









论文阅读笔记:SCTNet: Single-Branch CNN with Transformer Semantic Information for Real-Time Segmentation
代码:https://github.com/xzz777/SCTNet
论文:https://arxiv.org/pdf/2312.17071
1 背景
为了获得更好的分割性能,最近的语义分割方法都追求丰富的长程上下文。为了捕获和编码丰富的上下文信息,人们提出了不同的方法,包括大感受野、多尺度特征融合、自注意力机制等。其中,自注意力机制作为Transformer的重要组成部分,已被证明具有显著的建模长距离上下文的能力。虽然这些方法十分有效,但通常会导致高额的计算成本。值得注意的是,基于自注意力的工作计算复杂度通常与图像分辨率的平方相关,这显著增加了处理高分辨率图像的延迟。
许多实时工作采用双边架构,以较快的速度提取高质量的语义信息。如图2(a)所示,通过以双边网络来分离早期的细节特征和上下文信息,并对其进行并行处理。为了平衡推理速度和精度,DDRNet和RTFormer等方法采用了特征共享架构,在深度阶段划分空间特征和上下文特征,如2(b)所示。然而这些方法在两个分支之间引入密集融合模块以增加提取特征的语义信息,所以存在推理速度和计算成本的冲突。本文提出的SCTNet,使用仅训练的transformer分支来对其CNN分支的语义,推理时只使用CNN分支,这样既提高了速度,又使得CNN有良好的语义特征。整体架构如图2(c)。

图1展示了SCTNet和其他实时分割方法在Cityscapes验证集上的对比效果。

2 创新点
-
提出了一种新颖的单分支实时分割网络SCTNet。通过从Transformer到CNN的语义信息对齐学习提取丰富的语义信息,SCTNet在保持轻量级单分支CNN快速推理速度的同时,拥有较高的Transformer准确率。
-
为了缓解CNN特征和transformer特征之间的语义鸿沟,作者设计了CFBlock ( ConvFormer Block ),它可以仅使用卷积操作作为transformer block来捕获长距离上下文。此外,提出的SIAM语义对齐模块可以以更有效的方式对齐特征。
-
大量的实验结果表明,本文提出的SCTNet在Cityscapes、ADE20K和COCO - Stuff - 10K上的实时语义分割性能优于现有的先进方法。SCTNet为提高实时语义分割的速度和性能提供了新的思路。
3 方法
作者提出了一种带有Transformer语义信息的单分支CNN网络用于实时分割,称为SCTNet。具体来说,SCTNet从仅训练的Transformer语义分支到CNN分支学习长距离上下文。为了减少Transformer和CNN之间的语义鸿沟,作者设计了一个类似于Transformer的CNN块成为CFBlock,并在对齐之前使用一个共享的解码器头。利用训练中对齐的语义信息,单分支CNN可以对语义信息和空间细节进行信息编码,因此SCTNet能够在保持轻量级单分支CNN架构高效推理的同时,还能从Transformer架构庞大的有效感受野种对齐语义表示。如图3。

4 模块
4.1 Conv-Former Block
由于网络类型不同,CNN和Transformer提取的特征表示存在明显差异。在CNN和Transformer之间直接进行特征对齐使得学习过程变得困难。为了使CNN分支更容易的学习如何从Transformer分支中提取高质量的语义信息,作者设计了Conv-Former Block。Conv-Former Block尽可能模拟transformer block的结构,以更好地学习transformer分支的语义信息。同时,Conv-Former Block只使用有效的卷积操作来实现注意力功能。
Conv-Former Block的结构类似于典型的Transformer编码器的结构,如图4左边所示。

此过程可以表示为:

其中 N o r m ( ⋅ ) Norm(·) Norm(⋅) 表示Batch Normalization。 x , f , y x,f,y x,f,y 分别表示输入,隐含层特征和输出。
用于实时分割的注意力机制应该具有低延迟和强大的语义提取能力。作者认为GFA(GPU Friendly Attention)比较符合,所以卷积注意力参考自GFA。
GPU Friendly Attention来自论文《RTFormer: Efficient Design for Real-Time Semantic Segmentation with Transformer》,可参考之前的博客《论文阅读笔记:RTFormer: Efficient Design for Real-Time Semantic Segmentation with Transformer》
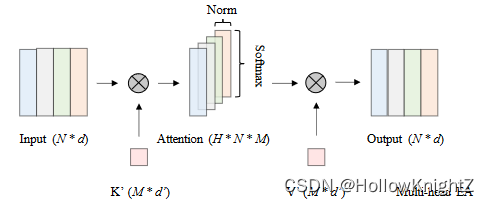
GFA与提出的卷积注意力有两个主要的区别。首先GFA的矩阵相乘操作替换为逐像素卷积操作。点卷积相当于像素到像素的乘法运算,但不要特征扁平化和reshape操作,这些操作不利于保持固有的空间结构,并带来额外的推理延迟。
此外,卷积提供了一种更灵活的方式来扩展外部参数。然而,由于Transformer和CNN之间存在语义鸿沟,简单地计算几个可学习向量与每个像素之间的相似度,然后根据相似度图和可学习向量对像素进行增强,不足以捕获丰富的上下文信息。为了更好地对齐Transformer的语义信息,作者将可学习的向量扩大为可学习的核。一方面,这将像素与可学习向量之间的相似度计算转换为具有可学习核的像素块之间的相似度计算。另一方面,具有可学习核的卷积操作在一定程度上保留了更多的局部空间信息。卷积注意力的操作可以概括如下:

其中
X
∈
R
C
×
H
×
W
,
K
∈
R
C
×
N
×
k
×
k
,
K
T
∈
R
N
×
C
×
k
×
k
X∈R^{C×H×W},K∈R^{C×N×k×k},K^T∈R^{N×C×k×k}
X∈RC×H×W,K∈RC×N×k×k,KT∈RN×C×k×k表示输入图像和可学习的query和key(这里应该是key和value吧?)。C,H,W表示特征图的通道,高度和宽度,N是可学习参数个数,k表示可学习参数的核大小,θ表示分组双归一化,即在H×W的维度上应用softmax,在N的维度上应用分组L2范数。
在HW维度进行softmax归一化,使得所有像素点对存储单元K的单个像素相似度之和为1,在N维度上归一化,使得HW个查询点对的注意力差距拉大,更容易关注不同的位置。
考虑到效率问题,作者采用空间可分离卷积而不是标准卷积来实现卷积注意力。更具体地说,使用一个1 × k和一个k × 1卷积来近似一个k × k卷积层。图4展示了卷积注意力的实现细节。
典型的前馈网络FFN由一个通道扩展点卷积、一个深度3×3卷积和一个通道压缩点卷积组成。与典型的FFN不同,本文使用的FFN由两个标准的3×3卷积层组成。与典型的FFN相比,本文使用的FFN更高效,并提供了更大的感受野。
4.2 语义信息对齐模块
语义信息对齐模块用于在训练中进行特征学习,其可以拆分为主干特征对齐和共享解码器头对齐。
得益于Conv-Former Block的transformer式结构,对齐损失可以很容易的将CF Block的特征和transformer的特征对齐。如图。简而言之,主干特征对齐首先从transformer和CNN分支对特征进行下采样或上采样进行对齐。然后将CNN的特征投影到transformer的维度上。最后,对投影后的特征进行语义对齐损失,使语义表示对齐。

考虑到CNN好Transformer在解码空间上的显著差异,将解码特征与输出logits直接对齐只能得到有限的提升。因此,作者提出了共享解码器头对齐。将单分支CNN的stage2和stage4特征级联输入到点卷积中进行维度扩展。然后将高维特征传递到Transformer解码器,最后利用Transformer解码器的新的输出特征和logits值来计算与Transformer解码器原始输出的对齐损失。

