







1. Inference in Linear Regression
After fitting a linear regression model we often look at the coefficients to infer relationships between the predictors and the response variable. But we should always ask, "how reliable are our model interpretations?"
Suppose our model for advertising:
Here x are in $1000s and y are in thousand unit sales and every unit sells for $1.
Our interpretation might then be as follows: for every dollar invested in advertising, we get an additional 1.01 back in sales. That is, 1% profit.
1.1 Confidence intervals for the predictors estimates
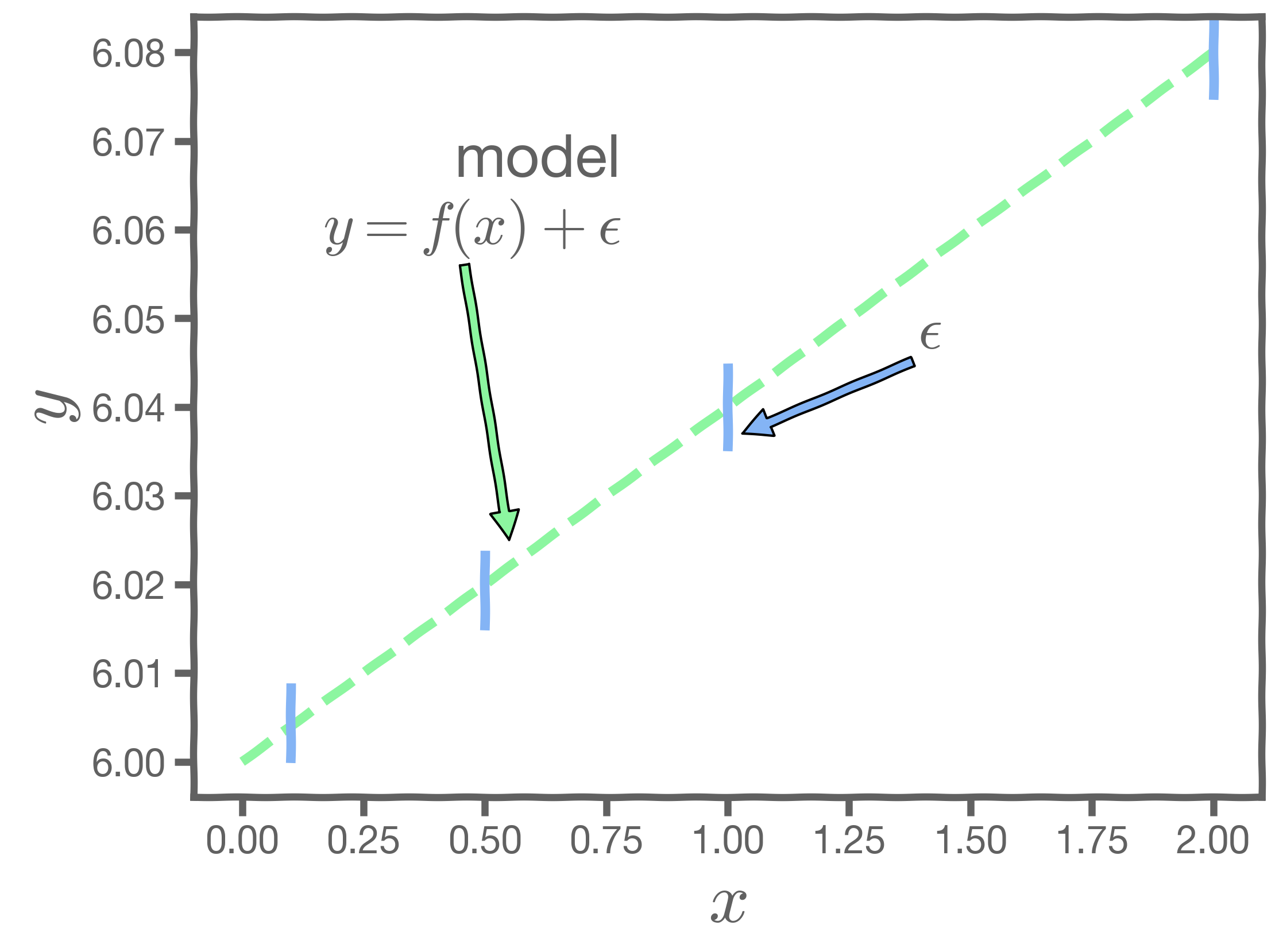
Our observation, represented as , is interpreted either as the noise introduced by random variations in natural systems, or imprecisions of the measuring instruments, or environmental irregularities.
If we knew the exact form of ,for example,
, and there was no noise in the data, then the estimation of would have been exact.
In such a case, is a 1% profit worth it? That's a business decision, and not one that linear regression can answer.
However, two things should make us mistrust of the values of :
- observational error is always there - this is called aleatoric error or irreducible error
- the exact form of
is unknown - this is called misspecification error and is part of the epistemic error
Both errors are combined into a catch-it-all term, . Because of this, every time we measure the response for a fixed value of
, we will obtain a different observation and hence a different estimate of
.
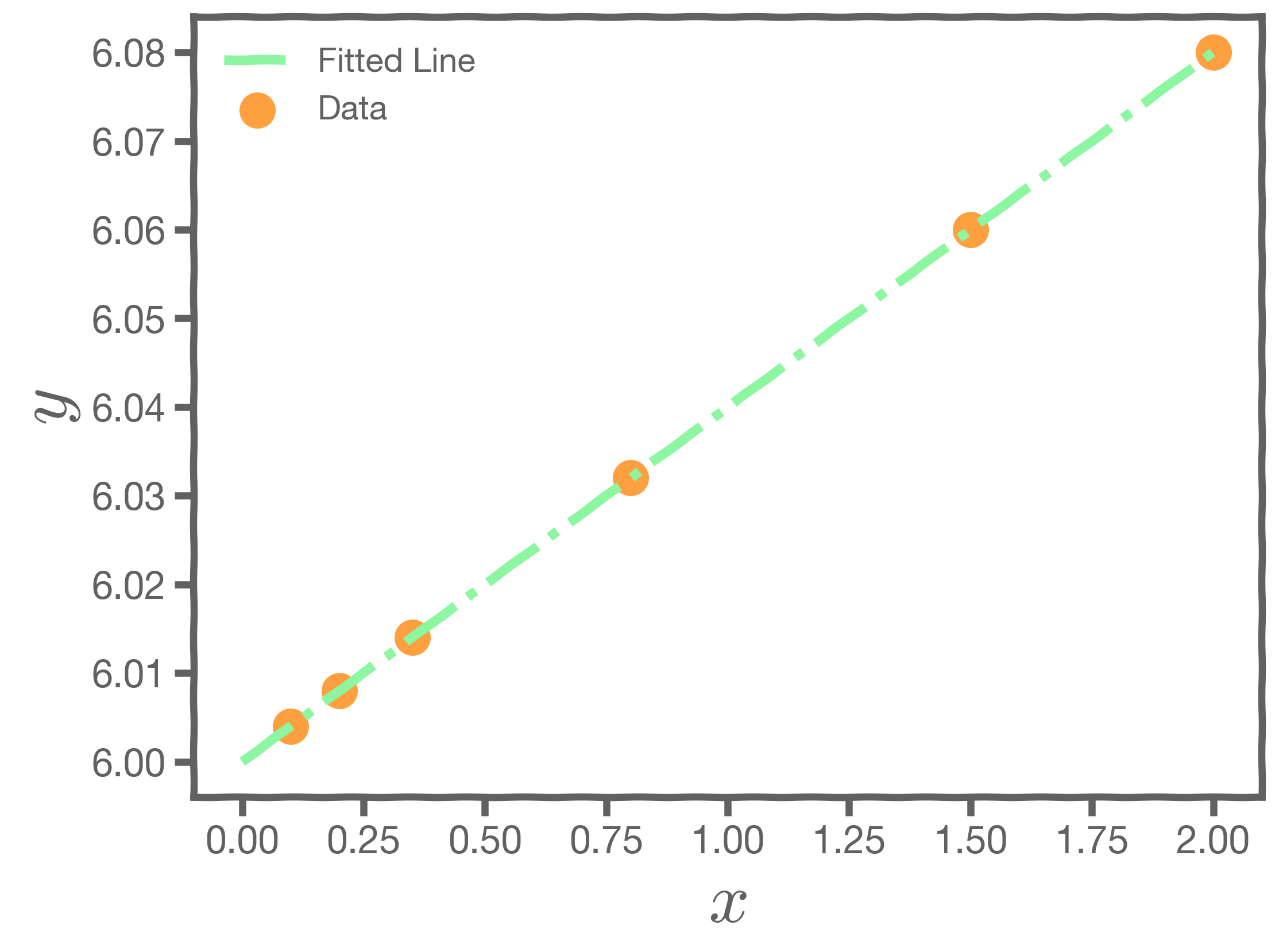
Let us consider an example. Start with a model , the correct relationship between input and outcome.
