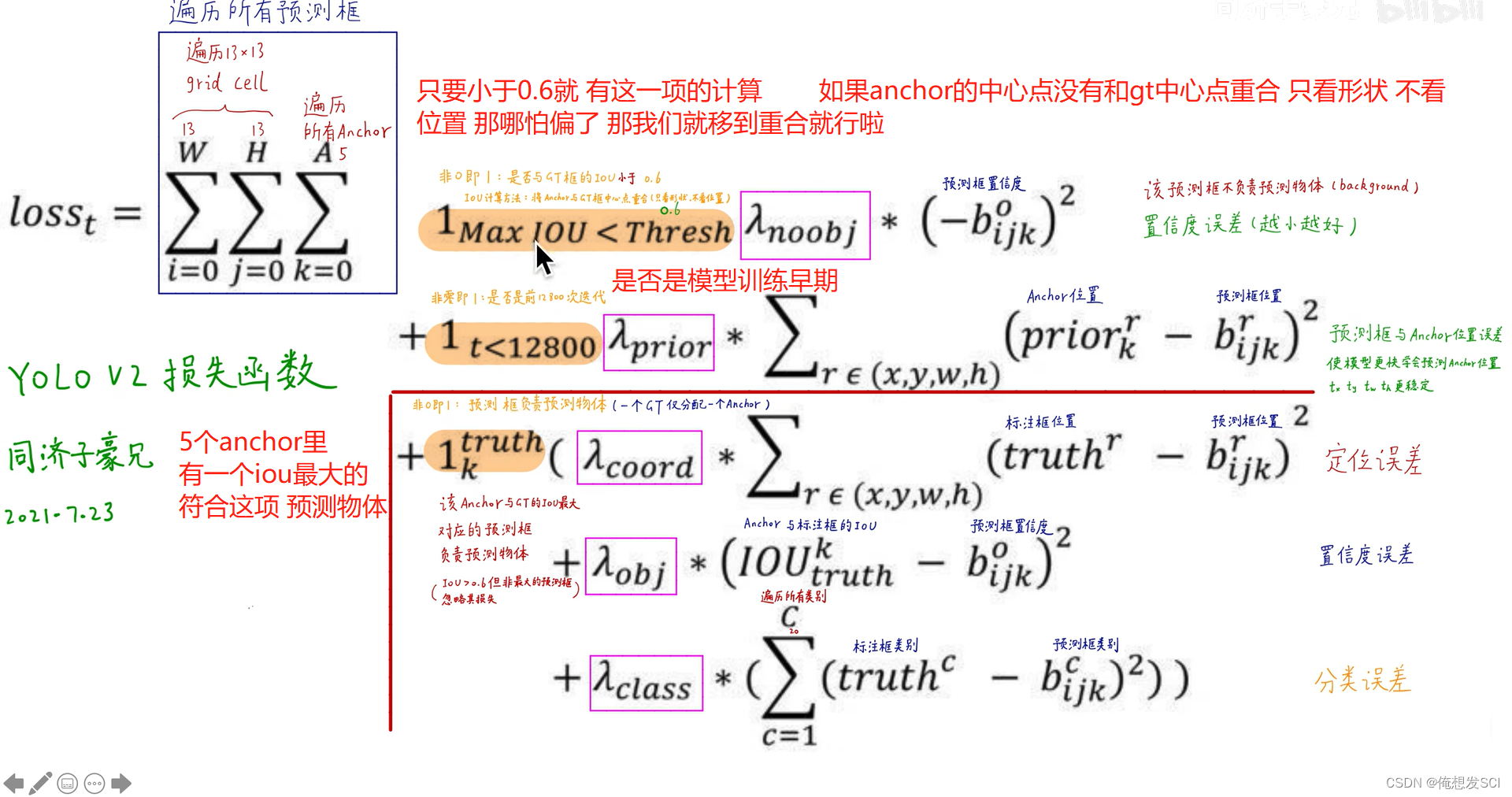
非0即1 那就是这一项要或者不要
第一项 《小于0.6》那就是被抛弃的孩子 他的预测框的置信度越0越号 (0-bijk) 标签值为0 没写出来
第二项 早期 定义各种xywh参数 要让anchor的四个参数与预测框的尽可能接近 loss才会越小 模型更快的学习 让一个框为大哥可能预测长条的物体 另一个是二弟 预测矮胖的物体 前期让他们各司其职!!! 模型更稳定
第三项 红框隔开
下面三个都是预测框预测物体 一个gt只分配给一个anchor
(高考状元 考的不好 考的还行但不是高考状元 忽略这些人的损失)
对于高考状元 :三个误差
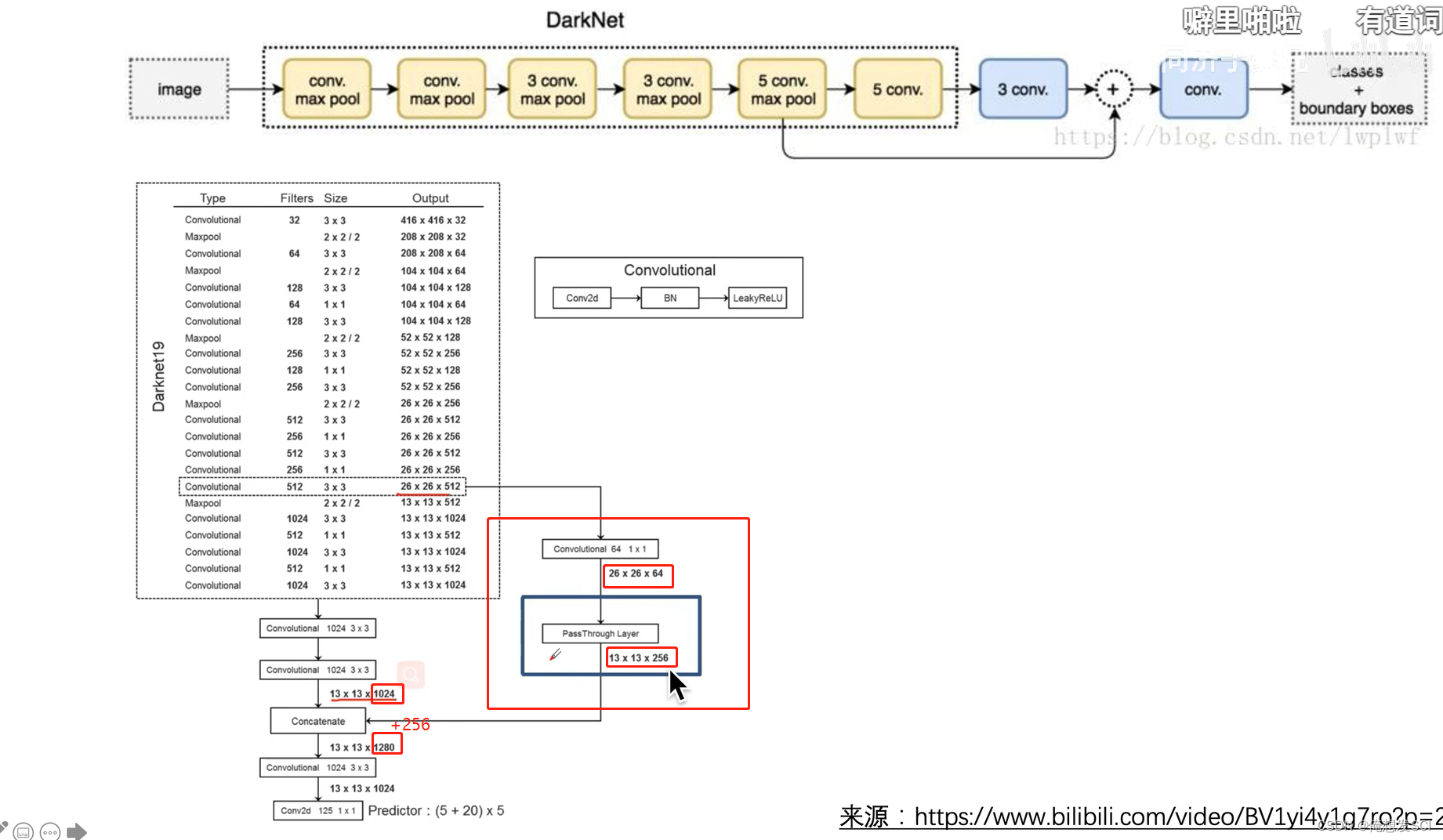
(6)Fine-Grained Features.(细粒度特征)

