






参考视频:(强推|双字)2022吴恩达机器学习Deeplearning.ai课程_哔哩哔哩_bilibili p92-p104
一.决策树
定义可以直接看百度百科:决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
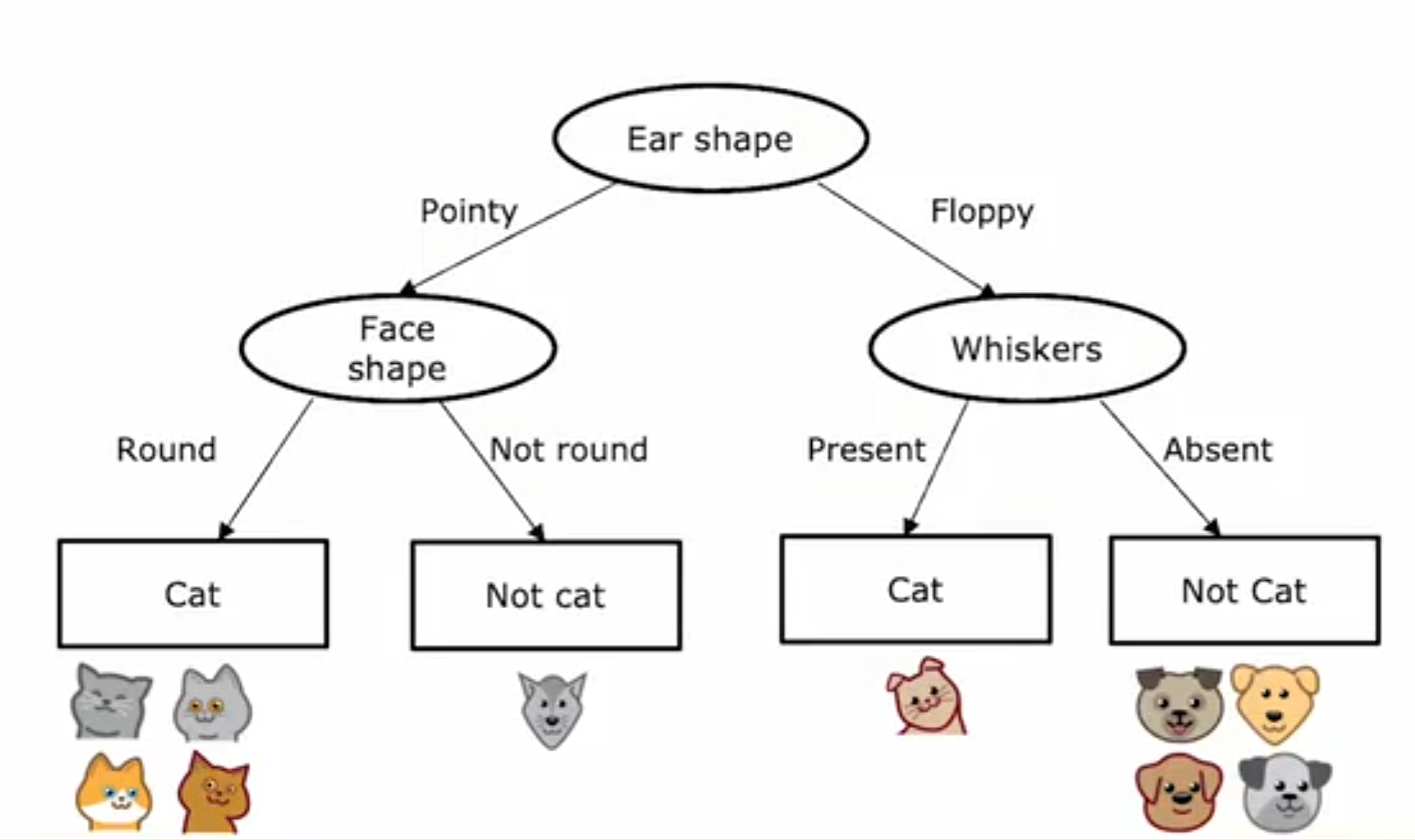
举个例子:可以通过这样一个树形结构来预测图片上的生物是猫还是狗
1.1构建决策树
每个节点上如何选择需要区分的特征?
提高纯度:还是上面的猫咪分类的例子,耳朵这种特征不能很好的将猫和狗分开,但是猫的骨骼结构可以将猫和其他动物更加精确的分开。如果使用骨骼的x光片,那将是更好的节点。如果再使用猫的DNA序列进行比对,那基本可以确认这是一只猫。
什么时候停止分类?
