






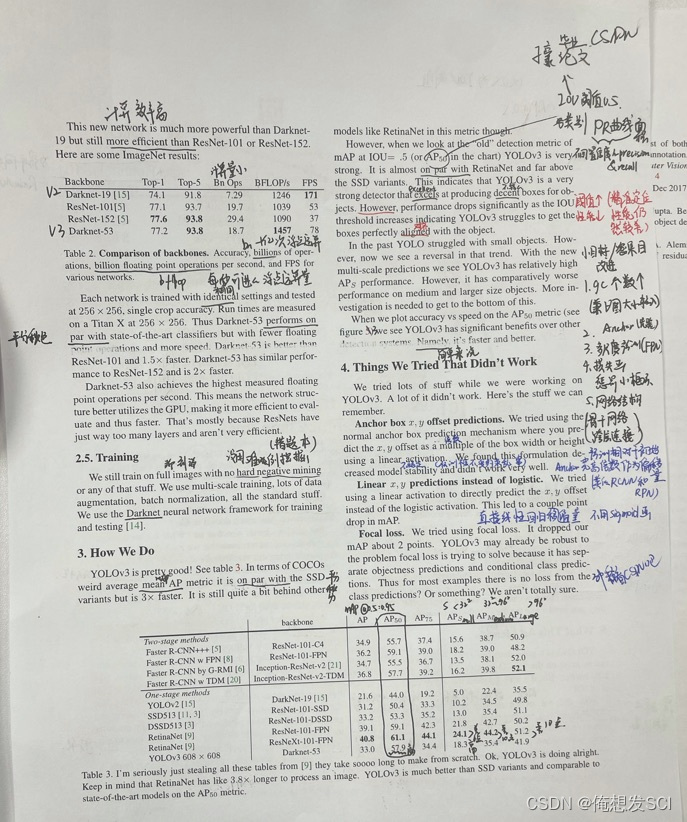
YOLOv3性能 作者直接把性能花在Retinanei数据图上了
左图是不同阈值 右图是阈值0.5
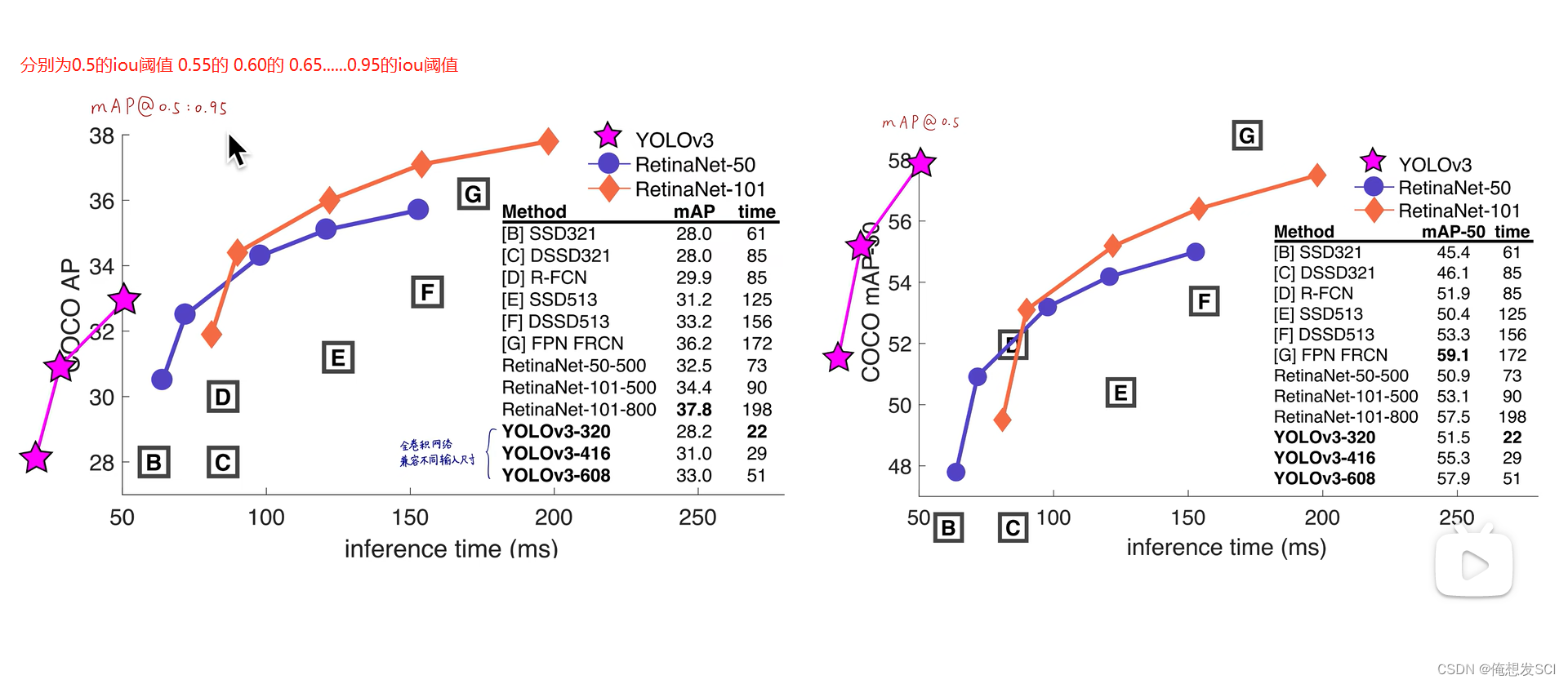
map就是算出的所有阈值的ap做平均
为啥第一个图比第二个图低呢? 因为第一个图是阈值达到0.95 那得和标注的多重合啊 那得多了不起啊 so 肯定没有那么强 就低了点 。而第二个阈值0.5 重合0.5就行 那就肯定比0.95高啊
反正作者说了 高阈值性能不科学哈哈哈哈

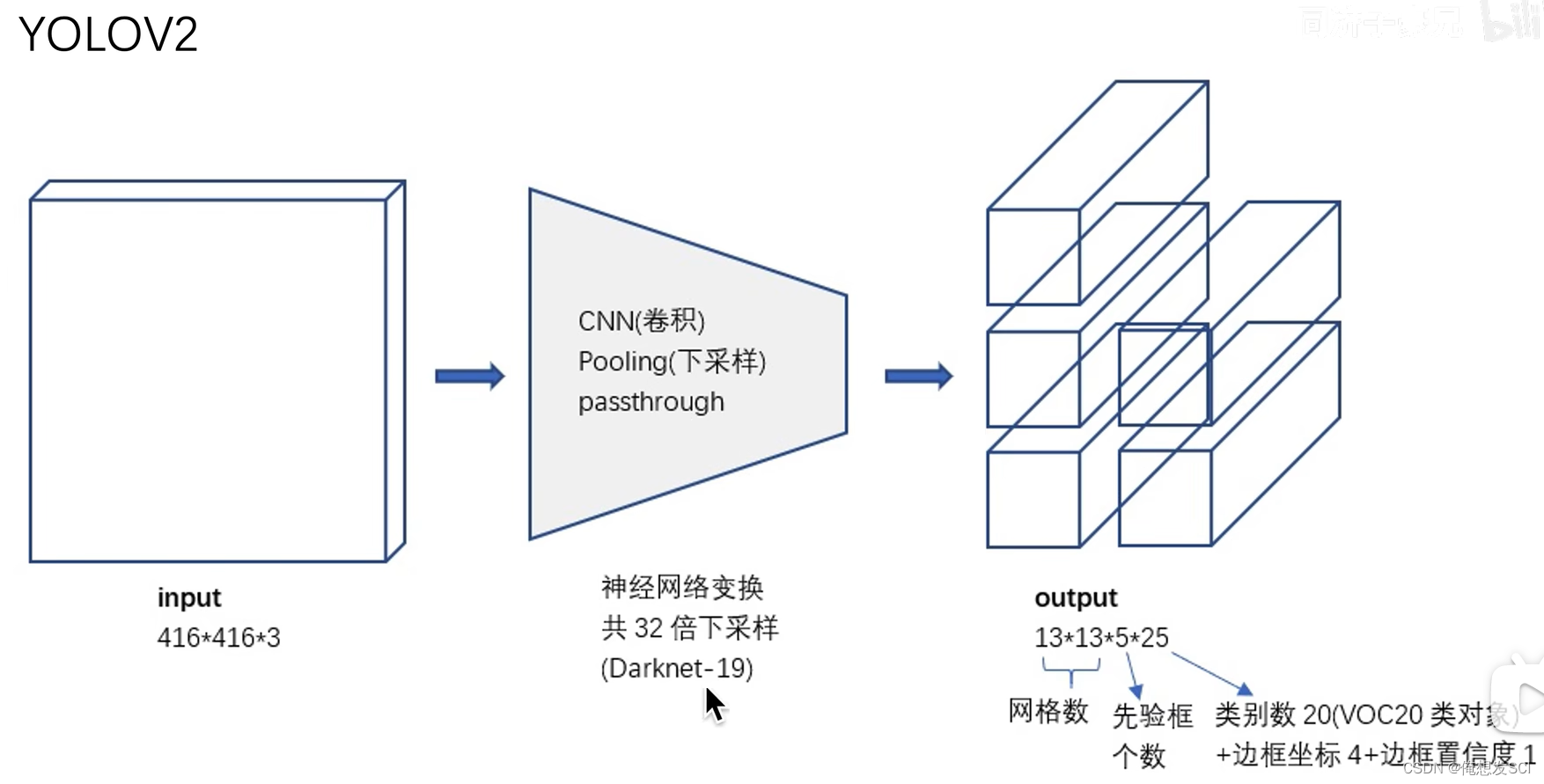
YOLOV2是Darknet-19 有19层
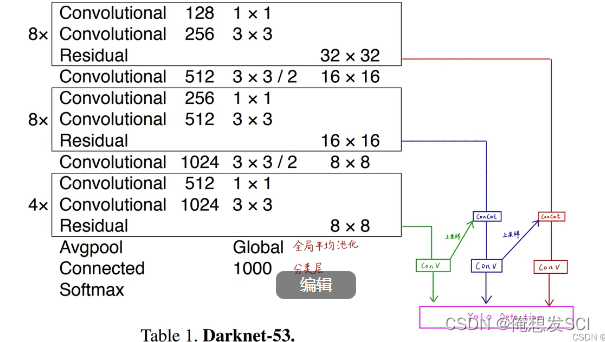
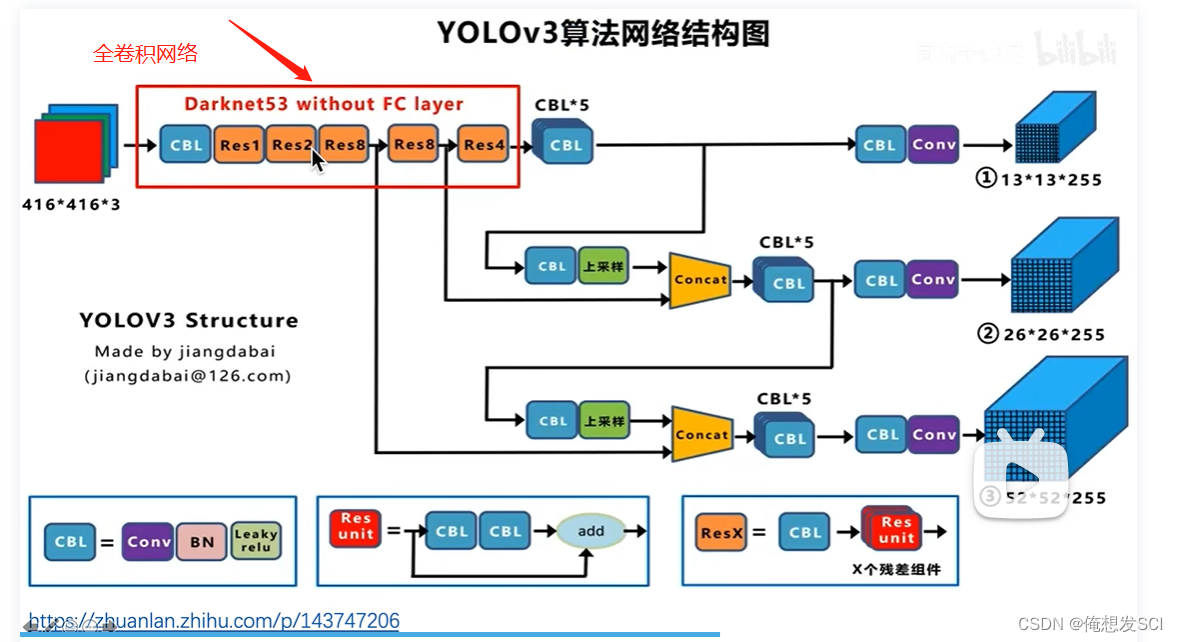
53 就是52个卷积和一个全连接层 并且里面加了残差连接