拆分变成更长条
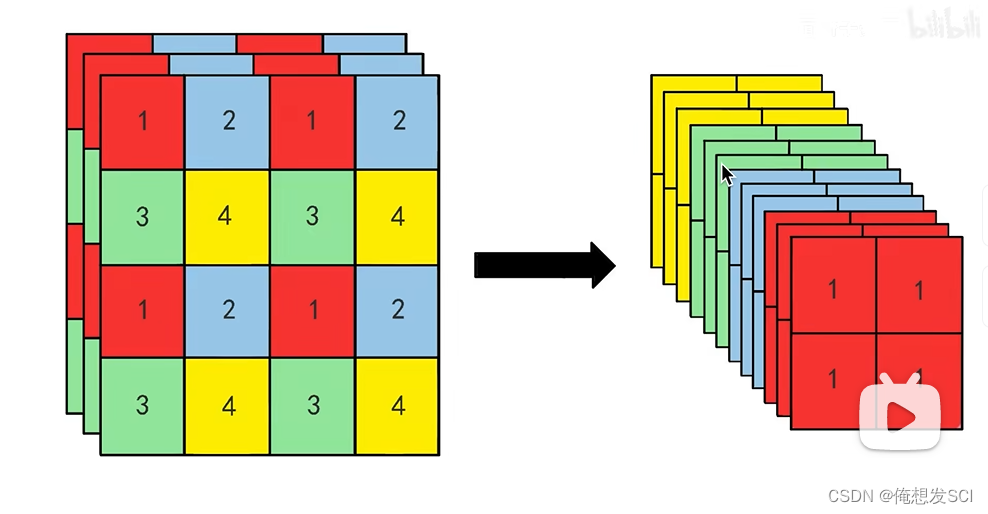
111拿出来 2222拿出来 相同拼一起 通道数扩展了 长宽变为原来一半 通道变成四倍
(7)Multi-Scale Training.(多尺度训练)

