






一.机器学习概述
参考视频:(强推|双字)2022吴恩达机器学习Deeplearning.ai课程_哔哩哔哩_bilibili p1-p41
1.1监督学习
向程序里面输入X,然后给出输出Y。
比如输入一个邮件,由人来给出这个邮件是否是垃圾邮件。邮件分类器学习了很多次之后,再次输入,就可以自动给出是否是垃圾邮件。
回归问题:简单来说就是根据一些离散的点进行拟合
分类算法:将一些数据划分成两类或多类。
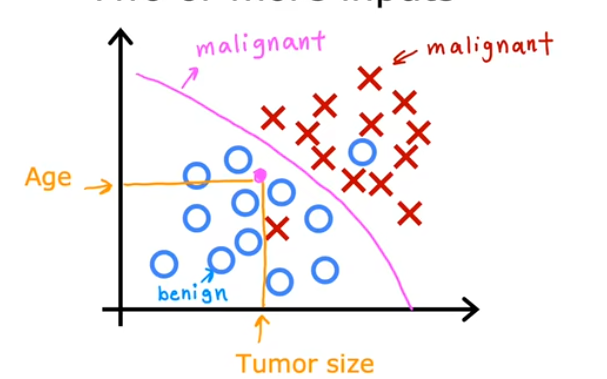
输入一个肿瘤大小值和病人年龄,判断是否是良性肿瘤。
1.2无监督学习
将输入的数据归纳总结成为拥有共同特征的簇。
聚类算法:将有关系的数据放在一个组中。
异常检测:检测异常数据。
降维技术(dimensionality reduction):在损失信息尽量少的前提下,使用更少的数据进行描述。
1.3线性回归模型
用一条直线来拟合一堆离散的点。这个模型中只有一个自变量。

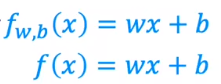
模型可以用一个f来进行映射与表示。w,b是系数。
1.4代价函数公式(损失函数,loss/cost function)
代价函数(损失函数)是指衡量预测值和真实值之间差异的函数。
最简单的一种代价函数(线性):

最后的目的是让代价函数尽可能的小,这也就代表拟合的效果更好。
以下是一组点,对W取值不同时,会有不同的J。

在W取多个值之后,最终可以找到对应最小J的W值。
多个参数时也是一样,可以找到一个w和b的组合使得J最小
1.5梯度下降

这是一个有两个参数的J。
在山坡上的点时,每走一步,需要选择下降速度最快的方向。
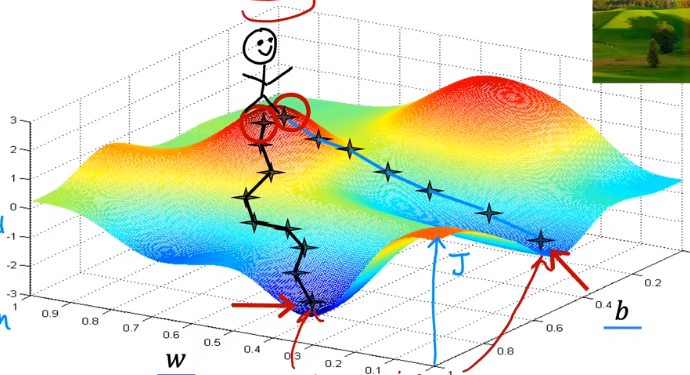
但是当出发位置不同时,可能走到的目的地(局部最优解)是不一样的。
梯度下降时,同时更新w,b
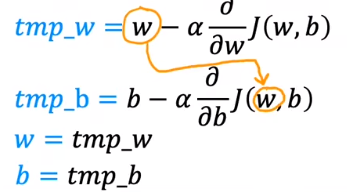
上面式子中的指的是学习率,永远是正数。
数学推导表达如下
二.多维特征
多维的可以使用向量来表示:

![]()
np.dot(w,x)是计算w和x的点积。
2.1梯度下降
梯度下降就是每一步都做n和w和一个b。

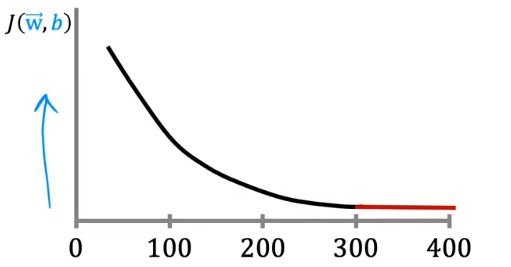
梯度下降的曲线应该是类似上图的形状。如果曲线的尾部上翘,可能是太大了。

2.2特征缩放
如果两个维度之间数值的取值范围差距过大,就应该使他们尽可能的在取值范围上相似。
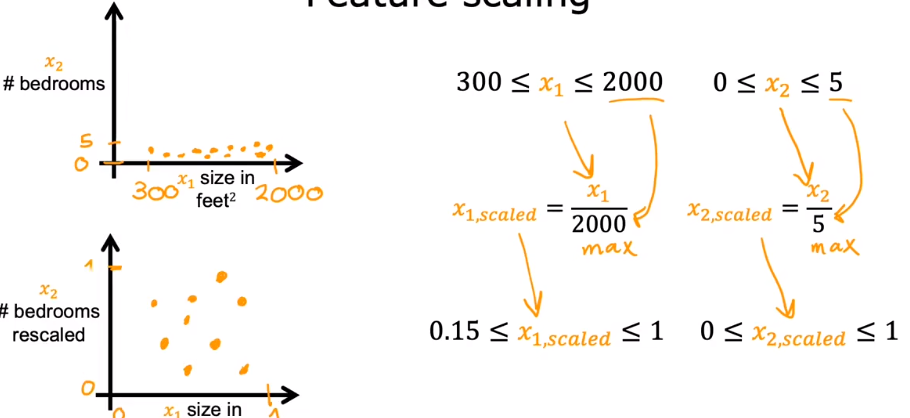
还有一种方法是归一化,先减去平均值,再缩放。

