







一、GPU如何做并行计算
1.简单的串行计算

对于如上的运算AX+Y,每次运算我们需要从内存读取两个数据,一个是x[i],一个是y[i],最后存回y[i]。这里面有一个FMA的操作(融合乘加(FMA)指令是RISC处理器中的常见指令),把乘法和加法融合在一起。之后进行N次的迭代。这就是在CPU的一段串行,按顺序执行的程序。

以Intel Exon 8280芯片为例,内存带宽是113GB/s,内存延时是89ns ,那么每次,也就是89ns里面,我们有11659个byte去执行,当然这只是峰值的算力。
![]()
实际上在89ns的延迟时间内,我们只移动了16个byte,此时内存利用率≈0.14%。

我们99%以上的时间都花在了内存搬运上。
2.利用并发

咱们把刚才的程序展开,每次执行0~7数据,迭代8次。这样就利用了并发,使得总线处于忙碌状态。这样我们每次就可以执行11659/(8+8)=729次请求。
但仍然存在问题。
- 编译器很少对循环展开100次以上
- 一个线程每次执行的指令数量是有限的,不可能会执行非常非常多的并发数量
- 一个线程很难去直接处理700多个计算的负荷。
3.并行循环展开

通过并行处理器/多个线程去执行AX+Y,同样可以是总线处于忙碌状态当中。每次进行729次迭代,但不一样的是,我们每个线程独立去负责相关的运算,每个线程都去计算一次AX+Y。我们要进行729次计算,那么我们就需要进行729个线程,这时候我们的瓶颈变为了线程数量和内存请求。
二、并发与并行
并行指我们能同时处理多个相同的任务。
并发指我们能处理多个任务的功能,但不一定是同时。
利用多线程去对循环进行展开提高整体硬件利用率,这就是GPU的主要原理。

以上面三款芯片参数为例,我们看看我们需要多少线程才能解决内存时延的问题。可以看到GPU的时延比CPU高很多 ,而线程数是GPU比CPU高很多很多,这就是GPU的特点,它拥有大量的线程专门为大量大规模并行任务设计。

因此GPU相当于一个大型吞吐机,有的线程等待着数据,有的线程等待被激活运算,有的线程处于计算当中。指令执行的延迟和数据搬运的延迟通常不是GPU设计考虑的首要任务,主要目的是增加线程。
而CPU相当于一个延迟机,它希望一个线程里面完成所有的工作,所以要想办法在减少延时上。首要任务是优化线程的执行速率和效率。
三、GPU缓存机制