骨干网络最最重要啦 !!!!!!!!!!!!!!!!各个领域都是以骨干网络提取的特征来进行后处理得到的!! 他是提供食材的人 目标检测头 或者关键点检测头是做饭的厨师
52个卷积 是把所有的convolutional加上 不算residual哦 一共是52 然后加上最后的全连接层=53
训练好这个IMagnet一千分类的骨干网络之后 后面的全局平均池化层拿掉 他就是作为特征提取器
注意里面的步长为2哦 可能是2导致的下采样


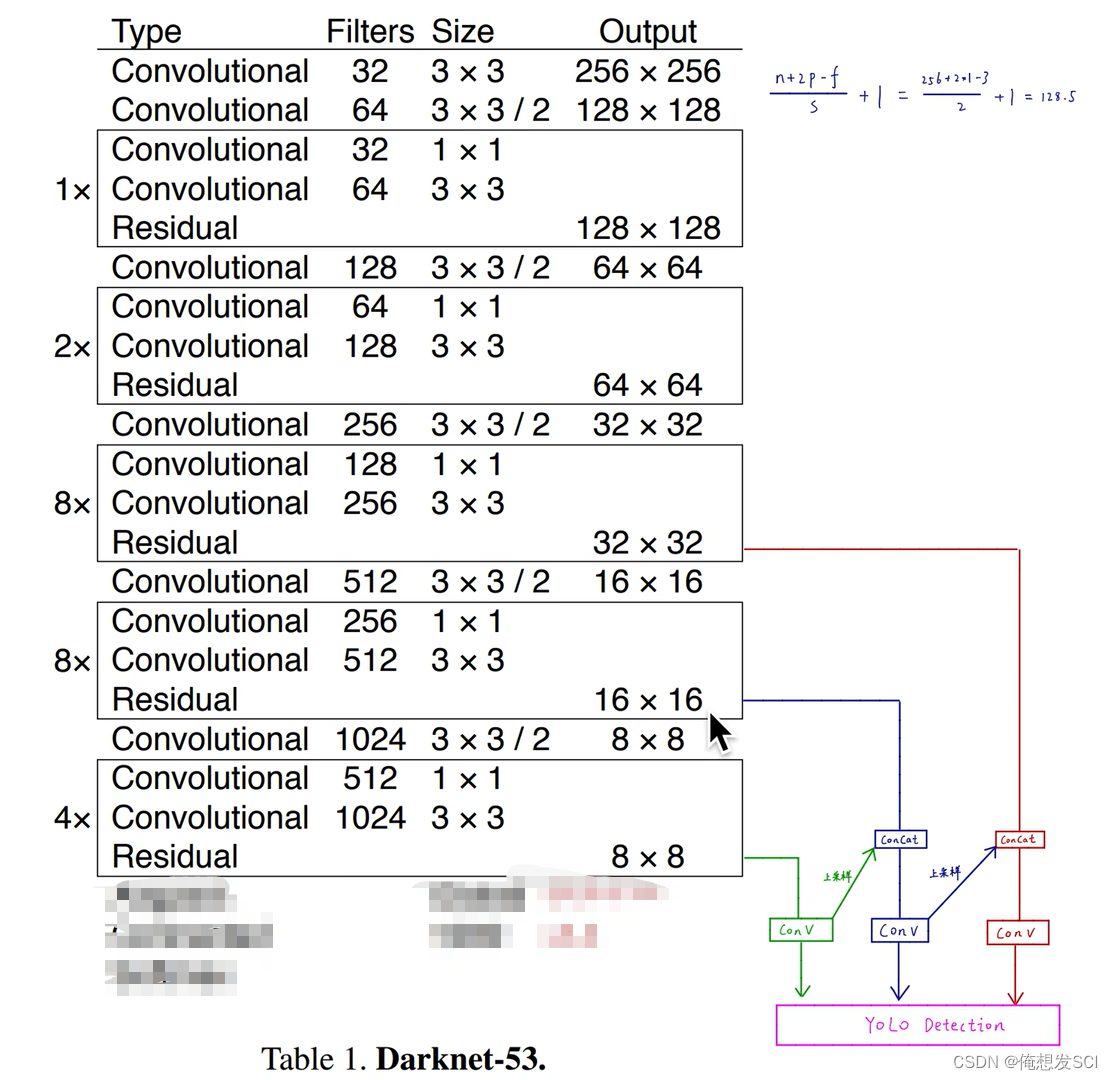
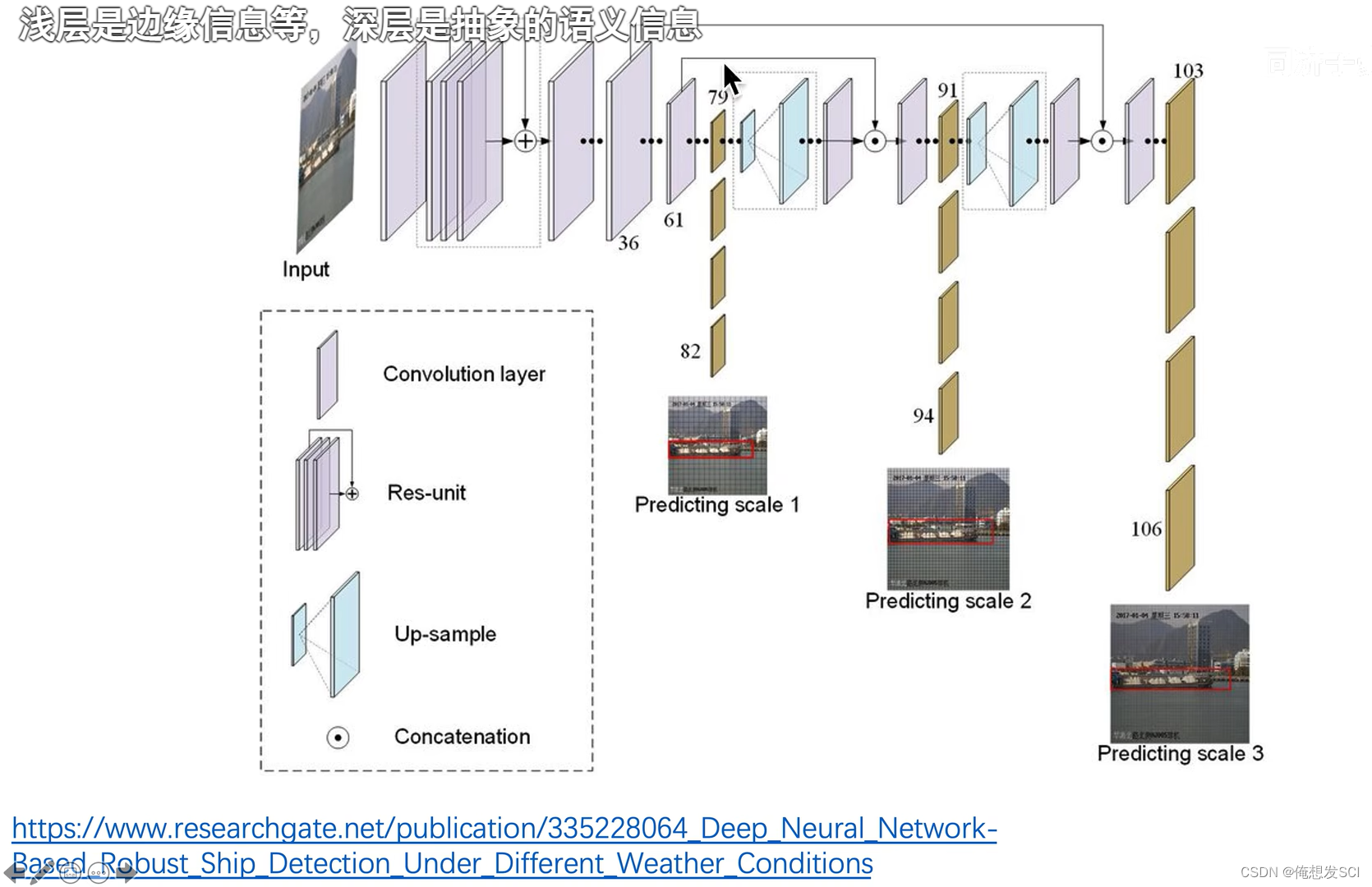
输入图像得到三种尺度特征 在进行后续多尺度目标检测。
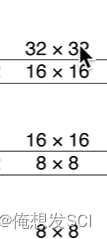
 这三个尺度分别下采样了32 16 8倍