For some values of ,
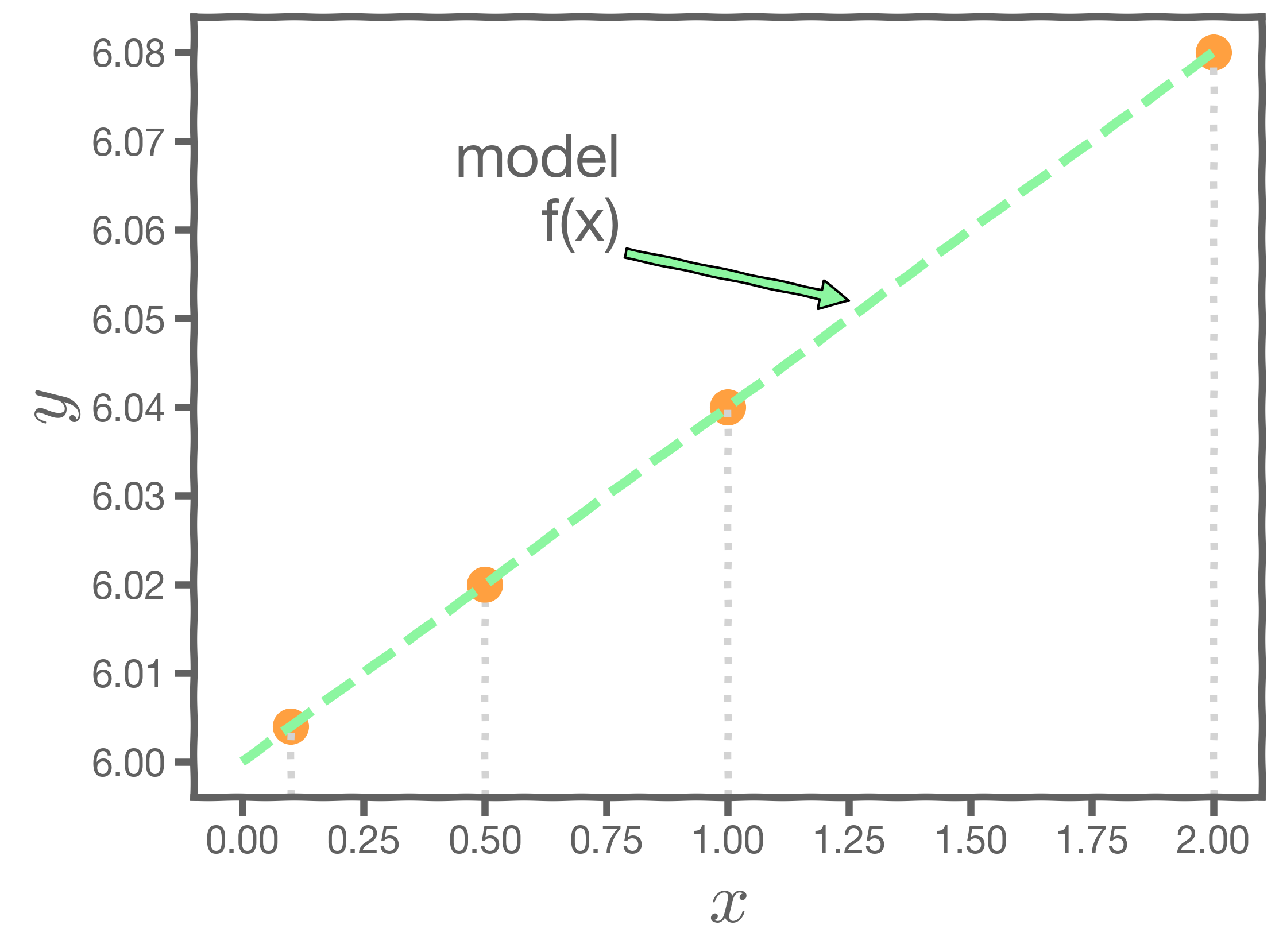
Every time we measure the response for a fixed
we obtain a different observation.
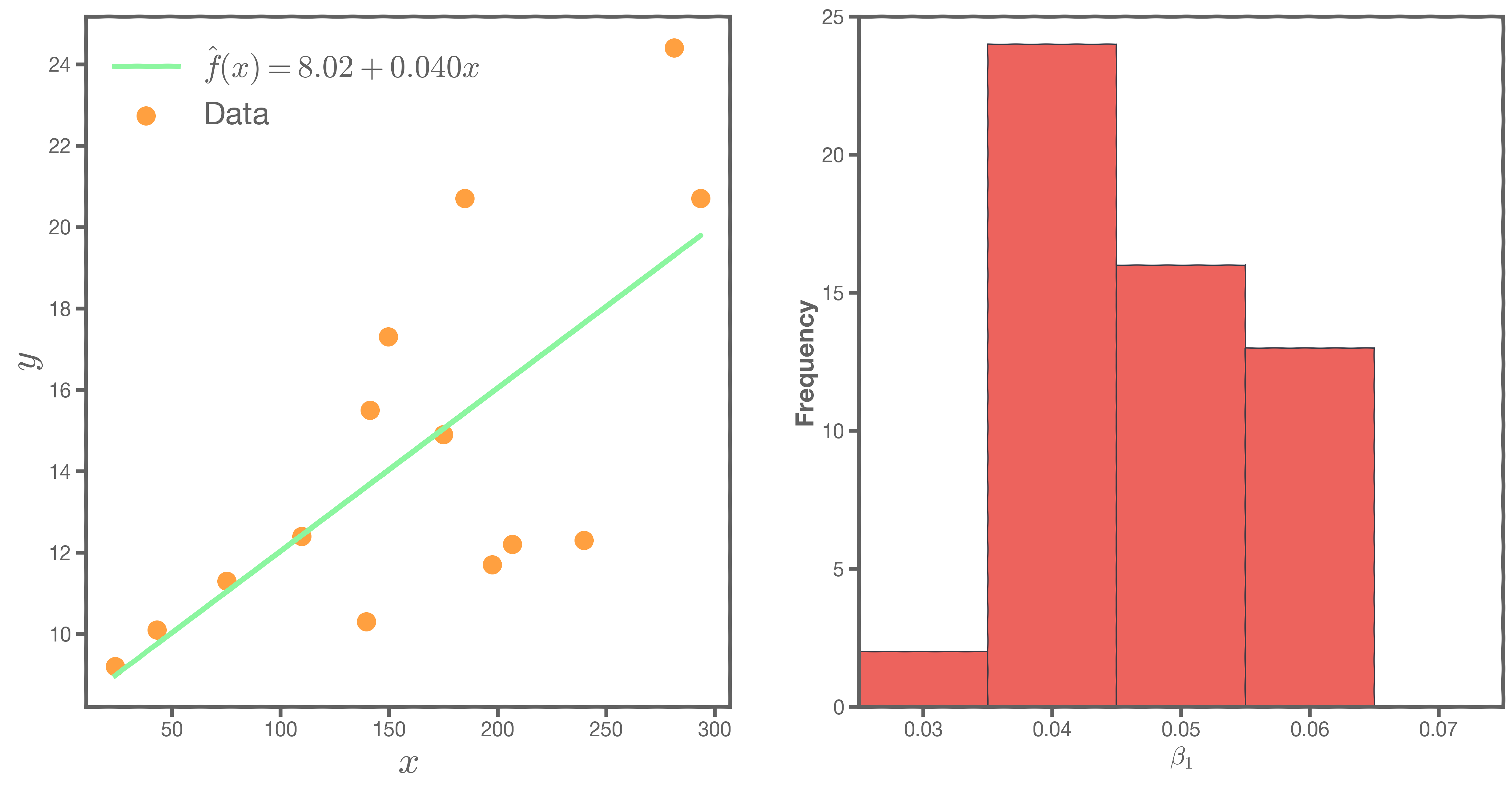
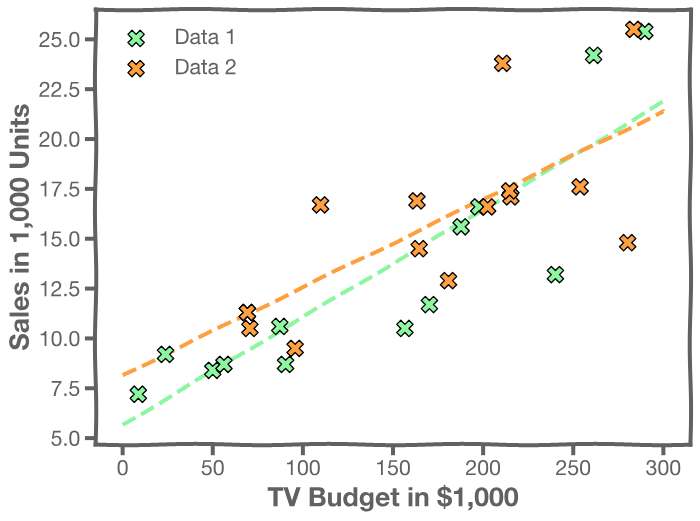
One set of observations, "one realization" yields one set of . This is represented as orange circles in the plot. Similarly, the squares and crosses each represent a set of
realized.