Cache大家应该都很熟悉,在CPU里,它起到了提高查询速率的作用。缓存对GPU同样的重要。
GPU有着一块独立的高带宽内存,也就是我们通常所说的显存。
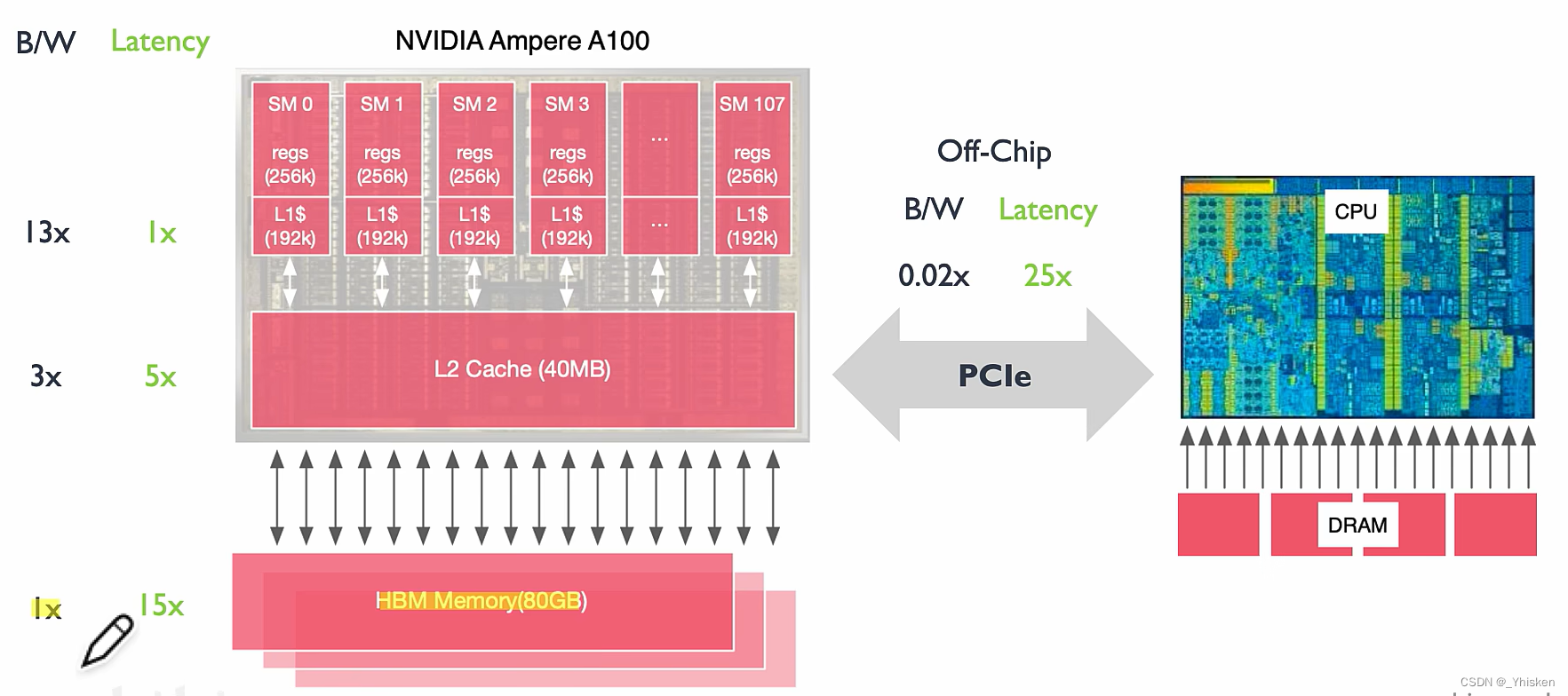
可以看到GPU缓存的内存时延是逐级递增的,而如果要用CPU去搬运数据,时延则更长。
显存的作用就是防止内存向显卡传输数据的速度跟不上计算的速度。

可以距离SM越近的缓存,运算操作越少,运算强度越低。反观PCIe,带宽很低,时延很高,计算强度也很高,算力利用率也会很低

带宽增加的同时,我们的线程数也需要增加,这样才能处理并行操作。每个线程都执行一个对应的数据才能把算力利用率提升上去。只有线程数足够多才能让整个系统的内存处于忙碌状态,让我们的计算也处于忙碌的状态。
四、GPU线程机制

上图所示左,为GPU的一个简单的基本架构,其中包含非常多的SM,SM(Streaming Multiprocessor 多流处理器),可以被认为是GPU内部一个基本的运算单元。
在GPU一个时钟周期内,我们可以执行多个warp,在这里一个SM里面有64个warp,每次warp可以进行一次并发的执行,GPU主要就是通过增加线程增加warp来掩盖延时问题,而不是减少延时时间。

可以看到A100芯片有22W个线程,线程可以在不同的warp上进行调度。大部分时候,应用程序是用不完这么多线程的,并且并不是所有线程都在进行运算,有些在搬运数据,有些在等待下次计算,所以GPU的算力利用率并不是很高,但因为超配额的线程,我们并不会觉得慢。
参考:
深入GPU原理:线程和缓存关系【AI芯片】GPU原理01_哔哩哔哩_bilibili
Efficient dual-precision floating-point fused-multiply-add architecture - ScienceDirect















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









