









首先来说贝叶斯分类器就是一个概率密度估计的过程。
一.贝叶斯决策论
(1)后验概率与期望损失
贝叶斯决策论是概率框架下实施决策的基本方法。贝叶斯分类器依据两大基石:概率和损失来进行最优分类。下面,我们以多分类为例来解释基本原理。
引入参数:

当将属于cj的样本误分为ci类,所产生的期望损失(条件风险)为:
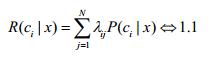
(2)贝叶斯判定准则
1.1式可以看做是贝叶斯分类器的目标函数,那么显然我们就要优化这个目标函数,使期望损失最小。这也符合我们的直观感受。根据贝叶斯判定准则:为最优化总体风险,只需是每个个体元素都最小即可。我们使用R(C|x)来表示单个元素的条件风险。
在不同的具体问题中,λ可以取不同的值,在这里我们仅仅关心概率,因此将其置为1/0。于是1.1式可以进行推演:

因此原来的期望损失最小就转化为了最大化正确分类率P(c|x),也即是最大化后验概率。如果我们能直接求出后验概率,那么这个问题就解决了。但事实上并没有那么简单。后验概率本身就是一个执果索因的过程。下面举个例子:
口袋里有3个红球2个白球,采用不放回的方式摸球。
(1)第一次摸到红球的概率?(先验概率)
(2)若第二次摸到了红球,求第一次也摸到红球的概率?(后验概率)
(3)生成式模型VS判别式模型
我们上面说到要最大化正确分类率P(c|x),那么这里有两种方式:
①生成式模型:即我们可以根据实际情况和已有的经验,或者一些简单的判断,然后估计出后验概率的概率分布形式P(c,x),然后根据数据求出后验概率的概率分布即概率分布的相应参数),再根据贝叶斯定理(下文讲解)即可求出后验概率P(c|x),下文将详细讲解这一过程。
②判别式模型:判别式模型通常是指直接对P(c|x)或者f(x)建模,最后直接输出P(|x)或者f(x)的模型。
(4)贝叶斯定理
对于贝叶斯分类器而言,采用的是生成式模型,因此我们就必须用到联合分布P(c,x)和贝叶斯定理:
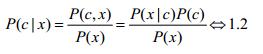
解释下里面的几个概率:P(c|x)—后验概率;P(c,x)—联合分布;P(x|c)—条件概率或者叫“似然”;P(x)—归一化因子;P(c)—先验概率。
在1.2中,我们应该关注条件概率P(x|c),因为先验概率P(c)很容易从数据分部里面求出来(ci里面数据的个数)/(总数据个数)获得,归一化因子就跟常数没啥区别了。因此根据训练数据求条件概率P(x|c)成为我们的焦点。
当然了,你可以说,我们可以像求P(c),通过统计每一个类别ci中的数据个数,用频率来代替概率值。这样做当然是不可行的,我们不妨假设所分类别为20个类别,也即20维。如果求P(c),那么我们每个维度里面有几个数据就够了,充其量就百十来个,就足够我们求出20个P(c)。但是我们求P(x|c)呢,就完全不一样了:
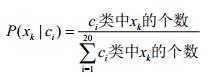
需要的数据将呈指数级别增长(这个问题暂时有点模糊,说不清楚),许多数据根本不会出现在你的训练集中,这也是机器学习中的维度灾难和数据稀疏。如果数据的数量远多于数据维度所需要的数据(10倍左右),那么应该是可以这样做的。
二.极大似然估计(MLE)
(这其实是一种参数估计方法,而常见的非参数估计有knn)我们上面也说到了,当数据量不够的情况下,我们只能凭行业经验预估p(x|c)(注意小写代表概率)的概率分布,然后训练求参来得出P(x|c)。这里我们还是用老掉牙的高斯分布吧,同时我们引入P(x|c)的参数,将P(x|c)表示为:

然后对均值和方差进行最大似然估计:
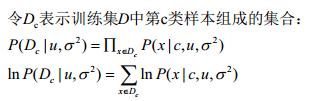
最后求出参数u和方差:

因此我们就求出了对于第c类而言的P(x|c)。按照这种方法,如我们所说的20类,我们就需要求出20个P(x|c),然后对每一个xi而言求出他的20个P(c|xi),哪一个最大,就将xi分类到哪一个c中。















 4797
4797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