For each of these realizations, we fit a model and estimate and
. Thus, it results in one set of model parameters,
and
, for each realization.
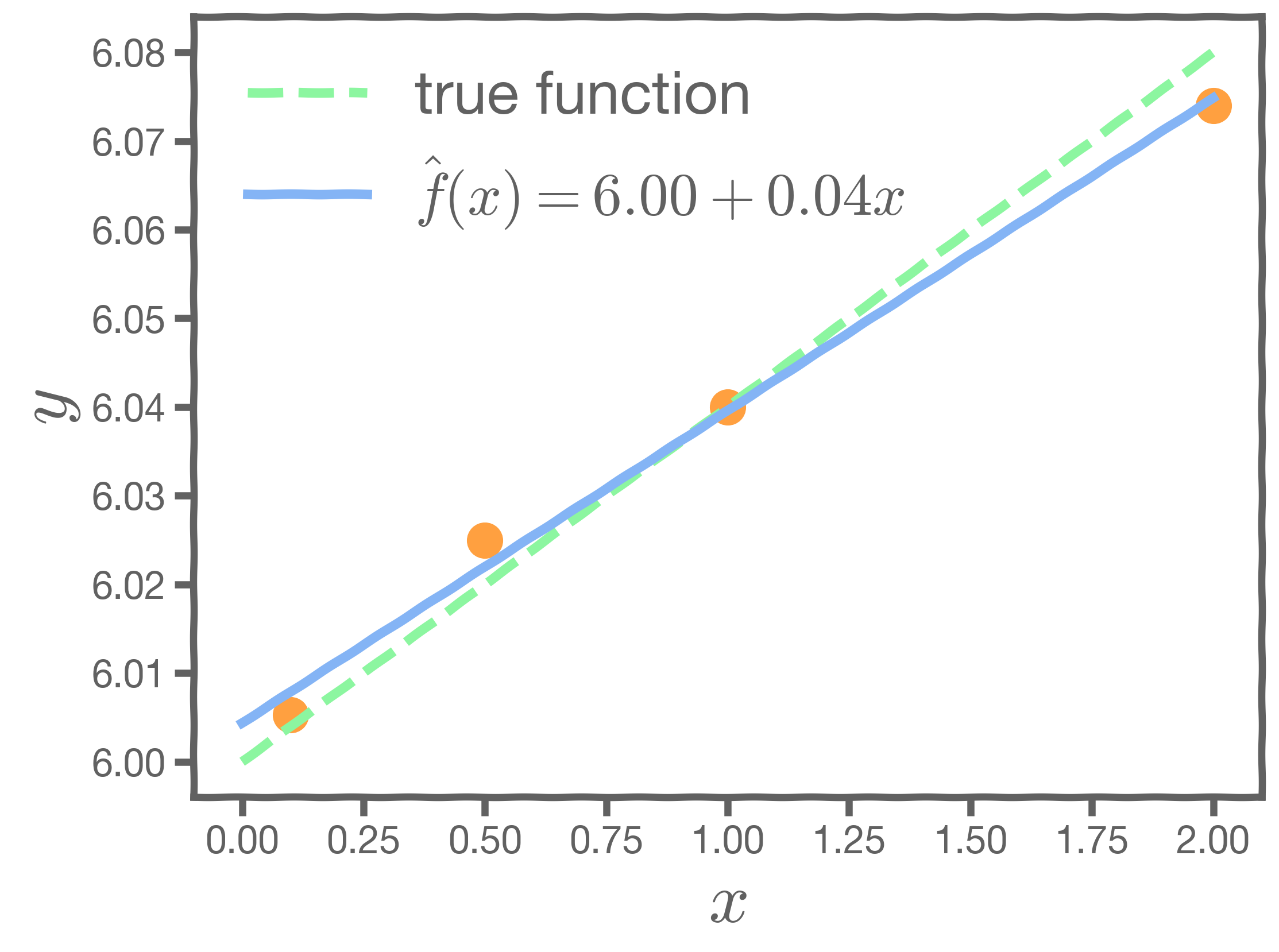
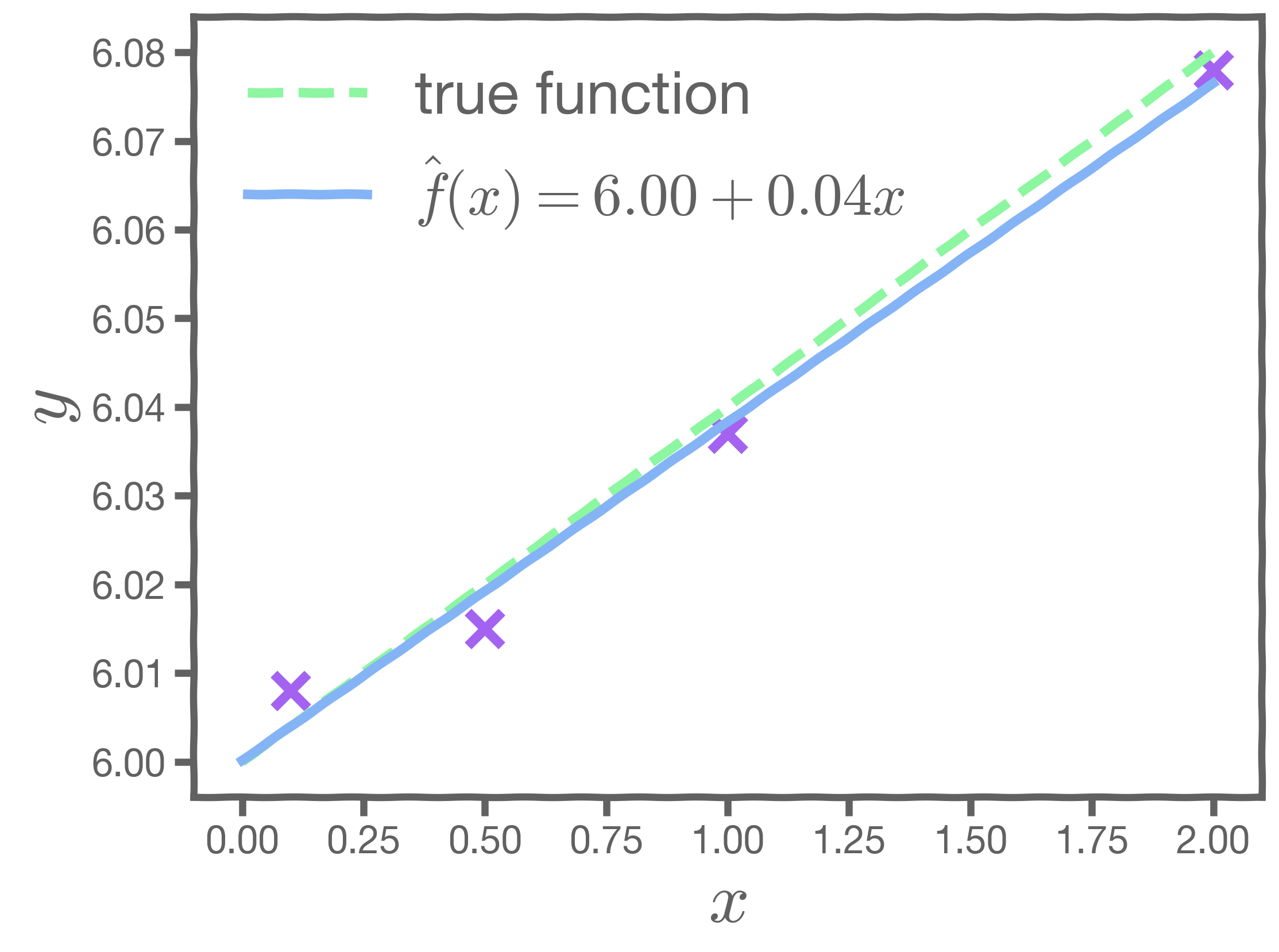
So, if we have one set of measurements of , our estimates of
and
are just for this particular realization. Given this, how do we know the truth? How do we deal with this conundrum?