Z-core归一化的方法是首先减去平均值,再除以标准差。

三.逻辑回归模型
3.1逻辑回归
有的时候,使用线性回归模型不能很好的拟合,类似下面的曲线却可以很好的进行描述。
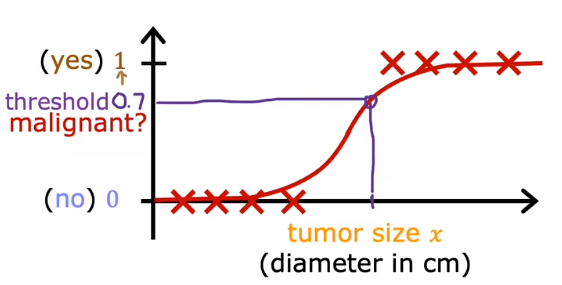
这种类型的曲线可以使用sigmoid(logistic)方程进行表示:

其特征是输出值的范围是从0到1。公式为:

如果将0.5设为阈值,那高于0.5就输出1,低于0.5就输出0。
使用sigmoid函数表达现实的模型的方式如下,将直线的线性方程的式子代入Z。
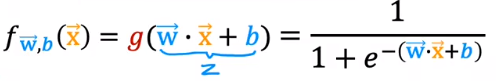
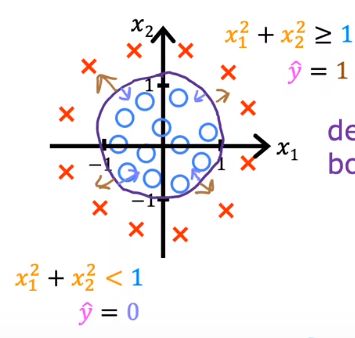
决策边界是指分隔两种输出的界限。
3.2代价函数(loss)
线性回归的loss是下凹的,所以可以用梯度下降,但是如果逻辑回归模型也使用同一种loss,曲线就会很不规则,凹凸性(二阶导师恒为正)就会经常变化。

所以使用新的代价函数。
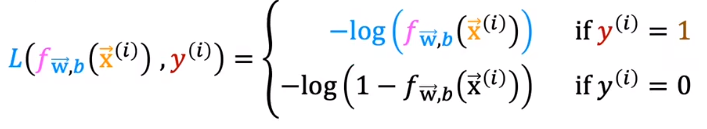
或者写成这种形式
3.3梯度下降
loss计算如下:

每一步的更新:
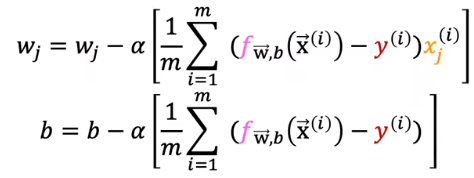
虽然看起来很像线性回归,但是f是不一样的。

3.4过拟合

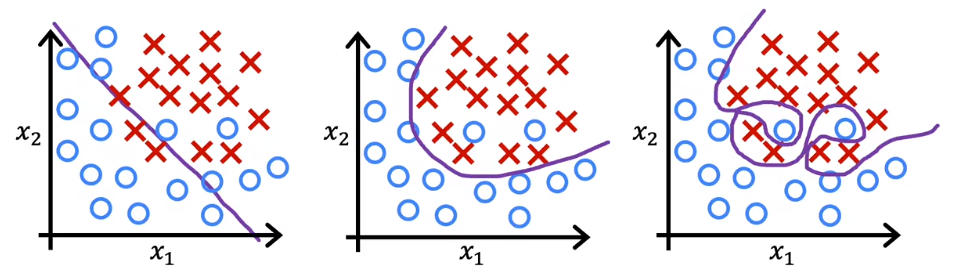
上图中,第一个欠拟合,选择的曲线不能完全表示。第二个刚刚好。第三个过拟合,没有办法添加新的点(添加之后可能离曲线很远),也没有办法训练其他数据集。
那么如何解决过拟合。
可以添加更多的训练数据。
还可以减少特征的数量,中n的数量不要过多。使用一些特征的子集。
使用正则化的方式。将高阶x的系数减小。
3.5正则化
将代价函数更新为如下的形式:
新增的后面这一项的目的是让每一个w都尽量小,尽量减少过拟合出现的可能性。
这样拟合的程度就收到的控制。
如果过小,就可能过拟合,
如果过大,就会欠拟合。
只有当合适大小,才能正确拟合。
梯度下降也会变成这样。















 1319
1319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