当节点上都是一类的时候。
当再进行分类,树的深度会突破设定的最大深度时。
当进行拆分之后,对节点的纯度影响过小时。
节点中例子的数量低于某个数值。比如在一个节点中有两个狗,一个猫,就可以设定停止了。
1.2纯度
顾名思义就是一个节点里面同一个类的数量占比。
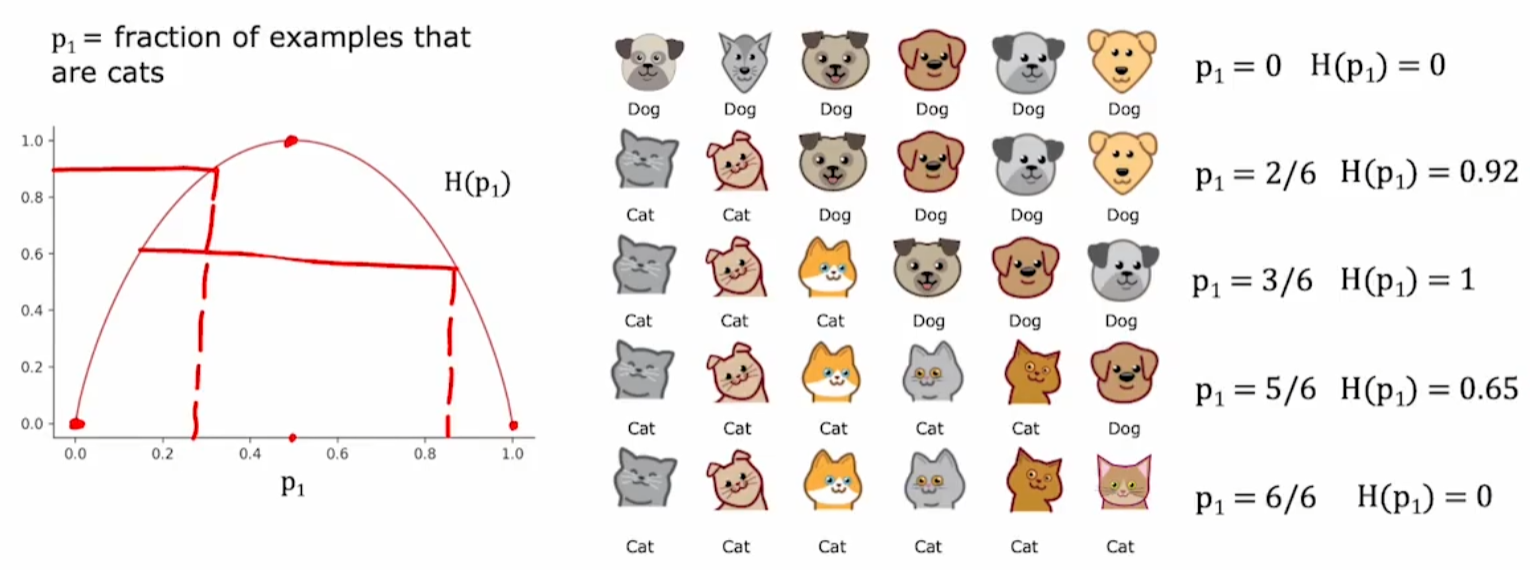
曲线是一个向上的凸型曲线。
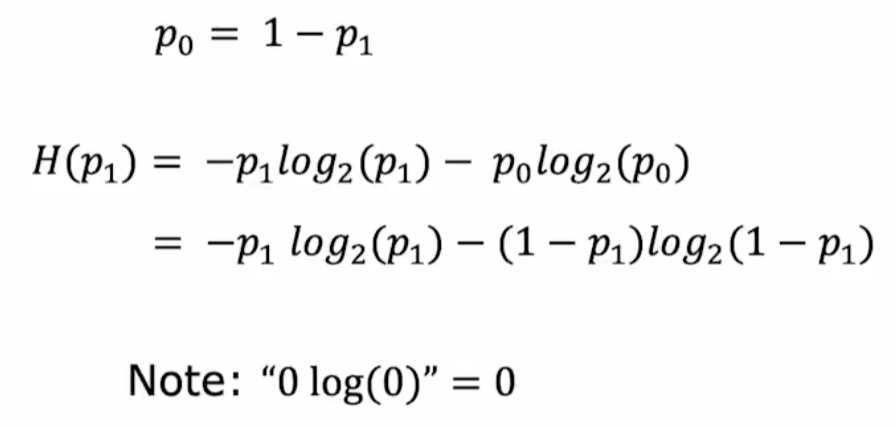
H是熵,熵越大,越不纯。
节点选择分类的特征时,计算加权的熵,选择熵最小的特征作为分类的判断。

1.3变量类型
具有多个值的变量:将每一个值当作一个特征
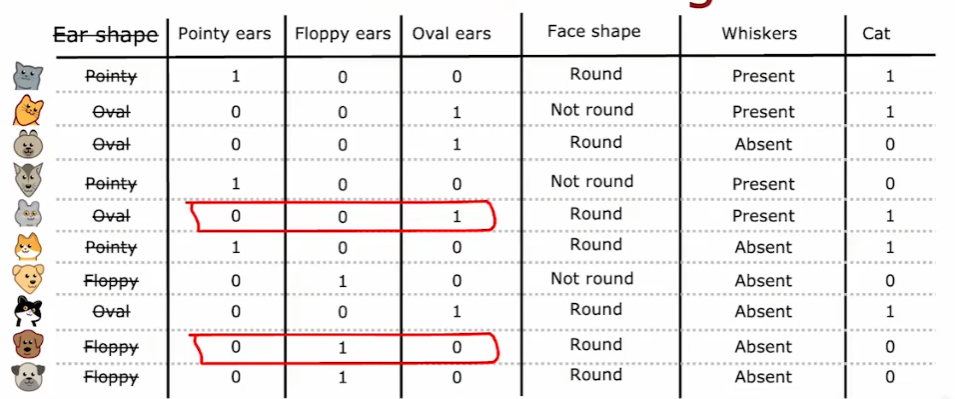