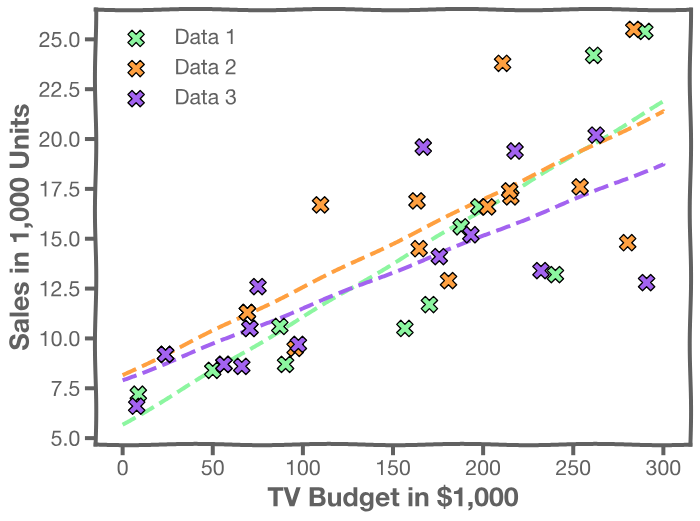
To resolve this, imagine that we have a multitude of parallel universes, and we repeat this experiment on each of the other universes.
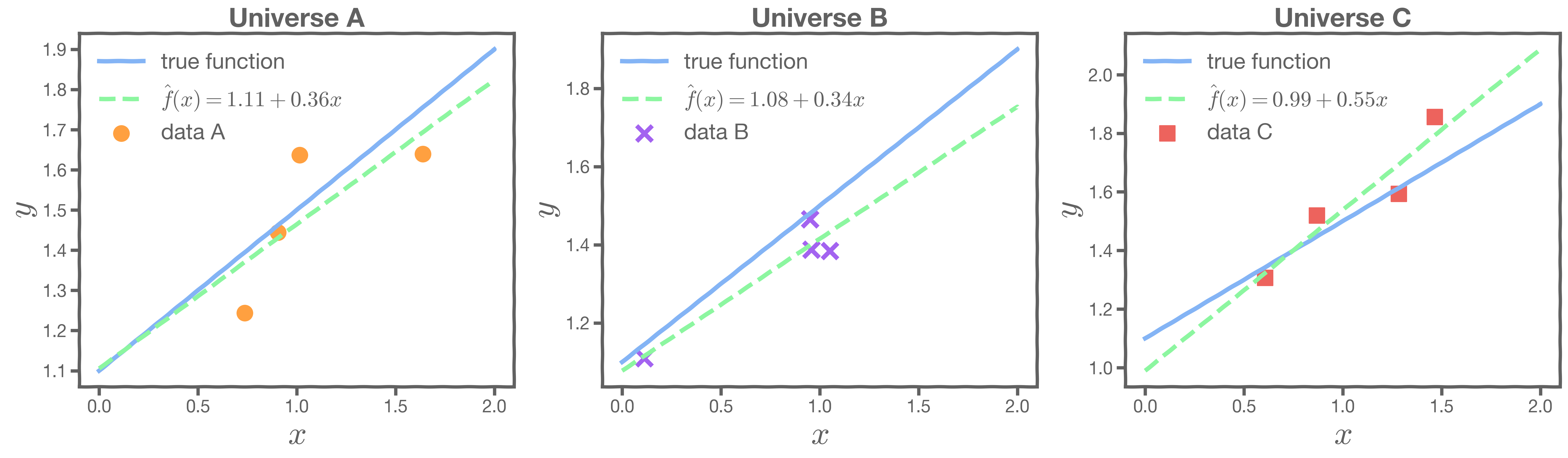
In our magical realism, we can now sample multiple times. One universe means one sample, which means one set of estimates for
and
. The graphs on the left below show the best-fit lines for each of the universes, and the right-hand graph shows the distribution of the estimates of
and
.
Another sample, another estimate of and

This is repeated until we have sufficient samples of and
to understand their distribution.
2. Bootstrap and Confidence Intervals
2.1 Producing Alternative Data Sets
In the absence of active imagination, magic, parallel universes, and the like, we need an alternative way of producing fake data sets that resemble parallel universes.
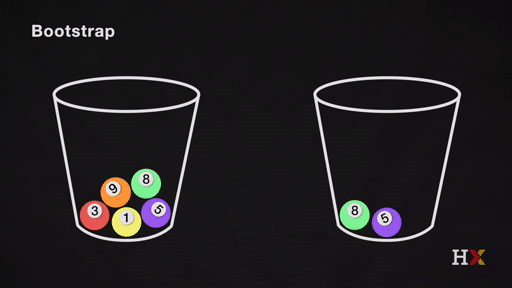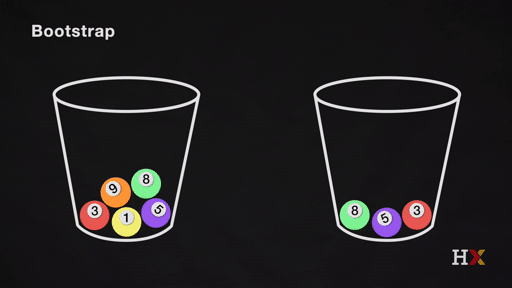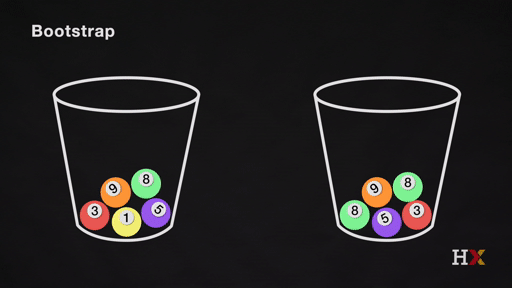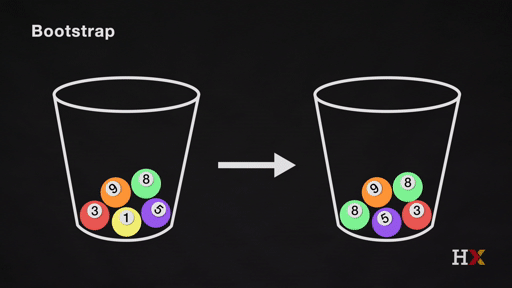
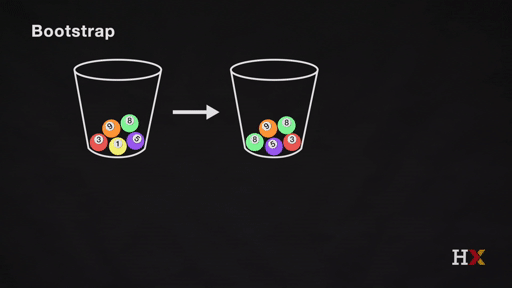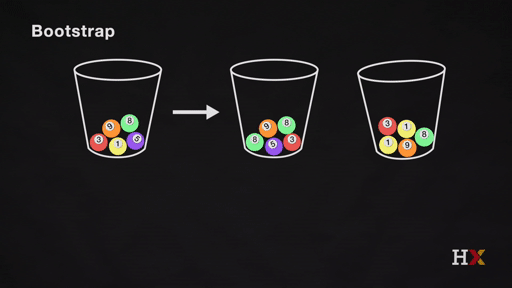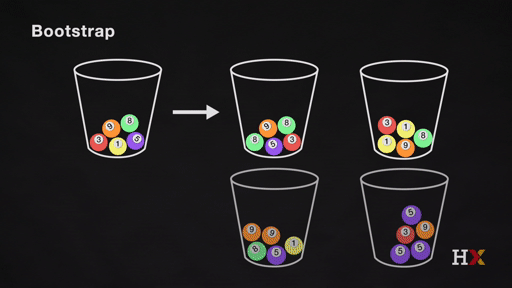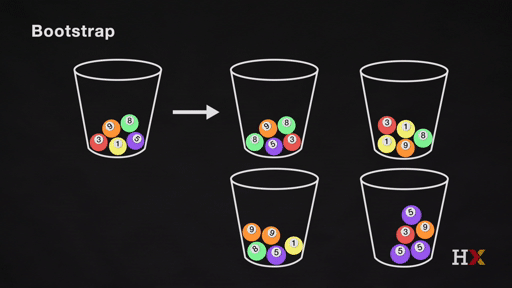
Bootstrapping is the practice of sampling observed data to estimate statistical properties.
Bootstrap Example

We first randomly pick a ball and replicate it. We then move the replicated ball to another bucket.

This is called sampling with replacement.
We then randomly pick another ball and replicate it again. As before, we move the replicated ball to the other bucket.

We repeat this process. We continue until the 'other' bucket has the same number of balls as the original.
We repeat the same process and acquire many sets of bootstrapped observations.