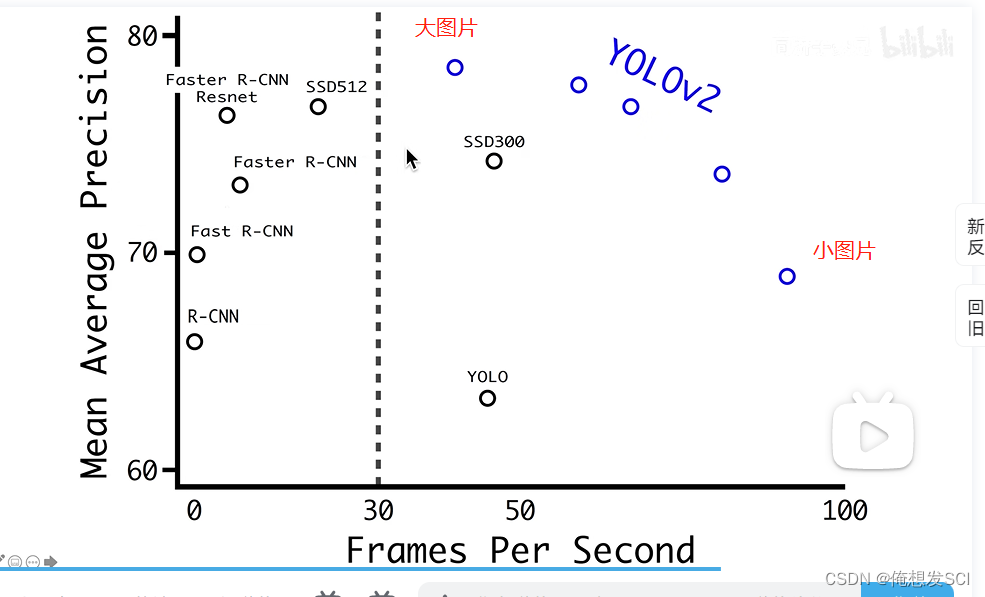
高分辨率的大图片 YOLO会比较慢 但是精度高
低分辨率的小图片YOLO快 但是精度差
5.Faster(更快)
数据集变成了 一堆放一堆