这三个尺度分别下采样了32 16 8倍
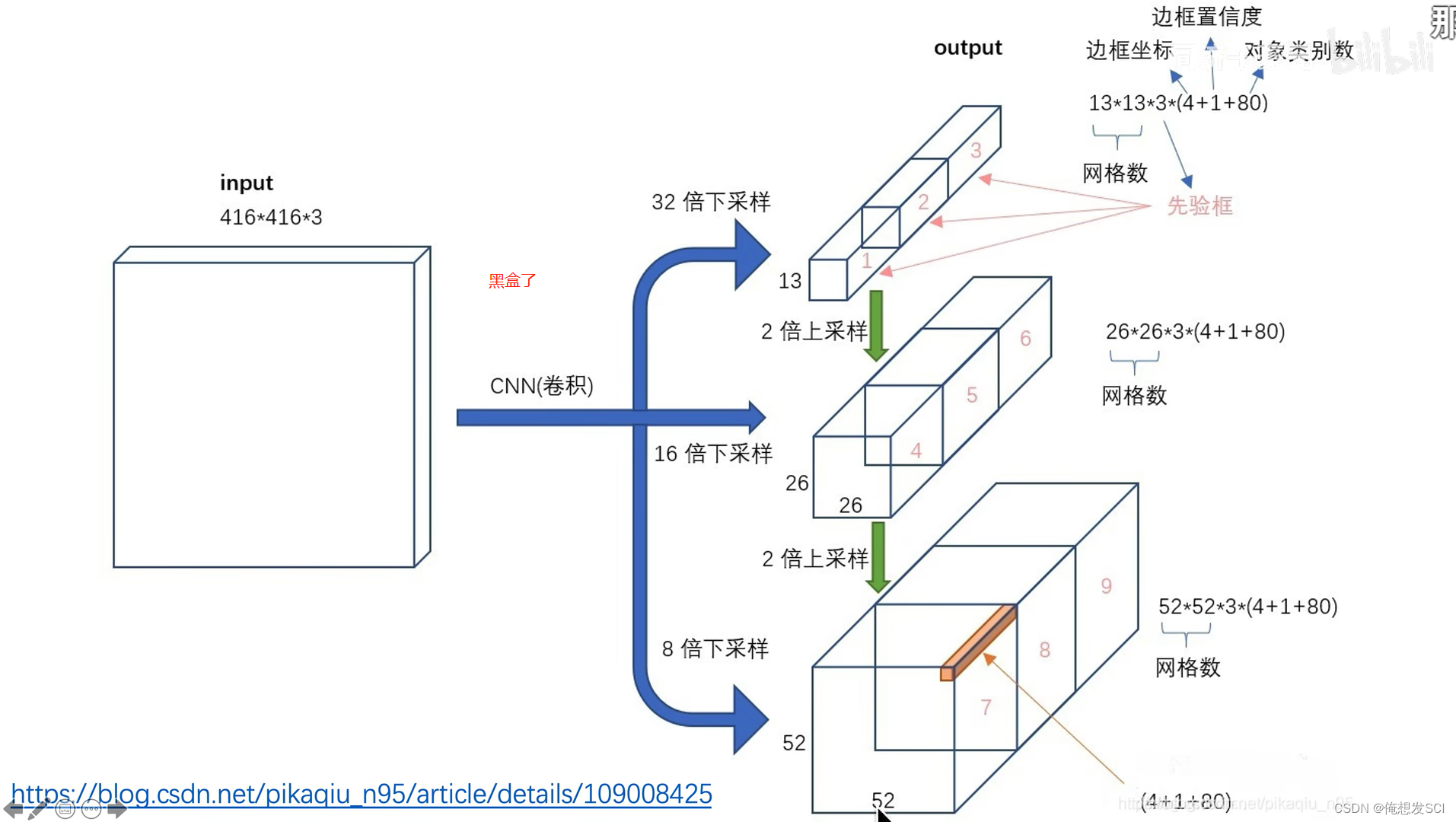
如果输入416*416 图片 下采样:416/32=13*13 26*26 416/8= 52* 52
因为把后面的分类头拿掉 他就变成了全卷积网络 里面没有全连接层 所以可以兼容任意尺度的图像
256 608 416 只要是32的倍数 因为我们下采样是32的倍数哦
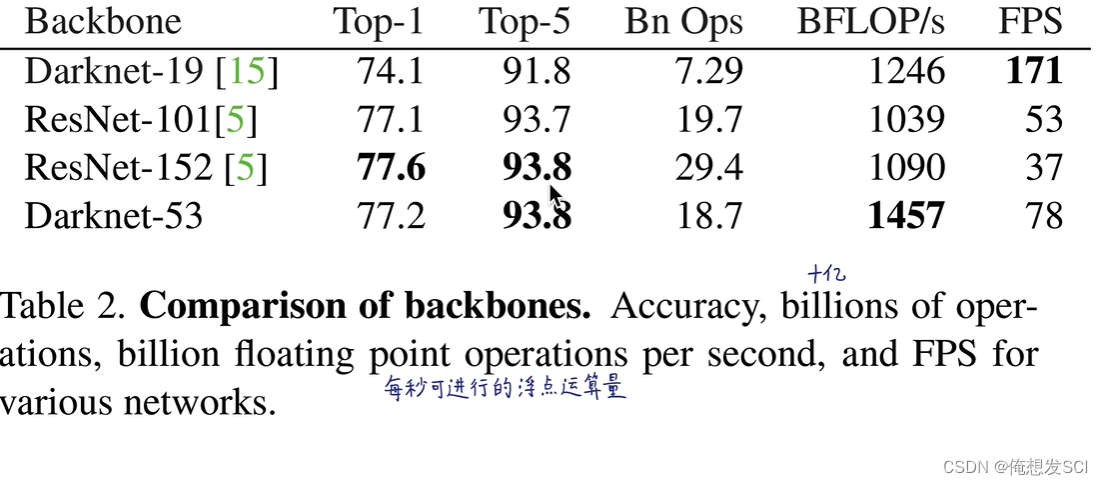
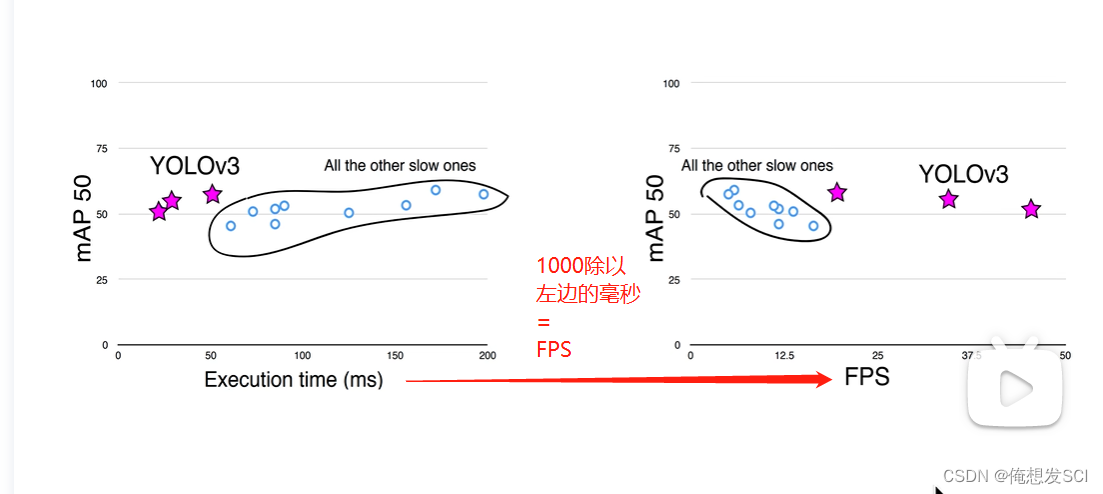
第二个坐标开始 : 性能不错 运算量小 更高效运算GPU fps更臃肿一些 有点慢 但是也高于v1用的19
浮点运算量 更高效利用GPU
v1 gridcell=7 24层卷积2全连接层 boundingbox