2.2 Bootstrapping for Estimating Sampling Error
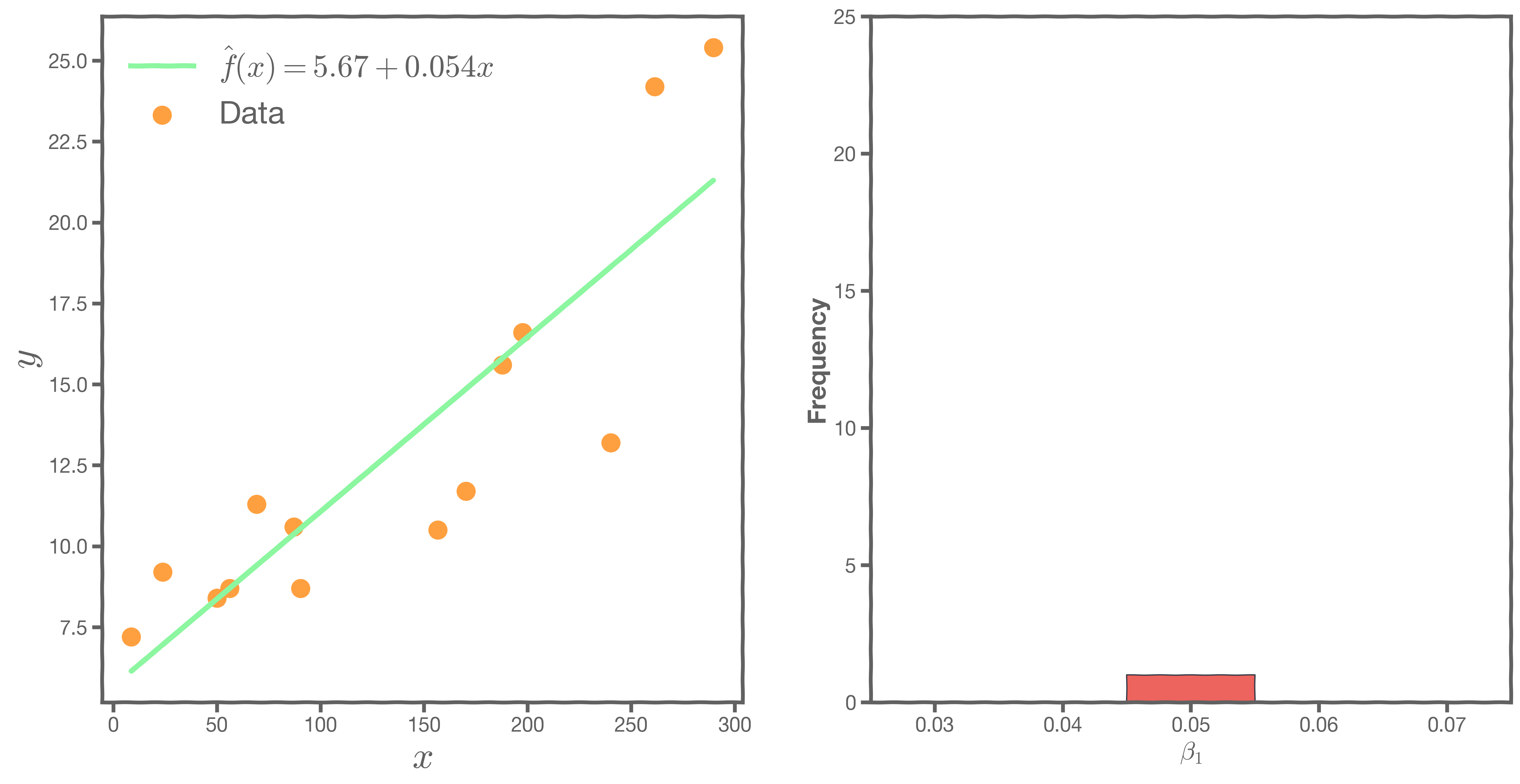
Bootstrapping is the practice of estimating the properties of an estimator by measuring those properties by, for example, sampling from the observed data. For example, we can compute and
multiple times by randomly sampling our data set. We then use the variance of our multiple estimates to approximate the true variance of
and
.
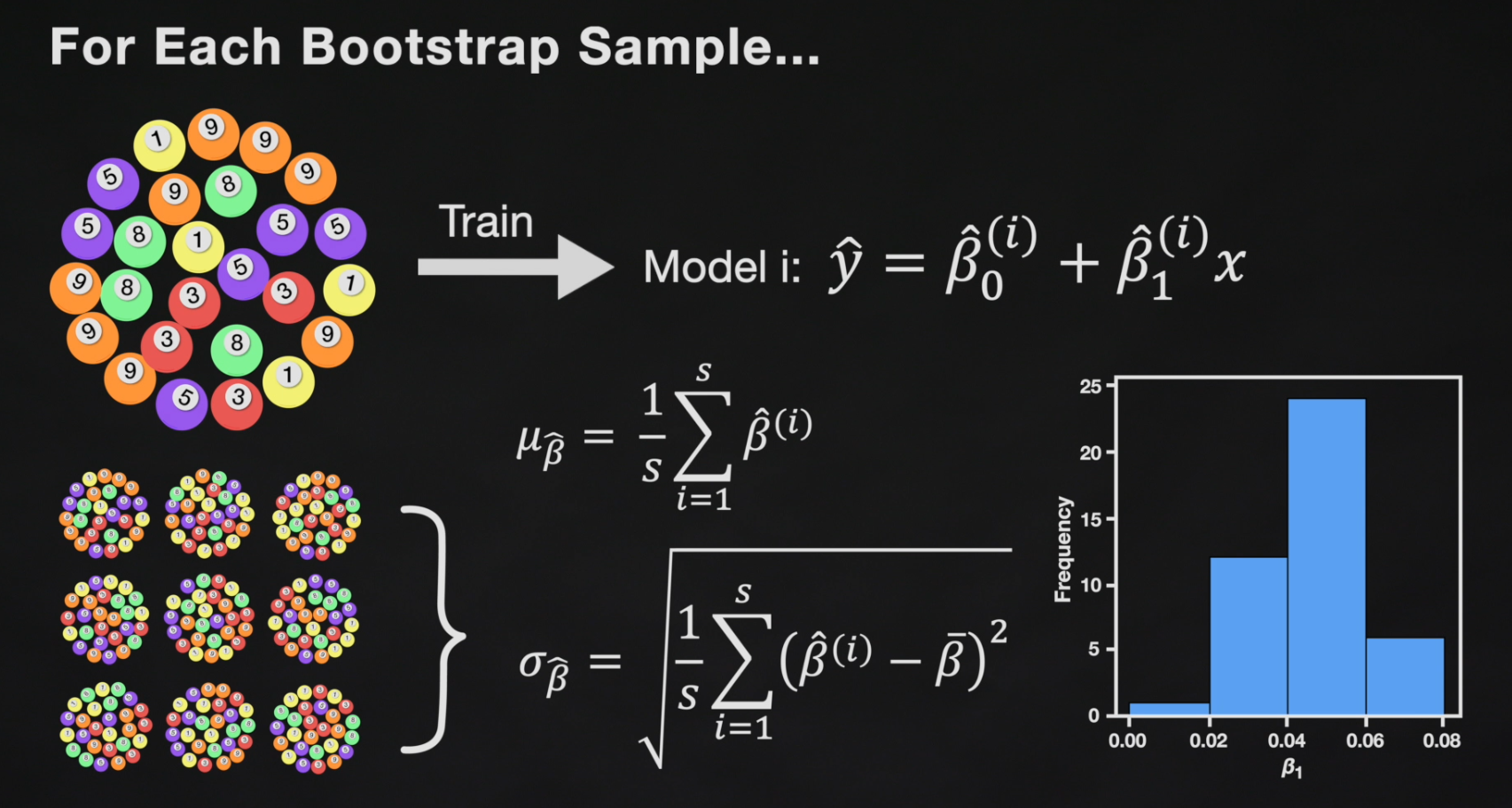
We can now estimate the mean and standard deviation of the estimates and .
The standard errors give us a sense of our uncertainty over our estimates. Typically, we express this uncertainty as a 95% confidence interval, which is the range of values such that the true value of is contained in this interval with 95% percent probability.
