






参考视频:(强推|双字)2022吴恩达机器学习Deeplearning.ai课程_哔哩哔哩_bilibili p75-p104
本文对视频做了一些补充,参考书:Neural Networks and Deep Learning邱锡鹏
一.模型评估
1.1交叉验证
正常的验证方案是把数据划分成训练集和测试集,比例一般是80%,20%。
这种方法的弊端是,在划分方法不同或者划分的子集不同时,训练的效果也不一样。
交叉验证的一种方式就是将数据集分成K份,每一份都做一次测试集,其他的k-1份作为验证集。这样经过k次,得到k个训练结果,将这几个结果平均得到最终结果。
通过交叉验证,还可以避免欠拟合和过拟合的问题。

baseline可以是人类的识别率,作为算法效果验证的基准。
Training error 是训练的错误率,Cross validation error是交叉验证的错误率。
如果像第一组数据这样,Training error和Cross validation error差距较大,得到的结论就是有高方差。
如果像第二组数据这样,Training error和baseline差距较大,得到的结论就是有高偏差。
1.2学习曲线
正常情况下,训练的误差应该是这样的。
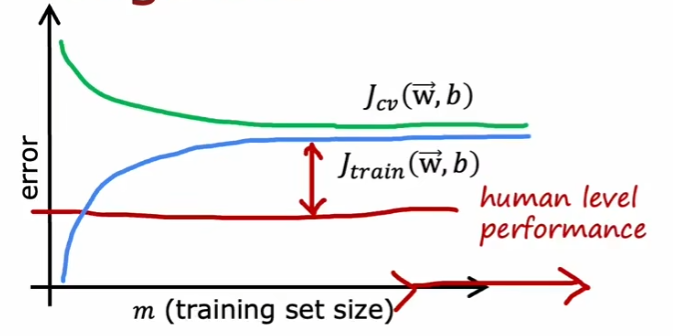
如果出现过拟合,那么误差可能是这样的。
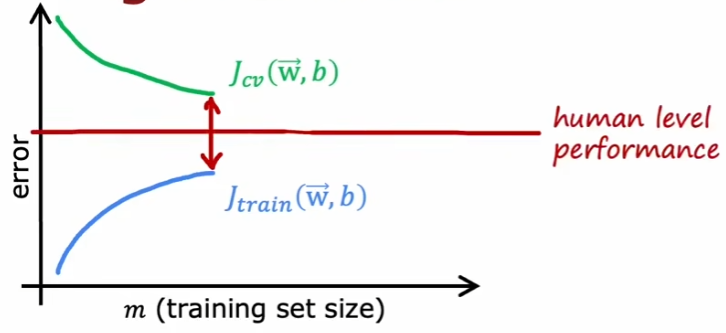
这种情况下,增加数据的量可以缓解过拟合。
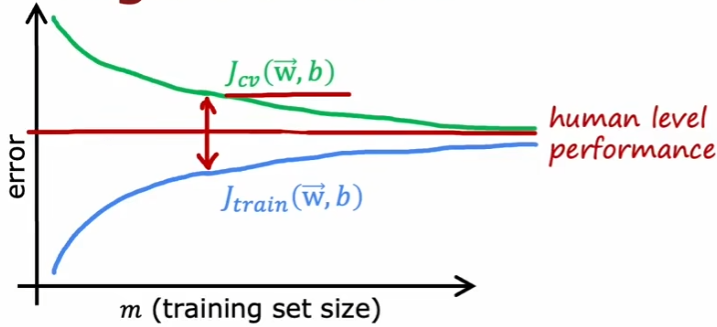
1.3如何调整模型
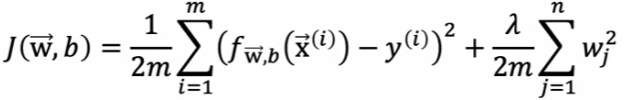
高方差:
1.获取更多训练数据。
2.减少特征数量。
3.增加λ。
高偏差:
1.增加特征的数量。
2.增加特征多项式。
3.减小λ。
1.4迁移学习
如果数据量特别小,例如只有50张手写图片,怎么完成神经网络的训练。
这个时候就应该使用迁移学习,迁移学习就是把已经在大型数据集上面训练好的神经网络进行微调,就可以完成自己的目标任务。
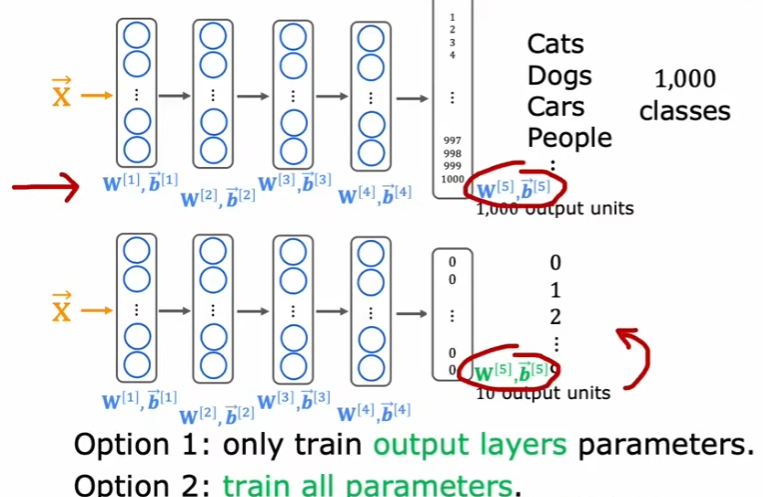 首先使用上面的神经网络来训练较大的数据集,具有较多分类。训练好参数之后,将除了输出层的其他层直接复制,后面接一个新的输出层。这个输出层的分类就比较少,只需要训练输出层的参数就可以了。这种方法,可以类似人类上了初中做小学数学题一样。
首先使用上面的神经网络来训练较大的数据集,具有较多分类。训练好参数之后,将除了输出层的其他层直接复制,后面接一个新的输出层。这个输出层的分类就比较少,只需要训练输出层的参数就可以了。这种方法,可以类似人类上了初中做小学数学题一样。
1.5误差