v2 gridcell=13 Darknet-19 18卷积+1全连接层 anchor(先验框 是那种已经差不多检验高瘦物体的anchorbox就都是那种高瘦的anchorbox)
知乎江da白绘制的图
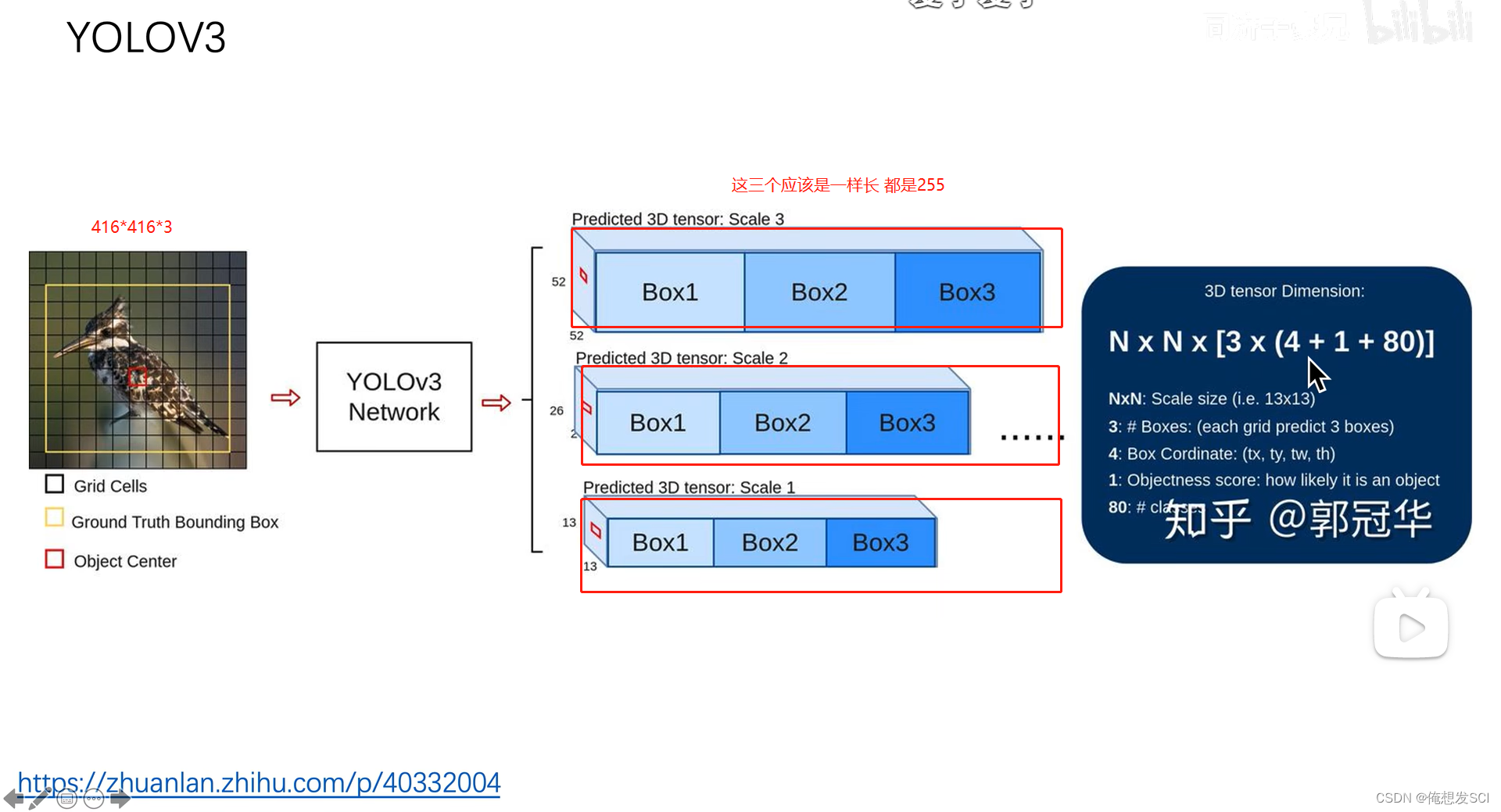
输入416*416*3 输出 是三个尺寸的featuremap13*13*255、 26*26255、52*52*255
255---------------3* 85 3:每个gc生成3个anchor 每个anchor对应一个预测框 每个预测框对应5+80维 5:xywhc coco数据集80个类别的条件类别概率
13*13*255对应原图像的感受野就是32*32、 那也就是说13*13负责预测大物体
因为416/13=32 那个13就是分格格呀 gc啦
26*26255 16*16、 中等
52*52*255 8*8 、 小物体

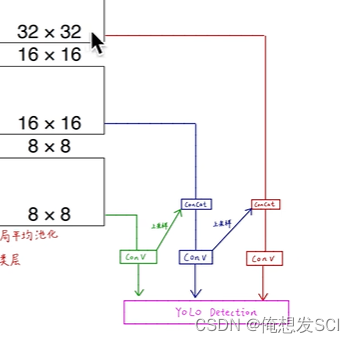
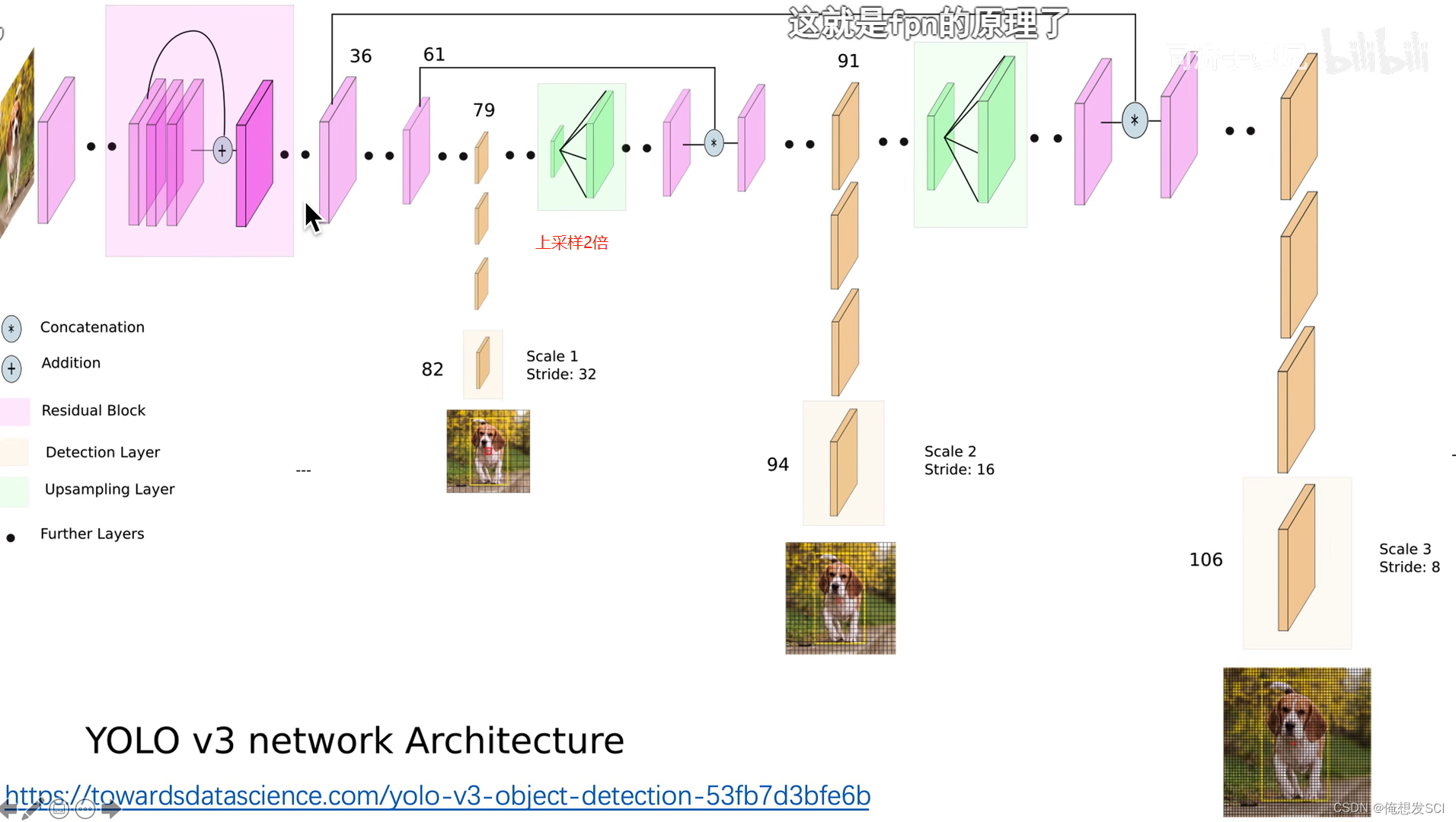
上采样2倍(3*2 =26) 在和骨干网络26*26尺度的特征进行拼接 经过处理得到26*26*255
concat : 两个作业本摞起来的操作 两个本厚度不一样 就沿着厚度方向摞起来
26*26这个也上采样2倍(26*2=52)和骨干网络52*52尺度的特征拼接 处理得到 52*52*255的特征
也就是说: 其实最后那个52*52*255的特征 融合了前面26*26特征 也融合了13*13的特征