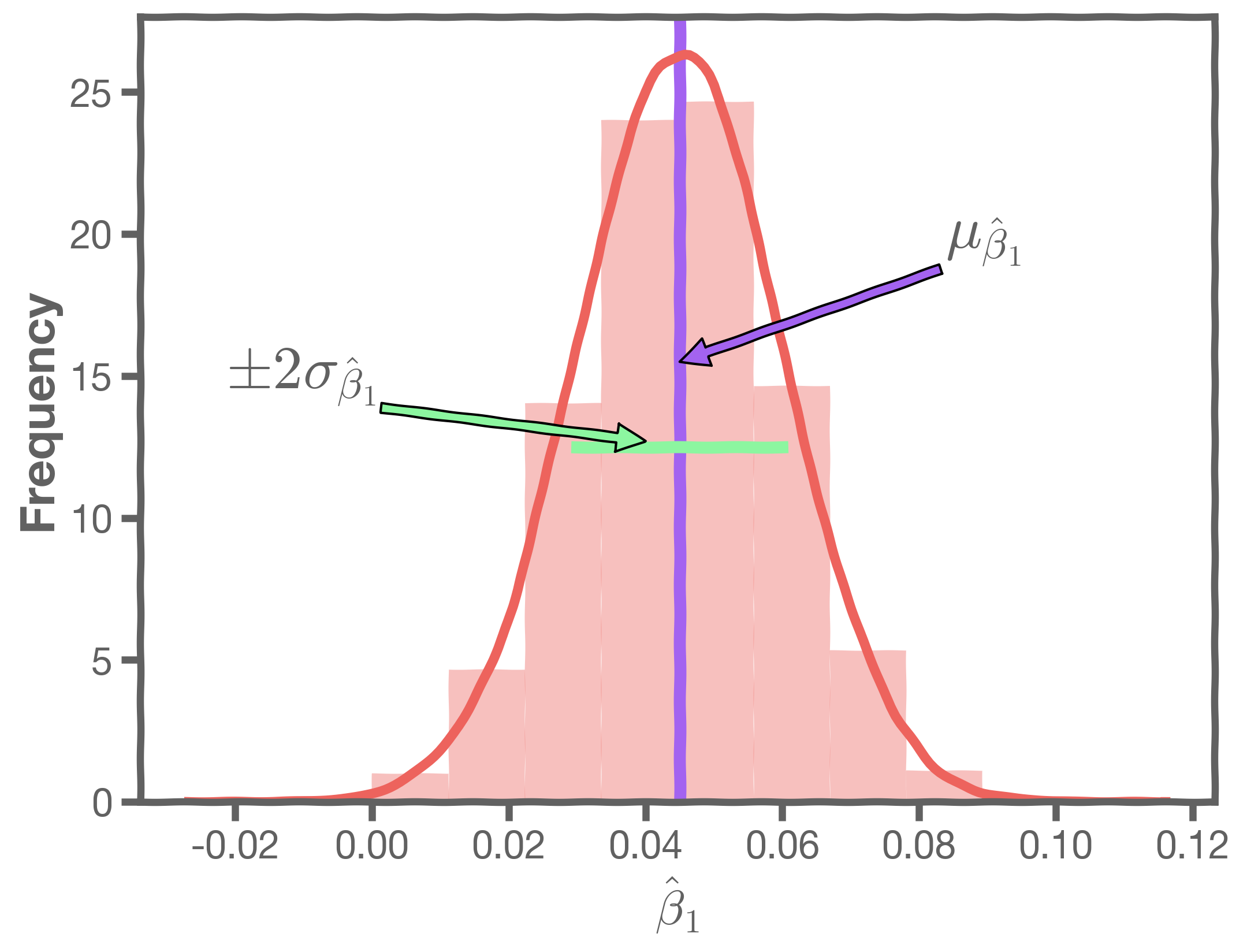
If we assume normality, then:
3. Evaluating Predictor Significance
3.1 Feature importance
Now that we know how to generate these distributions we are ready to answer two important questions:
- Which predictors are most important?
- which of them really affects the outcome?
The three charts below show three different histograms for beta, for newspaper, TV, and radio advertising. Each one has a different mean and standard deviation. How can we tell which of these three predictors is the most important?

To incorporate the uncertainty of the coefficients, we need to determine whether the estimates of 's are sufficiently far from zero.
To do so, we define a new metric, which we call -test statistic:
The
-test
The -test statistic measures the distance from zero in units of standard deviation.
-test is a scaled version of the usual t-test,
where is the number of bootstraps.
3.2 Feature Importance
Consider the following example using the Boston Housing data. This dataset contains information collected by the U.S Census Service concerning housing in the area of Boston. The coefficients below are from a model that predicts prices given house size, age, crime, pupil-teacher ratio, etc.
This plot gives the feature importance based on the absolute value of the coefficients.

The following plot gives the feature importance based not on the absolute value of the coefficients over multiple bootstraps and includes the uncertainty of the coefficients.

Finally, we have the feature importance based on the t-test. Notice that the rank of the importance has changed.
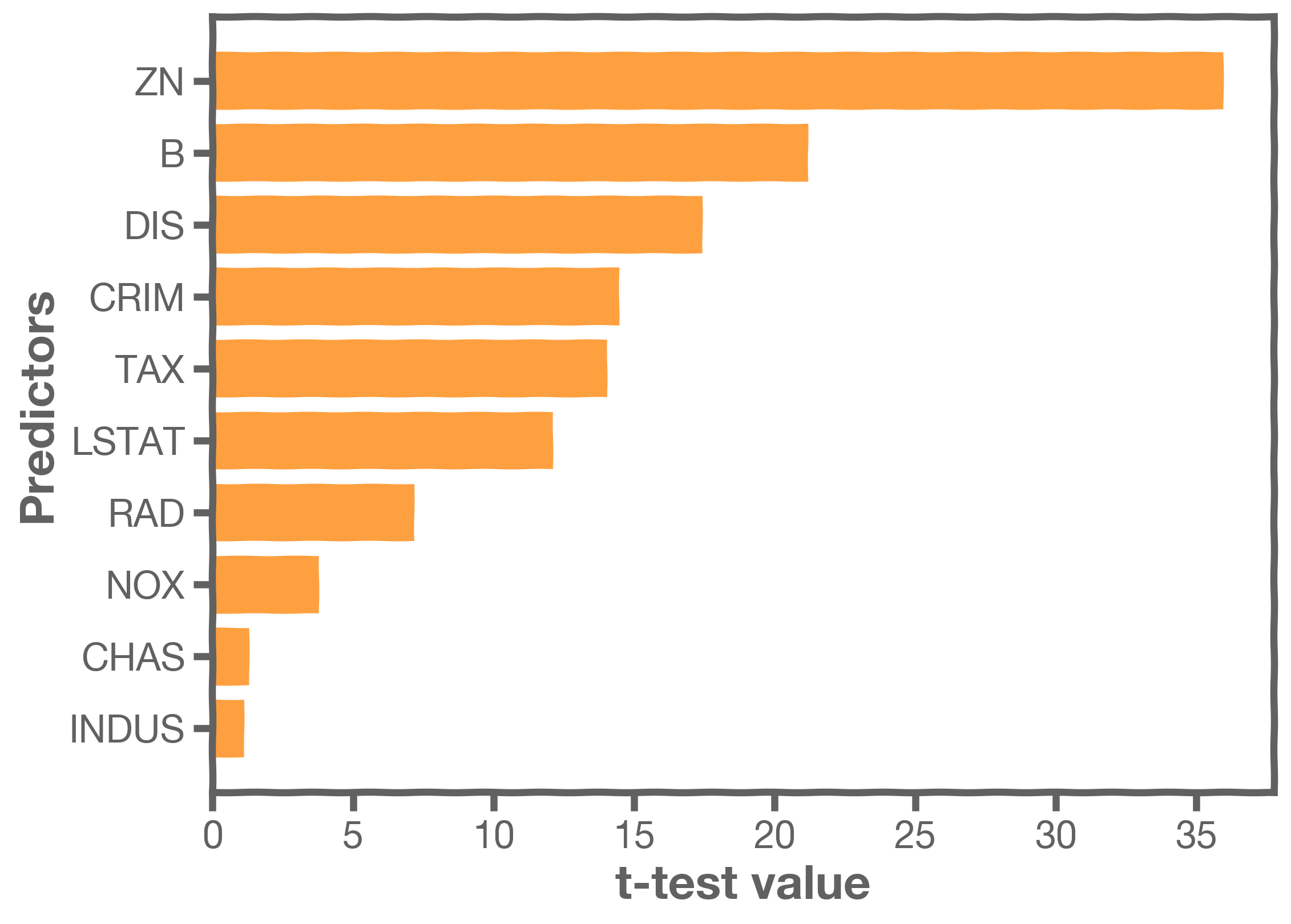
Just because a predictor is ranked as the most important, it does not necessarily mean that the outcome depends on that predictor. How do we assess if there is a true relationship between outcome and predictors?
As with R-squared, we should compare its significance -test to the equivalent measure from a dataset where we know that there is no relationship between predictors and outcome.
