






本篇文章主要注重于对代码前半部分即预测头之前的代码进行解读,预测头部分原理将在之后更新
- 代码理解
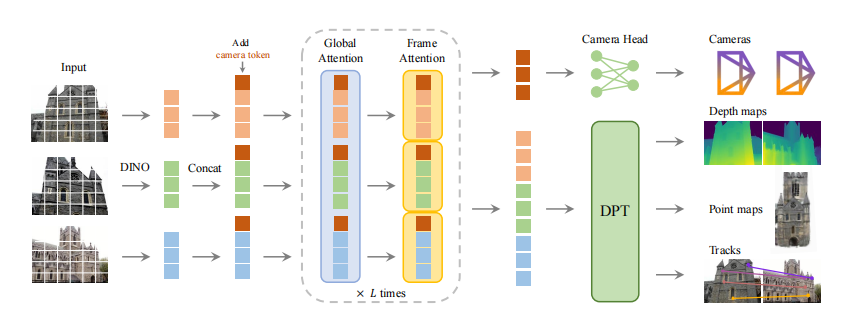
由图1.我们可以看出该VGGT模型实际为一个大模型,它的思路并不是很复杂。下面我解释代码。

这是VGGT代码下models里面vggt代码的前半段,这部分主要为继承heads里面的预测头。
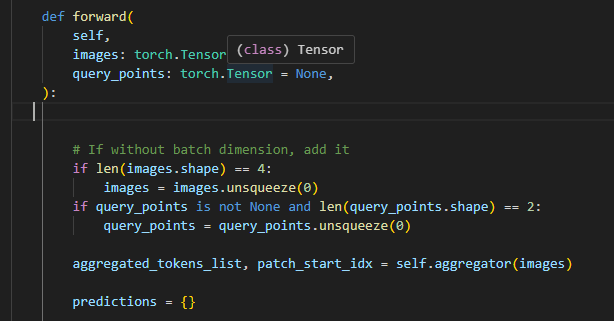
这一部分为vggt的核心,第一个if判断图像的形状,如果 images 是 4 维的,unsqueeze(0) 会在第 0 维(即最前面)增加一个新的维度,使 images 从形状 [batch_size, channels, height, width] 变成 [1, batch_size, channels, height, width]。这种操作通常是为了将数据批量化,使得即使只有一张图片,也可以像处理多张图片一样处理(将其看作批量大小为 1 的情况)。
第二个if为如果 query_points 不为None,且是一个 2 维张量(意味着它包含多个查询点的坐标),则通过 unsqueeze(0) 将其形状变为 [1, num_points, 2],即将其看作只有一个批次的查询点
下一行代码通过调用 self.aggregator(images),将 images 作为输入传递给 aggregator 方法。aggregator 返回两个值:
aggregated_tokens_list:包含多个张量的列表,这些张量为通过注意力机制处理后的图像或特征patch_start_idx:表示patch tokens的开始位置,为一个整数
即对应图一中
接下来,我们将阅读models/aggregator代码来具体了解过程。阅读深度学习这方面代码时,我们应注重于def forward,此为该方法的具体路线。
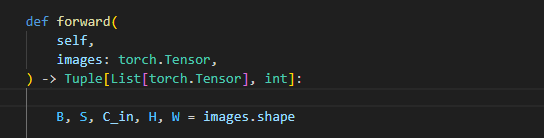
在这一行代码中,传入了图像数据, 形状为 [B, S, 3, H, W],其中:B 表示批量大小(batch size),即每次输入的图像数量、S 表示序列长度(sequence length),如果是视频或图像序列,这个值就是序列中的帧数或图像数、3 是颜色通道数,代表 RGB 三个颜色通道(每张图像有三个颜色通道)、H 是图像的高度(height),即图像在垂直方向的像素数、W 是图像的宽度(width),即图像在水平方向的像素数。
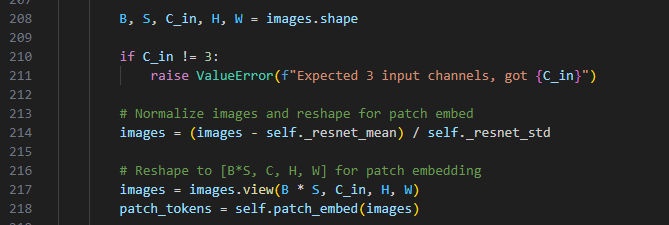
这一部分代码为对图像形状进行简单处理,第一个if很简单就不多说了。
214行代码为对输入图像进行归一化处理。通过减去每个通道的均值并除以标准差,图像的像素值将被调整为与预训练 ResNet 模型兼容的范围。这种归一化可以帮助提高模型的训练效果,使得模型更加稳定和高效。而resnet_mean与renet_end数值aggregator第20行与第21行已经定义了
217行将原始图像的批次和序列长度S 合并为一个新的批次大小,使得输入到后续网络的形状为 [B * S, C_in, H, W],即将多个图像展平为一个“样本”,以便后续处理。