具有连续值的变量:根据每个数据的值做拆分,计算熵,选择最好的拆分数值。
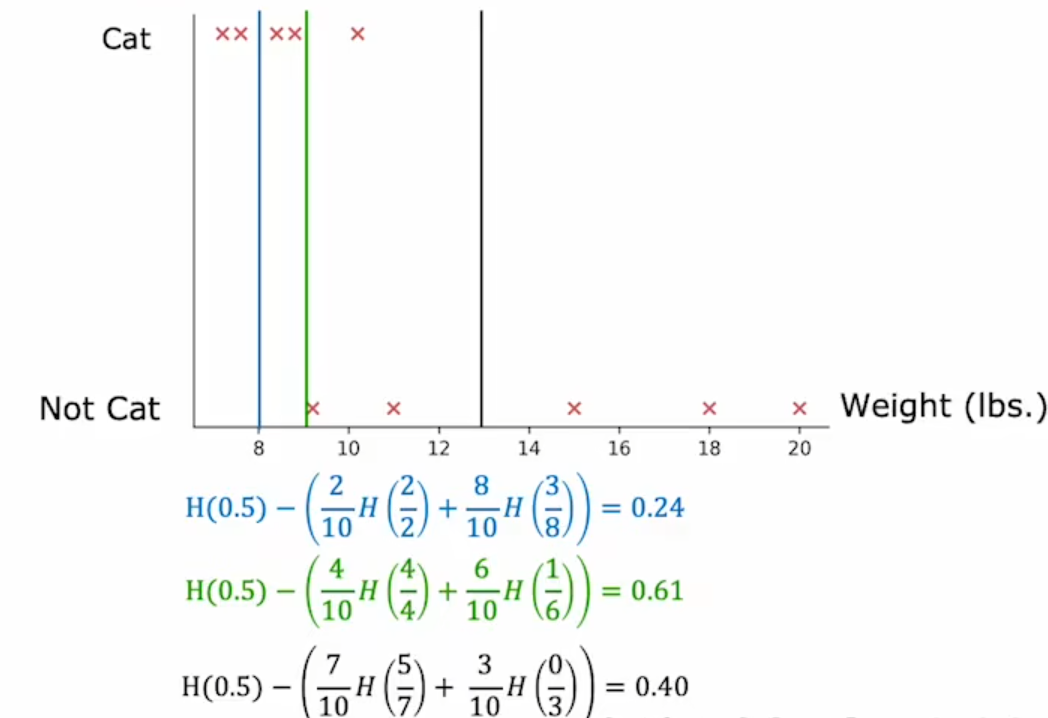
1.4随机森林
首先将原始的数据集进行有放回抽样,生成一个和原始数据集大小相同的随机抽样数据集,再在此基础上生成决策树。重复上述步骤n次,就可以得到一个随机森林。
在森林中挑选一个熵最小的树作为输出。
1.5XGBoost
工业上已经很成熟的运用了,很好,很快!具体原理自行搜索。
1.6应用场景
表格类型数据















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