We are sure that there will be no such relationship in data that are randomly generated. Therefore, we want to compare the -test of the predictors from our model with -test values calculated using random data using the following steps:
- For random datasets fit models
- Generate distributions for all predictors and calculate the means and standard errors
- Calculate the t-tests
- Repeat and create a Probability Density Function (PDF) for all the t-tests
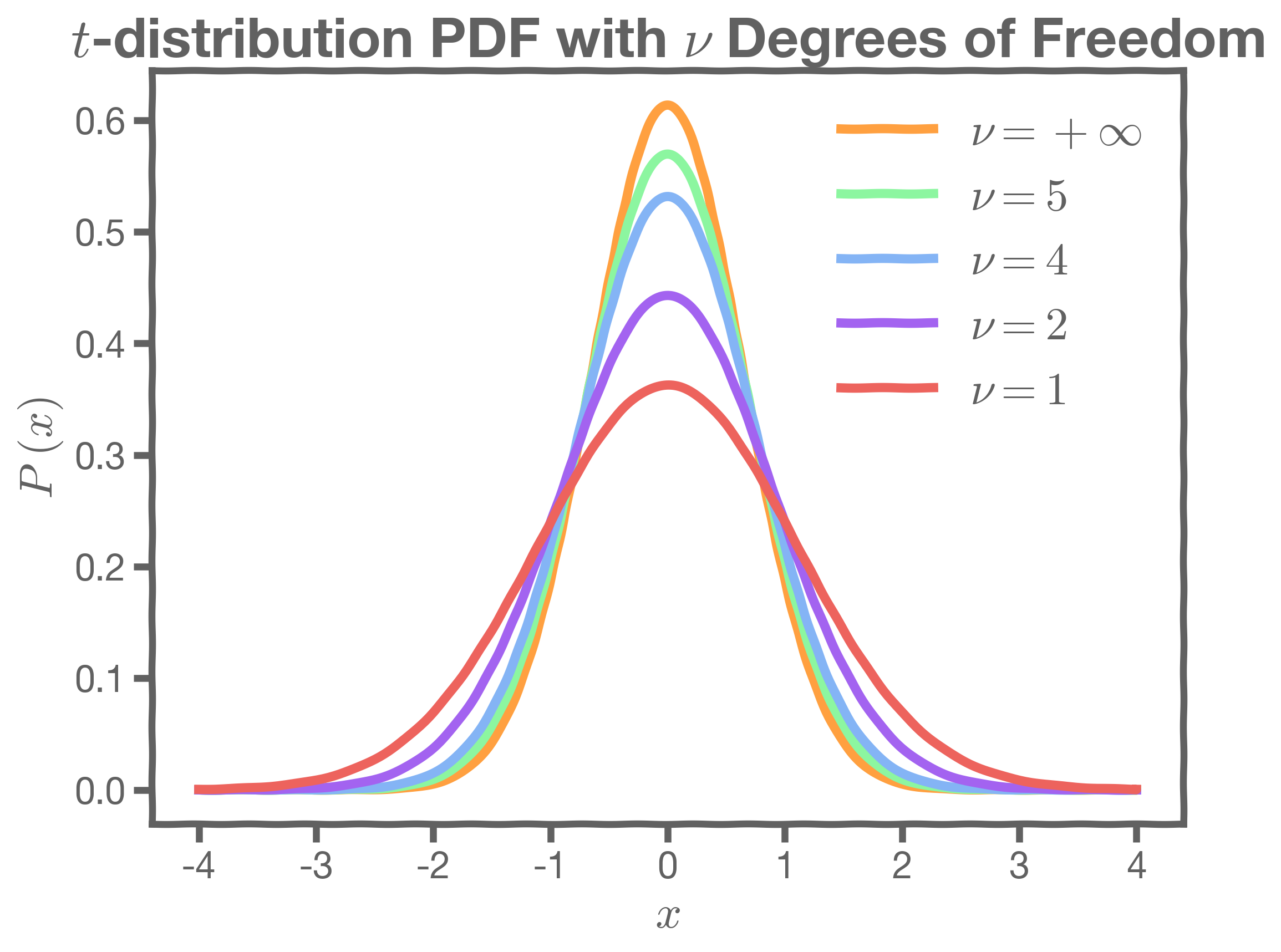
It turns out we do not have to of this, because this is a known distribution called student-t distribution.
In this student-t distribution plot, represents the degrees of freedom (number of data points minus number of predictors):
3.3 P-value
To compare the t-test values of the predictors form our model, , we estimate the probability of observing . This is called the probability of the p-value, defined as:
P-value
A small p-value indicates that it is unlikely to observe such a substantial association between the predictor and the response due to chance.
It is common practice to use p-value < 0.05 as the threshold for significance.
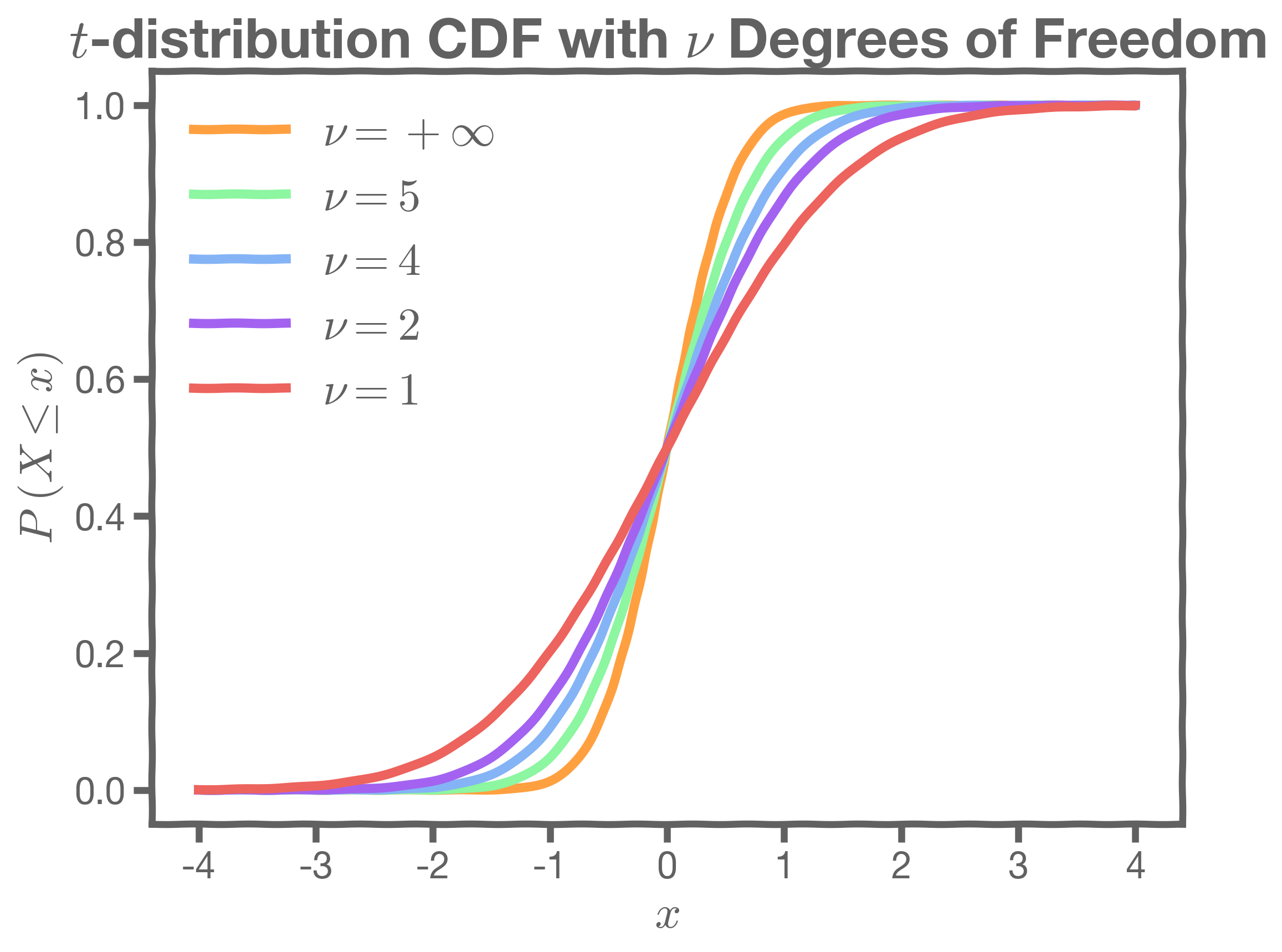
NOTE: To calculate the p-value we use the Cumulative Distribution Function (CDF) of the student-t.
stats model a Python library has a build-in function stats.t.cdf() which can be used to calculate this.