218行代码调用self_patch_embed函数对images进行处理,我们转而了解self_patch_embed函数作用。
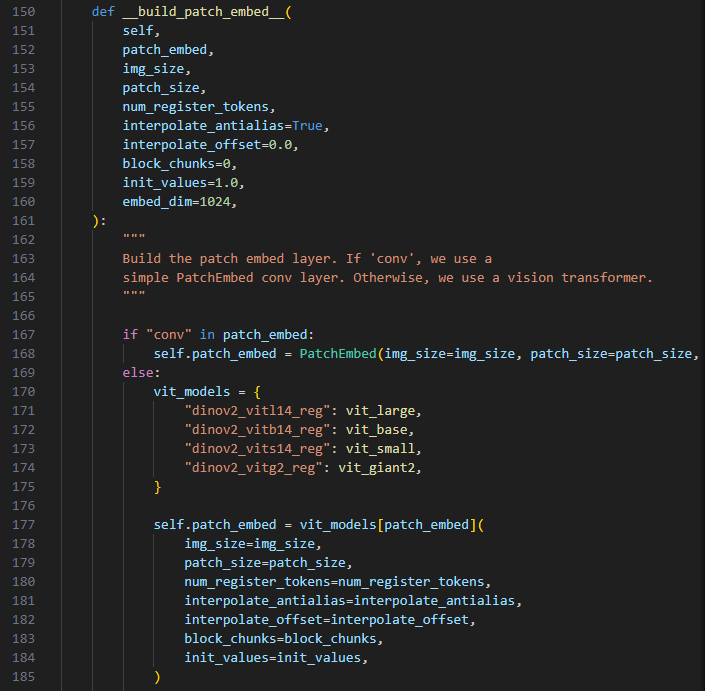
在aggregator第150-185行定义了此函数,可以看出进行一个判断后,进行不同操作,而patch_embed里面是否含有“conv”在aggregator第68行已经给出结果,patch_embed="dinov2_vitl14_reg"。所以我们执行171行的vit_large模型。我们转而继续了解vit_large模型
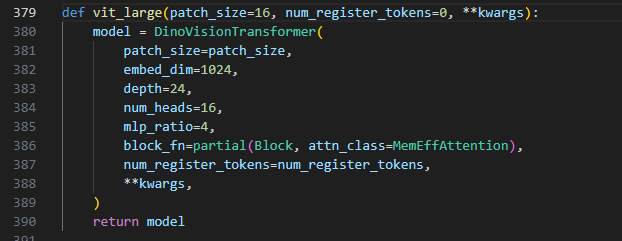
查看上下文可知 vit_large与其他几个vit_的不同为不同的参数,通过查看DinoVisionTransformer我们可以得知
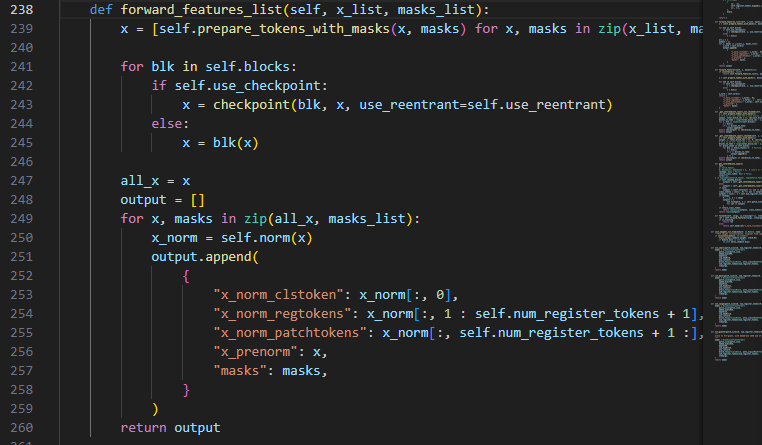
当输入一组输入图像和掩码的前向传播,具体步骤如下:
- 对于每一对图像和掩码,使用
prepare_tokens_with_masks函数进行预处理。 - 然后依次经过网络中的各个块(
self.blocks),每个块是一个Transformer的层,可能会进行检查点操作(checkpoint),以减少内存使用。 - 最终输出每一层的归一化后的特征,并且返回
"x_norm_clstoken":获取归一化后的x的第一个元素(通常是分类 token 或者特殊的标记)。"x_norm_regtokens":获取归一化后的x中的前几个注册 token(可能是特定的标记或输入的部分)。"x_norm_patchtokens":获取归一化后的x中的剩余部分,即 Patch tokens(通常是输入图像的局部信息块)。"x_prenorm":保存原始的、未归一化的数据。"masks":保存对应的掩码。
当输入的是一个图像是,可以参考def forward_features。
现在我们回过头来,看models/aggregator代码

第220-221行代码判断 patch_tokens 是否是一个字典 (dict) 类型。如果是字典,则从字典中获取名为 "x_norm_patchtokens" 的键对应的值,并将这个值赋给 patch_tokens。所以,patch_tokens 将是字典中 "x_norm_patchtokens" 这一项的数据。
223行代码patch_tokens.shape 返回的是一个三维的形状信息,代码从中获取了第二和第三个维度的大小并分别赋值给 P 和 C,忽略了第一个维度的大小。

在这两行代码里面,我们首先观察sself.camera_token与self.register_token。这两个参数也在aggregator里面有定义。而slice_expand_and_flatten函数的作用为处理形状为 (1, 2, X, C) 的专用 token,用于多帧处理:
1) 第一个位置(索引=0)仅用于第一帧。
2) 第二个位置(索引=1)用于其余的所有帧(S-1 帧)。
3) 扩展这两个位置以匹配批次大小 B。
4) 将它们拼接成 (B, S, X, C) 形状,其中每个序列的第一位置 token 是 1 个,后面跟着 (S-1) 个第二位置 token。
5) 将形状展平为 (B*S, X, C) 以进行处理。