发挥了深层网络的语义特化抽象的特征 也充分利用了浅层网络的细粒度的像素级别的边缘转角结构信息的底层特征
多尺度特征融合 不同尺度物体检测
条件概率: 假设这个框已经存在物体了 他是猫的概率 狗的概率



骨干 颈部 头
Backnone提取 Neck融合特征fpn head最终预测结果 
骨干 是全卷积网络 没有全连接 可以兼容32倍数的不同尺度

共有9个anchor
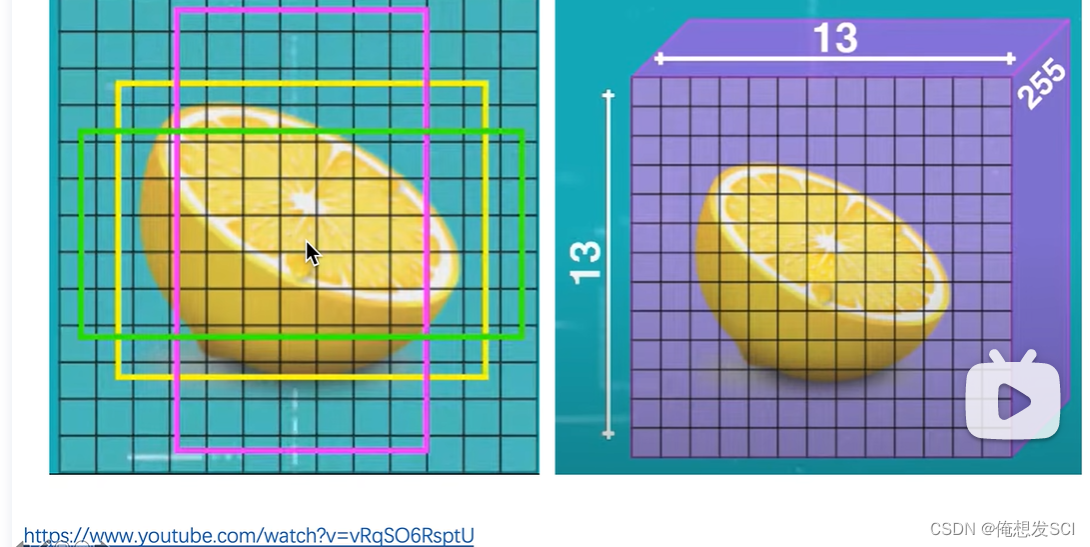
不再看物体中心点落在哪个gridcell里了 看谁的anchor的iou与物体的iou最大 由大的那个anchor(预测框)预测物体
非最大的就不是正样本
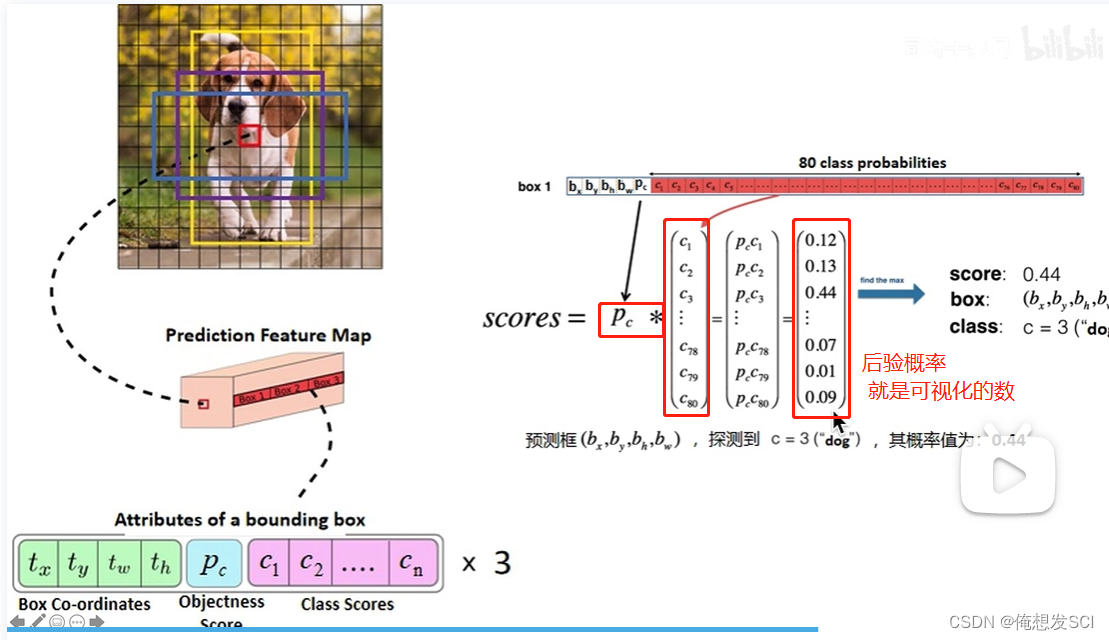
后验概率的置信度 可视化能看见每个框能看见是数字
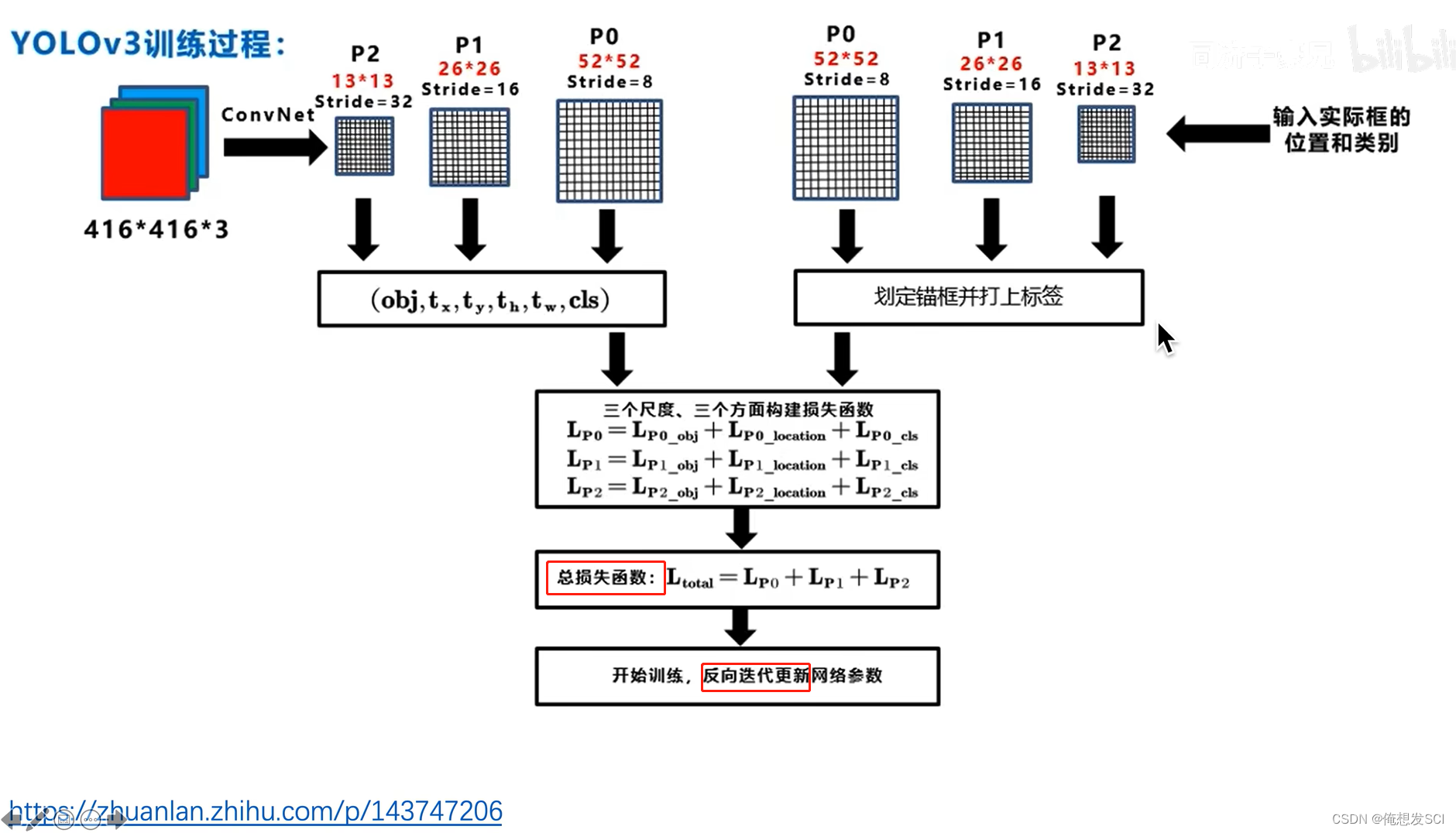
YOLOV3 过程
狗人工标注的黄色框 中心点是红色的那个框吧
红色那个gc会有三个anchor 找到与标注框iou最大的那个anchor 用他来预测物体