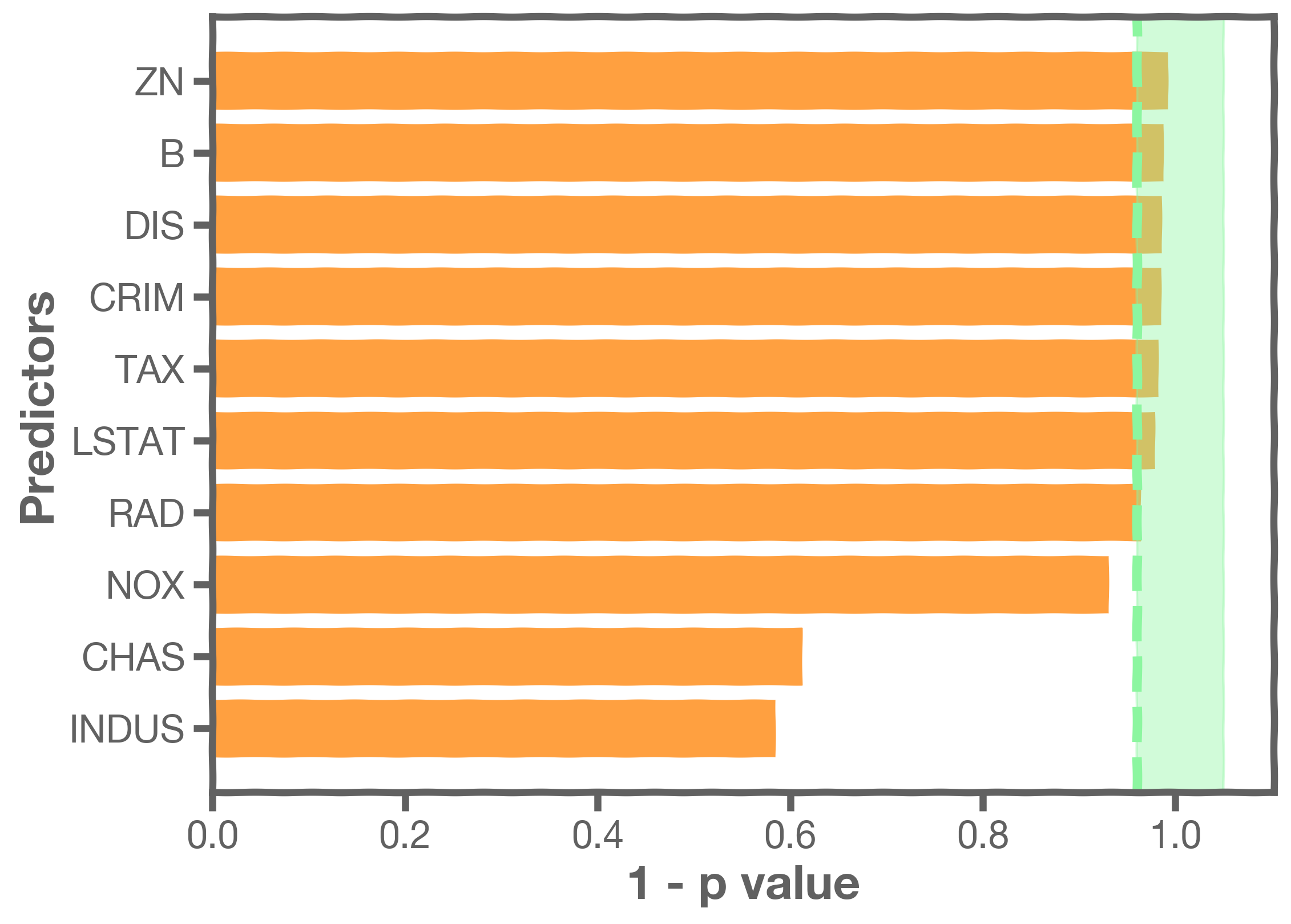
As a continuation of the Boston Housing data example used above, we now have the feature importance plotted using the p-value.
3.4 Hypothesis Testing
Hypothesis testing is a formal process through which we evaluate the validity of a statistical hypothesis by considering evidence for or against the hypothesis gathered by random sampling of the data.
The involves the following steps:
- State the hypothesis, typically a null hypothesis,
and an alternative hypothesis,
, that is the negation of the former.
- Choose a type of analysis, i.e. how to use sample data to evaluate the null hypothesis. Typically this involves choosing a single test statistic.
- Sample data and compute the test statistic.
Use the value of the test statistic to either reject or not reject the null hypothesis.
This is an example of the Hypothesis testing process:
-
- State Hypothesis
- Null hypothesis:
and
- Alternative hypothesis:
- Null hypothesis:
- Choose Test Statistic: the t-test
- Sample: Using bootstrapping we can estimate
s,
,
and the t-test
- Reject or accept the hypothesis
- We compute the p-value, the probability of observing any value equal to or larger from random data.
- If p-value < (p-value - threshold), reject the null hypothesis
- Else, accept the null hypothesis
- We compute the p-value, the probability of observing any value equal to or larger from random data.
- State Hypothesis
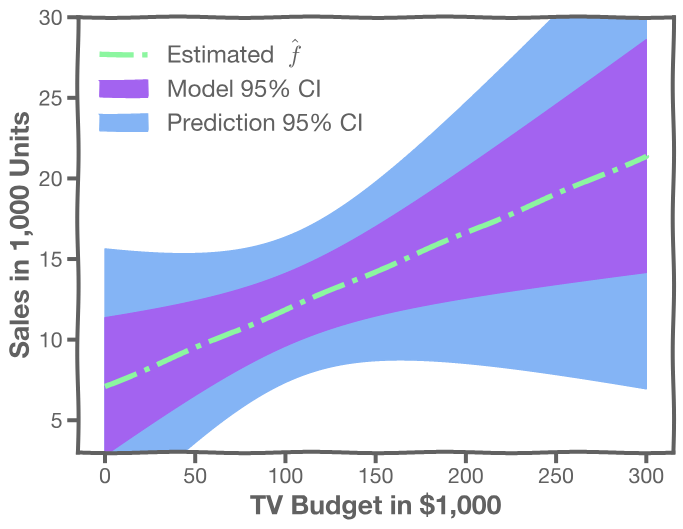
4. Prediction Intervals
4.1 How well do we know 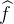 ?
?
Our confidence in is directly related to the confidence in , which we can use to determine the model
Here we show one models' predictions given the fitted coefficients.

Here is another one.
There is one such regression line for every bootstrapped sample.
The following plot shows all regression lines for 1,000 such bootstrapped samples.
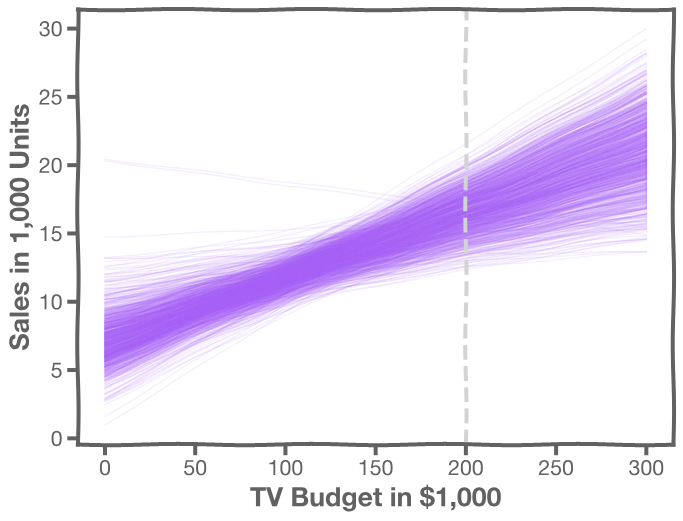
For a given , we examine the distribution of
and determine the mean and standard deviation.
For every , we calculate the mean and standard deviation of the models, (shown with dotted line) and the 95% CI of those models (shaded area)
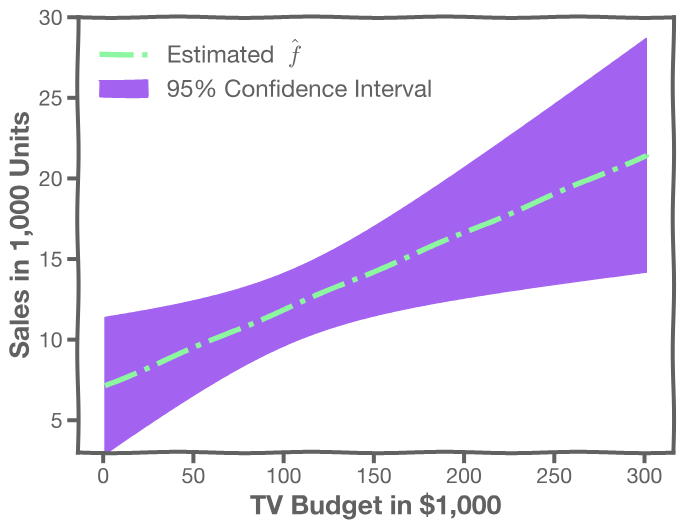
4.2 Confidence in predicting 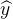
Even if we know - the response value cannot be perfectly predicted because of the random error in the model (irreducible error).
To find out how much will vary from
, we use prediction intervals.
The prediction interval is obtained using the following method:
- For a given , we have a distribution of models
- For each of these
- The prediction confidence intervals are then the 95% region as depicted in the plot















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