图中实际上正确,并且预测正确的有15个,实际上错误但是预测正确的有5个,实际上错误并且预测错误的有70个,实际上正确但是预测错误的有10个。
由于国内教材的翻译有多种,这里直接看英文的名字,我个人偏向使用查准率个查全率。
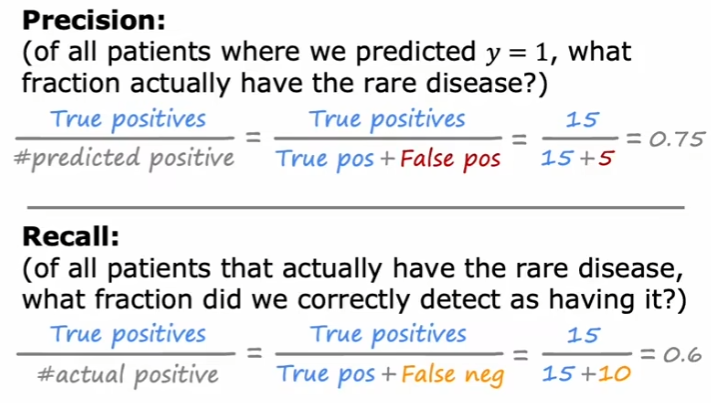
如果预测的是病人是否得病,那么计算机说有病的时候,病人有75%的可能性有病。
如果实际上病人有病,那么计算机说他有病的概率是60%。
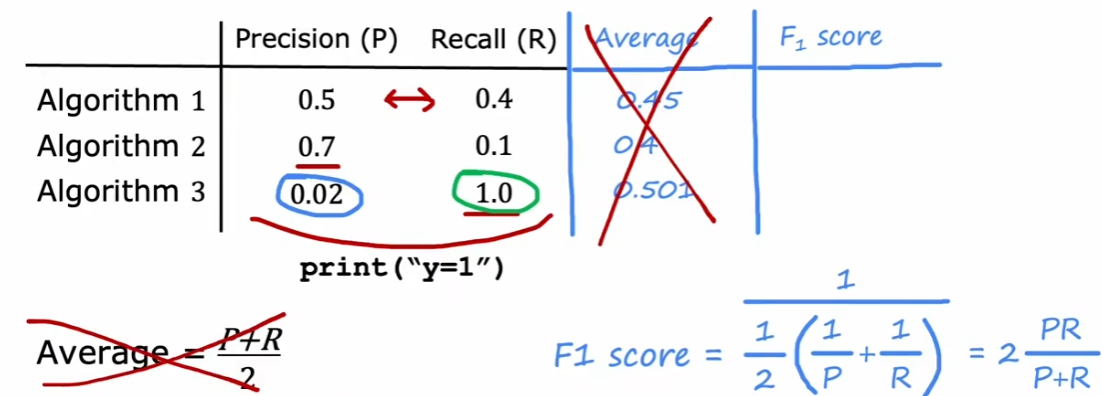
这样看来,这两个参数都是越高越好。那么如何衡量呢?
如果只是计算平均值,可能会出现算法3这种情况,所以计算F1分数。















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