4.3 整体结构
为了在获取丰富语义信息的同时减少计算成本,作者将流行的双分支架构简化为一个用于推理的快速CNN分支和一个仅用于训练的语义对齐的Transformer分支。SCTNet采用了一个典型的分层CNN骨干网络来提高推理速度。
骨干网络从一个由两个连续的3×3卷积层组成的stem块开始。前两个阶段由堆叠的残差块组成,后两个阶段包括了被称为Conv-Former Blocks(CFBlocks)的提出的类似Transformer块的块。CFBlock采用了类似Transformer块远程上下文捕获功能的卷积操作。在第2∼4阶段的开始应用了一个convdown层,该层由一个带有批量归一化和ReLU激活的步进卷积组成,用于下采样,为了清晰起见,图3中省略了该层。
解码器头由一个DAPPM和一个分割头组成。为了进一步丰富上下文信息,在第4阶段的输出后添加了一个DAPPM。然后将输出与第2阶段的特征图连接起来。最后,将这个输出特征传入一个分割头。具体来说,分割头由一个3×3的Conv-BN-ReLU操作符和一个1×1的卷积分类器组成。
在训练阶段有两个流。SCTNet采用一个仅用于训练的Transformer作为语义分支,提取强大的全局语义上下文。语义信息对齐模块监督卷积分支,将来自Transformer的高质量全局上下文对齐。
**在推理阶段,**为了避免两个分支的大量计算成本,只部署CNN分支。通过与Transformer对齐的语义信息,单分支CNN可以生成准确的分割结果,而无需额外的语义或昂贵的密集融合。具体来说,输入图像被送入单分支分层卷积骨干网络。然后解码器头从骨干网络中提取特征,并进行简单的连接,然后进行像素级分类。
4.4 对齐损失
为了更好的对齐语义信息,作者使用了通道蒸馏损失CWD Loss作为对齐损失,Loss如下:

其中, c = 1 , 2 , … , C c=1,2,…,C c=1,2,…,C 表示通道, i = 1 , 2 , … , H ⋅ W i=1,2,…,H·W i=1,2,…,H⋅W表示空间位置, X T X^T XT 和 X S X^S XS 表示transformer分支和CNN分支的特征图。 ϕ \phi ϕ 将特征激活转化为通道概率分布,消除了Transformer和CNN之间尺度的影响。为了最小化 L c w d L_{cwd} Lcwd ,当 ϕ ( X T c , i ) \phi(X_T^{c,i}) ϕ(XTc,i) 很大是, ϕ ( X S c , i ) \phi(X_S^{c,i}) ϕ(XSc,i) 也会变得很大,但当 ϕ ( X T c , i ) \phi(X_T^{c,i}) ϕ(XTc,i) 很小时,并不会监督影响 ϕ ( X S c , i ) \phi(X_S^{c,i}) ϕ(XSc,i) 。这就迫使CNN学习Transformer中前景显著度的分布,,而前景显著度包含了语义信息, τ \tau τ 是超参,且越大,概率分布会越接近。
5 效果
5.1 和SOTA方法对比
在RTX 3090上,使用512×512的分辨率推理评估ADE20K的对比效果表2。

在RTX 3090上,使用640×640的分辨率推理评估COCO-Stuff测试集的对比效果如表3。

在RTX 2080Ti上,推理评估Cityscapes验证集的对比效果如表11。

在RTX 3090上,推理评估Cityscapes验证集的对比效果如表12。

一些展示效果和速度的图:



5.2 消融实验
为了验证提出的CFBlock的有效性,作者将CFBlocks替换成层其他的卷积块和transformer块,对比效果如表4。本文提出的方法取得了速度和效果的均衡。

将语义信息对齐模块用在Segformer等方法上却了一致的改进,这证明了提出的SIAM模块的有效性。(Seg100表示原图尺寸分割,Seg50表示下采样为原来的1/2分割,以此类推。)

文中提出的各个模块的消融实验效果如表6。

CFBlock中卷积核的设置实验如表8。

损失函数、对齐损失的使用位置和对齐损失的权重的消融实验如表9。

作者还选择了不同的语义分支进行消融实验,最终选择训练时间和显存更少,效果更好的SegFormer作为最终的语义分支。

6 结论
可以将Transformer模型的语义提取能力迁移到CNN模型上。


















 7738
7738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