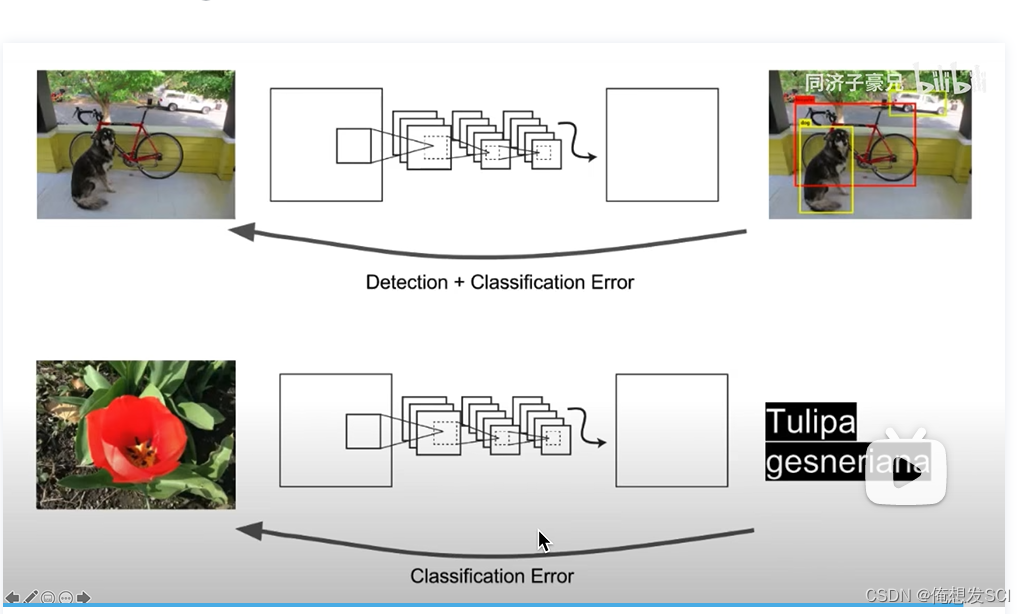
输入的若为目标检测标签的,则在模型中反向传播目标检测的损失函数。
输入的若为分类标签的,则反向传播分类的损失函数