 YOLOV1是最多98个
YOLOV1是最多98个



输入图像越大 得到的gridcell也大预测框的数量就是gridsize的数量*3 ,得到的三个尺度的预测框数量也多 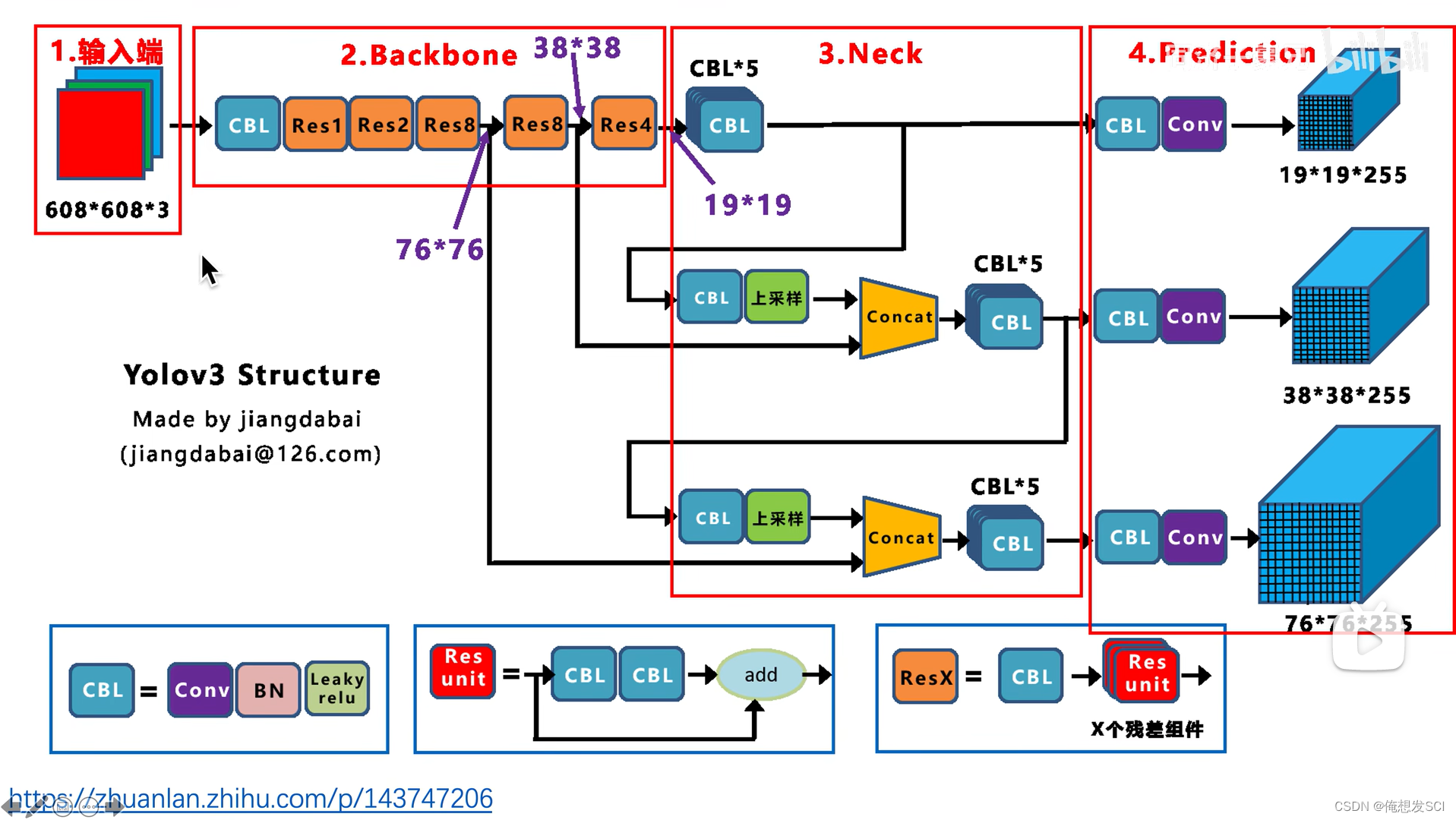