所以camera_token最终为(B*S,1,embed_dim),register_token最终为(B*S,num_register_tokens,embed_dim)
![]()
129行中,torch.randn(1, 2, 1, embed_dim):这行代码创建了一个形状为 (1, 2, 1, embed_dim) 的张量,张量的元素是从标准正态分布(均值为 0,方差为 1)中随机生成的。nn.Parameter 是 PyTorch 中的一个特殊类型,用来定义一个模型的可训练参数。通常在神经网络中,通过 nn.Parameter 定义的变量都会被视为模型的参数,并在训练过程中参与梯度更新。
130行同理。embed_dim与num_register_tokens在aggregator前面第49行与第53行已定义过。
![]() 这行代码的目的是将
这行代码的目的是将 camera_token、register_token 和 patch_tokens 这三个张量在列方向上拼接起来,形成一个新的张量 tokens,其形状是沿维度 1 拼接后的结果,应该为(B*S, S+num_register_tokens-1, embed_dim)
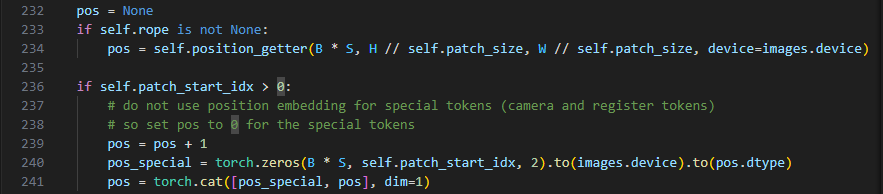
在233行中判断self.rope是否为None,而在aggregator 第70行中已经得知self.rope不为None,使用了Rotary Position Embedding(ROPE)的技术来为输入的 tokens 生成位置嵌入。
第234行则为使用self.position_getter函数来获取位置嵌入。B * S 表示批次大小和序列长度的乘积,表示每个 token 需要的位置嵌入数量。H // self.patch_size 和 W // self.patch_size 是输入图像的高度和宽度,除以 patch 的大小,用来计算位置嵌入的空间维度。device=images.device 将位置嵌入的设备设为图像所在的设备。
第236行中判断self.patch_start_idx>0,由self.patch_start_idx定义知,符合条件。将 pos 中的所有位置嵌入值加 1。这一步的目的是确保位置嵌入的偏移量,以防止特殊 token 使用位置嵌入时的冲突。创建一个形状为 (B * S, self.patch_start_idx, 2) 的全零张量,用来表示特殊 tokens(比如 camera 和 register tokens)的位置嵌入torch.zeros(...).to(images.device).to(pos.dtype) 将这个张量放到与 images 相同的设备上,并确保它与 pos 张量的数据类型一致。使用 torch.cat 函数在 dim=1 上将 pos_special(表示特殊 token 的位置嵌入)和 pos(表示普通 token 的位置嵌入)拼接起来。这样,拼接后的 pos 将包含所有 token 的位置嵌入,其中特殊 tokens 的位置嵌入为零。所以最终pos的shape为(B*S, patch_start_id+H/patch_size+W/patch_size, 2)
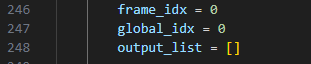