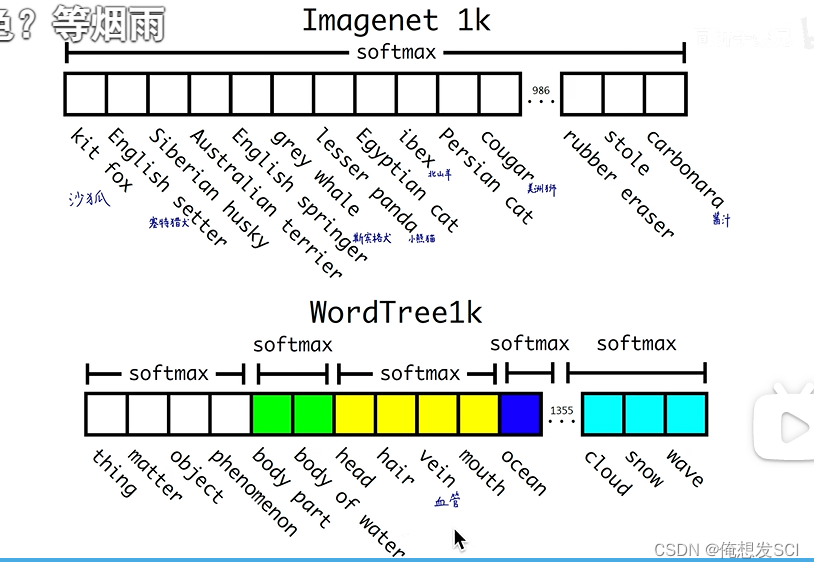
我们想目标检测也能达到图像分类的级别 但是从数据上就卡脖子了 标注目标检测是很高成本 表框框和类别
但是图像分类是低成本的(猫狗识别)

We also propose a joint training algorithm that allows us to train object detectors on both detection and classification data. Our method leverages labeled detection images to learn to precisely localize objects while it uses classification images to increase its vocabulary and robustness.
我们还提出了一种联合训练算法,使我们能够在检测和分类数据上训练目标检测器。我们的方法利用有标签的检测图像来学习精确定位物体,同时使用分类图像来增加词表和鲁棒性。
recall 就是将所有目标全部检出的能力较弱


一个epoch是把训练集中的所有都喂进去
一个batchsize就把batchsize大小的喂进去
先验框 知道数据集中有很多车 就预先设置矮胖的框


我们从YOLO中移除全连接层,并使用Anchor框来预测边界框。首先,我们去除了一个池化层,使网络卷积层输出具有更高的分辨率。我们还缩小了网络,操作416×416的输入图像而不是448×448。我们这样做是因为我们要在我们的特征图中位置个数是奇数,所以只会有一个中心格子。目标,特别是大目标,往往占据图像的中心,所以在中心有一个单独的位置来预测这些目标的很好的,而不是四个都相邻的位置。YOLO的卷积层将图像下采样32倍,所以通过使用416的输入图像,我们得到了13×13的输出特征图。

当我们移动到Anchor框时,我们也将类预测机制与空间位置分离,预测每个Anchor框的类别和目标。与YOLO类似,是否为目标的预测仍然预测了真值和proposal的边界框的IOU,并且类别预测预测了当存在目标时该类别的条件概率。
使用Anchor框,我们的精度发生了一些小的下降。YOLO对每张图像只预测98个边界框,但是使用Anchor框我们的模型预测超过一千个。如果不使用Anchor框,我们的中间模型将获得69.5的mAP,召回率为81%。使用Anchor框的模型得到了69.2 mAP,召回率为88%。尽管mAP下降了一点,但召回率的上升意味着我们的模型有更大的改进空间


不手工指定了 而用kmeans聚类


IOU值大 才好 d小
(5)Direct location prediction. (直接预测位置)