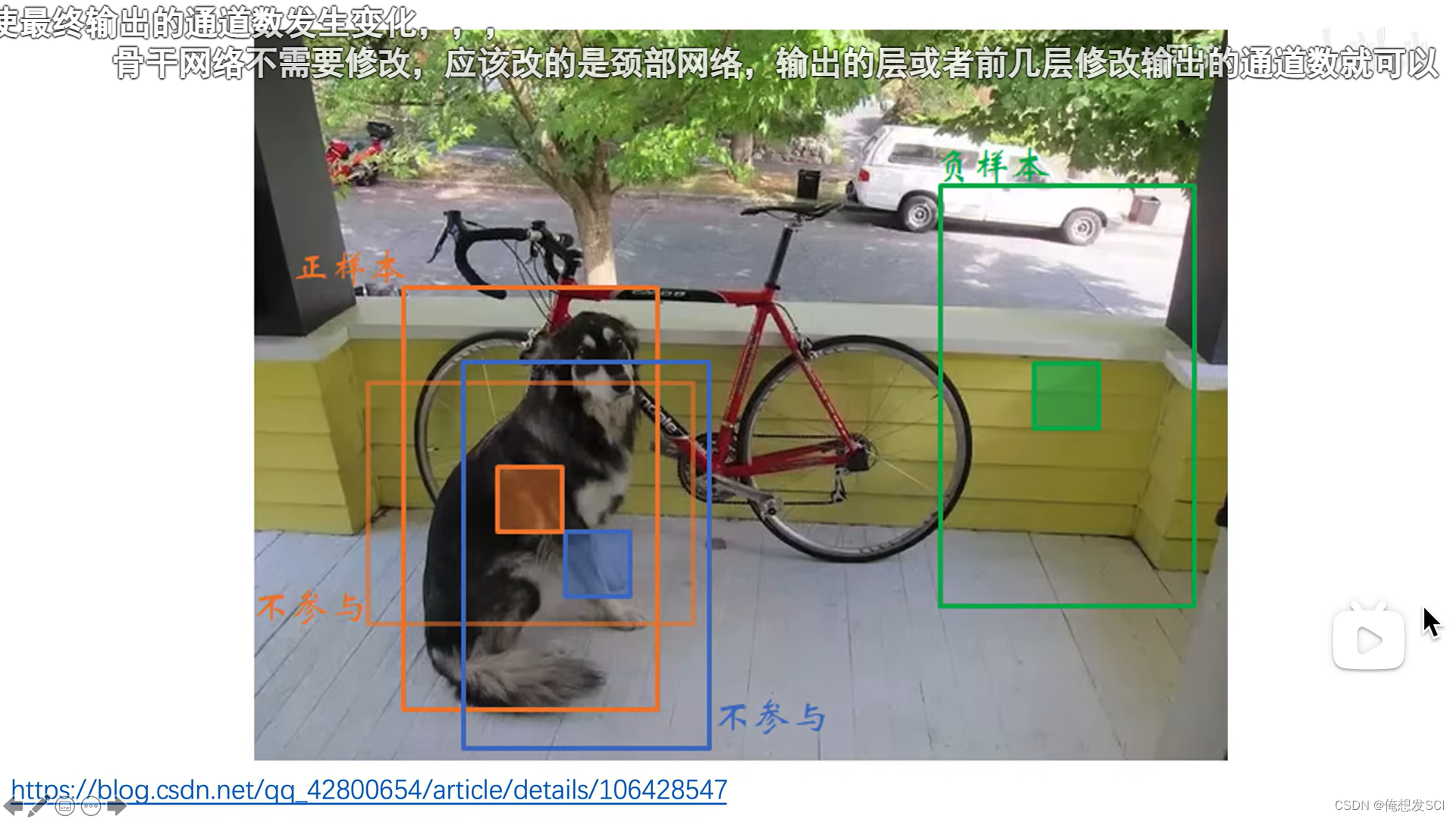
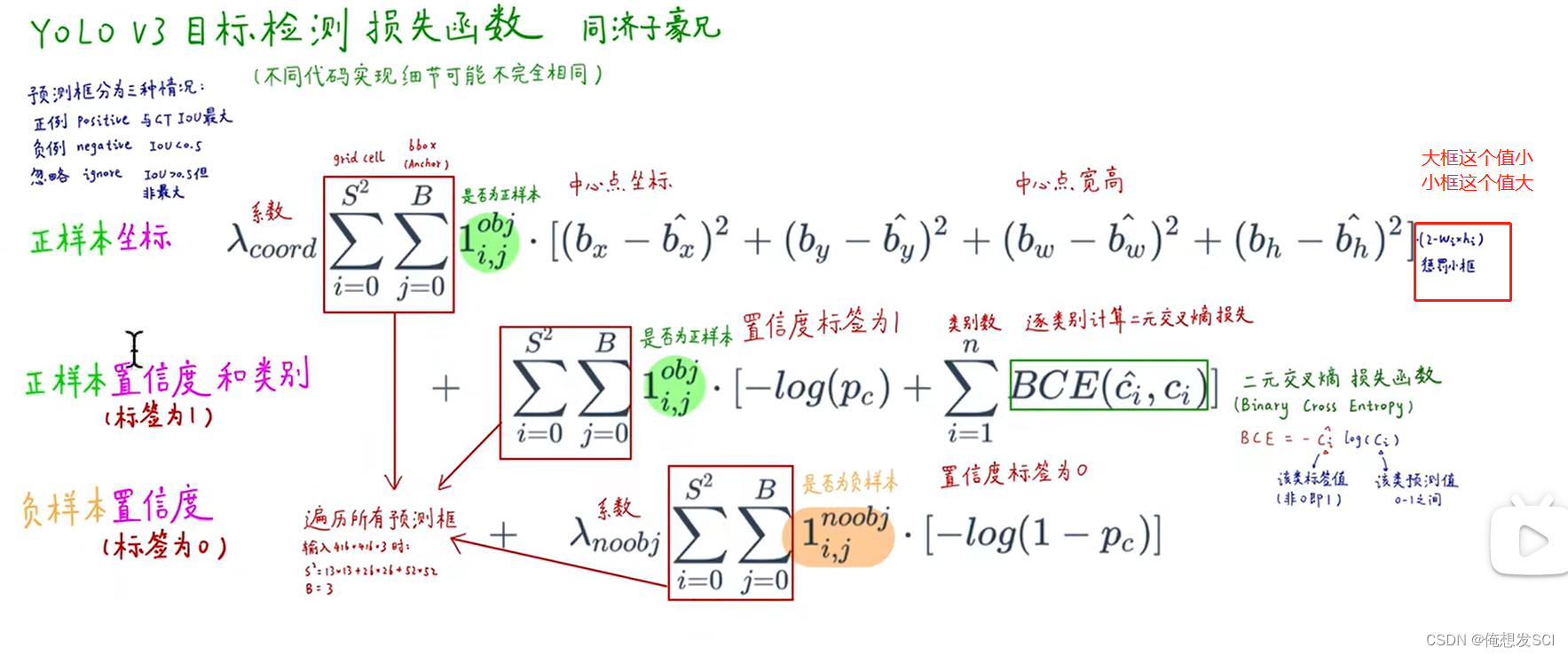
正负样本的选取!!!!!!!!!!!!!!!!!!!!!!!!!!!iou
大于阈值 iou最大 正样本
大于阈值但不是iou最大 忽略
小于阈值就是 负样本 蓝色和绿色!!
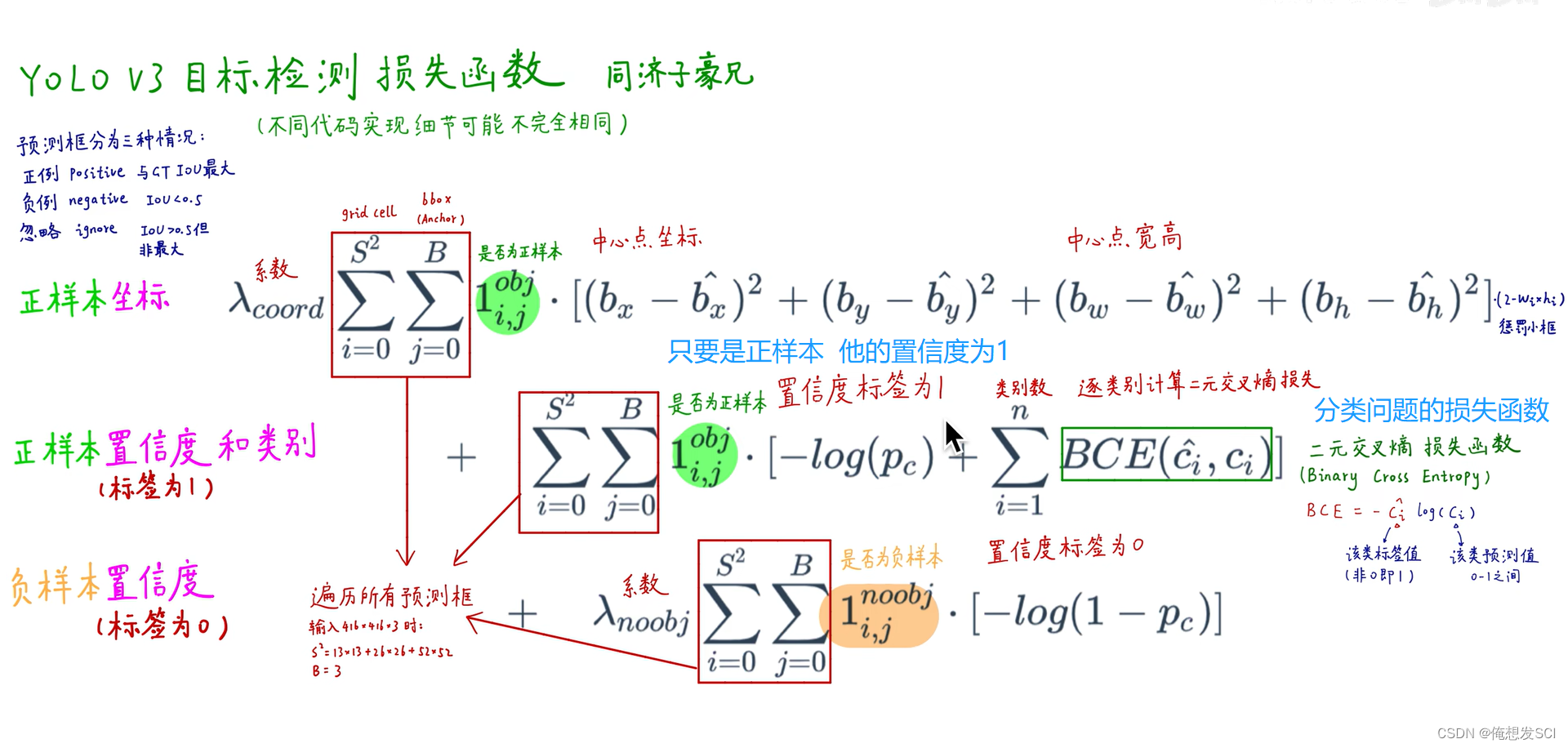
不同代码可能实现的损失函数不一样
训练
测试
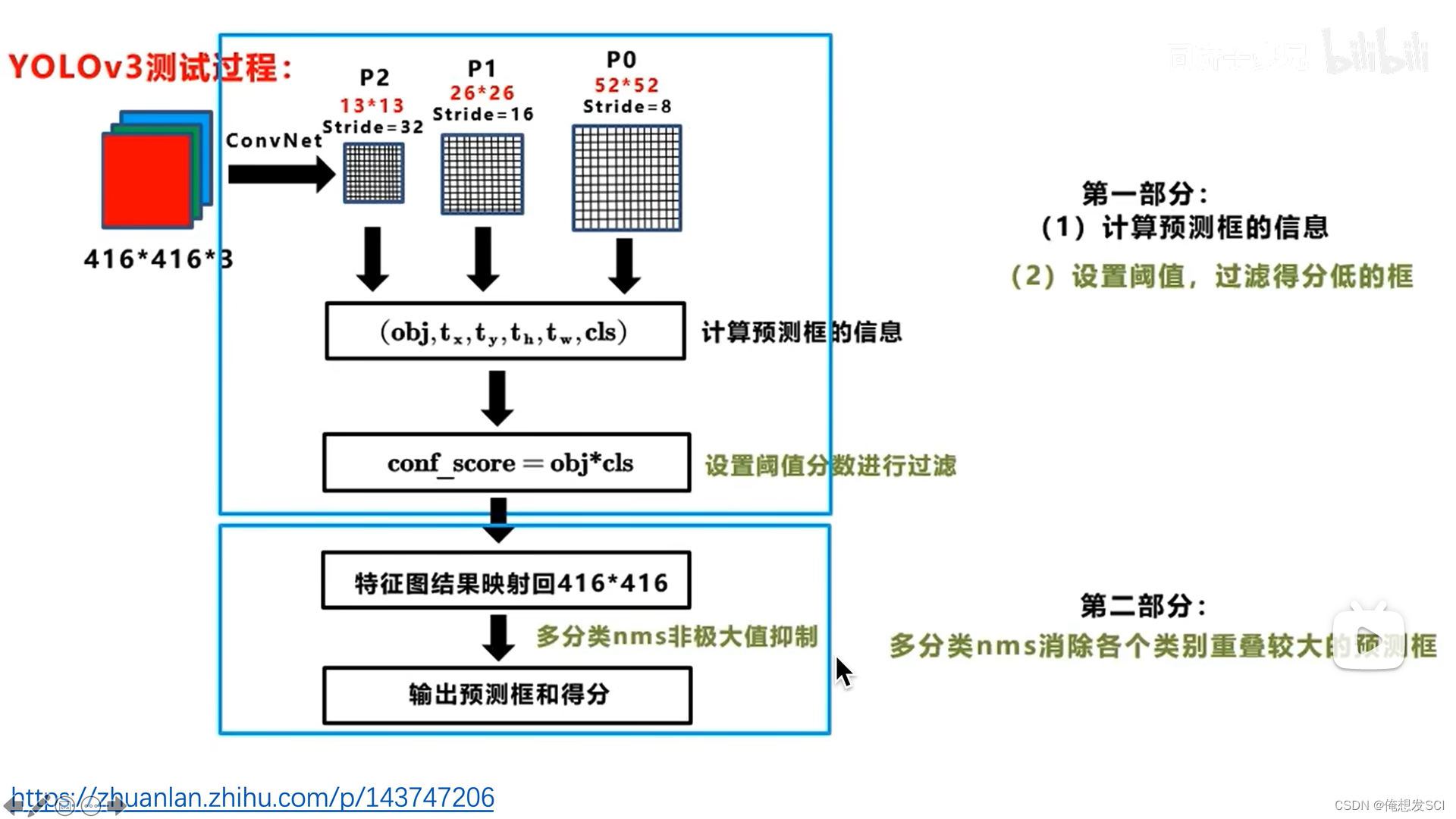
conf-score就是那个 后验概率
代码
评估指标