这一部分frame_idx 可能局部注意力机制的索引,global_idx 可能用于全局注意力机制的索引,output_list 用于存储结果或处理后的数据。
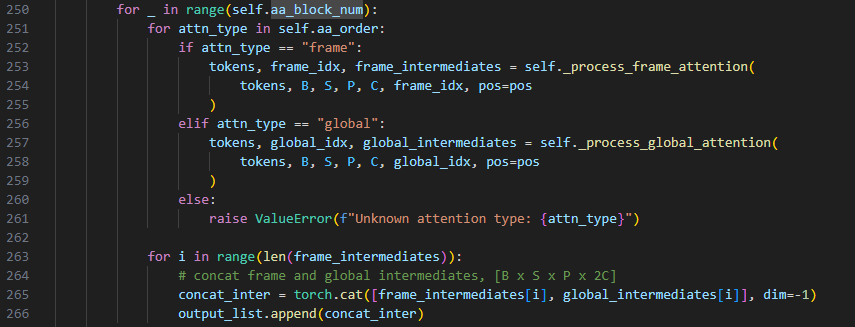
这部分代码由内外两个循环构成,外部循环第250行self.aa_block_num 表示循环的次数,假设它是一个整数,这个循环会执行 aa_block_num 次。而self.aa_block_num 在第125行有定义,读者可自行计算。
内部循环第251行的循环表示attn_type 依次取 self.aa_order 中的元素,通常这表示不同的注意力类型 "frame" 和 "global",并使用_process_frame_attention方法来进行注意力计算。现在我们关注一下_process_frame_attention
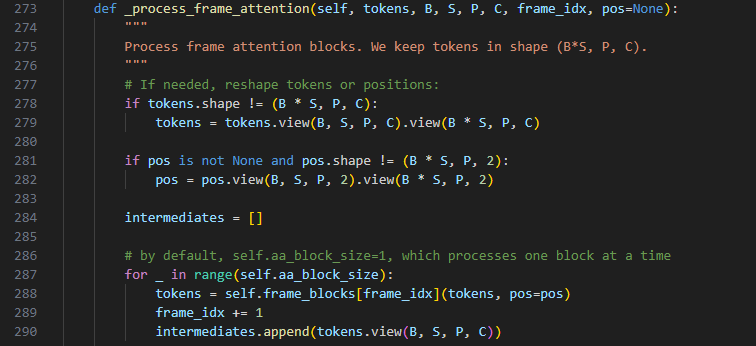
第278行代码判断 tokens形状是否为(B * S, P, C),若不是则调整为(B * S, P, C),在第244行中定义了P与C为tokens的后两个维度,所以P=S+num_register_tokens-1 C=embed_dim
第281行代码判断是否pos不是空的,并且形状为(B * S, P, 2),则调整形状为(B * S, P, 2)
第284行代码intermediates 是一个空列表,用来存储每个处理步骤的中间结果。在框架注意力中,这些中间结果通常是 tokens 在经过每个处理步骤后的状态。
第287行代码self.aa_block_size 是一个配置参数,表示在处理框架时需要处理的块的数量,在第60行中定义为1,即每次只处理一块。self.frame_blocks[frame_idx](tokens, pos=pos) 使用 frame_idx 索引从 frame_blocks 中取出一个处理块,并将 tokens 和 pos(如果存在)传递给它进行处理。frame_idx += 1 在每次处理后,递增 frame_idx,表示下一个框架块的索引。intermediates.append(tokens.view(B, S, P, C)) 将当前的 tokens 调整为 (B, S, P, C) 的形状,并将其添加到 intermediates 列表中,以便后续使用或返回。
现在我们回过头来看第264行代码。对 frame_intermediates 和 global_intermediates 中的每一对张量,沿着最后一个维度(特征维度)进行拼接,并将结果保存到 output_list 中。最终,output_list 将包含多个拼接后的张量,每个张量的形状为 [B, S, P, 2C],其中 2C 是原来 C 的两倍。

第269-271行代码目的就是在不再需要这些变量的时候,将它们删除,以便腾出内存空间,尤其是在处理大量数据时,合理释放内存是很重要的。
最后返回output_list与 self.patch_start_idx
如有错误,请及时告知于我,谢谢。

















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