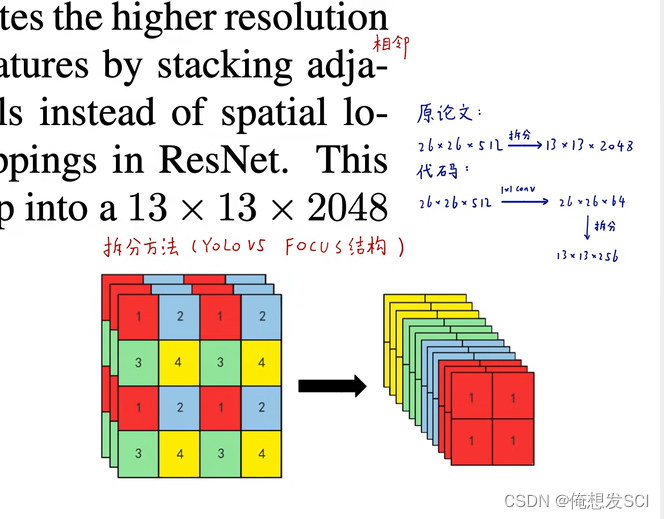




Darknet 新的分类网络用到YOLOv2里
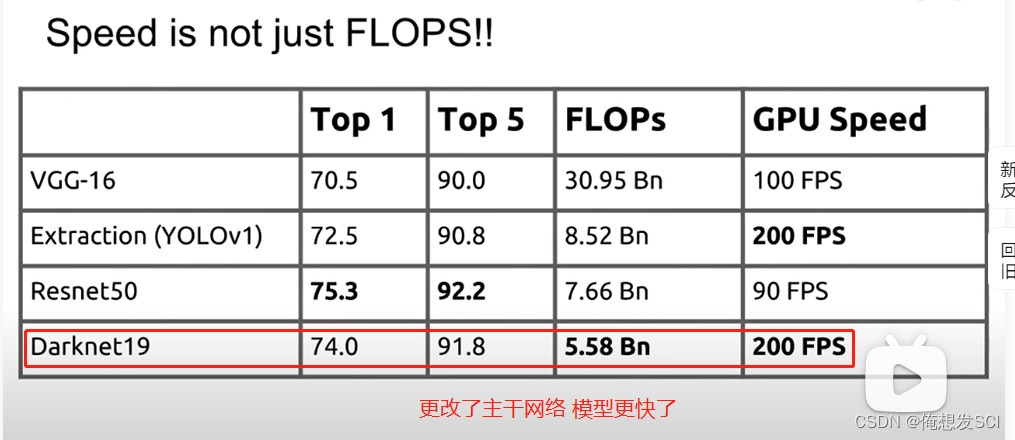
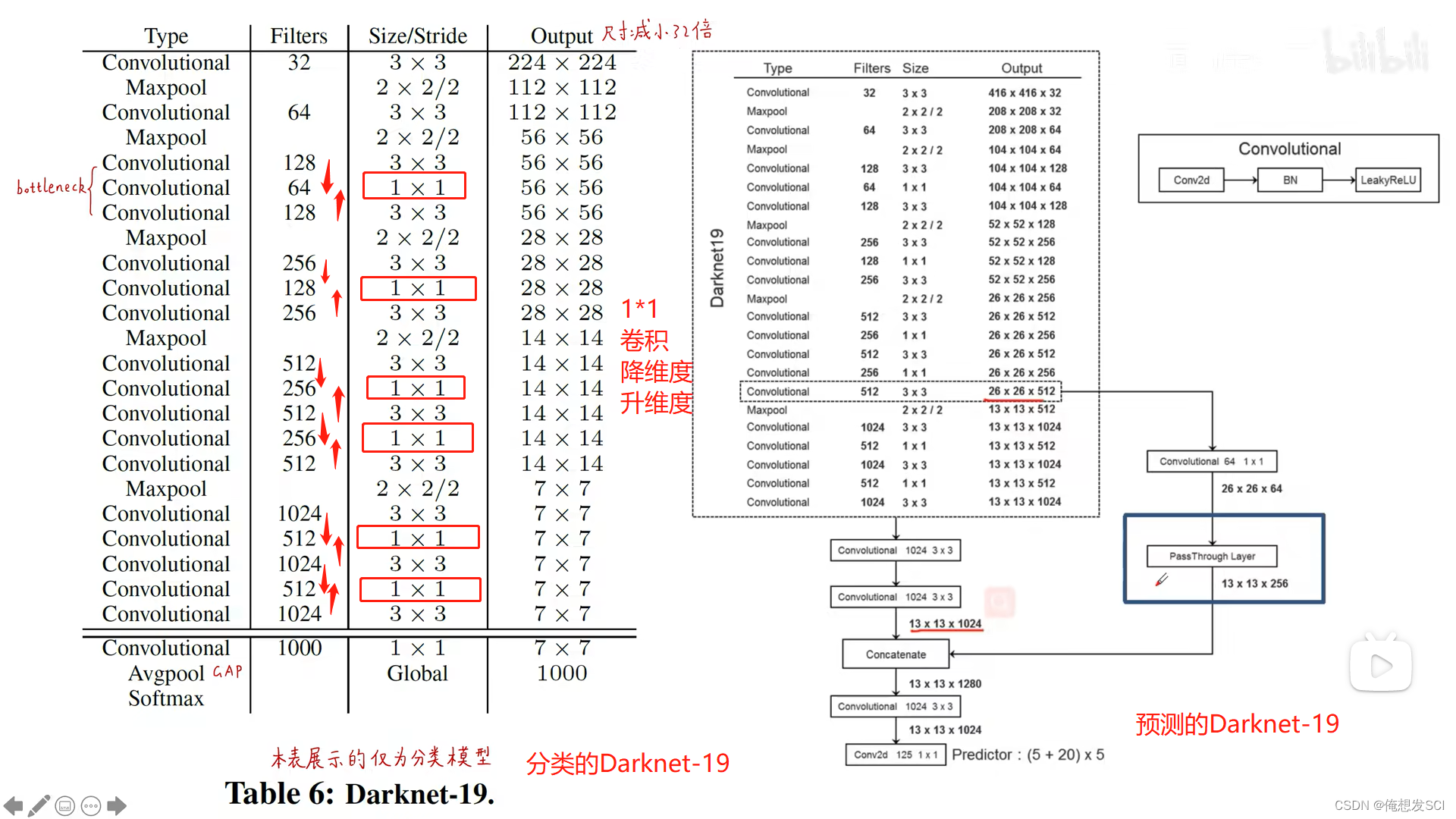
Darknet-19。我们提出了一个新的分类模型作为YOLOv2的基础。我们的模型建立在网络设计先前工作以及该领域常识的基础上。与VGG模型类似,我们大多使用3×3卷积核,并在每个池化步骤之后使得通道数量加倍[17]。按照Network in Network(NIN)的工作,我们使用全局平均池化的结果做预测,并且使用1×1卷积核来压缩3×3卷积之间的特征表示[9]。我们使用批归一化来稳定训练、加速收敛,并正则化模型[7] 去掉了全连接层
第一部分:
BN分类器
anchor 聚类得到
输出的值限制 就是滑动的图
加细粒度特征的直通层
多尺度训练
faster方面改进骨干网络
第二部分:
stronger