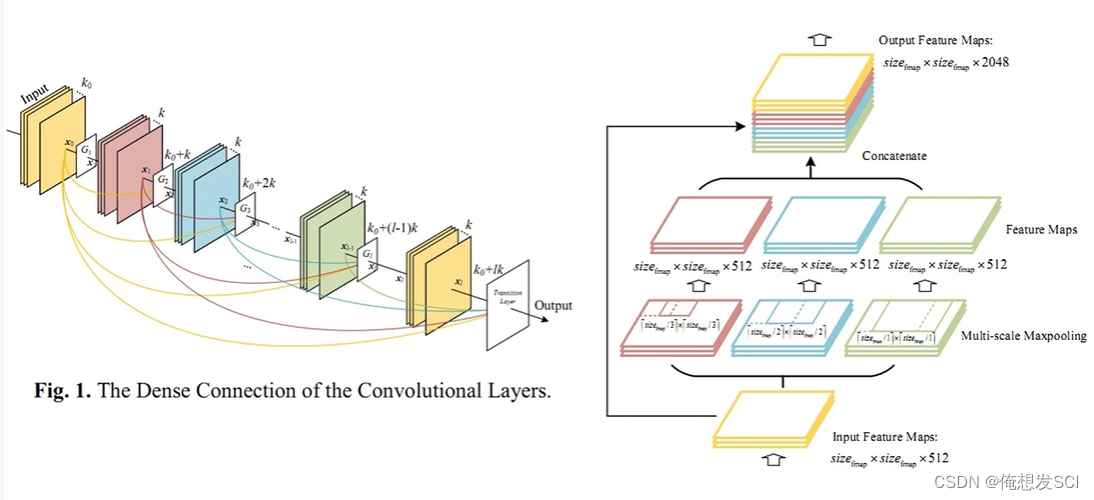
加dense模块 空间金字塔池化 spp
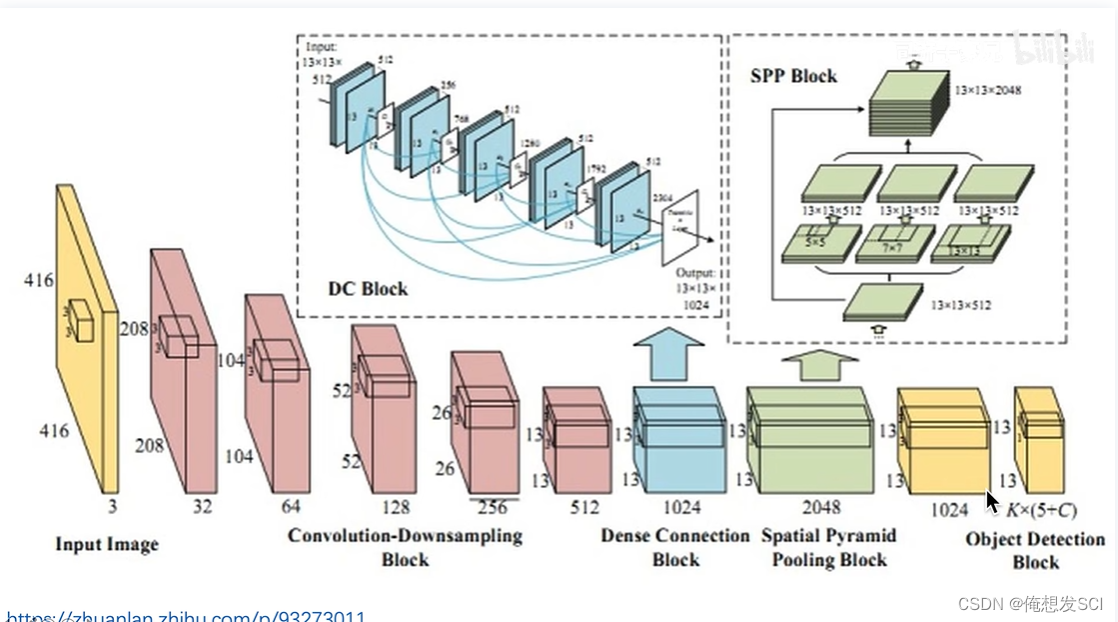

精读视频




256/8=32 32*32对应原图的感受野是8*8
416/8=52 52*52对应原图的感受野也是8*8
416/32=13 感受野是32 感受野大预测大物体
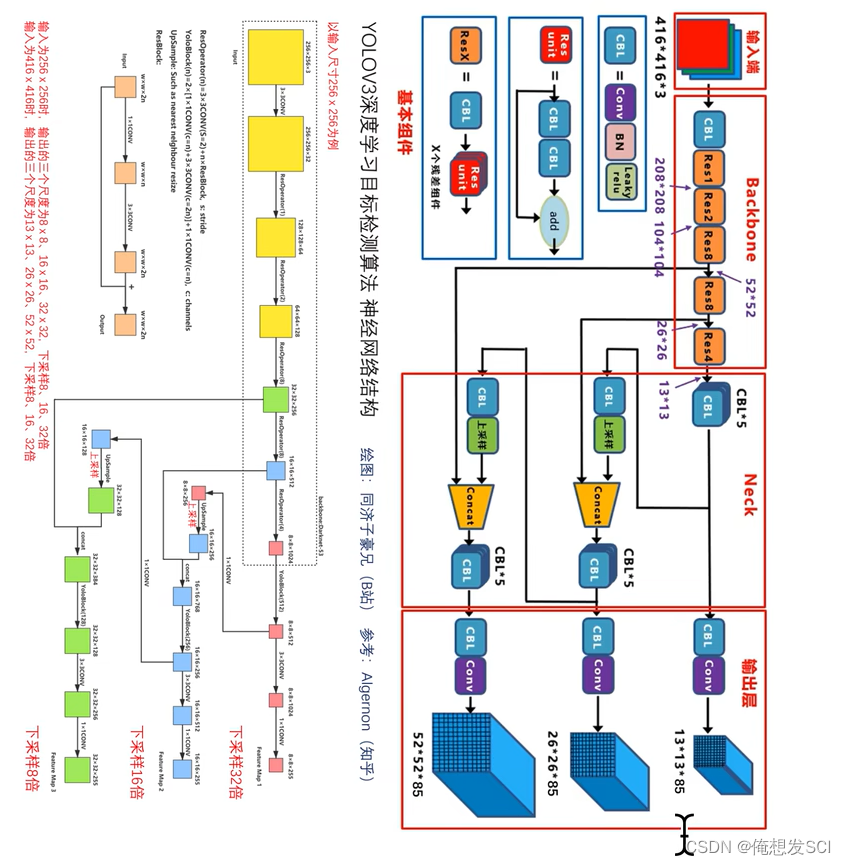


残差 batchnomalzation (BN)都是很常用的配置
用了就可以来引用文献啦


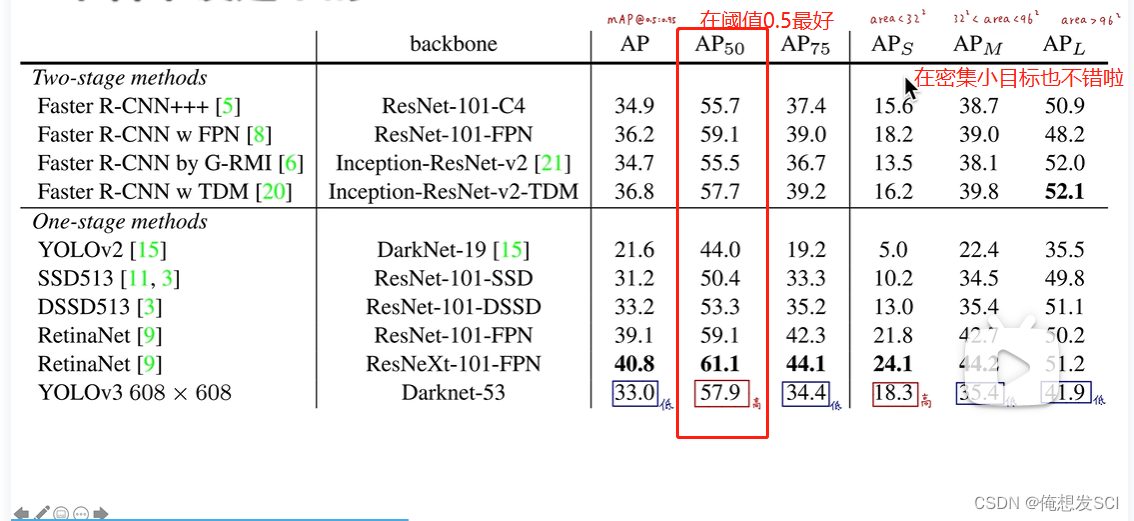
性能指标!!!!!!子豪兄的论文
论文里的IOUthresh=0.5
Pthresh是置信度阈值 假设0.2吧
两个都是人工指定的
根据预测框和gt的iou就能知道他在哪个区间 就是下面那四个可能

FP 本来是背景 但是还给他预测出来了 本来是没有猫 但是预测出一个小猫的框
FN 定位不错 但是置信度预测出来的太小了

TP 除以竖着
TP 除以横着

map0.5求一次平均 0.5:0.95求单独类别的平均 还得再求每个类别的平均

4.
Focal loss 看重暧昧的那个人 也给他高权重 效果nonono

loss
绿绿黄 三个数非零即1
这三项都遍历了所有的预测框

假设猫的预测值Pc gt是猫
第一项 -log(pc): -log猫的预测值 预测值越接近1 loss越小
第二项BCE是猫 标签Cihat是1


没听懂




传送带:大佬们的文章
















 4136
4136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