传送带:大佬们的文章
目标检测经典论文——YOLOV2论文翻译:YOLO9000: Better, Faster, Stronger(YOLO9000:更好、更快、更强)_bigcindy的博客-CSDN博客YOLO9000: Better, Faster, StrongerYOLO9000:更好、更快、更强Joseph Redmon*†, Ali Farhadi*†University of Washington*, Allen Institute for AI†http://pjreddie.com/yolo9000/AbstractWe introduce YOLO9000, a state-of-the-art, real-time ob...https://blog.csdn.net/Jwenxue/article/details/107706348【目标检测 论文精读】……YOLO-V2 & YOLO9000 ……(YOLO9000: Better, Faster, Stronger)_深度不学习!!的博客-CSDN博客_yolov2论文下载anchor和bbox的区别。yolo9000 & yolov2 论文精读
https://blog.csdn.net/qq_38737428/article/details/124865549?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165864087116782184614684%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=165864087116782184614684&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~pc_rank_34-1-124865549-null-null.142%5Ev33%5Epc_rank_34,185%5Ev2%5Econtrol&utm_term=%E3%80%90%E7%B2%BE%E8%AF%BBAI%E8%AE%BA%E6%96%87%E3%80%91YOLO%20V2%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B&spm=1018.2226.3001.4187















 2797
2797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









